📚 博主的专栏
上篇文章:HTTP服务器实现
下篇文章:传输层协议-TCP
摘要 :
本文系统探讨传输层核心概念,重点解析端口号的作用与分类,涵盖知名端口号的绑定规则、进程与端口号的映射机制,以及一个端口号不可多进程绑定的底层原理。深入剖析UDP协议的结构化数据特性,详解其无连接、不可靠及面向数据报的核心特点,并分析UDP缓冲区设计与数据传输限制。结合操作系统实现,阐述报文封装/解包流程及sk_buff结构对网络报文的管理逻辑,列举基于UDP的应用层协议(如DNS、TFTP)。文章通过理论与命令示例结合,帮助读者构建对传输层协议栈的全面认知,理解数据从应用层到网络层的完整传递机制。
目录
[认识知名端口号(Well-Know Port Number)](#认识知名端口号(Well-Know Port Number))
一个进程可以绑定多个端口号,一个端口号一般不可以被多个进程bind
[UDP 的特点](#UDP 的特点)
[UDP 使用注意事项](#UDP 使用注意事项)
传输层
负责数据能够从发送端传输接收端.
再谈端口号
端口号(Port)标识了一个主机上进行通信的不同的应用程序;
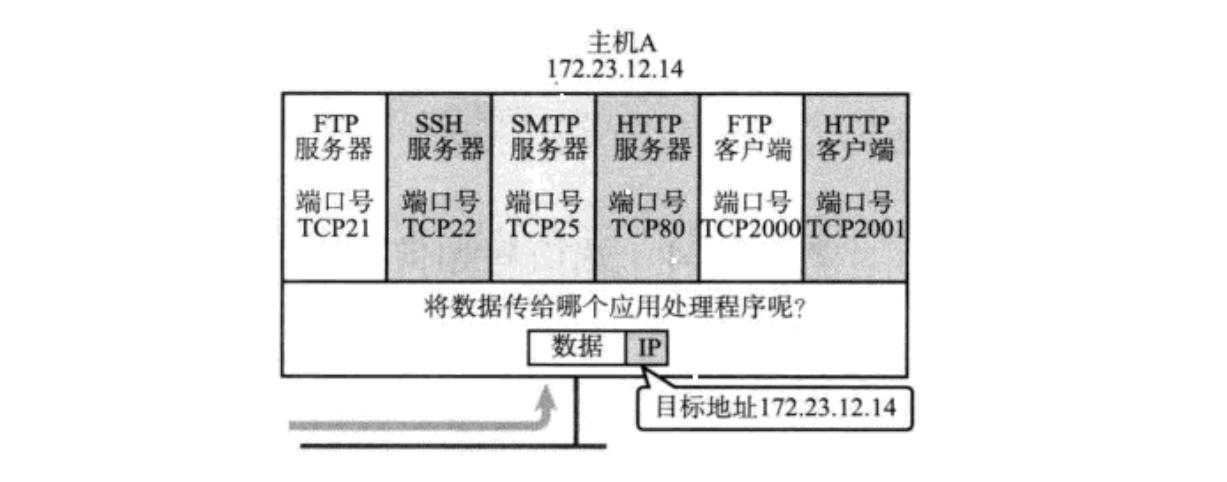
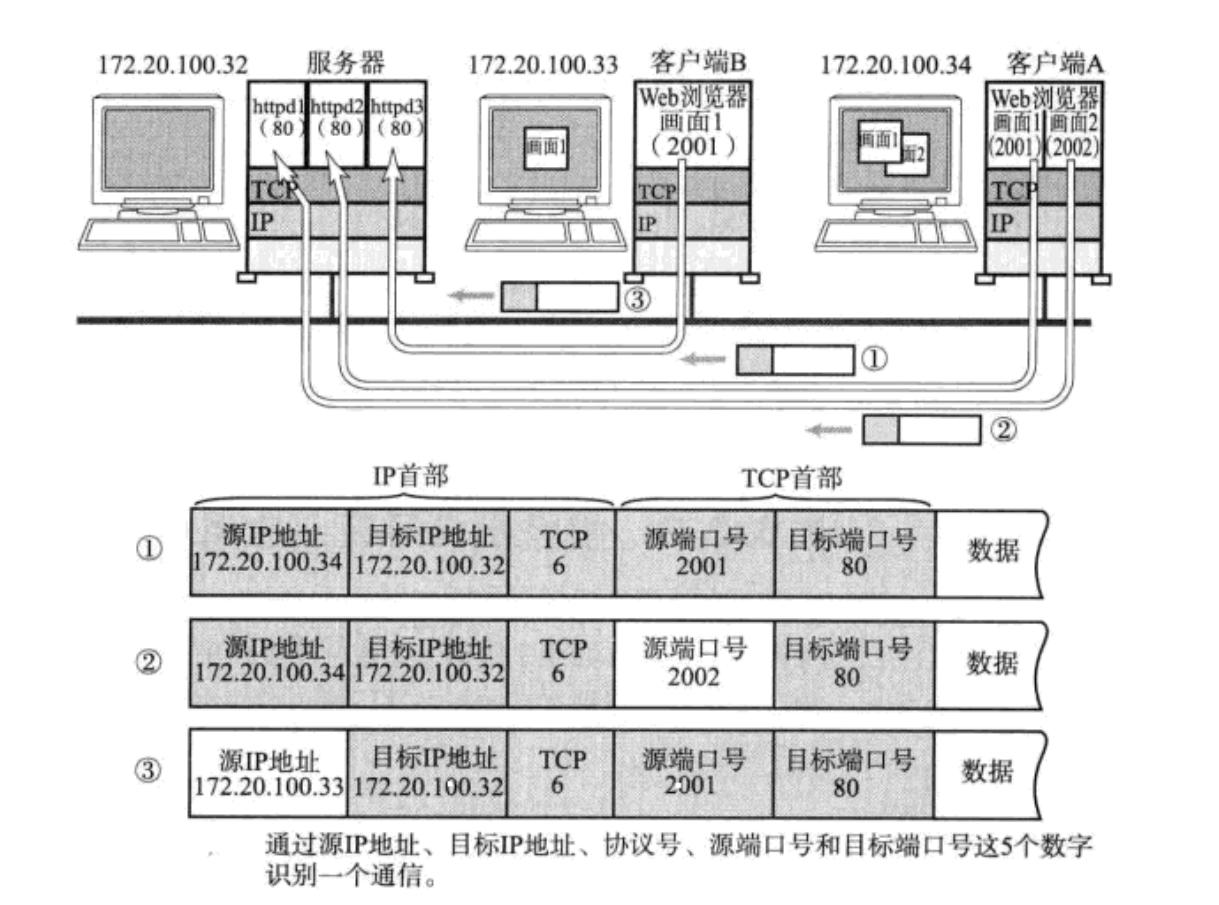
在 TCP/IP 协议中, 用 "源 IP", "源端口号", "目的 IP", "目的端口号", "协议号" 这样一个五元组来标识一个通信(可以通过 netstat -n 查看)
cpp
pupu@VM-8-15-ubuntu:~/computer-network/class_59_传输层$ netstat -nltp
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:33060 0.0.0.0:* LISTEN -
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN -
tcp 0 0 127.0.0.1:3306 0.0.0.0:* LISTEN -
tcp 0 0 127.0.0.1:6010 0.0.0.0:* LISTEN -
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN -
tcp6 0 0 ::1:6010 :::* LISTEN -
tcp6 0 0 :::22 :::* LISTEN - 端口号范围划分
• 0 - 1023: 知名端口号, HTTP, FTP, SSH 等这些广为使用的应用层协议, 他们的端口号都是固定的.(必须使用sudo更高权限才能绑)端口号和他对应的服务是强关联的。
• 1024 - 65535: 操作系统动态分配的端口号. 客户端程序的端口号, 就是由操作系统从这个范围分配的
认识知名端口号(Well-Know Port Number)
有些服务器是非常常用的, 为了使用方便, 人们约定一些常用的服务器, 都是用以下这些固定的端口号:
• ssh 服务器, 使用 22 端口
• ftp 服务器, 使用 21 端口
• telnet 服务器, 使用 23 端口
• http 服务器, 使用 80 端口
• https 服务器, 使用 443
执行下面的命令, 可以看到知名端口号:
bash
cat /etc/services
cpp
# Network services, Internet style
#
# Updated from https://www.iana.org/assignments/service-names-port-numbers/service-names-port-numbers.xhtml .
#
# New ports will be added on request if they have been officially assigned
# by IANA and used in the real-world or are needed by a debian package.
# If you need a huge list of used numbers please install the nmap package.
tcpmux 1/tcp # TCP port service multiplexer
echo 7/tcp
echo 7/udp
discard 9/tcp sink null
discard 9/udp sink null
systat 11/tcp users
daytime 13/tcp
daytime 13/udp
netstat 15/tcp
qotd 17/tcp quote
chargen 19/tcp ttytst source
chargen 19/udp ttytst source
ftp-data 20/tcp
ftp 21/tcp
fsp 21/udp fspd
ssh 22/tcp # SSH Remote Login Protocol
telnet 23/tcp
smtp 25/tcp mail
time 37/tcp timserver
time 37/udp timserver
whois 43/tcp nicname
tacacs 49/tcp # Login Host Protocol (TACACS)
tacacs 49/udp
domain 53/tcp # Domain Name Server
。
。
。
。一个进程可以绑定多个端口号,一个端口号一般不可以被多个进程bind
一个进程可以绑定多个端口号吗? 可以!
请理解:我们要的是从端口号到服务的唯一性,比如说TCP我们可以创建多个套接字,每个链接用的是不同的端口号。一个服务器在将来也可以建两个套接字一个用来发送数据,一个用来发送控制命令。
一个端口号是否可以被多个进程bind? 原则上一般不可以
我们要的是从端口号到服务的唯一性
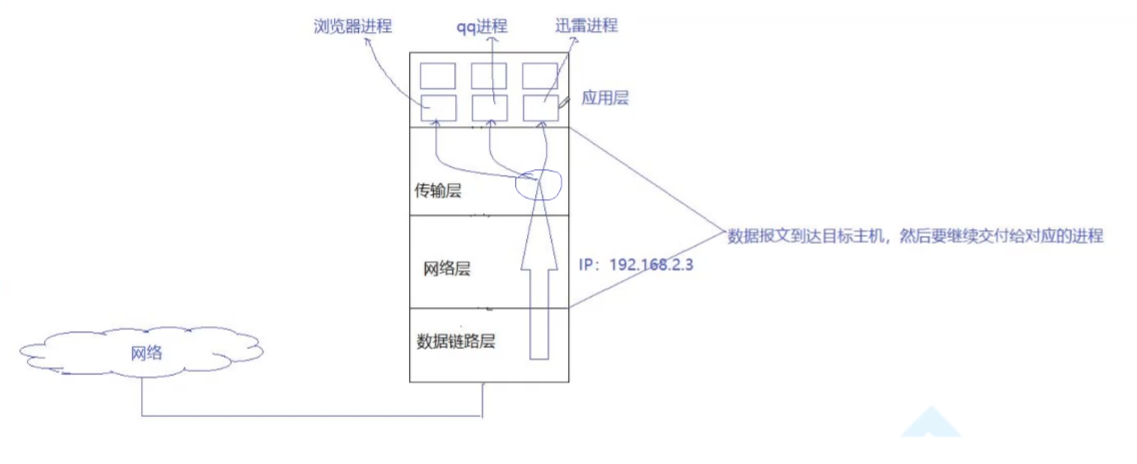
如何理解端口号和进程之间的关系?
每一个进程都有一个struct task_struct的结构体,而在我们我的操作系统内部实际上会存在着一个hashtable,在这个hashtable当中key就是我们的端口号,而value就是进程
因此bind这个操作就是将进程pcb地址和端口号构建出hash的映射关系,当底层传入了数据,传输的数据的报文当中一定携带端口号,再通过端口号如果是目的端口号,以正向的方式向哈希表中查表,找到进程,将数据交给进程,再通过文件描述符表,将数据从fd读到数据交给应用层。因此一个端口号只能被一个进程绑定,因为key值是唯一的。一个进程可以有多个端口号,从不同的端口号正向的去查找可以找到唯一的这个进程,但是如果一个端口号绑定两个进程,通过key值去查找的时候,无法判定是查找哪个进程,因此一个端口号只能绑定一个进程
UDP协议:本质是一个结构化数据

**UDP报头是一个结构体,**这就意味着,报头里面的每一个字段都是结构体当中的某一个属性。
cpp
struct udrhdr
{
_be16 source;
_be16 dest;
_be16 len;
_sum16 check;
}• 16 位 UDP 长度, 表示整个数据报(UDP 首部+UDP 数据)的最大长度;
• 如果校验和出错, 就会直接丢弃。
任何协议都有两个问题:
1.如何将报头和有效载荷进行分离(封装)。前8个字节就是报头,用16 位 UDP 长度来确定有效载荷的大小。
2.如何将有效载荷进行分离。根据目的端口号,找到应用层的对应进程,将数据给上层的进程。
UDP 的特点
UDP 传输的过程类似于寄信.
**•**无连接: 知道对端的 IP 和端口号就直接进行传输, 不需要建立连接;
•不可靠: 没有确认机制, 没有重传机制; 如果因为网络故障该段无法发到对方,UDP 协议层也不会给应用层返回任何错误信息;
•面向数据报(TCP是面向数据流): 不能够灵活的控制读写数据的次数和数量;报文之间边界是明确的,不需要我们来做独立的分离。直接做序列化和反序列化。
面向数据报
应用层交给 UDP 多长的报文, UDP 原样发送, 既不会拆分, 也不会合并;
用 UDP 传输 100 个字节的数据:
• 如果发送端调用一次 sendto, 发送 100 个字节, 那么接收端也必须调用对应的一次 recvfrom, 接收 100 个字节; 而不能循环调用 10 次 recvfrom, 每次接收 10 个字节
UDP 的缓冲区
• UDP 没有真正意义上的 发送缓冲区. 调用 sendto 会直接(从应用层)交给内核, 由内核将数据传给网络层协议进行后续的传输动作;
• UDP 具有**接收缓冲区****(保证报文不会被大面积被丢包)**直接从下层将数据就传到应用层的接收缓冲区;. 但是这个接收缓冲区不能保证收到的 UDP 报的顺序和发送 UDP 报的顺序一致; 如果缓冲区满了, 再到达的 UDP 数据就会被丢弃。
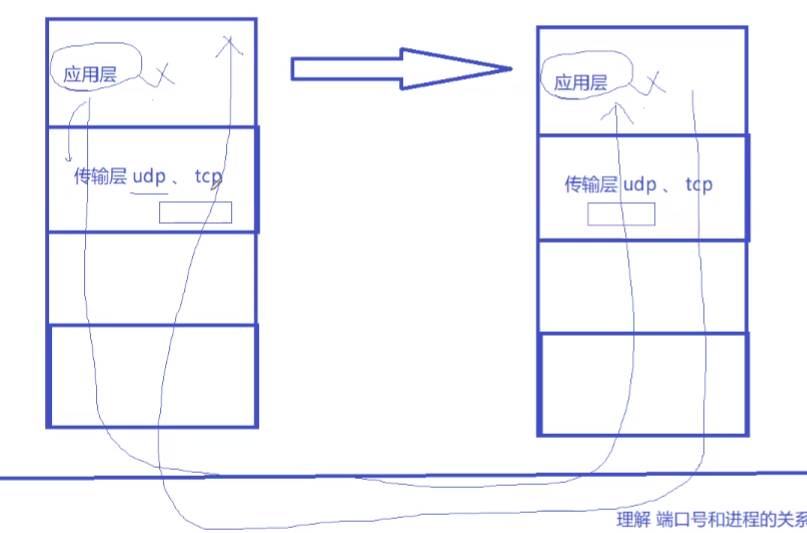
udp的套接字socket也是既能读又能写,全双工的。
**注意:**为什么udp没有真正意义上的发送缓冲器?这是因为udp不具有可靠性,不需要丢包重传,只需要添加报头再发出去,因此不需要保存在缓冲区,而是直接发。
UDP 使用注意事项
我们注意到, UDP 协议首部中有一个 16 位的最大长度. 也就是说一个 UDP 能传输的数据最大长度是 64K(包含 UDP 首部).如果超过654K,使用sendto就会失败,(每种OS不一样)有可能发一部分。
r然而 64K 在当今的互联网环境下, 是一个非常小的数字.
如果我们需要传输的数据超过 64K, 就需要在应用层手动的分包, 多次发送, 并在接收端手动拼装
基于UDP的应用层协议
• NFS: 网络文件系统
• TFTP: 简单文件传输协议
• DHCP: 动态主机配置协议
• BOOTP: 启动协议(用于无盘设备启动)
• DNS:域名解析协议,把IP地址转化成字符串
进一步深刻理解:封装和解包、报文向上交付和向下传递!!
将来我们所要发送的是结构体变量(值写好的),因此之后直接使用结构体指针访问到每一个属性值。
1.将来的客户端(其他语言)和服务器(用C++\C语言写的)设备可能完全不一样,结构化字段类型的的长度都不一样,另外还有大小端,内存对齐等问题,在应用层的差别比较大。而在内核因为没有业务(纯技术话题)就可以这么使用,能这么做的前提:没有任何新的字段,保证在报文发送时不会增加网络发送量,双方OS,任何OS都是C语言写的,网络序列都是固定的,考虑清楚大小端序列,转化成网络序列,结构体就不会出错。OS大家的标准化程度做的较高,使用的都是C语言,都需要将网络序列化转成大端序列,报文的格式大家都认识,因此网络协议一般发的就是结构体对象,这一般就叫做二进制流的序列化和反序列化。
在OS内部我们需要建立这样的认识:
在OS内部,在同一时间点 ,会同时存在收到大量的报文,正在被向上交付,也正在被向下交付。
因此OS会对各种报文进行管理,因此在OS通过先描述再组织 的方式对报文进行管理。因此一个完整的报文不仅仅是有对应的报头和有效载荷,还有描述报文的结构体,在OS中叫做struct sk_buff。
在struct sk_buff内部:指针:char *head,char *data.....
结构体指针:struct sk_buff *sk;
在传输层,会给每一个报文都形成一个缓冲区,缓冲区特点,不是从头开始访问的,而是在偏中间的位置,通过char *head,char *data,这两个指针,指向同一个位置,当在应用层要拷贝数据过来的时候,会将数据拷贝到后半部分。
cpp
struct udrhdr
{
_be16 source;
_be16 dest;
_be16 len;
_sum16 check;
}**udp报头的添加:**在缓冲区中,以data作为开始向后拷贝正文部分数据,添加报头的时候,让data不要动,给报头添加信息,head向前移动udp字段信息个字节,每次添加head指针就向前移动,最后head向前移动udp信息个字节。最后再将buffer->header强转成指针类型(struct udrhdr*)(buffer->header)如图:
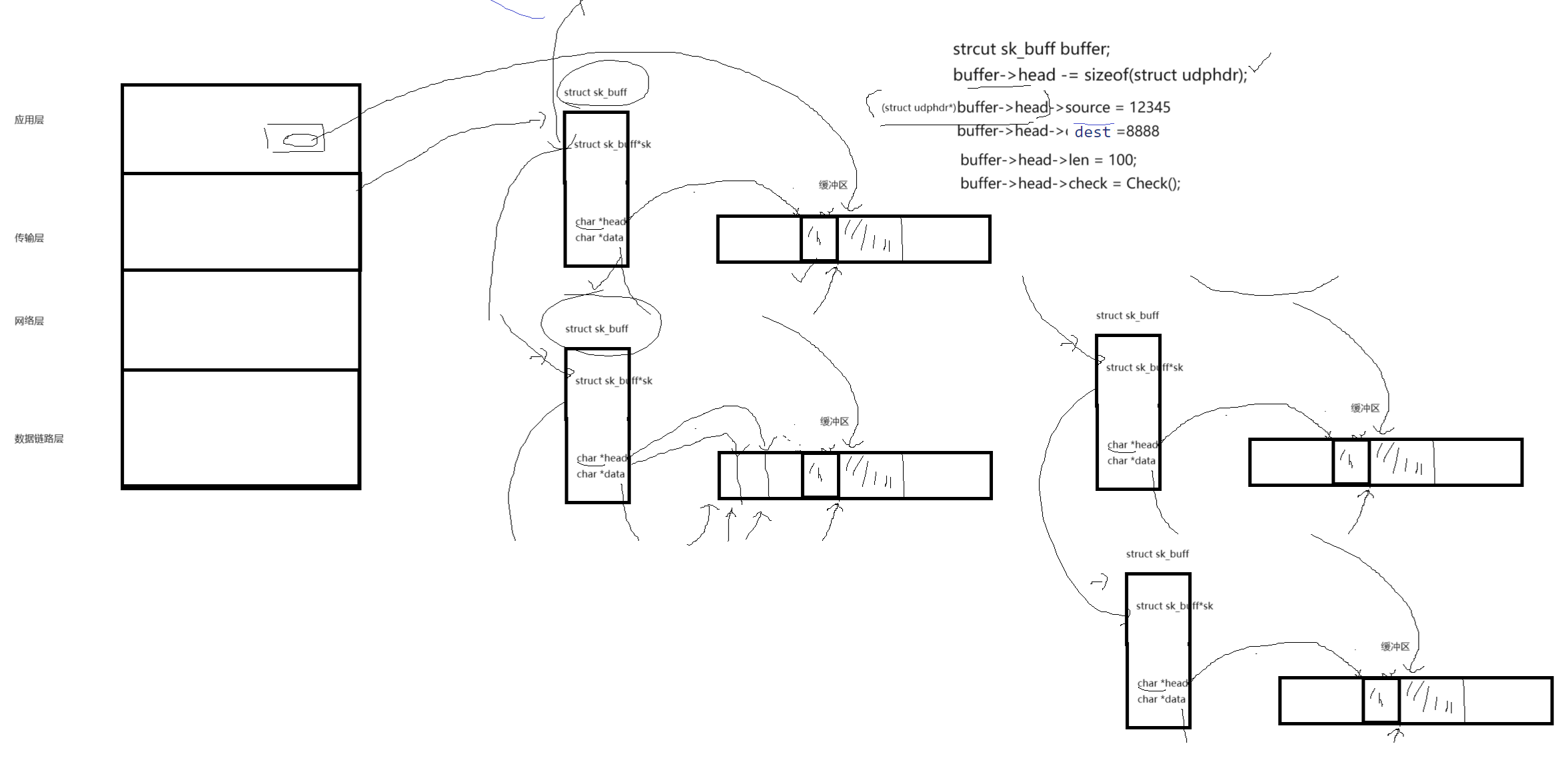
系统中具有多个报文,也存在多个sk_buffer,最后对报文的管理就变成了,只需要把sk_buff用指针链接起来(双链表),最后只要能找到链表的头,就能知道整个所有的报文,因此对报文的管理就转化成了对链表的增删查改。交付给下一层就是把数据结构交给下一层。
对于报文的解包:就是找到对应的sk_buff之后,使用header依次向后加,就能够解包。因此最后在协议栈中流动的就是结构体对象。通过传参来层级处理。
结语:随着这篇博客接近尾声,我衷心希望我所分享的内容能为你带来一些启发和帮助。学习和理解的过程往往充满挑战,但正是这些挑战让我们不断成长和进步。我在准备这篇文章时,也深刻体会到了学习与分享的乐趣。
在此,我要特别感谢每一位阅读到这里的你。是你的关注和支持,给予了我持续写作和分享的动力。我深知,无论我在某个领域有多少见解,都离不开大家的鼓励与指正。因此,如果你在阅读过程中有任何疑问、建议或是发现了文章中的不足之处,都欢迎你慷慨赐教。
你的每一条反馈都是我前进路上的宝贵财富。同时,我也非常期待能够得到你的点赞、收藏,关注这将是对我莫大的支持和鼓励。当然,我更期待的是能够持续为你带来有价值的内容。