物流单据处理:每天处理大量发货单PDF,提取订单编号、发货方信息等关键字段重命名文件
合同管理:从合同PDF中提取合同编号、签署方名称等作为文件名
学术论文整理:根据论文标题或作者信息重命名PDF文件
财务票据归档:从发票PDF中提取发票号码、日期等信息命名文件

界面设计
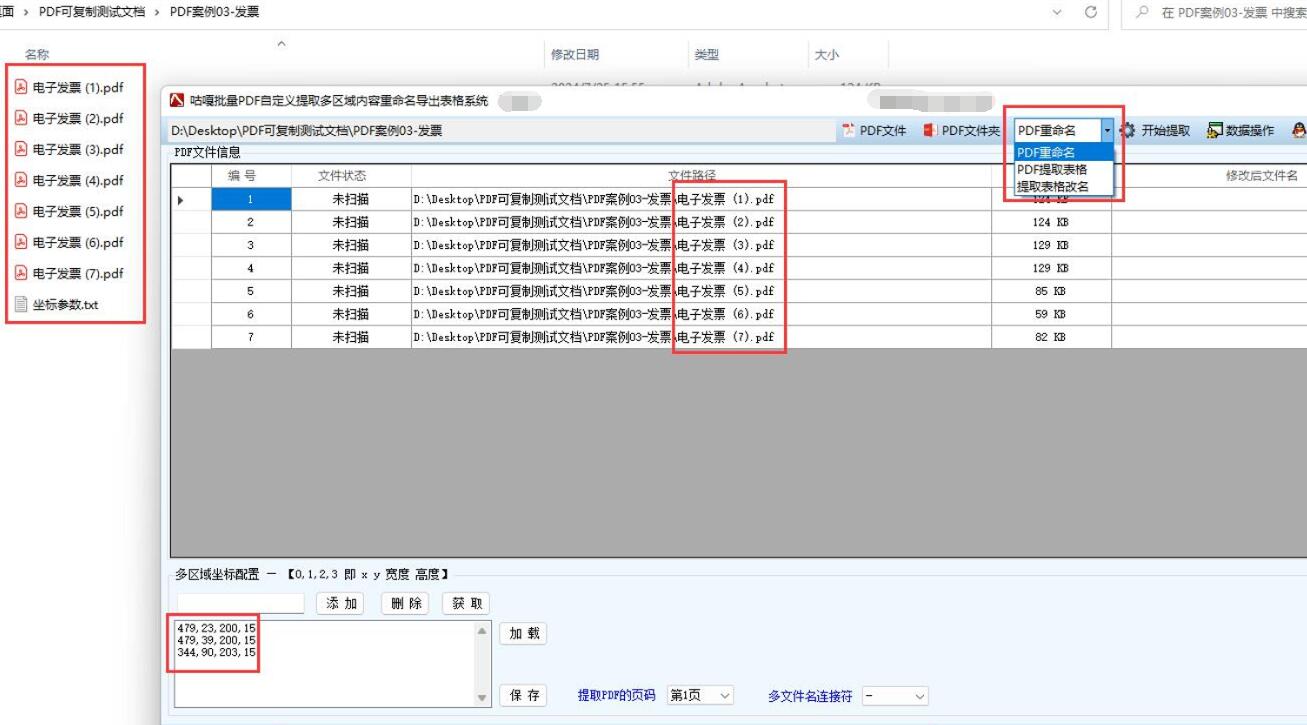
图形界面(GUI)设计
// 使用Java Swing设计简单界面
JFrame frame = new JFrame("PDF批量重命名工具");
frame.setSize(500, 400);
// 主要组件
JButton selectDirBtn = new JButton("选择PDF目录");
JTextField dirPathField = new JTextField(30);
JTextArea logArea = new JTextArea(10, 40);
JButton processBtn = new JButton("开始处理");
// 布局
JPanel panel = new JPanel();
panel.add(new JLabel("PDF目录:"));
panel.add(dirPathField);
panel.add(selectDirBtn);
panel.add(new JScrollPane(logArea));
panel.add(processBtn);
frame.add(panel);
frame.setVisible(true);命令行界面(CLI)设计
支持命令行参数:
java -jar PDFRenamer.jar -i /path/to/pdf -o /output/path -p "提取模式"详细实现步骤
1. 环境准备
-
JDK 8+
-
Maven项目
-
添加PDFBox依赖
org.apache.pdfbox pdfbox 2.0.29
2. 核心代码实现
PDF文本提取类
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import org.apache.pdfbox.text.TextPosition;
public class PDFTextExtractor {
public static String extractTextFromRegion(String filePath,
int pageNum, float x1, float y1, float x2, float y2) throws IOException {
try (PDDocument document = PDDocument.load(new File(filePath))) {
PDFTextStripper stripper = new PDFTextStripper() {
@Override
protected void writeString(String text, List<TextPosition> textPositions) {
for (TextPosition textPosition : textPositions) {
float x = textPosition.getX();
float y = textPosition.getY();
// 只收集指定区域内的文本
if (x >= x1 && x <= x2 && y >= y1 && y <= y2) {
super.writeString(text, textPositions);
break;
}
}
}
};
stripper.setStartPage(pageNum);
stripper.setEndPage(pageNum);
return stripper.getText(document).trim();
}
}
}批量重命名类
import java.io.File;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class PDFRenamer {
public static void batchRename(String dirPath, String pattern) throws IOException {
File dir = new File(dirPath);
File[] pdfFiles = dir.listFiles((d, name) -> name.endsWith(".pdf"));
if (pdfFiles == null) return;
for (File pdfFile : pdfFiles) {
// 提取指定区域文本作为新文件名
String newName = extractContentForNaming(pdfFile.getPath(), pattern);
if (newName != null && !newName.isEmpty()) {
Path source = Paths.get(pdfFile.getPath());
Path target = Paths.get(pdfFile.getParent(), newName + ".pdf");
// 避免文件名冲突
int counter = 1;
while (Files.exists(target)) {
target = Paths.get(pdfFile.getParent(),
newName + "_" + (counter++) + ".pdf");
}
Files.move(source, target);
System.out.println("重命名: " + pdfFile.getName() + " -> " + target.getFileName());
}
}
}
private static String extractContentForNaming(String filePath, String pattern) {
// 实现根据pattern提取特定内容的逻辑
// 例如从第一页的(100,100)到(300,300)区域提取文本
try {
return PDFTextExtractor.extractTextFromRegion(filePath, 1, 100, 100, 300, 300);
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
}3. 使用示例
public class Main {
public static void main(String[] args) {
// GUI版本
PDFRenamerGUI.launch();
// 或CLI版本
if (args.length > 0) {
PDFRenamer.batchRename(args[0], "default");
} else {
PDFRenamer.batchRename("C:\\PDFs", "title");
}
}
}优化与总结
优化建议
-
性能优化:
- 使用多线程处理大量PDF文件
- 缓存已解析的PDF文档避免重复加载
-
功能增强:
- 支持正则表达式匹配提取内容
- 添加PDF拆分功能(按页拆分) 支持OCR识别扫描版PDF
-
健壮性改进:
- 添加文件重命名冲突处理机制
- 增加操作日志和撤销功能
总结
本方案基于Apache PDFBox实现了PDF内容提取和批量重命名功能,具有以下特点:
- 支持指定区域内容提取
- 提供GUI和CLI两种操作方式
- 易于集成到现有Java系统中
实际应用中可根据具体需求调整区域识别策略和命名规则,例如物流行业可提取运单号,合同管理可提取合同编号。