一、不是扫描件但不能搜索的原因
1. 情况一:文字被转成了"图形文字"
- 有些PDF文件虽然看起来像是文字,其实是图片或者矢量图格式,不能直接搜索。
2. 情况二:PDF被加密
-
有些PDF设置了"内容复制/提取"权限受限,即使你能阅读,但不能搜索、复制或选择文字。
-
这通常是加密的一种表现。
3. 情况三:PDF嵌入了字体,但不是真正的文本
- 有时PDF作者用的特殊软件或字体,会让文字显示正常,但实际上是不可识别的字符
二、解决方法
1. 方法一:使用OCR软件将内容转为可搜索文字
即使不是扫描件,也可以用 OCR 工具强制识别为文字。
推荐工具:
-
Adobe Acrobat Pro(有"识别文本"功能)
-
ABBYY FineReader
-
PaddleOCR(开源免费,适合懂技术的人)
-
PDF-XChange Editor(轻量好用,有OCR功能)
2. 方法二:查看是否有加密限制,并尝试解除
步骤(用Adobe Acrobat Pro为例):
-
打开PDF文件;
-
点击顶部菜单
文件(File)→属性(Properties); -
在"安全(Security)"标签下查看权限;
- 如果显示:"不能复制内容","不能提取内容"等限制,说明有加密。
如何解密:
-
若只是"权限密码"(不需要打开文件时输入密码),可以尝试以下方式解除:
-
使用 Smallpdf、iLovePDF、PDFCandy 等在线解密工具;
-
使用 Adobe Acrobat Pro:
-
打开文件;
-
使用"另存为"(Save As)时,取消安全设置;
-
前提是你知道权限密码,或权限设置很弱。
-
-
3. 方法三:复制部分文本,看是否能粘贴成正常文字
-
复制几行粘贴到记事本或Word里;
-
如果出现乱码或空白,说明PDF内容不可选或被加密/格式特殊。
三、小测试:快速判断是否可选中内容
-
鼠标拖动文件中的文字:
-
如果能高亮,说明不是扫描图;
-
如果不能,可能是扫描件或"图形文字";
-
-
如果能高亮但不能搜索,通常是权限限制或内容不是标准文字编码。
以上内容由 ai 生成,仅供记录与参考
四、笔者问题
菏泽统计年鉴2018.pdf 无法搜索关键字,而且也不是扫描图片 ,但根据PDF的底层信息,它可能采用了一种"图片+不可选文字"的方式嵌入内容 ,或者存在字体嵌入保护 或文本被转为图形对象的问题。
五、关键词无法搜索的常见原因:
-
PDF中的文字被转换成图形或路径(即使看起来像文字,实际上是"画"出来的,不能搜索)。
-
字体嵌入或加密,阻止复制和搜索。
-
文字层被隐藏或丢失。
-
使用了不标准的编码方式或旧格式导出
**六、**解决方法建议
方法一:用Adobe Acrobat OCR识别(适合官方方式)
-
用 Adobe Acrobat 打开该 PDF。
-
菜单栏选择:
工具>扫描和OCR>识别文本。 -
识别后保存,这样文字就可以被搜索和复制了。
效果不好,只能识别后是空白,且文字识别错误率高
方法二:用免费的工具进行OCR识别
-
使用网站:Free Online OCR - Image to text and PDF to Doc converter
-
或用免费的桌面软件:
-
PDF24 Creator(支持OCR识别和输出可搜索PDF)
-
FreeOCR(适合基础识别)
-
-
笔者安装 PDF24 Creator 后,仅识别出200多个汉字,效果不好
方法三:用Python批量处理(适合技术用户)本文讲解重点
如果你会用Python,可以用tesserocr或PyMuPDF结合OCR处理整个PDF文档
一)版本1
1. 功能说明
该 Python 脚本会:
1)用 PyMuPDF 将 PDF 每页渲染为图像;
2)用 pytesseract 识别图像中的中文文字;
3)用 pytesseract.image_to_pdf_or_hocr() 生成带文字层的 PDF;
4)合并成一个新的 可搜索 PDF 文件。
2. 环境依赖
1)打开 powershell
win+r 打开运行, 搜索powershell 打开 Windows PowerShell
开头有"PS",就代表打开的是 powershell 没错

2)确保安装好以下 python库:pytesseract、pymupdf 和 pillow
在 powershell 中输入:
bash
C:\Users\19025\AppData\Local\Programs\Python\Python313\python.exe -m pip install pytesseract pymupdf pillow
# C:\Users\19025\AppData\Local\Programs\Python\Python313\ 替换为本地 python 环境的路径(1) 为什么要用本地python环境?
因为还要安装Tesseract OCR 引擎本体,发现好像只能在本地环境运行才能链接Tesseract OCR
(2) 如何找到本地 python 环境路径?
在powershell中输入
bash
python --version找到本地 python 版本

在任务栏里搜索 python,找到对应的 python 版本,笔者本地只安装了一个版本,所以不用找
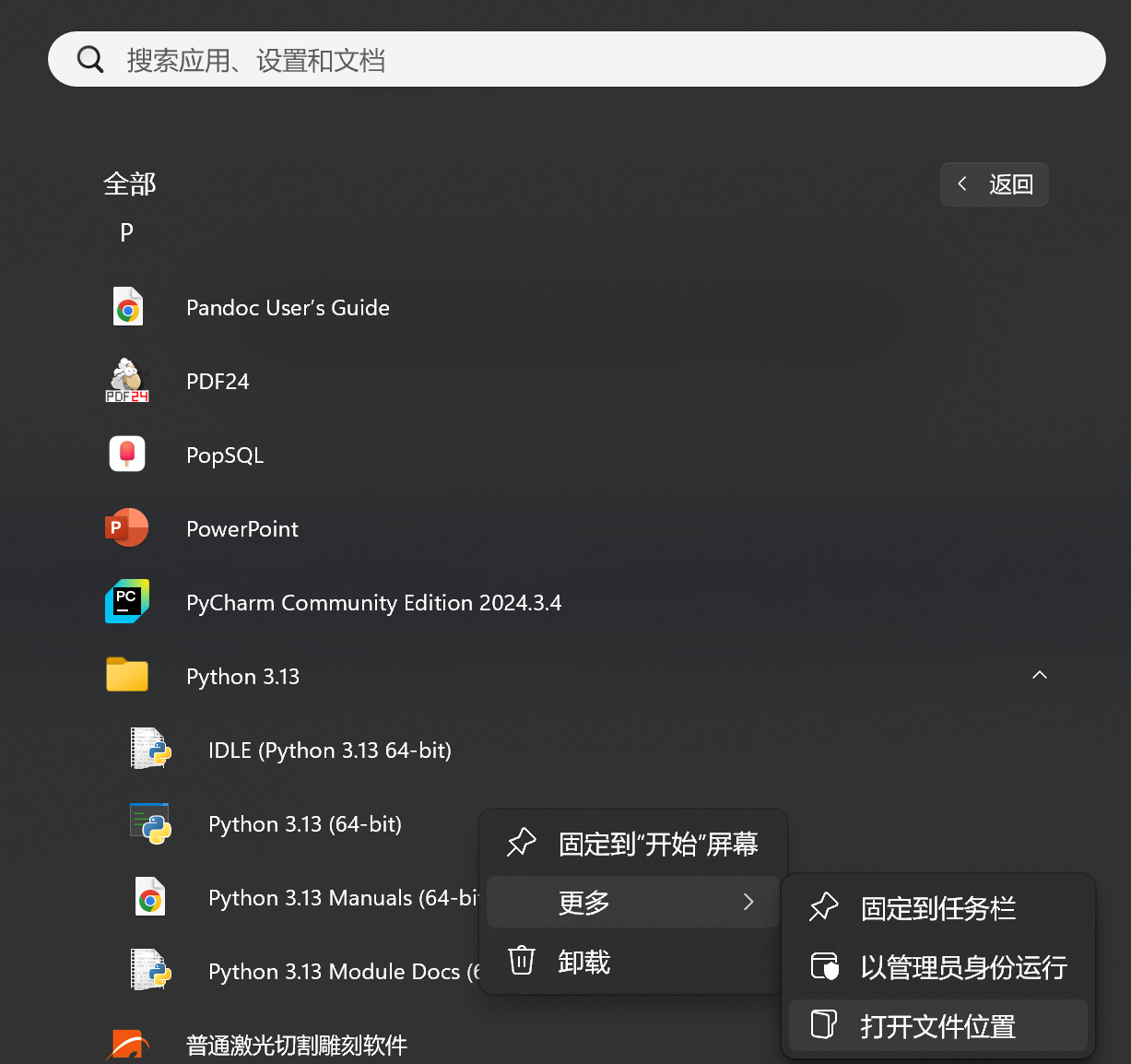
打开文件位置后,这里出现的是快捷方式的路径

右击 python 3.13,点击 打开文件所在的位置
这里就是python主程序所在的路径了
复制路径,替换即可

3)安装 Tesseract OCR 引擎本体,并配置中文语言包
(1)安装 Tesseract:
Windows 下载地址:https://github.com/tesseract-ocr/tesseract/releases

点击 .exe,自动开始下载
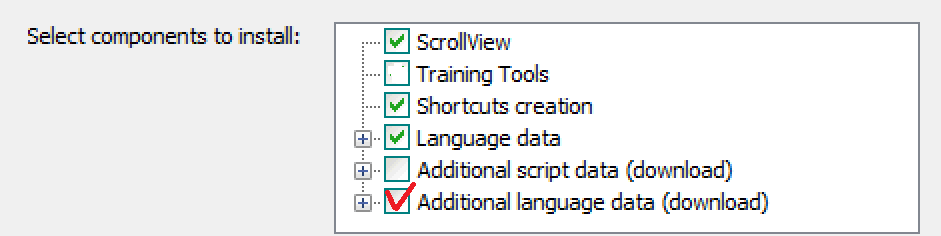
下载完成后,点击安装包开始安装
安装时,取消勾选"Training Tools",勾选"Additional language data(download)",最好别修改安装路径
安装完成后,进入:
bash
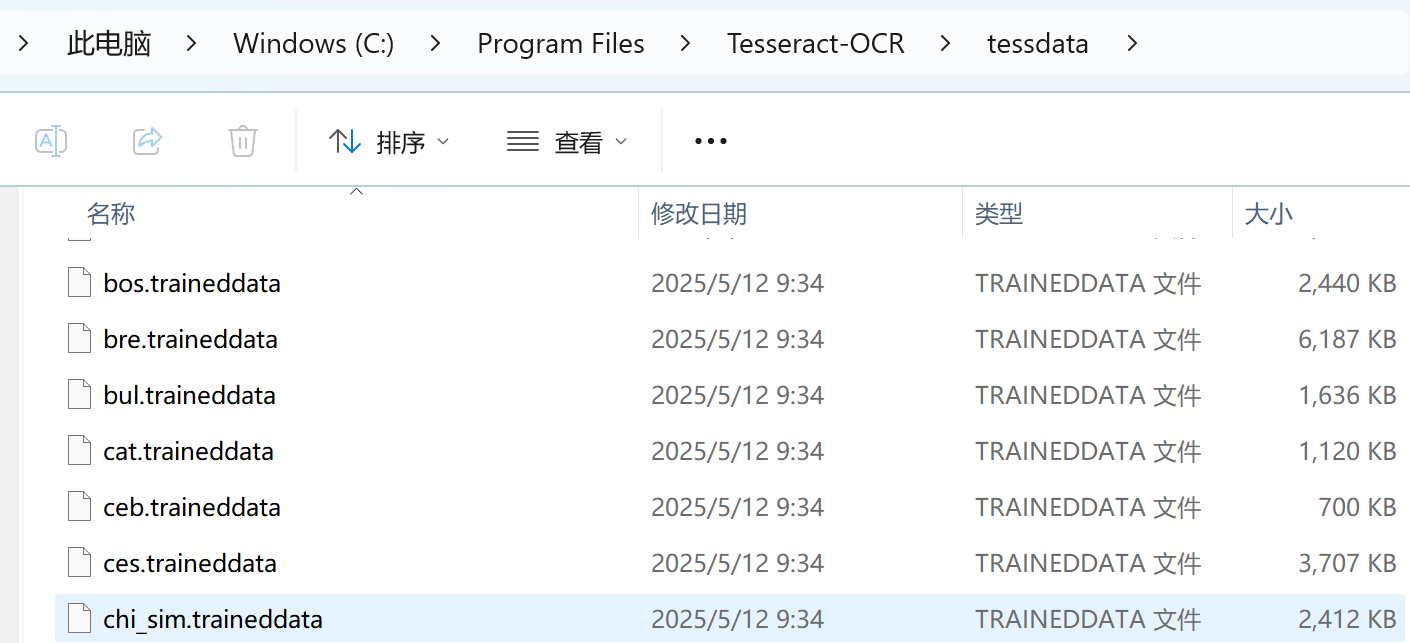
C:\Program Files\Tesseract-OCR\tessdata如果你能看到 chi_sim.traineddata 文件,就说明中文支持安装成功。
(2)添加系统环境变量
A. 复制 Tesseract 的安装路径
默认安装路径是:
bash
C:\Program Files\Tesseract-OCRB. 添加到系统PATH中
Windows 11 / 10 操作:
a. 在"开始"菜单搜索 "环境变量",点击"编辑系统环境变量";
b. 在弹出窗口中点击右下角"环境变量(N)...";
c. 在"系统变量"区域找到 Path,点击"编辑";
d. 点击"新建",粘贴路径:
bash
C:\Program Files\Tesseract-OCRe. 点击"确定"保存所有窗口。
C. 验证是否配置成功
a. 打开 命令提示符(cmd),输入:
bash
tesseract -vb. 如果输出版本信息,说明配置成功,例如:
bash
tesseract v5.5.0.20241111
leptonica-1.85.0
...3. python 脚本
bash
import fitz # PyMuPDF
import pytesseract
from PIL import Image
import io
# 打开原始PDF
input_pdf_path = "D:/test/菏泽统计年鉴2018.pdf"
output_pdf_path = "D:/test/菏泽统计年鉴2018_OCR.pdf"
doc = fitz.open(input_pdf_path)
# 创建空的输出PDF
ocr_doc = fitz.open()
# 遍历每页进行OCR识别
for i, page in enumerate(doc):
print(f"OCR 第 {i + 1} 页...")
# 渲染页面为图片
pix = page.get_pixmap(dpi=300)
img = Image.open(io.BytesIO(pix.tobytes("png")))
# 使用 Tesseract OCR 识别中文,并生成 PDF 格式
pdf_bytes = pytesseract.image_to_pdf_or_hocr(img, lang='chi_sim', extension='pdf')
ocr_page = fitz.open("pdf", pdf_bytes)
# 插入到新PDF中
ocr_doc.insert_pdf(ocr_page)
# 保存新PDF
ocr_doc.save(output_pdf_path)
ocr_doc.close()
print(f"✅ OCR 处理完成,输出文件:{output_pdf_path}")存在问题:现在搜索只能搜到单个字 ,搜索多个字的词组(如"进口额")搜不到
这是因为:Tesseract 生成的 OCR PDF 中文本层之间的汉字是分开的,每个字之间实际上被插入了不可见字符(如空格、换行、透明块)。
二)版本2
扫描版统计年鉴 PDF,通过 OCR 转为可搜索文本,然后批量搜索关键词(支持词组),并输出在哪一页找到了
- 功能说明
-
使用
PyMuPDF打开 PDF; -
每页图片化,用
TesseractOCR 识别中文; -
提取 OCR 文本并清洗;
-
搜索关键词(支持词组和模糊匹配);
-
输出匹配结果和所在页码。
- 脚本代码
bash
import fitz # PyMuPDF
import pytesseract
from PIL import Image
import io
import re
# ====== 设置路径 ======
input_pdf_path = "D:/test/菏泽统计年鉴2018.pdf"
output_pdf_path = "D:/test/菏泽统计年鉴2018_OCR1.pdf"
keyword_file = "D:/test/keywords.txt" # 每行一个关键词
# ====== 加载关键词 ======
with open(keyword_file, "r", encoding="utf-8") as f:
keywords = [line.strip() for line in f if line.strip()]
# ====== 打开原始 PDF ======
doc = fitz.open(input_pdf_path)
ocr_doc = fitz.open()
# ====== OCR 识别每一页并生成新 PDF ======
print("[*] 开始 OCR 处理...")
for i, page in enumerate(doc):
print(f" - 正在识别第 {i+1} 页...")
pix = page.get_pixmap(dpi=300)
img = Image.open(io.BytesIO(pix.tobytes("png")))
# OCR 识别中文,输出 PDF 页
pdf_bytes = pytesseract.image_to_pdf_or_hocr(img, lang='chi_sim', extension='pdf')
ocr_page = fitz.open("pdf", pdf_bytes)
ocr_doc.insert_pdf(ocr_page)
# 保存 OCR 后的 PDF
ocr_doc.save(output_pdf_path)
ocr_doc.close()
doc.close()
print(f"[✓] OCR 完成,已保存到:{output_pdf_path}")
# ====== 提取文本并搜索关键词 ======
print("\n[*] 正在搜索关键词...\n")
ocr_doc = fitz.open(output_pdf_path)
# 记录匹配结果
results = []
for page_num, page in enumerate(ocr_doc, start=1):
text = page.get_text()
clean_text = re.sub(r"\s+", "", text) # 清洗不可见字符
for kw in keywords:
if kw in clean_text:
results.append((kw, page_num, "精确"))
else:
pattern = ".*".join(list(kw)) # 模糊匹配:每个字之间允许有干扰
if re.search(pattern, clean_text):
results.append((kw, page_num, "模糊"))
ocr_doc.close()
# ====== 输出结果 ======
if results:
for kw, page_num, match_type in results:
print(f"[{match_type}] 第 {page_num} 页 找到:{kw}")
else:
print("未找到任何关键词。")3. keywords.txt 示例
放在 D:/test/keywords.txt,每行一个关键词:
bash
地区生产总值
固定资产投资总额
总人口
第一产业增加值
第二产业增加值
第三产业增加值
地方财政收入
进口额
出口额
全年水资源总量
人均粮食产量
粮食产量
能源消费总量
人均用水量
森林覆盖率
耕地面积
二氧化硫年均浓度
细颗粒物年均浓度
化肥施用量
人口密度
空气质量综合指数附上查找结果:查找.txt
bash
[精确] 第 7 页 找到:地区生产总值
[精确] 第 7 页 找到:总人口
[模糊] 第 11 页 找到:地区生产总值
[模糊] 第 11 页 找到:总人口
[模糊] 第 11 页 找到:第一产业增加值
[模糊] 第 11 页 找到:第二产业增加值
[模糊] 第 11 页 找到:第三产业增加值
[精确] 第 11 页 找到:地方财政收入
[模糊] 第 12 页 找到:地区生产总值
[模糊] 第 12 页 找到:总人口
[模糊] 第 12 页 找到:进口额
[模糊] 第 12 页 找到:出口额
[模糊] 第 13 页 找到:总人口
[模糊] 第 13 页 找到:进口额
[精确] 第 14 页 找到:地区生产总值
[模糊] 第 14 页 找到:固定资产投资总额
[模糊] 第 14 页 找到:总人口
[模糊] 第 14 页 找到:第一产业增加值
[模糊] 第 14 页 找到:进口额
[模糊] 第 14 页 找到:出口额
[模糊] 第 17 页 找到:总人口
[模糊] 第 17 页 找到:人均用水量
[模糊] 第 18 页 找到:全年水资源总量
[模糊] 第 18 页 找到:能源消费总量
[精确] 第 21 页 找到:地区生产总值
[精确] 第 21 页 找到:第一产业增加值
[精确] 第 21 页 找到:第二产业增加值
[精确] 第 21 页 找到:第三产业增加值
[模糊] 第 21 页 找到:粮食产量
[精确] 第 22 页 找到:地区生产总值
[模糊] 第 23 页 找到:固定资产投资总额
[模糊] 第 23 页 找到:地方财政收入
[模糊] 第 23 页 找到:进口额
[模糊] 第 23 页 找到:出口额
[模糊] 第 24 页 找到:总人口
[模糊] 第 24 页 找到:进口额
[模糊] 第 24 页 找到:出口额
[模糊] 第 24 页 找到:二氧化硫年均浓度
[模糊] 第 24 页 找到:细颗粒物年均浓度
[精确] 第 29 页 找到:地区生产总值
[精确] 第 29 页 找到:总人口
[精确] 第 29 页 找到:第一产业增加值
[精确] 第 29 页 找到:第二产业增加值
[精确] 第 29 页 找到:第三产业增加值
[模糊] 第 29 页 找到:耕地面积
[精确] 第 29 页 找到:人口密度
[模糊] 第 31 页 找到:固定资产投资总额
[模糊] 第 32 页 找到:总人口
[精确] 第 33 页 找到:地区生产总值
[精确] 第 33 页 找到:第一产业增加值
[精确] 第 33 页 找到:第二产业增加值
[精确] 第 33 页 找到:第三产业增加值
[精确] 第 34 页 找到:地区生产总值
[精确] 第 37 页 找到:总人口
[精确] 第 38 页 找到:化肥施用量
[精确] 第 40 页 找到:耕地面积
[精确] 第 41 页 找到:耕地面积
[模糊] 第 52 页 找到:粮食产量
[模糊] 第 280 页 找到:总人口
[模糊] 第 286 页 找到:总人口
[精确] 第 445 页 找到:进口额
[精确] 第 445 页 找到:出口额
[精确] 第 533 页 找到:地区生产总值
[模糊] 第 533 页 找到:总人口
[模糊] 第 533 页 找到:第一产业增加值
[模糊] 第 533 页 找到:第二产业增加值
[模糊] 第 533 页 找到:第三产业增加值
[精确] 第 534 页 找到:地区生产总值
[模糊] 第 534 页 找到:第一产业增加值
[模糊] 第 534 页 找到:第二产业增加值
[模糊] 第 534 页 找到:第三产业增加值
[模糊] 第 535 页 找到:地方财政收入
[模糊] 第 536 页 找到:总人口
[模糊] 第 537 页 找到:粮食产量
[模糊] 第 538 页 找到:粮食产量
[模糊] 第 540 页 找到:总人口
[模糊] 第 541 页 找到:总人口
[模糊] 第 544 页 找到:地区生产总值
[精确] 第 544 页 找到:总人口
[模糊] 第 544 页 找到:第一产业增加值
[模糊] 第 544 页 找到:第二产业增加值
[精确] 第 544 页 找到:粮食产量
[精确] 第 544 页 找到:人口密度
[模糊] 第 545 页 找到:地区生产总值
[模糊] 第 545 页 找到:第二产业增加值
[模糊] 第 545 页 找到:第三产业增加值
[模糊] 第 551 页 找到:地区生产总值
[精确] 第 551 页 找到:总人口
[精确] 第 551 页 找到:第一产业增加值
[精确] 第 551 页 找到:第二产业增加值
[精确] 第 551 页 找到:第三产业增加值
[模糊] 第 553 页 找到:固定资产投资总额
[精确] 第 553 页 找到:粮食产量
[模糊] 第 553 页 找到:能源消费总量
[模糊] 第 554 页 找到:全年水资源总量
[精确] 第 554 页 找到:粮食产量
[模糊] 第 554 页 找到:耕地面积
[模糊] 第 556 页 找到:固定资产投资总额
[模糊] 第 556 页 找到:总人口
[模糊] 第 557 页 找到:总人口
[精确] 第 557 页 找到:进口额
[精确] 第 557 页 找到:出口额
[模糊] 第 558 页 找到:总人口
[模糊] 第 559 页 找到:总人口
[模糊] 第 559 页 找到:出口额
[模糊] 第 561 页 找到:总人口
[模糊] 第 561 页 找到:出口额
[模糊] 第 562 页 找到:总人口
[精确] 第 562 页 找到:全年水资源总量
[精确] 第 562 页 找到:人均用水量
[模糊] 第 563 页 找到:地区生产总值
[模糊] 第 563 页 找到:总人口
[精确] 第 563 页 找到:能源消费总量
[模糊] 第 563 页 找到:细颗粒物年均浓度
[模糊] 第 564 页 找到:总人口
[模糊] 第 564 页 找到:地方财政收入
[模糊] 第 564 页 找到:能源消费总量
[模糊] 第 565 页 找到:总人口
[模糊] 第 566 页 找到:地区生产总值
[模糊] 第 566 页 找到:总人口
[模糊] 第 566 页 找到:地方财政收入
[模糊] 第 566 页 找到:全年水资源总量
[模糊] 第 566 页 找到:人均用水量
[模糊] 第 567 页 找到:地区生产总值
[精确] 第 568 页 找到:总人口
[精确] 第 568 页 找到:第一产业增加值
[精确] 第 568 页 找到:第二产业增加值
[精确] 第 568 页 找到:第三产业增加值
[模糊] 第 569 页 找到:总人口
[模糊] 第 569 页 找到:粮食产量
[模糊] 第 570 页 找到:地区生产总值
[模糊] 第 570 页 找到:第一产业增加值
[精确] 第 570 页 找到:粮食产量
[精确] 第 570 页 找到:森林覆盖率
[精确] 第 571 页 找到:地区生产总值
[模糊] 第 571 页 找到:固定资产投资总额
[模糊] 第 571 页 找到:总人口
[模糊] 第 571 页 找到:进口额
[模糊] 第 572 页 找到:进口额
[模糊] 第 572 页 找到:出口额
[模糊] 第 574 页 找到:森林覆盖率
[精确] 第 575 页 找到:地区生产总值- 总结:没满足直接在 .pdf 中搜索词组的需求