一年前,笔者基于开源了一个阅读顺序模型(《【文档智能】符合人类阅读顺序的文档模型-LayoutReader及非官方权重开源》),
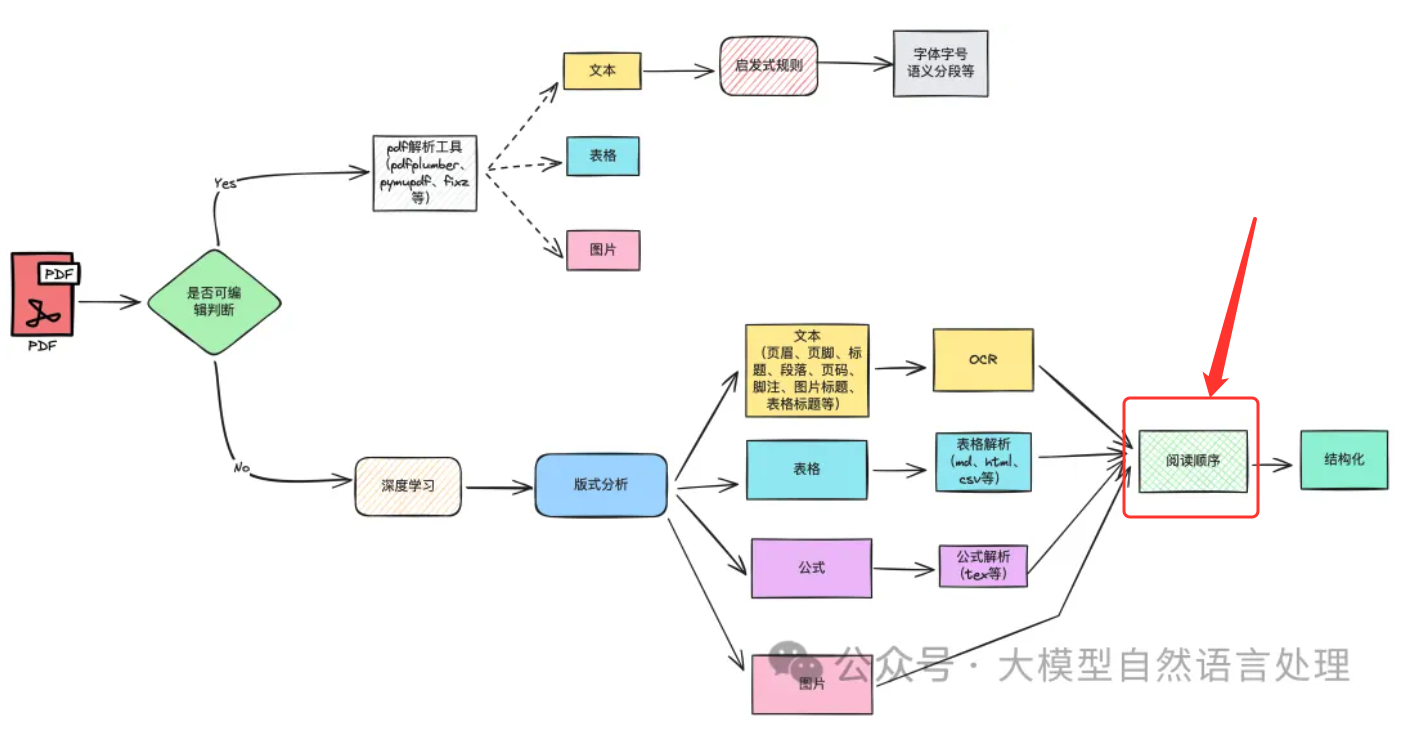
阅读顺序检测旨在捕获人类读者能够自然理解的单词序列。现有的OCR引擎通常按照从上到下、从左到右的方式排列识别到的文本行,但这并不适用于某些文档类型,如多栏模板、表格等。LayoutReader模型使用seq2seq模型捕获文本和布局信息,用于阅读顺序预测,在实验中表现出色,并显著提高了开源和商业OCR引擎在文本行排序方面的表现。
Github:https://github.com/yujunhuics/LayoutReader
权重地址:https://www.modelscope.cn/models/yujunhuinlp/LayoutReader-only-layout-large
有伙伴私信不知如何使用,笔者通过版式分析的结果,后接开源笔者开源的模型,完善这个技术链路。供参考。先看效果:
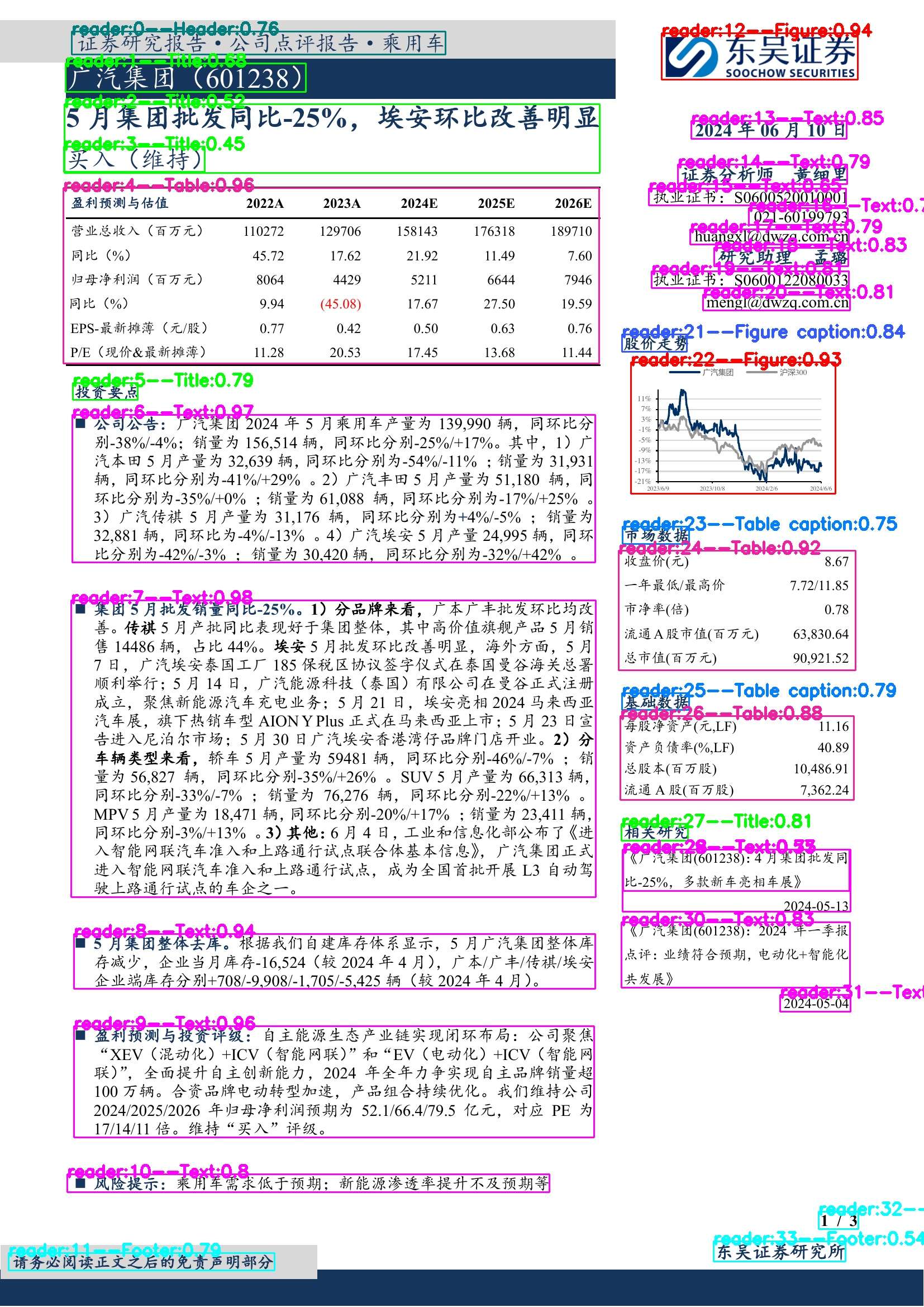

详细代码已上传:https://github.com/yujunhuics/LayoutReader/blob/main/vis.py
python
#!/usr/bin/env python
# _*_coding:utf-8_*_
# Author : Junhui Yu
from ultralytics import YOLO
import cv2
import torch
from model import LayoutLMv3ForBboxClassification
from collections import defaultdict
CLS_TOKEN_ID = 0
UNK_TOKEN_ID = 3
EOS_TOKEN_ID = 2
def BboxesMasks(boxes):
bbox = [[0, 0, 0, 0]] + boxes + [[0, 0, 0, 0]]
input_ids = [CLS_TOKEN_ID] + [UNK_TOKEN_ID] * len(boxes) + [EOS_TOKEN_ID]
attention_mask = [1] + [1] * len(boxes) + [1]
return {
"bbox": torch.tensor([bbox]),
"attention_mask": torch.tensor([attention_mask]),
"input_ids": torch.tensor([input_ids]),
}
def decode(logits, length):
logits = logits[1: length + 1, :length]
orders = logits.argsort(descending=False).tolist()
ret = [o.pop() for o in orders]
while True:
order_to_idxes = defaultdict(list)
for idx, order in enumerate(ret):
order_to_idxes[order].append(idx)
order_to_idxes = {k: v for k, v in order_to_idxes.items() if len(v) > 1}
if not order_to_idxes:
break
for order, idxes in order_to_idxes.items():
idxes_to_logit = {}
for idx in idxes:
idxes_to_logit[idx] = logits[idx, order]
idxes_to_logit = sorted(
idxes_to_logit.items(), key=lambda x: x[1], reverse=True
)
for idx, _ in idxes_to_logit[1:]:
ret[idx] = orders[idx].pop()
return ret
def layoutreader(bboxes):
inputs = BboxesMasks(bboxes)
logits = layoutreader_model(**inputs).logits.cpu().squeeze(0)
orders = decode(logits, len(bboxes))
return orders
# report label
# id2name = {
# 0: 'Text',
# 1: 'Title',
# 2: 'Header',
# 3: 'Footer',
# 4: 'Figure',
# 5: 'Table',
# 6: 'Toc',
# 7: 'Figure caption',
# 8: 'Table caption',
# 9: 'Equation',
# 10: 'Footnote'
# }
# paper label
id2name = {
0: 'Text',
1: 'Title',
2: 'Figure',
3: 'Figure caption',
4: 'Table',
5: 'Table caption',
6: 'Header',
7: 'Footer',
8: 'Reference',
9: 'Equation'
}
color_map = {
'Text': (255, 0, 255),
'Title': (0, 255, 0),
'Header': (125, 125, 0),
'Footer': (255, 255, 0),
'Figure': (0, 0, 255),
'Table': (160, 32, 240),
'Toc': (199, 97, 20),
'Figure caption': (255, 90, 50),
'Table caption': (255, 128, 0),
'Equation': (255, 123, 123),
'Footnote': (222, 110, 0)
}
image_path = 'page_4.png'
model_path = "./LayoutReader-only-layout-large"
# 下载地址:https://modelscope.cn/models/yujunhuinlp/LayoutReader-only-layout-large
layoutreader_model = LayoutLMv3ForBboxClassification.from_pretrained(model_path)
layout_model = YOLO('paper-8n.pt')
# 下载地址:https://huggingface.co/qihoo360/360LayoutAnalysis
# layout_model = YOLO('report-8n.pt')
result = layout_model(image_path, save=False, conf=0.45, save_crop=False, line_width=1)
print(result)
img = cv2.imread(image_path)
page_h, page_w = img.shape[:2]
x_scale = 1000.0 / page_w
y_scale = 1000.0 / page_h
bbox_cls = result[0].boxes.cls.tolist()
xyxyes = result[0].boxes.xyxy.tolist()
confes = result[0].boxes.conf.tolist()
print(xyxyes)
boxes = []
for left, top, right, bottom in xyxyes:
if left < 0:
left = 0
if right > page_w:
right = page_w
if top < 0:
top = 0
if bottom > page_h:
bottom = page_h
left = round(left * x_scale)
top = round(top * y_scale)
right = round(right * x_scale)
bottom = round(bottom * y_scale)
assert (
1000 >= right >= left >= 0 and 1000 >= bottom >= top >= 0), \
f'Invalid box. right: {right}, left: {left}, bottom: {bottom}, top: {top}'
boxes.append([left, top, right, bottom])
print(boxes)
orders = layoutreader(boxes)
print(orders)
xyxyes = [xyxyes[i] for i in orders]
bbox_cls = [bbox_cls[i] for i in orders]
confes = [confes[i] for i in orders]
print(xyxyes)
for idx, b_cls, xyxy, conf in zip(range(len(xyxyes)), bbox_cls, xyxyes, confes):
top_left_x, top_left_y, bottom_right_x, bottom_right_y = xyxy[0], xyxy[1], xyxy[2], xyxy[3]
cv2.rectangle(img, (int(top_left_x), int(top_left_y)), (int(bottom_right_x), int(bottom_right_y)),
color_map[id2name[b_cls]],
2)
cv2.putText(img, f"reader:{idx}--" + id2name[b_cls] + ":" + str(round(conf, 2)),
(int(top_left_x), int(top_left_y) + 5),
cv2.FONT_HERSHEY_SIMPLEX,
1,
color_map[id2name[b_cls]], 3) # Add label text
cv2.imwrite("vis-result.jpg", img)