更加好排版:https://www.big-yellow-j.top/posts/2025/05/08/GAN.html
日常使用比较多的生成模型比如GPT/Qwen等这些大多都是"文生文"模型(当然GPT有自己的大一统模型可以"文生图")但是网上流行很多AI生成图像,而这些生成图像模型大多都离不开下面三种模型:1、GAN;2、VAE;3、Diffusion Model。因此本文主要介绍这三个基础模型作为生成模型的入门,本文主要介绍GAN模型。
此处安利一下 何凯明老师在MiT的课程:
https://mit-6s978.github.io/schedule.html
Generative Adversarial Nets(GAN)
在GAN里面一个比较核心的概念就是:通过生成模型G去捕获数据分布,而后通过一个判别模型D,判断样品来自训练数据而不是G。
A generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G
通过下面图像来了解:
其中:判别模型会尝试在数据空间中划定边界,而生成式模型会尝试对数据在整个空间中的放置方式进行建模
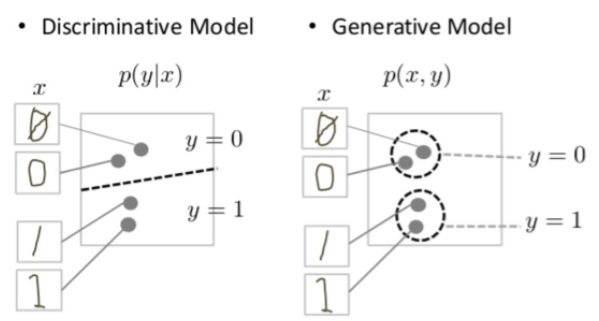
换言之就是:有两组模型1、生成模型G;2、判别模型D。其中生成模型用来生成我们需要的图像而我们的判别模型则是用来判断所生产的图像是不是"合理"的(就像老师和学生关系,老师只去关注学生的作品怎么样,而学生只去关注如何生成老师满足的作品)。了解基本原理之后,接下来深入了解其理论知识:假设数据\(x\) 存在一个分布 \(p_g\) 那么可以通过随机生成一个噪音变量 \(p_z(z)\) 而后通过一个模型(生成模型) \(G(z;\theta _g)\) 来将我们的噪音变量映射到我们正式的数据分布上,而后通过另外一个模型(判别模型) \(D(x;\theta _d)\) 来判断数据是来自生成模型还是原始数据分布,因此就可以定义一个下面损失函数:
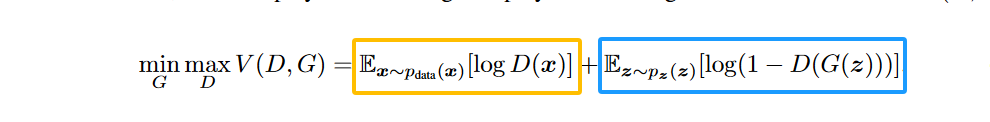
其中两种不同颜色在最值处理上是因为:1、\(D(x)\):判别器给真实样本的概率输出(判断真实的样本标记1,对于生成的样本标记0);那么对于这部分计算值:\(log(D(x))\) 自然而然的希望他是越大越好(希望判别器经可能的判别真实样本 );2、\(D(G(z))\):判别器对于生成样本的概率输出,对于这部分值(\(D(G(z))\)的计算值)我们希望越接近0越好(越接近0也就意味着判别模型能够区分生成样本),但是对于生成器模型而言希望的是:通过随机生成的样本:z越贴近我们真实分布越好。
两个模型就像是零和博弈,一个尽可能的生成假的东西,一个尽可能判别出假东西
整个训练过程如下所示:
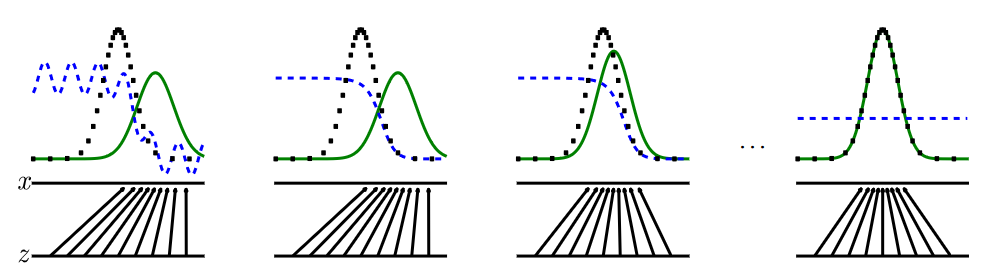
从左到右边:最开始生成模型所生成的效果不佳,判别模型可以很容易就判断出哪些是正式数据哪些是生成数据(蓝色线条代表判别模型给出的评分,最开始很容易判断出哪些是生成数据哪些是正式数据),但是随着模型迭代,生成模型所生成的内容越来越贴近正式的数据分布进而导致判别模型越来越难以判断。
算法流程:

GAN训练过程分为两部分:第一部分学习优化判别器;第二部分学习优化生成器。模型架构:
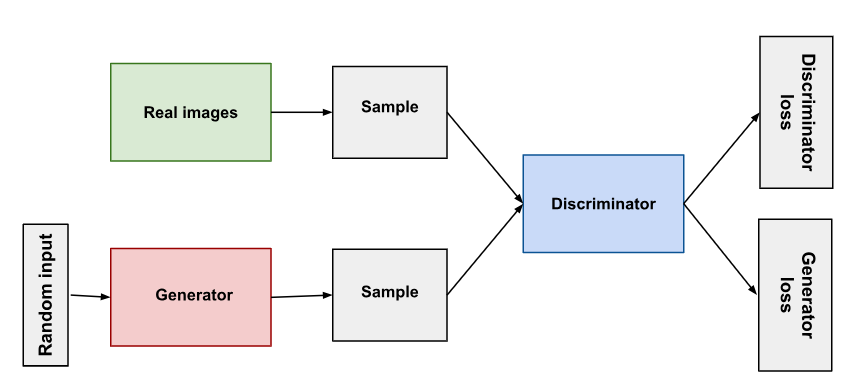
进一步了解GAN数学原理
这部分内容主要参考李宏毅老师Youtube教程:
以及博客中的总结:https://alberthg.github.io/2018/05/05/introduction-gan/
1、GAN算法推导
首先,重申以下一些重要参数和名词:
- 生成器(Generator,G)
- Generator是一个函数,输入是 \(z\) ,输出是 \(x\) ;
- 给定一个先验分布 \(p_{prior}(z)\) 和反映生成器G的分布 \(P_G(x)\),\(P_G(x)\) 对应的就是上一节的 \(p_{model}(x;θ)\) ;
- 判别器(Discriminator,D)
- Discriminator也是一个函数,输入是 \(x\) ,输出是一个标量;
- 主要是评估 \(P_G(x)\) 和 \(P_{data}(x)\) 之间到底有多不同,也就是求他们之间的交叉熵,\(P_{data}(x)\) 对应的是上一节的 \(p_{data}(x)\)。
引入目标公式:\(V(G,D)\)
\V = E_{x \\sim P_{data} } \\left \[\\ log\\ D(x) \\ \\right + E_{x \sim P_{G} } \left \\ log\\ (1-D(x)) \\ \\right \]
这条公式就是来衡量 \(P_G(x)\) 和 \(P_{data}(x)\) 之间的不同程度。对于GAN,我们的做法就是:给定 G ,找到一个 \(D^{* }\) 使得 \(V(G,D)\) 最大,即 \(\underset{D}{max}\ V(G,D)\) ,直觉上很好理解:在生成器固定的时候,就是通过判别器尽可能地将生成图片和真实图片区别开来,也就是要最大化两者之间的交叉熵。
\D\^{\* } = arg\\ \\underset{D}{max}\\ V(G,D) \\
然后,要是固定 D ,使得 \(\underset{D}{max}\ V(G,D)\) 最小的这个 G 代表的就是最好的生成器。所以 G 终极目标就是找到 \(G^{* }\), 找到了 \(G^{* }\) 我们就找到了分布 \(P_G(x)\) 对应参数的 \(θ_{G}\) :
\G\^{\* } = arg\\ \\underset{G}{min}\\ \\underset{D}{max}\\ V(G,D) \\
上边的步骤已经给出了常用的组件和一个我们期望的优化目标,现在我们按照步骤来对目标进行推导:
寻找最好的 \(D^{* }\)
首先是第一步,给定 G ,找到一个 \(D^{* }\) 使得 \(V(G,D)\) 最大,即求 \(\underset{D}{max}\ V(G,D)\) :
\\\begin{align} V \& = E_{x \\sim P_{data} } \\left \[\\ log\\ D(x) \\ \\right + E_{x \sim P_{G} } \left \\ log\\ (1-D(x)) \\ \\right \\ & = \int_{x} P_{data}(x) log D(x) dx+ \int_{x} P_G(x)log(1-D(x))dx \\ & = \int_{x}\left P_{data}(x) log D(x) + P_G(x)log(1-D(x)) \\right dx \end{align} \]
这里假定 \(D(x)\) 可以去代表任何函数。然后对每一个固定的 \(x\) 而言,我们只要让 \(P_{data}(x) log D(x) + P_G(x)log(1-D(x))\) 最大,那么积分后的值 \(V\) 也是最大的。
于是,我们设:
\f(D) = P_{data}(x) log D + P_G(x)log(1-D) \\
其中 \(D = D(x)\) ,而 \(P_{data}(x)\) 是给定的,因为真实分布是客观存在的,而因为 G 也是给定的,所以 \(P_G(x)\) 也是固定的。那么,对 \(f(D)\) 求导,然后令 \({f}'(D) = 0\),发现:
\D\^{\* } = \\frac{P_{data}(x)}{P_{data}(x)+P_G(x)} \\
于是我们就找出了在给定的 G 的条件下,最好的 D 要满足的条件。此时,我们求 \(\underset{D}{max}\ V(G,D)\) 就非常简单了,直接把前边的 \(D^{* }\) 代进去:
\\\begin{align} \& \\underset{D}{max}\\ V(G,D) \\\\ \& = V(G,D\^{\* })\\\\ \& = E_{x \\sim P_{data} } \\left \[\\ log\\ D\^{\* }(x) \\ \\right + E_{x \sim P_{G} } \left \\ log\\ (1-D\^{\* }(x)) \\ \\right \\ & = E_{x \sim P_{data} } \left \\ log\\ \\frac{P_{data}(x)}{P_{data}(x)+P_G(x)} \\ \\right + E_{x \sim P_{G} } \left \\ log\\ \\frac{P_{G}(x)}{P_{data}(x)+P_G(x)} \\ \\right \\ & = \int_{x} P_{data}(x) log \frac{P_{data}(x)}{P_{data}(x)+P_G(x)} dx+ \int_{x} P_G(x)log(\frac{P_{G}(x)}{P_{data}(x)+P_G(x)})dx \\ & = \int_{x} P_{data}(x) log \frac{\frac{1}{2}P_{data}(x)}{\frac{P_{data}(x)+P_G(x)}{2} } dx+ \int_{x} P_{G}(x) log \frac{\frac{1}{2}P_{G}(x)}{\frac{P_{data}(x)+P_G(x)}{2} } dx \\ & = \int_{x}P_{data}(x)\left ( log \frac{1}{2}+log \frac{P_{data}(x)}{\frac{P_{data}(x)+P_G(x)}{2} } \right ) dx \\ & = 2 log \frac{1}{2} + 2 \times \left \\frac{1}{2} KL\\left( P_{data}(x) \|\| \\frac{P_{data}(x)+P_{G}(x)}{2}\\right )\\right \\ & \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ + 2 \times \left \\frac{1}{2} KL\\left( P_{G}(x) \|\| \\frac{P_{data}(x)+P_{G}(x)}{2}\\right )\\right \\ & = -2 log 2 + 2 JSD \left ( P_{data}(x) || P_G(x) \right) \end{align} \]
\(JSD(P_{data}(x)||P_G(x))\in0, log2\)。那么,\(\underset{D}{max}V(G,D)\in0,-2log2\)
寻找最好的 \(G^{* }\)
这是第二步,给定 D ,找到一个 \(G^{* }\) 使得 \(\underset{D}{max}\ V(G,D)\) 最小,即求 \(\underset{G}{min}\ \underset{D}{max}\ V(G,D)\) :
根据求得的 \(D^{* }\) 我们有:
\\\begin{align} G\^{\* } \& =arg\\ \\underset{G}{min}\\ \\underset{D}{max}\\ V(G,D) \\\\ \& =arg\\ \\underset{G}{min}\\ \\underset{D}{max}\\ (-2 log 2 + 2 JSD \\left ( P_{data}(x) \|\| P_G(x) \\right)) \\end{align} \\
那么根据上式,使得最小化 \(G\) 需要满足的条件是:
\P_{data}(x) = P_{G}(x) \\
直观上我们也可以知道,当生成器的分布和真实数据的分布一样的时候,就能让 \(\underset{D}{max}\ V(G,D)\) 最小。至于如何让生成器的分布不断拟合真实数据的分布,在训练的过程中我们就可以使用梯度下降来计算:
\θ_G := θ_G - \\eta \\frac{\\partial\\ \\underset{D}{max}\\ V(G,D)}{\\partial\\ θ_G} \\
2、算法总结
- 给定一个初始的 \(G_0\) ;
- 找到 \(D_{0}^{* }\) ,最大化 \(V(G_0,D)\) ;(这个最大化的过程其实就是最大化 \(P_{data}(x)\) 和 \(P_{G_0}(x)\) 的交叉熵的过程)
- 使用梯度下降更新 \(G\) 的参数 \(θ_G := θ_G - \eta \frac{\partial\ \underset{D}{max}\ V(G,D_{0}^{* })}{\partial\ θ_G}\) ,得到 \(G_1\);
- 找到 \(D_{1}^{* }\) ,最大化 \(V(G_1,D)\) ;(这个最大化的过程其实就是最大化 \(P_{data}(x)\) 和 \(P_{G_1}(x)\) 的交叉熵的过程)
- 使用梯度下降更新 \(G\) 的参数 \(θ_G := θ_G - \eta \frac{\partial\ \underset{D}{max}\ V(G,D_{1}^{* })}{\partial\ θ_G}\) ,得到 \(G_2\);
- 循环......
3、实际过程中的算法推导
前面的推导都是基于理论上的推导,实际上前边的推导是有很多限制的,回顾以下在理论推导的过程中,其中的函数 \(V\) 是:
\\\begin{align} V \& = E_{x \\sim P_{data} } \\left \[\\ log\\ D(x) \\ \\right + E_{x \sim P_{G} } \left \\ log\\ (1-D(x)) \\ \\right \\ & = \int_{x} P_{data}(x) log D(x) dx+ \int_{x} P_G(x)log(1-D(x))dx \\ & = \int_{x}\left P_{data}(x) log D(x) + P_G(x)log(1-D(x)) \\right dx \end{align} \]
我们当时说 \(P_{data}(x)\) 是给定的,因为真实分布是客观存在的,而因为 G 也是给定的,所以 \(P_G(x)\) 也是固定的。但是现在有一个问题就是,样本空间是无穷大的,也就是我们没办法获得它的真实期望,那么我们只能使用估测的方法来进行。
比如从真实分布 \(P_{data}(x)\) 中抽样 \(\lbrace x^{(1)},x^{(2)},x^{(3)},...,x^{(m)} \rbrace\);从 \(P_{G}(x)\) 中抽样 \(\lbrace \tilde x^{(1)},\tilde x^{(2)},\tilde x^{(3)},...,\tilde x^{(m)} \rbrace\) ,而函数 \(V\) 就应该改写为:
\\\tilde V = \\frac{1}{m}\\sum_{i=1}\^{m} log D(x\^i) + \\frac{1}{m}\\sum_{i=1}\^{m} log (1-D(\\tilde x\^i)) \\
也就是我们要最大化 \(\tilde V\),也就是最小化交叉熵损失函数 \(L\),而这个 \(L\) 长这个样子:
\L = - \\left (\\frac{1}{m}\\sum_{i=1}\^{m} log D(x\^i) + \\frac{1}{m}\\sum_{i=1}\^{m} log (1-D(\\tilde x\^i)) \\right ) \\
也就是说 \(D\) 是一个由 \(θ_G\) 决定的一个二元分类器,从\(P_{data}(x)\) 中抽样 \(\lbrace x^{(1)},x^{(2)},x^{(3)},...,x^{(m)} \rbrace\) 作为正例;从 \(P_{G}(x)\) 中抽样 \(\lbrace \tilde x^{(1)},\tilde x^{(2)},\tilde x^{(3)},...,\tilde x^{(m)} \rbrace\) 作为反例。通过计算损失函数,就能够迭代梯度下降法从而得到满足条件的 \(D\)。
4、实际情况下的算法总结
- 初始化一个 由 \(θ_D\) 决定的 \(D\) 和由 \(θ_G\) 决定的 \(G\);
- 循环迭代训练过程:
- 训练判别器(D)的过程,循环 \(k\) 次:
- 从真实分布 \(P_{data}(x)\) 中抽样 \(m\)个正例 \(\lbrace x^{(1)},x^{(2)},x^{(3)},...,x^{(m)} \rbrace\)
- 从先验分布 \(P_{prior}(x)\) 中抽样 \(m\)个噪声向量 \(\lbrace z^{(1)},z^{(2)},z^{(3)},...,z^{(m)} \rbrace\)
- 利用生成器 \(\tilde x^i = G(z^i)\) 输入噪声向量生成 \(m\) 个反例 \(\lbrace \tilde x^{(1)},\tilde x^{(2)},\tilde x^{(3)},...,\tilde x^{(m)} \rbrace\)
- 最大化 \(\tilde V\) 更新判别器参数 \(θ_D\):
- \(\tilde V = \frac{1}{m}\sum_{i=1}^{m} log D(x^i) + \frac{1}{m}\sum_{i=1}^{m} log (1-D(\tilde x^i))\)
- \(θ_D := θ_D - \eta \nabla \tilde V(θ_D)\)
- 训练生成器(G)的过程,循环 \(1\) 次:
- 从先验分布 \(P_{prior}(x)\) 中抽样 \(m\)个噪声向量 \(\lbrace z^{(1)},z^{(2)},z^{(3)},...,z^{(m)} \rbrace\)
- 最小化 \(\tilde V\) 更新生成器参数 \(θ_G\):
- \(\tilde{V}=\frac{1}{m}\sum_{i=1}^m\log D(x^i)+\frac{1}{m}\sum_{i=1}^m\log(1-D(G(z^i)))\)
- \(θ_G := θ_G - \eta \nabla \tilde V(θ_G)\)
- 训练判别器(D)的过程,循环 \(k\) 次:
不过值得注意的一点是世纪在优化生成器的参数时候会直接不去计算:\(\frac{1}{m}\sum_{i=1}^m\log D(x^i)\)
5、GAN算法缺点
缺点-1:训练不稳定
主要原因在于这个优化过程并非标准的最小化任务,而是一个复杂的双向优化问题。在上面公式推导中我们得到的是:
\\\underset{D}{max}\\ V(G,D) = -2 log 2 + 2 JSD \\left ( P_{data}(x) \|\| P_G(x) \\right) \\
我们优化的目标函数是JSD,理想情况是两部分数据分布距离是越来越小。但实际上有两种情况可能会导致 JSD 永远判定两个分布距离"无穷大" ( \(\mathbf{JSD}(P_{data}(x)||P_G(x))=log2\) )。从而使得 Loss Function 永远是 0(实际测试代码也会存在这种问题,判别器的loss为0):
\\\max_D V(G, D) = -2\\log2 + 2 \\underbrace{\\mathbf{JSD}(P_{\\text{data}}(x) \\\| P_G(x))}_{\\log2} = 0 \\
第一种情况,就是判别器 D 太"强"了导致产生了过拟合 。例如下图:
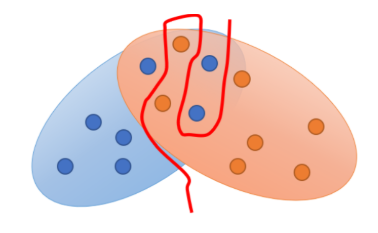
上图蓝色和橙色分别是两个分布,我们能发现分布之间确实有一些重叠,所以按理来说 JSD 不应该是 log2 。但由于我们是采样一部分样本进行训练,所以当判别器足够"强"的时候,就很有可能找到一条分界线强行将两类样本分开,从而让两类样本之间被认为完全不存在重叠。我们可以尝试传统的正则化方法(regularization等),也可以减少模型的参数让它变得弱一些。但是我们训练的目的就是要找到一个"很强"的判别器,我们在实际操作中是很难界定到底要将判别器调整到什么水平才能满足我们的需要:既不会太强,也不会太弱。还有一点就是我们之前曾经认为这个判别器应该能够测量 JSD,但它能测量 JSD 的前提就是它必须非常强,能够拟合任何数据。这就跟我们"不想让它太强"的想法有矛盾了,所以实际操作中用 regularization 等方法很难做到好的效果。
第二种情况,就是数据本身的特性 。一般来说,生成器产生的数据都是一个映射到高维空间的低维流型。而低维流型之间本身就"不是那么容易"产生重叠的。如下图所示
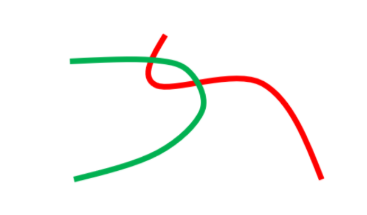
也就是说,想要让两个概率分布"碰"到一起的概率并不是很高,他们之间的 "Divergence" 永远是 log2。这会导致整个训练过程中,JSD 作为距离评判标准无法为训练提供指导。
解决方法有两种,一种是给数据加噪声,让生成器和真实数据分布"更容易"重叠在一起

但是这个方法缺点在于,我们的目标是训练准确的数据(例如高清图片等)。加入噪声势必会影响我们生成数据的质量。一个简单的做法是让噪声的幅度随着时间缩小。不过操作起来也是比较困难的。除此之外还有另一种方法。既然 JSD 效果不好,那我们可以换一个Loss Function,使得哪怕两个分布一直毫无重叠,但是都能提供一个不同的连续的的"距离的度量" ------ WGAN。
补充介绍-1 :WGAN原理 ;
在WGAN中替换最开始的JSD为:
\W(P_r,P_g)=\\inf_{\\gamma\\in\\Pi(P_r,P_g)}\\mathbb{E}_{(x,y)\\sim\\gamma}\[\\\|x-y\\\| \]
其中 \(P_r\)、\(P_g\)、\(\gamma\) 分别代表真实数据分布、生成数据分布、所有能将两个分布连接起来的联合分布。之所以这样是因为在使用JS散度时候,正如上面说的一样JS散度可能会饱和(恒等于log2),导致梯度消失,生成器无法学习。因此就会换一种"距离"度量方式。
对于WGAN可能会存在:1、判别器倾向于学习简单函数(如二值化输出)。2、梯度爆炸或消失(裁剪阈值 c 敏感)。因此在WGAN_GP提出如下损失函数:
\L_D=\\mathbb{E}_{x\\sim P_g}\[D(x)-\mathbb{E}{x\sim P_r}D(x)+\lambda L{GP} \]
\(L_{GP}=\lambda \mathbb{E}_{\hat{x}\sim P_2}(\|\|\\nabla_{\\hat{x}}D(\\hat{x})\|\|_2-1)\^2\)
缺点-1:模型坍塌
训练中可能遇到的另一个问题:所有的输出都一样!这个现象被称为模型坍塌。这个现象产生的原因可能是由于真实数据在空间中很多地方都有一个较大的概率值,但是我们的生成模型没有直接学习到真实分布的特性。为了保证最小化损失,它会宁可永远输出一样但是肯定正确的输出,也不愿意尝试其他不同但可能错误的输出。也就是说,我们的生成器有时可能无法兼顾数据分布的所有内部模式,只会保守地挑选出一个肯定正确的模式。
进一步了解GAN的代码操作
测试代码用MNIST数据集进行测试,代码模型其实就很简单就是几层线性模型+激活函数处理,主要关注的是模型如何进行训练,上面我么已经介绍了对于GAN训练需要通过同时训练判别器和生成器两个模型,因此对于训练过程代码如下:
python
for epoch in range(CONFIG['epochs']):
for real_images, _ in train_loader:
batch_size = real_images.size(0)
real_images = real_images.view(batch_size, -1).to(CONFIG['device'])
# 判别器目标就是判断样本来来源 因此只需要生成:1.真是样本标签;2.生成样本标签
real_labels = torch.ones(batch_size, 1, device=CONFIG['device'])
fake_labels = torch.zeros(batch_size, 1, device=CONFIG['device'])
# Train Discriminator
discriminator.zero_grad()
# Real images
outputs = discriminator(real_images) # 判别器任务就是判断样本来源
d_loss_real = criterion(outputs, real_labels)
# 随机生成一个向量而后输入到 生成器中 通过生成器生成 "可能"的图片而后再去计算loss
z = torch.randn(batch_size, CONFIG['latent_dim'], device=CONFIG['device'])
fake_images = generator(z)
outputs = discriminator(fake_images.detach())
d_loss_fake = criterion(outputs, fake_labels)
# 对判别器进行优化
d_loss = d_loss_real + d_loss_fake
d_loss.backward()
d_optimizer.step()
# 对生成器进行优化
generator.zero_grad()
outputs = discriminator(fake_images)
g_loss = criterion(outputs, real_labels)
g_loss.backward()
g_optimizer.step()不过值得注意的是在实际的测试过程中GAN会出现上面提到的问题,比如说判别器的loss直接变成了0,因此为了处理这种问题直接选择:1.真实样本添加一个噪声进行处理;2.标签平滑处理(不直接使用1而是用0.9);3.直接使用WGAN;4.直接调参batch_size等参数调整:
python
# 添加噪声处理
real_images = real_images + 0.05 * torch.randn_like(real_images)值得注意的是如果要使用WGAN或者WGAN-GP需要做如下修改:
- 使用WGAN:
1、将判别器最后的输出不要去用sigmoid进行处理,直接输出计算得到的概率即可
2、修改优化器选择不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD
3、计算损失过程中直接使用 判别器(在WGAN里面可能"称呼"为 critic)去计算 真实样本/ 生成样本的loss的均值
python
outputs = critic(real_images)
c_loss_real = -outputs.mean()
...
outputs = critic(fake_images.detach())
c_loss_fake = outputs.mean()
...
c_loss = c_loss_real + c_loss_fake
c_loss.backward()
c_optimizer.step()4、而后去对 判别器的梯度进行裁剪
python
for p in critic.parameters():
p.data.clamp_(-CONFIG['clip_value'], CONFIG['clip_value'])5、对于生成器而言就比较简单,直接对生成的样本去计算 loss以及反向传播
python
fake_images = generator(z)
outputs = critic(fake_images)
g_loss = -outputs.mean()
g_loss.backward()
g_optimizer.step()| GAN | DCGAN | WGAN | WGAN_GP |
|---|---|---|---|
 |
 |
 |
 |
其中WGAN和WGAN_GP都是直接使用DCGAN作为基础模型进行训练,并且都是在MNIST数据集上进行测试的结果,实际测试过程中可能最后得到的结果(epoch=100)可能不是最佳的生成的结果(视觉反映上的效果)
总结
本文主要介绍了GAN的基本原理以及数学推导,GAN主要优化目标为:\(\underset{D}{max}\ V(G,D) = -2 log 2 + 2 JSD \left ( P_{data}(x) || P_G(x) \right)\) 通过JS散度去度量生成样本和真实样本之间距离,理论上这个距离是减小的(两部分数据是重合的),但是可能会出现实际得到loss是0(JSD=log2)导致GAN的训练困难,因此提出WGAN使用新的距离度量方式去替换掉JSD。
参考
1、https://arxiv.org/pdf/1406.2661
2、https://developers.google.cn/machine-learning/gan/gan_structure