目录
1.JVM结构体系
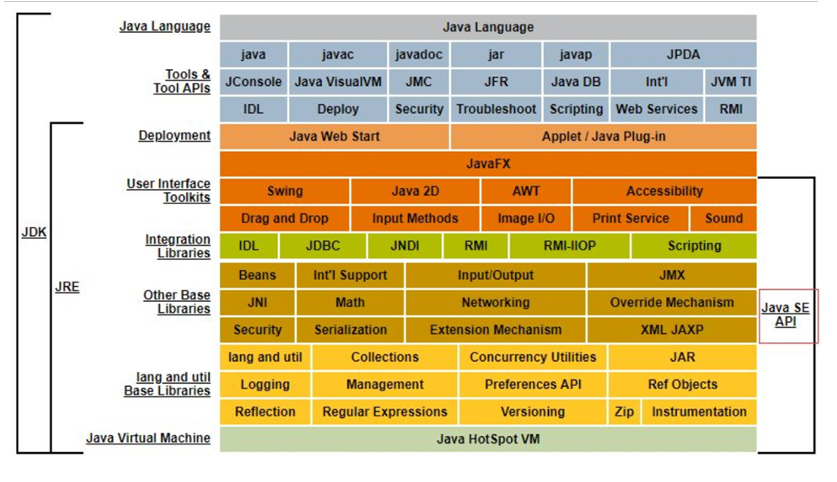
JDK**、JRE和JVM的包含关系:**
1)JDK=JRE+ 开发工具集(例如Javac,java编译工具等)
-
JRE=JVM+JavaSE标准类库(java核心类库)
-
如果只想运行开发好的 .class文件 只需要JRE

2.跨平台特性
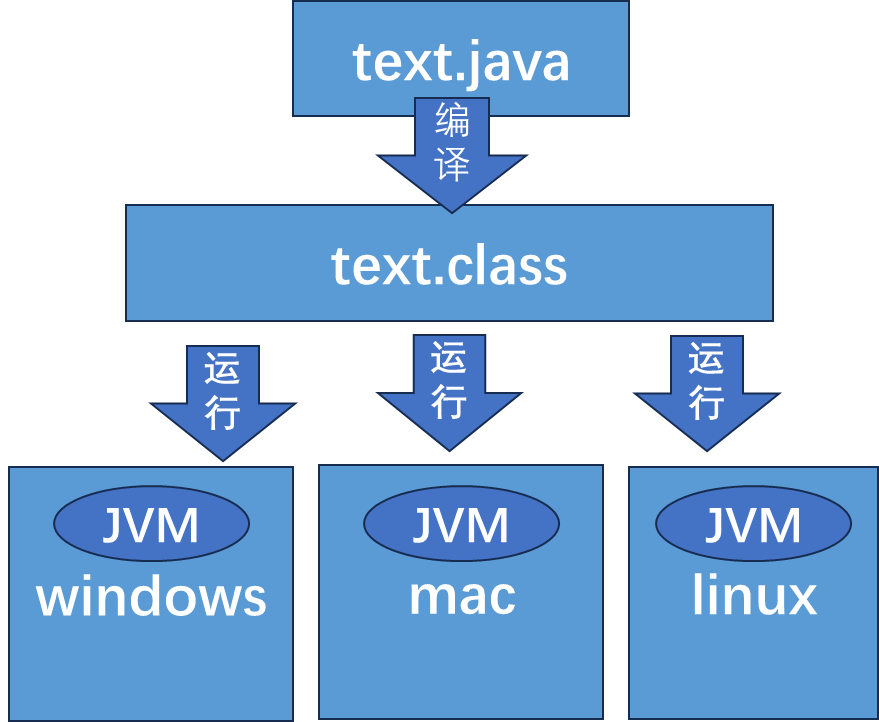
.java文件经过javac指令变成.class字节码文件 ,再通过java命令进入到java虚拟机里面运行,同样的文件到不同环境的jvm运行都会产生不同的二进制机器码,字节码是统一的,但JVM生成的机器码会因环境而异
一次编译,到处运行
每个不同版本的JDK内部都有对应的不同操作系统 的jvm环境,也就是不同版本的jvm去实现的
3.JVM整体结构及内存模型
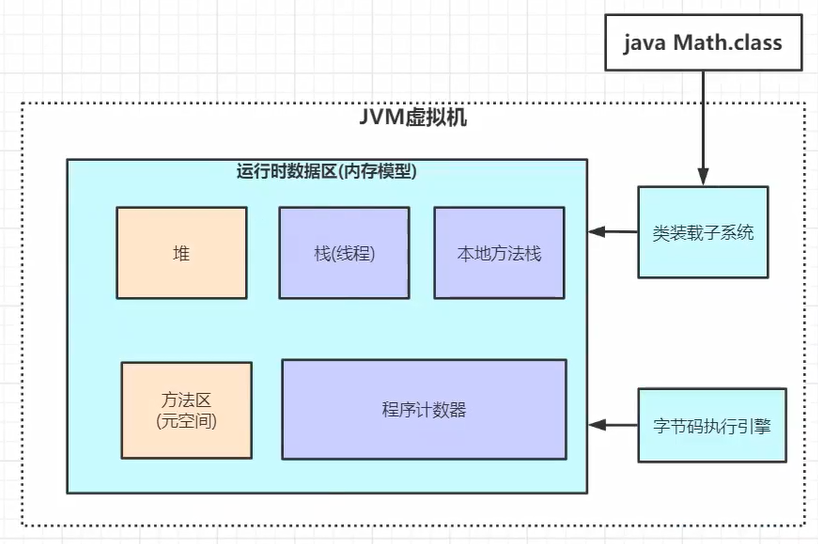
总共是有3块部分,运行流程也是如下:
1.类加载子系统
2.运行时数据区(内存模型)
3.字节码执行引擎
1.栈内存
我们来看一个简单的代码
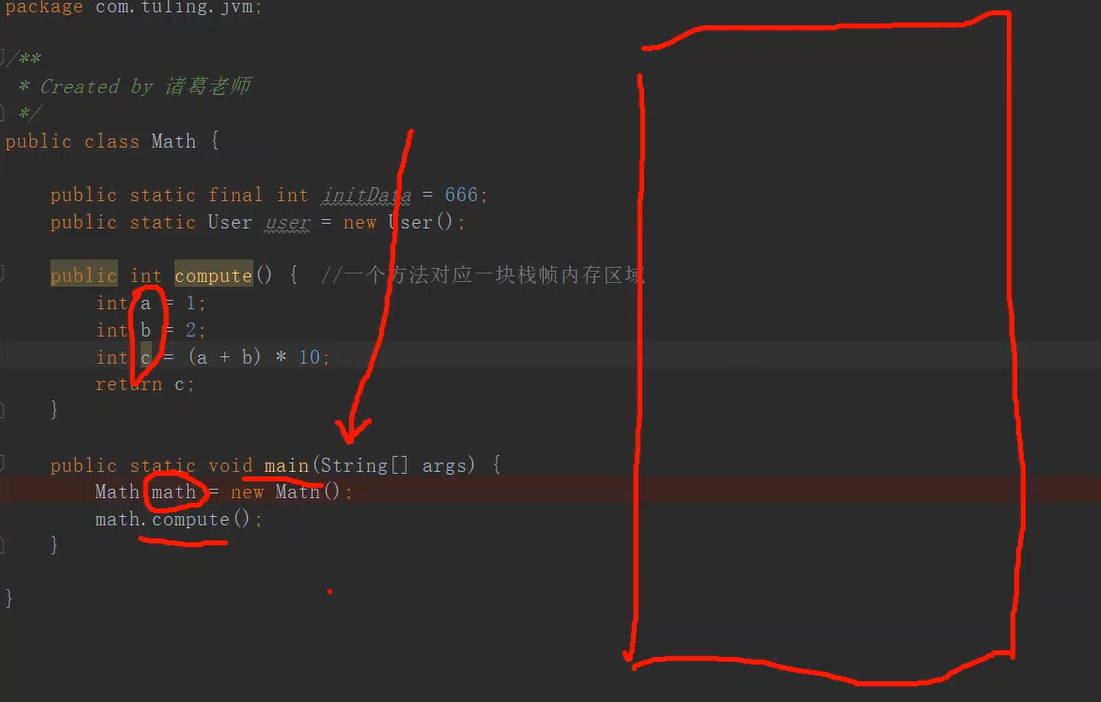
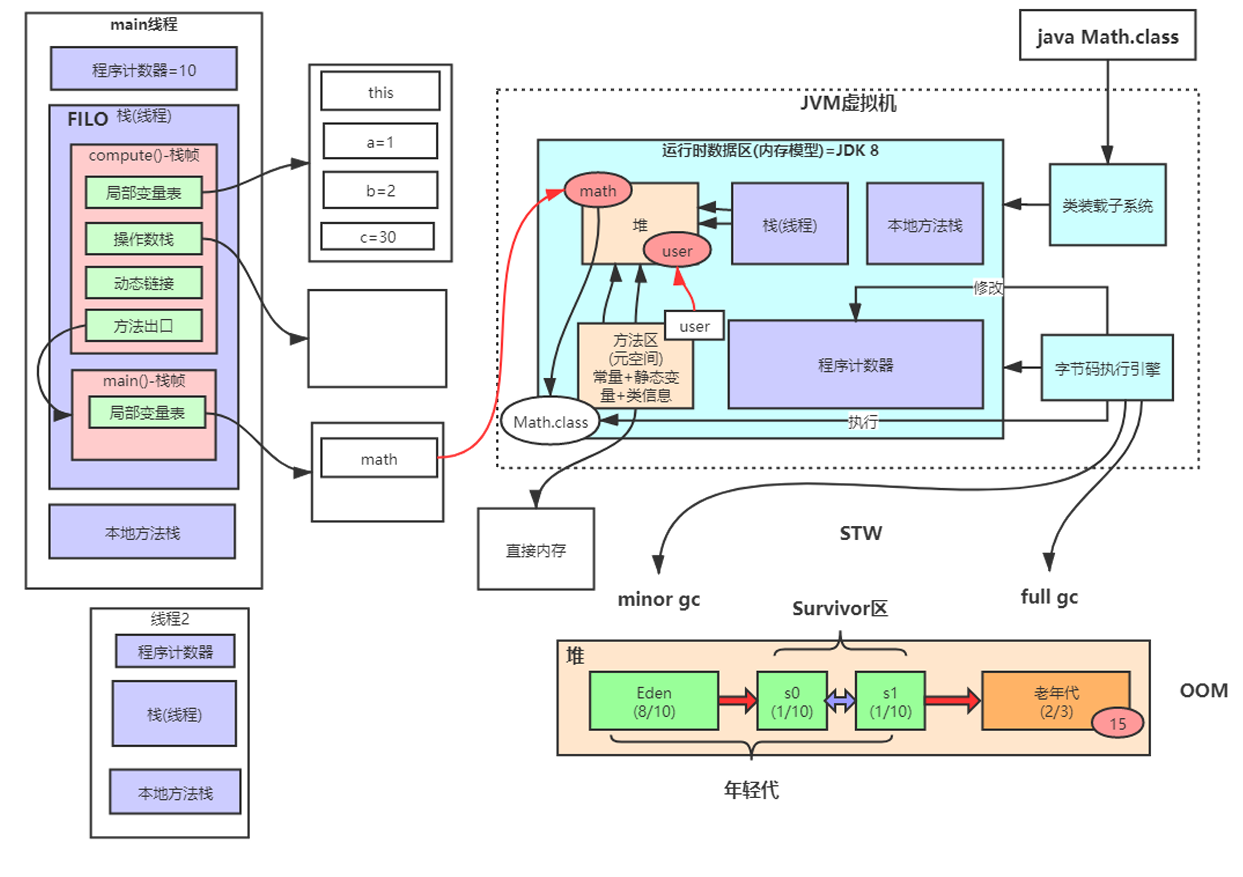
比如我们有一个main主方法,当我们运行的时候会有一个主线程来运行这个方法,此时java虚拟机会在线程栈内分配一块独立的空间 ,用来存放我们线程执行过程中用到的局部变量。 不同的线程执行都有自己的内存空间去放局部变量,这就是栈内存。 每一个方法的局部变量都有在栈内存 里面的一块栈帧内存区域来存放,每个栈帧区域都是独立的不会嵌套,这个栈就是数据结构的那个先进后出的栈,因此代码的从外到内执行变成了从上到下执行,符合!
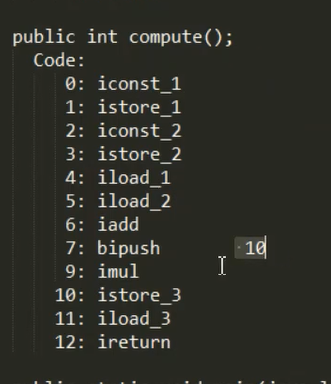
上图代码的jvm处理字节码文件的指令:
1、栈帧:
栈帧的内部也有很多区域,如下图:
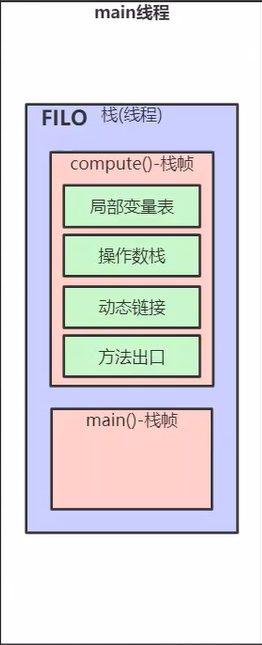
1.局部变量表
一开始存的就是具体方法的局部变量a之类的
| 数据类型 | 存储方式 | 示例 |
|---|---|---|
| 基本类型 | 直接存储值(int, float, boolean等) | int a = 10; |
| 对象引用 | 存储指向堆内存对象的指针(reference) | String s = "hello"; |
后续会被操作数栈赋值
2.操作数栈
比如上述代码的int a=2,常量2先通过JVM内的指令 iconst_1压入操作数栈里,局部变量表中分配的一块内存空间给变量a,然后通过指令istore_1使常量2先出栈 ,再存入局部变量表 使a=2赋值,注意,在JVM中字节码指令的执行是原子性的 ,istore_1 原子操作 ,先弹出栈顶值,再存入局部变量表,保证每条指令在执行时 不会被线程调度打断。
虽然运算过程发生在操作数栈 内,但JVM执行算术指令时,必须先将操作数从栈顶弹出,运算完成后再将结果压回栈顶
3.动态链接
在运行时确定方法的实际调用地址,比如动态链接确定实际调用的compute()方法,我们调用这个方法的时候得去知道这个方法内部有哪些指令,因为compute()已经放入常量池里面了,相当于目前只是个符号,当运行到这个符号的时候需要去解析,加载时会解析所有方法的符号引用,但非静态方法的绑定推迟到运行时 (因多态,将符号引用Math.compute:()存入运行时常量池 ,但不解析具体地址 ,因可能有子类覆盖),所以compute()只能在程序运行的时候加载,程序运行的时候把符号引用转换成对应代码的内存直接地址(或者说是直接引用)
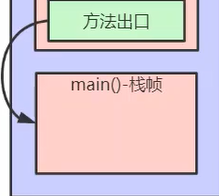
4.方法出口
compute()方法执行完要出computr()方法的栈帧回到main()方法的栈帧里面
2、创建对象

当我们new了一个对象之后,这个math对象会存入堆里面,但是此时栈里面的main()方法的栈帧里面也有一个局部变量表里的math变量,这两个math的关系是:
栈:本质是一个引用,存储堆里math对象的地址,类似于指针
堆:包含对象头(类型指针、GC标记等)、实例数据(字段)和方法表(vtable)等实际内容
因此我们可以得到一个结论:栈里面的很多局部变量都是指向堆里面的地址
====================================================================
2.程序计数器:
程序计数器也是在一个线程里面的,和栈内存一样,是线程私有的内存区域。
作用:
1.记录当前线程正在执行的字节码指令的地址
2.存储下一条要执行的指令地址
当JVM执行字节码时,程序计数器(PC寄存器)会指向当前线程正在执行的指令的地址
3.控制程序执行流程
顺序执行:字节码执行引擎会动态修改程序计数器的值
4.线程切换后恢复执行
当线程被操作系统挂起(如时间片用完),PC会保存当前执行位置。
线程恢复时,JVM根据程序计数器的值继续执行,确保程序逻辑正确。
====================================================================
3.方法区
方法区存的是常量池,所以也叫运行时常量池
方法区=常量+静态变量+类信息

当我们new了一个静态变量的user对象,这个对象会存入堆里面,此时user变量是存入方法区里面的,因为他是静态变量,所以这里也是方法区里面的user变量指向堆里面的user对象
因此我们又可以得到一个结论:方法区里面的很多静态变量都是指向堆里面的地址
拓展一下常量池类型:
-
类文件常量池 (Class File Constant Pool)
- 存储在.class文件中
- 包含编译期确定的各种符号引用和字面量
-
运行时常量池 (Runtime Constant Pool)
- 每个类/接口独有的
- 在类加载时从类文件常量池创建
-
字符串常量池 (String Constant Pool)
- 专门存储字符串字面量
- Java 7开始从方法区移到堆内存
-
基本类型包装类常量池
- 如IntegerCache、LongCache等
- 缓存特定范围内的基本类型包装对象
-
符号引用常量池 (Symbol Table)
- JVM内部使用的符号表
- 存储类、方法、字段等的符号引用
-
动态常量池 (Dynamic Constant Pool)
- Java 11引入
- 支持动态语言特性
-
本地方法常量池 (Native Method Constant Pool)
- 为本地方法调用服务的常量池
-
匿名类常量池 (Anonymous Class Constant Pool)
- 为匿名类特化的常量池结构
====================================================================
4.堆
结构图:
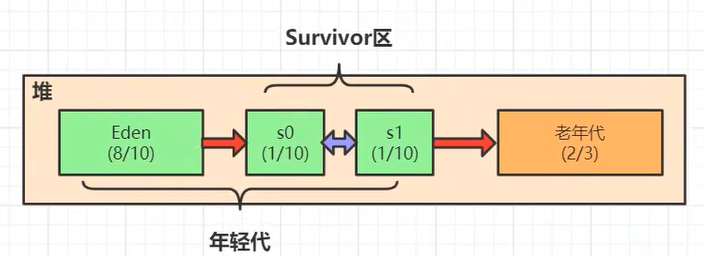
区域分为:
堆=年轻代(Eden+s0+s1)+老年代 s0+s1:Survivor区
我们new出来的对象 大部分都放在Eden区
1、如果Eden放满了怎么办?那么字节码执行引擎 会开启垃圾收集线程(垃圾回收GC),会把无用的对象回收
所有GC Roots共同作为起点,比如静态变量区和方法区的对象开始找引用对象,当找到某个对象不再被GC Roots直接或间接引用,就是说没有任何引用链连接到GC Roots,此时这条线上的所有节点都会被标记为非垃圾对象,因此会把这些**对象从Eden复制到Survivor区s0,**剩下的就是垃圾对象会被删除。
2、当Eren第2次满了,这时候会再次触发上述流程(放入Eden里对象),只不过满了之后回收的区域变成了**Eren+s0,**非垃圾对象会从Eren+s0区到s1区,剩下的垃圾对象再次被删除。
3、如果第3次满了,再次触发上述流程,只不过回收的区域变成了**Eren+s1,**非垃圾对象会从Eren+s1区到s0区,剩下的垃圾对象再次被删除。
4、每挪一次,对象的分段年龄会+1,一般达到15次会进入老年区;当放入s0或者s1的时候放不下也会直接放入老年区
**注意:**静态变量区属于GC Roots它本身不会被回收,而是通过它判断堆内对象是否存活。通常会进入到老年代的有:静态变量、对象池、缓存对象、spring容器里的对象
====================================================================
5.本地方法区

比如start()方法里面会调用一个本地方法接口是用C++写的,通过native关键字声明的方法:

本地方法会去找.dll文件
====================================================================
6.总结
当你读完读明白整篇文章的时候,你应该就理解如下图片了: