Marker是一款功能强大的PDF转换工具,它能够将PDF文件快速、准确地转换为Markdown格式。这款工具特别适合处理书籍和科学论文,支持所有语言的转换,并且能够去除页眉、页脚等干扰元素,格式化表格和代码块,提取并保存图像和Markdown文件,并将大部分方程式转换为LaTeX格式。
功能简介
Marker:重新定义 PDF 到 Markdown 的转换效率。
• Marker 满足了将复杂的 PDF 文档转换为 markdown 以便于管理的日益增长的需求。
• 传统的文本转换器难以维持原始布局、格式和内容的准确性。
• Marker 擅长准确地保存表格、代码块和数学方程式等复杂元素。
• 自动去除文档中的非主要元素,如页眉和页脚。
• 它能够以优化的处理速度和资源使用率有效地处理大量数据。
• Marker 的定制方法减少了数字 PDF 对 OCR 的依赖,从而实现了更快、更精确的转换。
• 可以在GPU、CPU或MPS上运行。
实现原理
Marker的工作原理基于深度学习模型。它首先通过OCR技术(如果需要的话)提取文本(采用启发式算法和 tesseract 工具),然后检测页面布局并确定阅读顺序(使用 布局分割器1 和 列检测器2)。接下来,Marker会对每个文本块进行清洁和格式化处理(运用启发式算法和 nougat3),最后将所有块合并并进行后处理,生成完整的Markdown文本(利用启发式算法和 pdf后处理器4)。Marker只在必要时使用模型,从而提高了转换速度和准确性。
性能表现
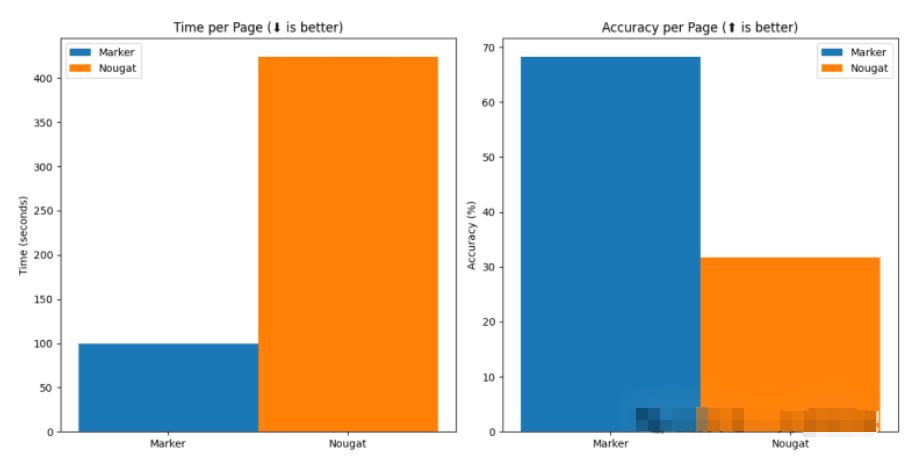
通过查找具有 pdf 版本和 latex 源的书籍和科学论文创建了一个测试集。将 latex 转换为文本,并将参考与文本提取方法的输出进行比较。
基准测试表明 marker 比 nougat 快 4 倍,而且在 arXiv 之外更准确(nougat 是在 arXiv 数据上训练的)
速度
| Method | Average Score | Time per page | Time per document |
|---|---|---|---|
| marker | 0.613721 | 0.631991 | 58.1432 |
| nougat | 0.406603 | 2.59702 | 238.926 |
准确性
前 3 篇是非 arXiv 书籍,后 3 篇是 arXiv 论文。
| Method | multicolcnn.pdf | switch_trans.pdf | thinkpython.pdf | thinkos.pdf | thinkdsp.pdf | crowd.pdf |
|---|---|---|---|---|---|---|
| marker | 0.536176 | 0.516833 | 0.70515 | 0.710657 | 0.690042 | 0.523467 |
| nougat | 0.44009 | 0.588973 | 0.322706 | 0.401342 | 0.160842 | 0.525663 |
基准测试期间,nougat的 GPU 内存使用峰值为 4.2GB,而marker的 GPU 内存使用峰值为 4.1GB。 基准测试在 A6000 Ada 上运行。
使用
安装
您需要 Python 3.9+ 和 PyTorch。如果您使用的不是 Mac 或 GPU 机器,则可能需要先安装 CPU 版本的 torch。请参阅此处5了解更多详细信息。
安装方式:
undefined
pip install marker-pdf转换单个文件
cobol
marker_single /path/to/file.pdf /path/to/output/folder --batch_multiplier 2 --max_pages 10 --langs English• --batch_multiplier是如果您有额外的 VRAM,默认批处理大小要乘以的数值。数字越大,占用的 VRAM 越多,但处理速度越快。默认设置为 2。默认批处理大小将占用约 3GB 的 VRAM。
• --max_pages是要处理的最大页数。忽略此项可转换整个文档。
• --langs是文档中用于 OCR 的语言的逗号分隔列表
转换多个文件
cobol
marker /path/to/input/folder /path/to/output/folder --workers 10 --max 10 --metadata_file /path/to/metadata.json --min_length 10000• --workers是一次要转换的 PDF 数量。默认情况下,此值设置为 1,但您可以增加此值以增加吞吐量,但代价是增加 CPU/GPU 使用率。INFERENCE_RAM / VRAM_PER_TASK如果您使用 GPU,则并行度不会增加。
• --max是要转换的 PDF 的最大数量。省略此项可转换文件夹中的所有 PDF。
• --min_length是需要从 PDF 中提取的最少字符数,然后才会考虑进行处理。如果您要处理大量 PDF,我建议设置此项以避免对大部分是图像的 PDF 进行 OCR。(这会减慢一切速度)
• --metadata_file是包含有关 pdf 元数据的 json 文件的可选路径。如果您提供它,它将用于设置每个 pdf 的语言。如果没有,DEFAULT_LANG将使用。格式为:
undefined
{在多个 GPU 上转换多个文件
cobol
MIN_LENGTH=10000 METADATA_FILE=../pdf_meta.json NUM_DEVICES=4 NUM_WORKERS=15 marker_chunk_convert ../pdf_in ../md_out• METADATA_FILE是包含 pdf 元数据的 json 文件的可选路径。请参阅上文了解格式。
• NUM_DEVICES是要使用的 GPU 数量。应大于2或等于。
• NUM_WORKERS是每个 GPU 上运行的并行进程数。每个 GPU 的并行度不会超过 INFERENCE_RAM / VRAM_PER_TASK。
• MIN_LENGTH是需要从 PDF 中提取的最少字符数,然后才会考虑进行处理。如果您要处理大量 PDF,我建议设置此项以避免对大部分是图像的 PDF 进行 OCR。(这会减慢一切速度)
项目地址
cobol
https://github.com/VikParuchuri/marker