目录
1.1、概述
ZooKeeper 的搭建模式包括单机模式、集群模式和伪集群模式,分别适用于不同的场景和需求,从简单的单节点测试环境到复杂的多节点高可用生产环境。在实际部署时,应根据系统的可用性要求、数据量、并发负载等因素选择合适的部署模式。
- 单机模式(Standalone Mode)
在单机模式下,ZooKeeper 仅在一个单独的服务器节点上运行。这种模式主要用于开发测试环境,便于快速部署和调试。由于只有一个节点,没有数据冗余和故障转移机制,因此不具备高可用性。单节点故障会导致整个服务不可用,不适用于生产环境。 - 集群模式(Cluster Mode / Distributed Mode)
集群模式是 ZooKeeper 在生产环境中推荐使用的部署模式。它由多个(通常为奇数个,如 3、5、7 等)独立的服务器节点组成一个 ZooKeeper 集群。每个节点既是服务提供者又是服务消费者,它们之间通过心跳机制保持通信,并通过 ZAB(ZooKeeper Atomic Broadcast)协议实现数据的复制、同步和一致性保证。集群模式提供了高可用性、容错性和可扩展性,即使部分节点发生故障,只要集群中存活节点的数量大于等于半数(即形成"多数派"),ZooKeeper 集群就能继续对外提供服务。 - 伪集群模式(Pseudo-Distributed Mode / Local Cluster Mode)
伪集群模式是在单台物理或虚拟机上模拟多节点集群的部署方式。在同一台机器上启动多个 ZooKeeper 服务实例,每个实例配置不同的端口、数据目录和身份标识(如服务器ID)。尽管所有节点实际上运行在同一台机器上,但从逻辑上看,它们形成了一个小型的 ZooKeeper 集群,能够模拟集群模式的行为,包括数据复制、节点选举等。伪集群模式常用于本地开发和测试环境,便于在单机上模拟多节点集群环境,验证分布式协调逻辑。
1.2、系统环境
zookeeper服务器是用Java创建的,运行在JVM之上。需要安装JDK7以上版本(最好JDK8或以上)。如果服务器上没有JDK环境请自行安装,这里不在赘述。具体系统环境如下:
| 环境名称 | 版本号 |
|---|---|
| 操作系统 | CentOS Linux release 8.4.2105 |
| JDK | 17.0.7 |
| ZooKeeper | 3.8.4 |
1.3、部署流程
本文将在操作系统为CentOS Linux release 8.4.2105、Java环境为JDK17.0.7的服务器上部署ZooKeeper3.8.4版本,具体流程如下:
1.3.1、下载安装包
用户可以自行在Apache ZooKeeper官网 ,选择最新稳定版本进行下载。在国内,从官网的下载速度较慢,可以从博主提供的资源地址下载:资源下载,也可以选择国内镜像站下载,比如阿里镜像站:阿里镜像 。官网下载和阿里镜像下载如下:


下载文件一般为一个.tar.gz或.zip格式的压缩包,例如 apache-zookeeper-3.8.4-bin.tar.gz。下载后将安装包保存在服务器上的自定义目录下即可,比如:/usr/local/ZooKeeper。
1.3.2、解压文件
对于.tar.gz文件,可以使用以下命令进行文件解压。命令如下:
tar -xvzf apache-zookeeper-3.8.4-bin.tar.gz解压后,将会生成一个名为 apache-zookeeper-3.8.4-bin 的目录,该目录即为ZooKeeper的安装目录。为了方便配置,可以重命名 ZooKeeper 安装目录。解压后的目录结构如下:
1.3.3、创建数据目录和日志目录
根据ZooKeeper的配置要求,需要创建两个目录分别用于存放数据和日志。如果不需要单独存放日志时,data 和 logs 可以共用一个目录。命令如下:
mkdir /data/zookeeper/data
mkdir /data/zookeeper/logs1.3.4、配置ZooKeeper
进入 apache-zookeeper-3.8.4-bin/conf 目录,使用 cp zoo_sample.cfg zoo.cfg 命令拷贝 zoo_sample.cfg 到当前目录。拷贝结果如下:
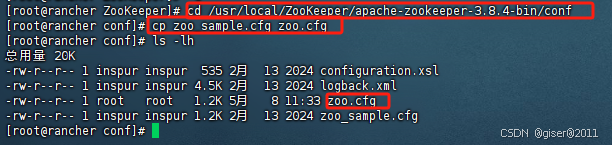
使用文本编辑器(如 vi、nano 或 emacs)打开 zoo.cfg 文件并进行如下配置:# 数据目录设置 dataDir=/data/zookeeper/data # 日志目录设置(如果需要单独存放日志) dataLogDir=/data/zookeeper/logs # 客户端连接端口 clientPort=2181。最终配置文件如下:

配置文件参数详解
- tickTime
时钟每跳的时间,默认值是2000毫秒,也就是2秒。 - initLimit
初始化集群时集群节点同步超时时间,默认值是10跳,也就是20秒。 - syncLimit
集群在运行过程中同步数据超时时间,默认值是5跳,也就是10秒。 - dataDir
数据存储位置。 - dataLogDir
日志存储位置。 - clientPort
ZooKeeper服务监听的端口,客户端连接的端口。 - maxClientCnxns
端连接线程池的数量,也就是最大客户端连接数量。
1.3.5、启动ZooKeeper服务
进入 apache-zookeeper-3.8.4-bin/bin 目录,执行 ./zkServer.sh start 命令启动 Zookeeper服务,启动成功后的效果如下:

1.3.6、连接和验证
验证单机模式运行状态可以通过查看日志或客户端连接的方式来验证,具体如下:
- 查看日志
检查指定的 dataLogDir 中的ZooKeeper日志文件,确认是否有启动成功的消息和其他异常信息。 - 使用命令行客户端
在ZooKeeper安装目录下,执行命令行客户端以连接到本地ZooKeeper服务:./zkCli.sh -server localhost:2181,如果连接成功,客户端将显示欢迎信息及提示符 zkshell:0。你可以尝试执行一些基本的命令,如 ls / 查看根节点下的子节点列表,验证ZooKeeper服务的响应。具体如下:
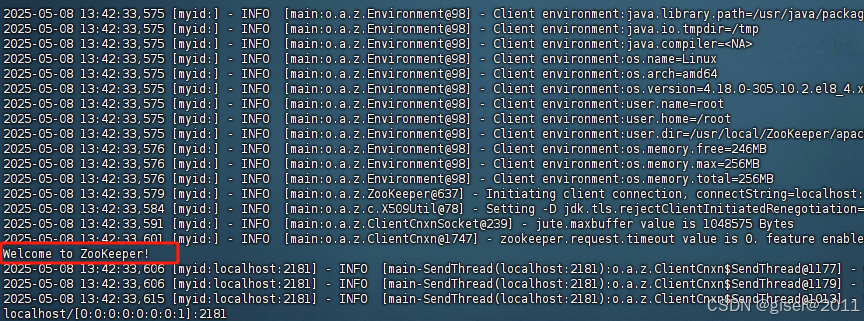
1.4、Zookeeper服务管理命令
1.4.1、启动Zookeeper服务
zkServer.sh start1.4.2、停止Zookeeper服务
zkServer.sh stop1.4.3、查看Zookeeper服务状态
zkServer.sh status1.4.4、重启Zookeeper服务
zkServer.sh restart