名人说:路漫漫其修远兮,吾将上下而求索。------ 屈原《离骚》
创作者:Code_流苏(CSDN) (一个喜欢古诗词和编程的Coder😊)目录
- 一、问答系统概述
- 1.问答系统的工作原理
- [2. 问答系统的典型应用场景](#2. 问答系统的典型应用场景)
- 二、问答系统分类
- [1. 基于检索的问答系统](#1. 基于检索的问答系统)
- [2. 基于生成的问答系统](#2. 基于生成的问答系统)
- [3. 两种方法的对比](#3. 两种方法的对比)
- 三、使用BERT构建问答系统
- [1. SQuAD数据集简介](#1. SQuAD数据集简介)
- [2. 微调BERT进行问答任务](#2. 微调BERT进行问答任务)
- 四、代码练习:实现一个基于BERT的问答系统
- [1. 环境准备](#1. 环境准备)
- [2. 构建基本问答模型](#2. 构建基本问答模型)
- [3. 使用预训练模型测试问答系统](#3. 使用预训练模型测试问答系统)
- [4. 微调BERT模型用于自定义问答任务](#4. 微调BERT模型用于自定义问答任务)
- [5. 构建完整的端到端问答应用](#5. 构建完整的端到端问答应用)
- 五、问答系统的未来发展
- 六、总结与实践建议
- 参考资料
👋 专栏介绍 : Python星球日记专栏介绍(持续更新ing)
✅ 上一篇 : 《Python星球日记》 第71天:命名实体识别(NER)与关系抽取
欢迎回到Python星球🪐日记 !今天是我们旅程的第72天。
在前面的日子里,我们深入学习了自然语言处理的基础知识,包括文本预处理、词向量、Transformer架构和各种预训练模型。今天,我们将探索问答系统 这一NLP的重要应用,以及如何结合信息检索技术构建智能问答系统。
一、问答系统概述
问答系统(Question Answering System)是一种能够理解用户的自然语言问题并给出准确答案的人工智能系统。从早期的规则型系统到如今基于深度学习的系统,问答技术已经取得了飞跃性的进步。
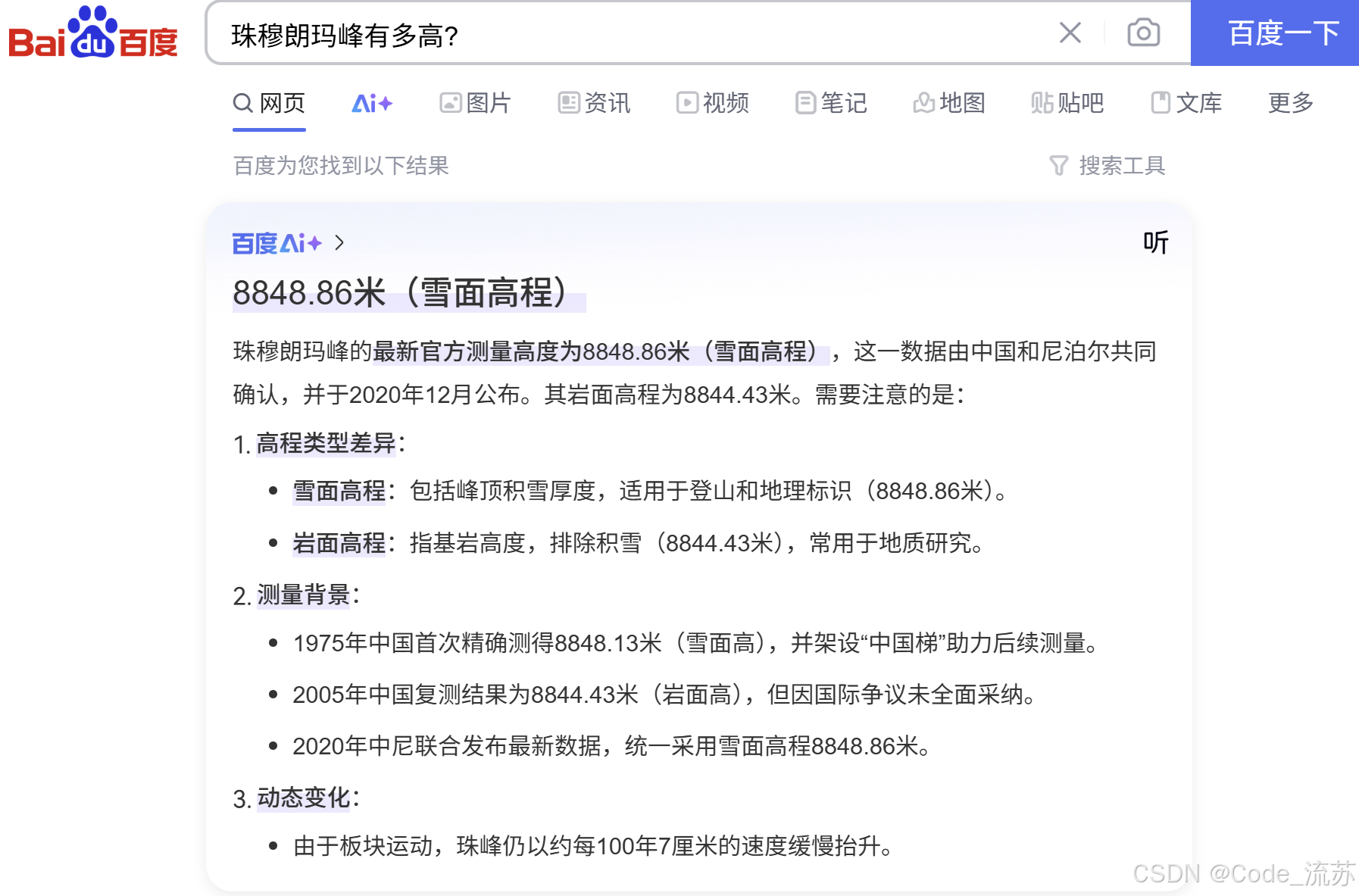
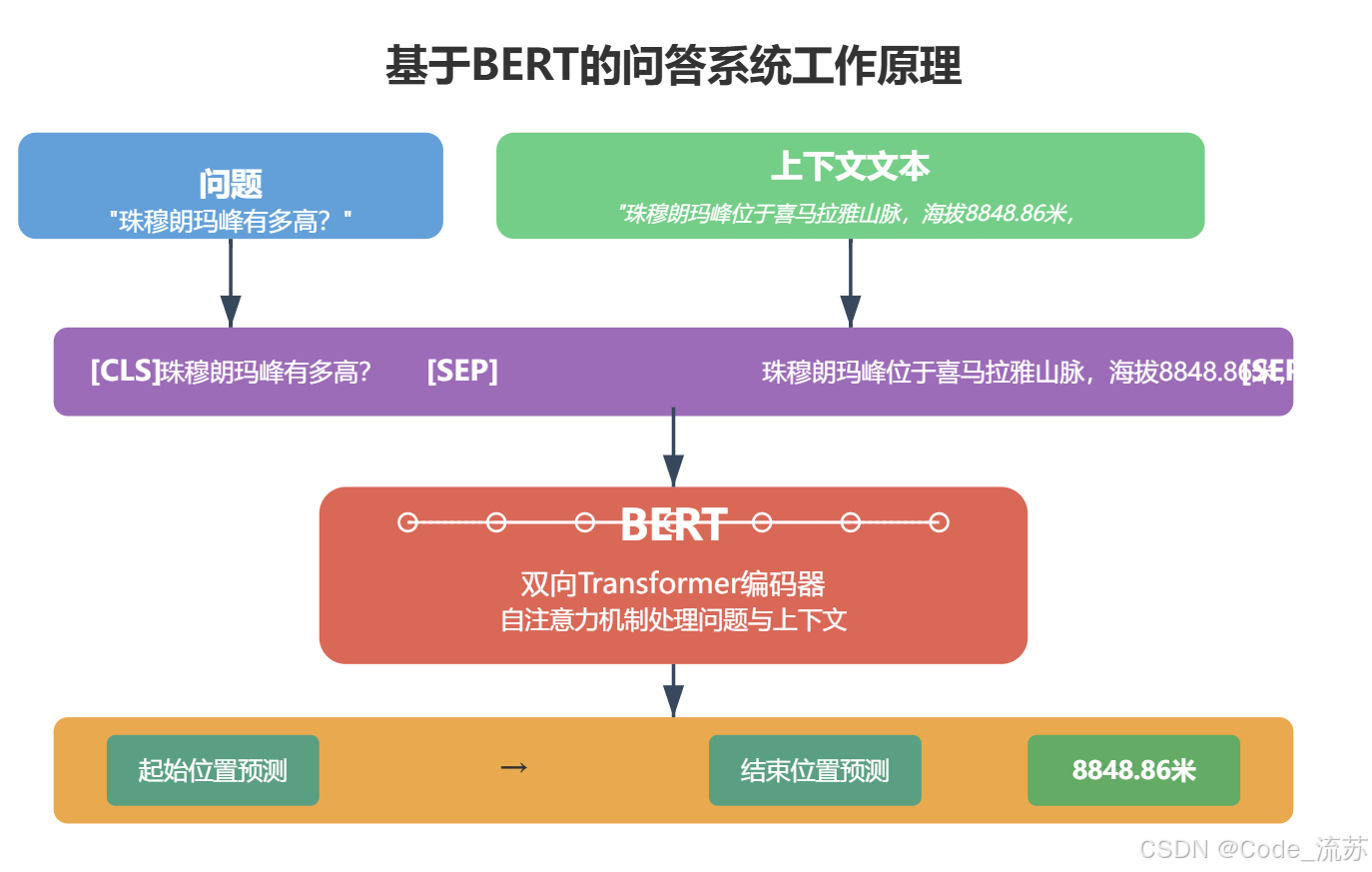
当你使用搜索引擎查询"珠穆朗玛峰有多高?"时,不再需要翻阅多个网页,而是直接得到"8848.86米"的精准答案,这就是问答系统的魅力所在。
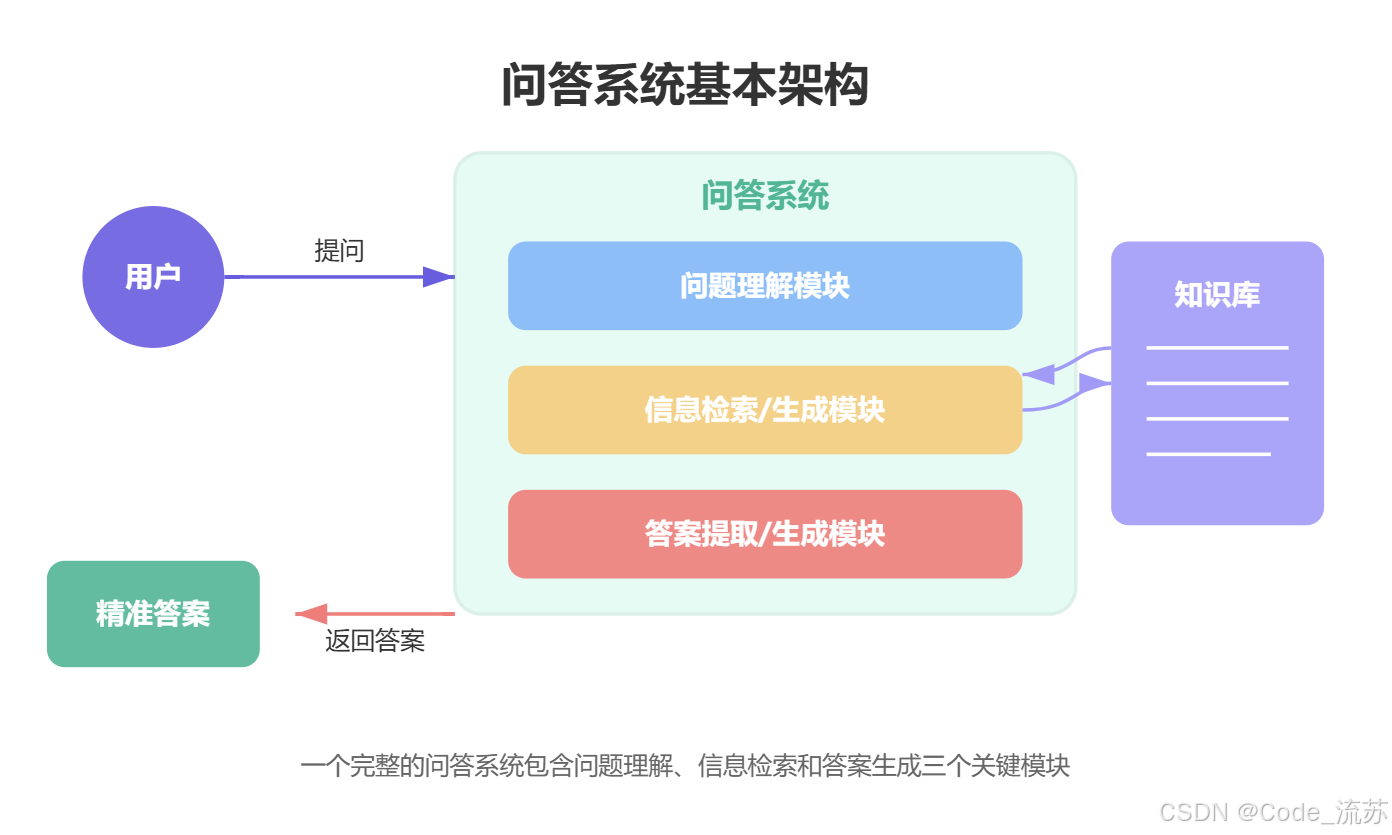
1.问答系统的工作原理
问答系统通常包含三个核心组件:问题理解 、信息检索/生成 和答案提取/生成。系统通过分析用户问题的语义,从知识库中检索相关信息,然后提取或生成最终答案。
2. 问答系统的典型应用场景
- 客服机器人:自动回答用户常见问题
- 智能搜索引擎:直接给出问题答案,而非仅列出网页链接
- 个人助手:Siri、Alexa等智能助手中的问答功能
- 医疗诊断辅助:回答医疗相关问题,辅助临床决策
- 教育辅导:回答学生的学习问题,提供个性化辅导
二、问答系统分类
根据答案生成方式的不同,问答系统主要分为两类:基于检索的问答系统 和基于生成的问答系统。
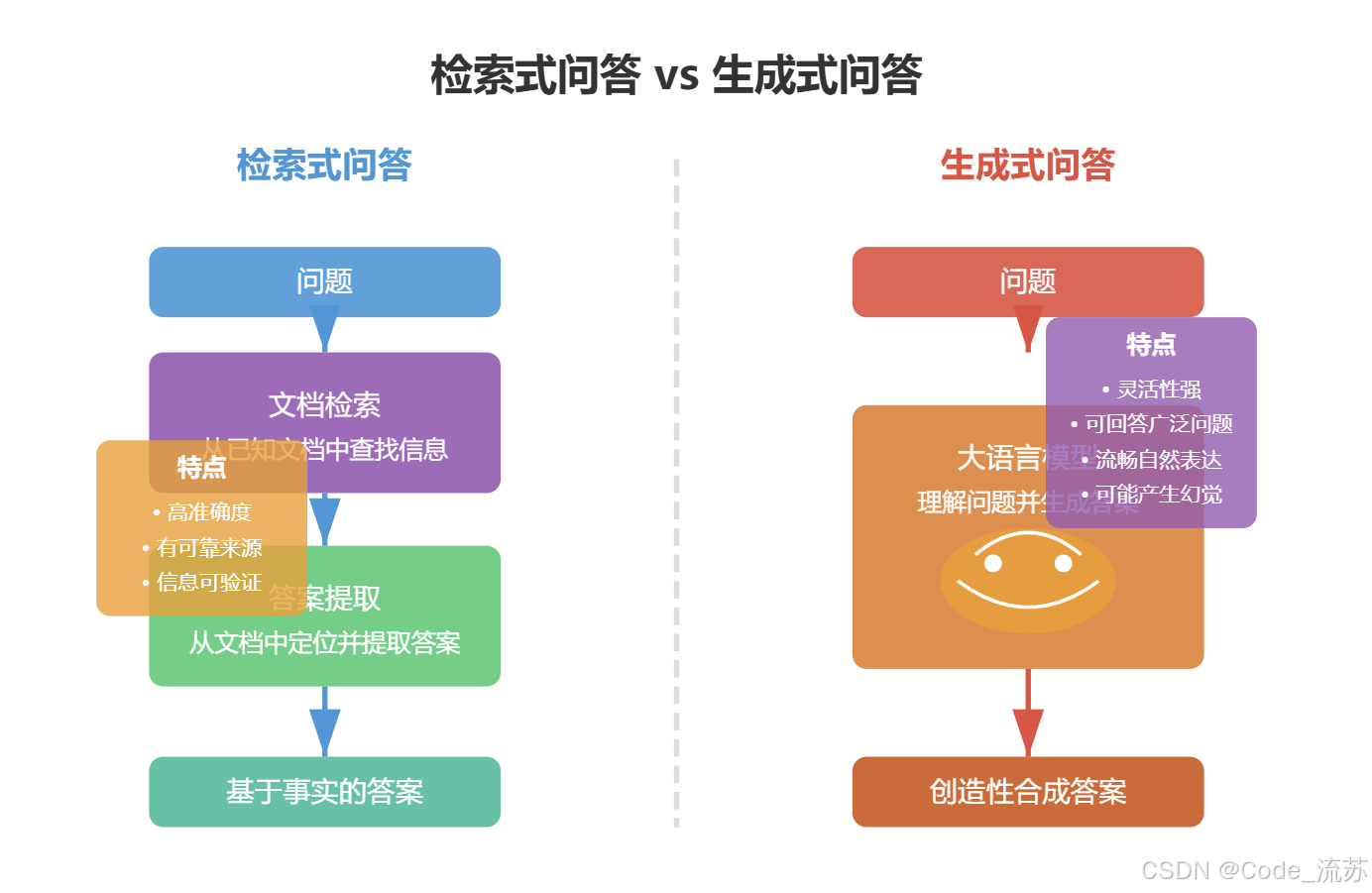
1. 基于检索的问答系统
基于检索的问答系统 (Retrieval-based QA)工作原理是从大量已有文档中检索 并提取 答案。这种方法确保答案有明确的来源依据,也称为抽取式问答。
工作流程主要包含三个步骤:
- 问题处理:分析用户问题,确定问题类型和关键词
- 文档检索:使用信息检索技术找到相关文档
- 答案提取:从检索到的文档中精确定位并提取答案片段
这类系统的关键在于两项核心技术:
- 信息检索(IR):使用BM25、TF-IDF等算法检索相关文档
- 阅读理解(MRC):从检索文档中精确定位答案位置
python
# 基于检索的问答系统简化示例
def retrieval_based_qa(question, documents):
# 步骤1:检索相关文档
relevant_docs = retrieve_documents(question, documents)
# 步骤2:从相关文档中提取答案
answer = extract_answer(question, relevant_docs)
return answer2. 基于生成的问答系统
基于生成的问答系统 (Generation-based QA)通过生成模型直接创建答案文本,而不是从已有文档中提取。这类系统通常基于大型语言模型(LLM),如GPT系列、LLaMA等。
生成式问答的优势在于:
- 灵活性强:可以回答开放性问题,生成流畅自然的答案
- 知识融合:能结合训练数据中的广泛知识
- 处理复杂问题:能回答假设性问题或需要推理的问题
但也存在一些挑战:
- 幻觉问题:可能生成看似合理但实际不准确的内容
- 控制困难:难以精确控制答案的范围和内容
- 缺乏透明度:难以追溯答案来源
python
# 基于生成的问答系统简化示例
def generation_based_qa(question, model):
# 构建提示
prompt = f"问题: {question}\n回答: "
# 使用预训练模型生成答案
answer = model.generate(prompt)
return answer3. 两种方法的对比
| 特性 | 基于检索的问答 | 基于生成的问答 |
|---|---|---|
| 答案来源 | 从文档中提取 | 模型生成 |
| 答案范围 | 受限于已有文档 | 开放性生成 |
| 准确性 | 高(有明确来源) | 可能出现幻觉 |
| 灵活性 | 受限 | 灵活 |
| 可追溯性 | 强 | 弱 |
| 适用场景 | 事实型问题、领域专业问题 | 开放性问题、推理问题 |
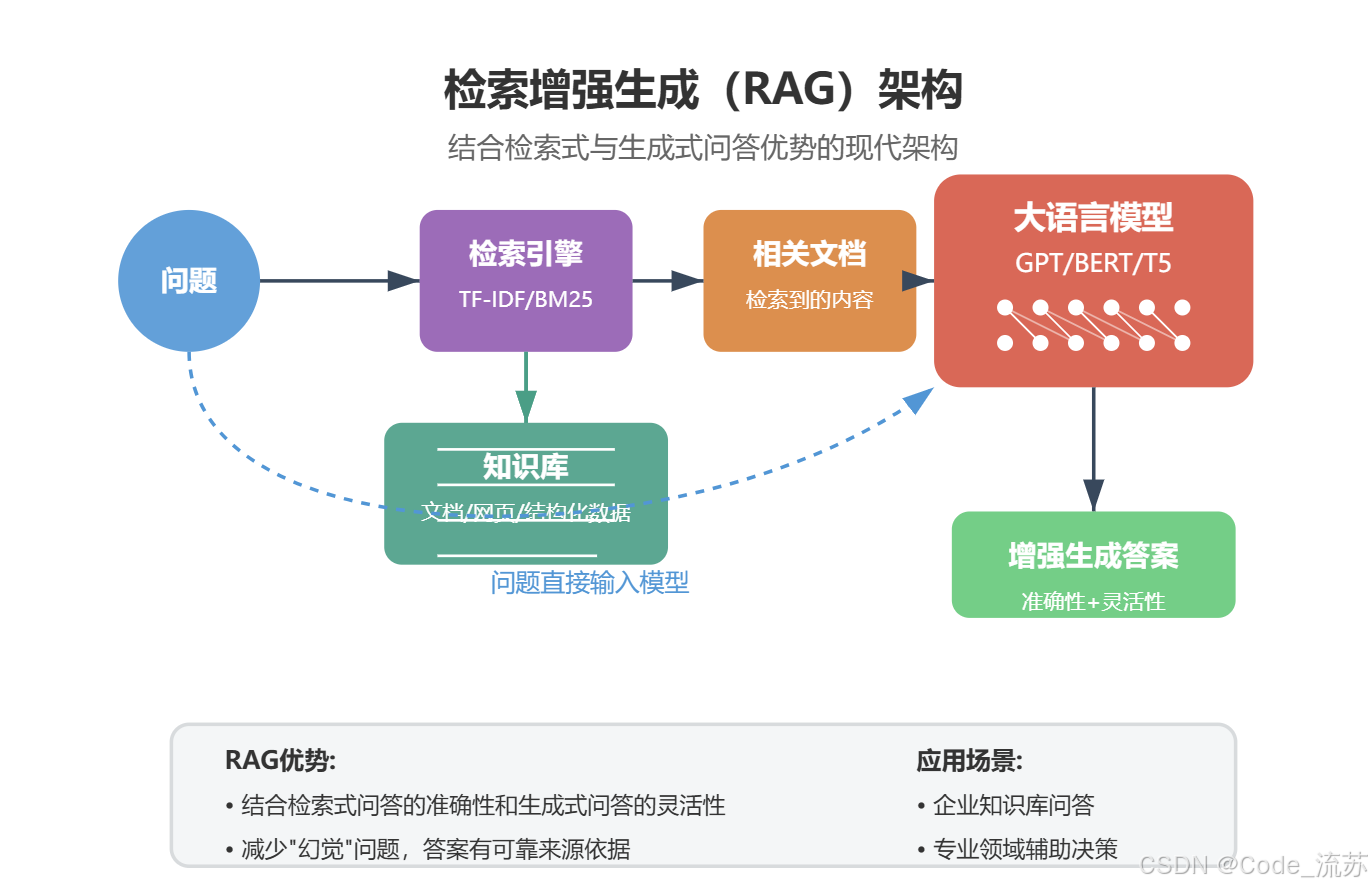
现代问答系统通常会结合这两种方法的优势,形成检索增强生成(RAG)架构,既保证答案的准确性,又提供灵活的表达能力。
三、使用BERT构建问答系统
1. SQuAD数据集简介
SQuAD(Stanford Question Answering Dataset)是构建和评估问答系统的标准数据集。它包含了从维基百科文章中提取的10万多个问题-答案对。
SQuAD的特点:
- 篇章式问答:每个问题都基于一段文本,答案是文本中的一个片段
- 人工标注:由人类标注者创建高质量的问答对
- 开放获取:公开可用,便于研究和比较不同模型
示例:
py
{
"data": [
{
"title": "Super_Bowl_50",
"paragraphs": [
{
"context": "Super Bowl 50 was an American football game to determine the champion of the National Football League (NFL) for the 2015 season. The American Football Conference (AFC) champion Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers 24--10 to earn their third Super Bowl title.",
"qas": [
{
"question": "Which NFL team won Super Bowl 50?",
"id": "56be4db0acb8001400a502ec",
"answers": [
{
"text": "Denver Broncos",
"answer_start": 177
}
]
},
{
"question": "What was the score of Super Bowl 50?",
"id": "56be4db0acb8001400a502ed",
"answers": [
{
"text": "24--10",
"answer_start": 249
}
]
}
]
}
]
}
]
}2. 微调BERT进行问答任务
BERT (B idirectional E ncoder R epresentations from Transformers)模型因其强大的上下文理解能力,成为构建问答系统的绝佳选择。通过在SQuAD数据集上微调BERT,我们可以创建一个高性能的问答系统。
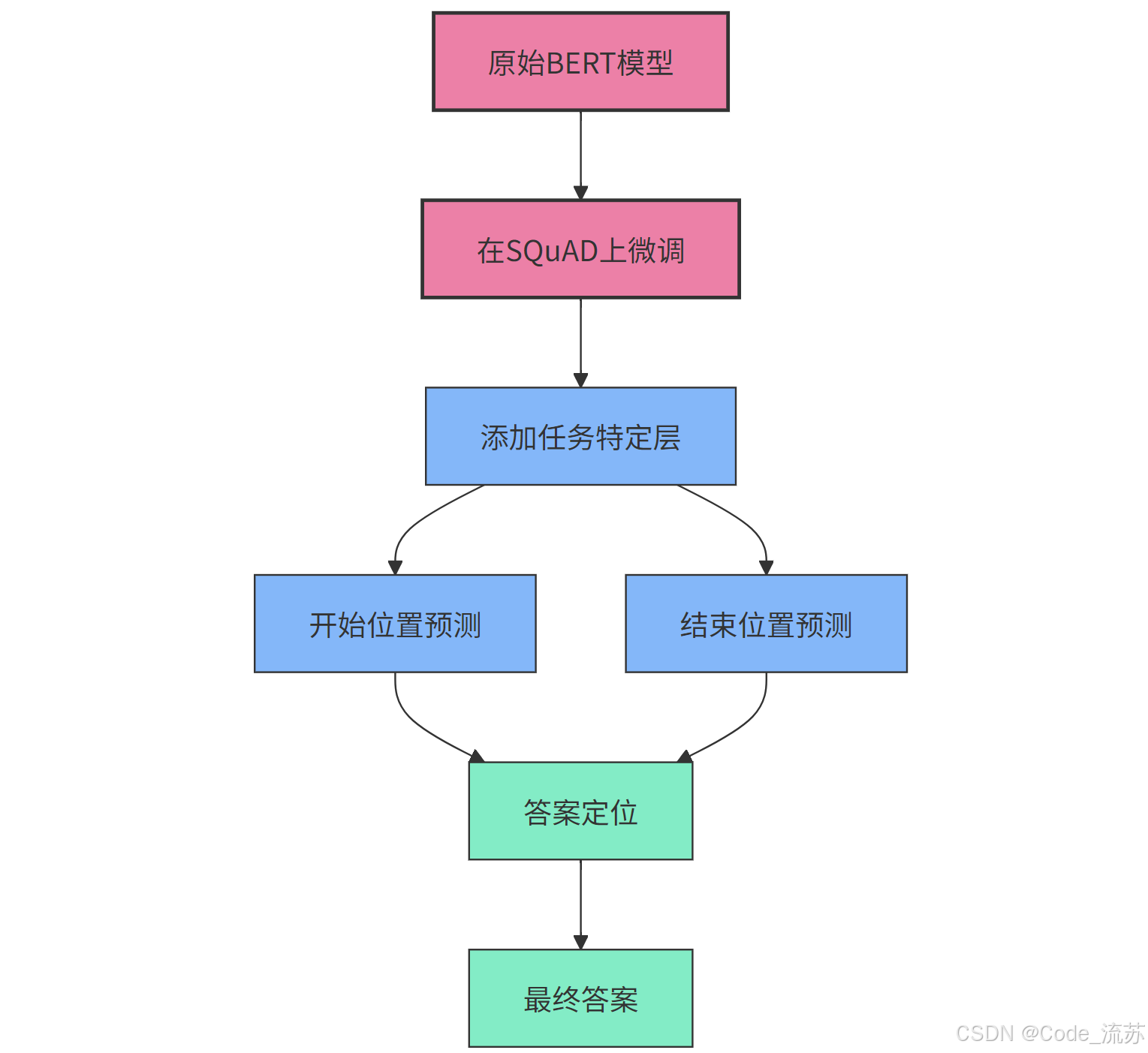
BERT模型针对问答任务的微调过程包括:
- 输入格式化 :将问题和上下文拼接成单一序列
[CLS] 问题 [SEP] 上下文 [SEP] - 添加任务特定层 :在BERT顶层添加两个全连接层,分别用于预测答案的开始位置 和结束位置
- 训练目标:最大化正确答案跨度的概率
- 推理过程:对所有可能的答案跨度计算概率,选择概率最高的作为最终答案
微调BERT进行问答任务的关键技术细节:
- 注意力机制:使BERT能够捕捉问题与上下文之间的复杂关系
- 上下文嵌入:每个单词的表示包含了整个序列的上下文信息
- 跨度预测:不是生成答案,而是预测答案在文本中的起始和结束位置
四、代码练习:实现一个基于BERT的问答系统
下面我们将通过实际代码,实现一个基于BERT的问答系统。我们将使用Hugging Face的Transformers库,它提供了丰富的预训练模型和便捷的API。
1. 环境准备
首先安装必要的库:
python
# 安装必要的库
!pip install transformers datasets torch pandas matplotlib2. 构建基本问答模型
python
import torch
from transformers import BertTokenizer, BertForQuestionAnswering
import numpy as np
class BertQASystem:
def __init__(self, model_name="bert-base-uncased"):
"""
初始化BERT问答系统
参数:
model_name: 使用的预训练模型名称
"""
# 加载预训练的tokenizer
self.tokenizer = BertTokenizer.from_pretrained(model_name)
# 加载预训练的问答模型
self.model = BertForQuestionAnswering.from_pretrained(model_name)
# 将模型设置为评估模式
self.model.eval()
# 如果有GPU,则使用GPU
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.model.to(self.device)
def answer_question(self, question, context, max_length=512):
"""
回答基于上下文的问题
参数:
question: 问题文本
context: 包含答案的上下文文本
max_length: 输入序列的最大长度
返回:
answer: 从上下文中提取的答案
start_score: 开始位置的得分
end_score: 结束位置的得分
"""
# 准备输入
inputs = self.tokenizer.encode_plus(
question,
context,
add_special_tokens=True,
max_length=max_length,
truncation="only_second",
padding="max_length",
return_tensors="pt"
)
# 将输入移动到正确的设备上
input_ids = inputs["input_ids"].to(self.device)
attention_mask = inputs["attention_mask"].to(self.device)
token_type_ids = inputs["token_type_ids"].to(self.device)
# 获取模型预测
with torch.no_grad():
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids
)
# 获取开始和结束位置的预测分数
start_scores = outputs.start_logits
end_scores = outputs.end_logits
# 找到最可能的答案
# 忽略[CLS]和[SEP]等特殊标记
answer_start = torch.argmax(start_scores)
answer_end = torch.argmax(end_scores)
# 确保答案是有效的(开始位置在结束位置之前)
if answer_start > answer_end:
answer_start, answer_end = answer_end, answer_start
# 将token IDs转换回文本
tokens = self.tokenizer.convert_ids_to_tokens(input_ids[0])
# 获取答案文本
answer = self.tokenizer.convert_tokens_to_string(tokens[answer_start:answer_end+1])
# 移除特殊标记和填充标记
answer = answer.replace("[CLS]", "").replace("[SEP]", "").replace("[PAD]", "").strip()
return {
"answer": answer,
"start_position": answer_start.item(),
"end_position": answer_end.item(),
"start_score": start_scores[0][answer_start].item(),
"end_score": end_scores[0][answer_end].item()
}让我解释一下这段代码的核心部分。上面的BertQASystem类创建了一个问答系统,它使用预训练的BERT模型来从上下文中找出问题的答案。
这个系统的工作原理是 :首先,我们使用tokenizer将问题和上下文文本转换成BERT模型能理解的数字序列。这些数字代表了词汇表中的标记(tokens),并且会添加特殊标记如[CLS](表示序列开始)和[SEP](用于分隔问题和上下文)。
当我们将这些数据输入BERT模型时,模型会输出两组分数:一组表示答案开始位置的可能性,另一组表示答案结束位置的可能性。通过找出这两组分数中的最大值,我们可以确定模型认为最可能的答案跨度(从开始位置到结束位置的文本片段)。
最后,我们将这些数字标记转换回文本,并进行一些清理工作,如移除特殊标记,就得到了我们的答案。
3. 使用预训练模型测试问答系统
python
# 使用预训练模型进行测试
def test_qa_system():
# 初始化问答系统,使用预训练的QA模型
qa_system = BertQASystem(model_name="deepset/bert-base-cased-squad2")
# 测试用例
contexts = [
"Python是一种广泛使用的解释型、高级和通用的编程语言。Python支持多种编程范式,包括结构化、面向对象和函数式编程。它拥有动态类型系统和垃圾回收功能,能够自动管理内存使用。Python由吉多·范罗苏姆创建,第一版发布于1991年。",
"自然语言处理(NLP)是人工智能的一个子领域,专注于使计算机能够理解、解释和生成人类语言。NLP结合了计算语言学、统计学、机器学习和深度学习等多个领域的技术。近年来,基于Transformer架构的模型如BERT、GPT和T5在NLP任务上取得了突破性进展。"
]
questions = [
"Python是谁创建的?",
"NLP是什么的子领域?"
]
for i, (context, question) in enumerate(zip(contexts, questions)):
print(f"\n测试 {i+1}:")
print(f"问题: {question}")
print(f"上下文: {context[:100]}...")
# 获取答案
result = qa_system.answer_question(question, context)
print(f"答案: {result['answer']}")
print(f"开始位置得分: {result['start_score']:.4f}")
print(f"结束位置得分: {result['end_score']:.4f}")
# 运行测试
if __name__ == "__main__":
test_qa_system()这部分代码展示了如何使用我们刚刚创建的问答系统。我们使用了一个已经在SQuAD数据集上微调过的BERT模型("deepset/bert-base-cased-squad2"),并给它提供了两个测试用例:一个关于Python的创建者,另一个关于NLP的分类。
当运行这段代码时,系统会尝试从给定的上下文中找出问题的答案。例如,对于"Python是谁创建的?"这个问题,系统应该能够从上下文中找出"吉多·范罗苏姆"这个答案。同样,对于"NLP是什么的子领域?",系统应该能够识别出"人工智能"。
输出结果不仅包括答案本身,还包括模型对这个答案的置信度(通过开始位置和结束位置的得分表示)。这可以帮助我们评估模型的预测有多可靠。
4. 微调BERT模型用于自定义问答任务
对于特定领域的问答任务,我们可能需要在自己的数据集上微调BERT模型。这个过程包括准备符合SQuAD格式的训练数据,然后进行模型训练。
微调过程的主要步骤包括:
- 数据准备:将数据转换为SQuAD格式,包含上下文、问题和答案位置
- 模型初始化:加载预训练的BERT模型
- 训练配置:设置优化器、学习率等超参数
- 训练循环:在训练数据上迭代,更新模型参数
- 模型保存:保存微调后的模型以供后续使用
5. 构建完整的端到端问答应用
现在让我们将前面的功能整合起来,构建一个完整的问答应用程序,该程序能够加载文档、预处理文本、检索相关内容,并使用BERT模型提取答案。
这个端到端系统实现了以下关键功能:
- 文档管理:添加和处理多个文档
- 文档检索:使用TF-IDF向量化和余弦相似度找到与问题最相关的文档
- 答案提取:使用BERT模型从检索到的文档中定位并提取答案
- 结果评估:计算答案的置信度和相关度得分
这个系统代表了一个典型的检索增强问答系统,它首先使用传统的信息检索技术找到相关文档,然后使用深度学习模型(BERT)提取精确答案。这种结合方法既能处理大量文档,又能提供精确的答案,是现代问答系统的标准架构。
五、问答系统的未来发展
问答系统技术正在快速发展,未来趋势包括:
- 多模态问答:结合图像、视频等多种模态的问答系统
- 对话式问答:能够维持多轮对话上下文的问答系统
- 知识图谱增强:利用结构化知识增强问答能力
- 更强的推理能力:能够进行复杂逻辑推理的问答系统
- 领域适应:更容易适应特定领域的问答系统
六、总结与实践建议
今天我们学习了问答系统的基础知识,包括:
- 问答系统的基本概念和分类
- 基于检索和基于生成的问答系统各自的优缺点
- 使用BERT模型构建问答系统的技术细节
- 端到端问答系统的实现方法
构建优秀问答系统的实践建议:
- 选择合适的架构:根据应用场景选择检索式、生成式或混合架构
- 数据质量至关重要:确保训练数据的质量和覆盖范围
- 进行充分的评估:使用多种指标评估系统性能
- 考虑实际部署限制:在实际应用中需要考虑延迟、资源消耗等因素
- 不断迭代改进:根据用户反馈持续优化系统
问答系统是NLP技术的重要应用,也是人工智能与人类交互的关键接口。随着技术的不断进步,问答系统将变得越来越智能,为我们提供更加精准、自然的信息获取体验。
参考资料
- SQuAD数据集:https://rajpurkar.github.io/SQuAD-explorer/
- Hugging Face Transformers文档:https://huggingface.co/docs/transformers/
- BERT论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 斯坦福CS224N课程:自然语言处理与深度学习
祝你学习愉快,Python星球的探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!