文章目录
🌟范式
数据库的范式是⼀组规则。在设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式
关系数据库有六种范式:第⼀范式(1NF)、第⼆范式(2NF)、第三范式(3NF)、巴斯-科德
范式(BCNF)、第四范式(4NF)和第五范式(5NF,⼜称完美范式),越⾼的范式数据库冗余越⼩。然⽽,普遍认为范式越⾼虽然对数据关系有更好的约束性,但也可能导致数据库IO更繁忙,因此在实际应⽤中,数据库设计通常只需满⾜第三范式即可
总结:范式描述的就是数据关系模型,一对一关系,一对多关系,多对多关系
现在有一个学生教务系统
学生,学号,课程,班级
- 一个学生 只能有一个学号,一个学号只能是一个学生(一对一)
- 一个学生只属于一个班级,一个班级可以包含多个学生(一对多)
- 一个学生可以选择多门课程,一个课程也可以包含多个学生(多对多)
🌟表的设计
- 根据一些实际的业务场景,来设计表,主要是确定数据库中有几个表,每个表是做什么的,每个表有哪些字段
OOA 面向对象分析-->OOD 面向对象设计-->OOP 面向对象编程
具体步骤
1.从需求中获得类,类对应到数据库中的实体,实体在数据空中就表现为一张一张的表,类中的属性就对应着表中的字段(列)
2.确定类与类之间的关系
3.使用SQL去创建具体的表
设计表的时候会遵守的规则,这样的规则我们称之为三大范式
💫第一范式 1NF
关系型数据库的一个最基本要求,不满足第一范式不可以称为关系型数据库
- 数据库表的每⼀列都是不可分割的原⼦数据项,而不能是集合,数组,对象,即表里的字段不可再进行拆分
🪐反例
- 举个第一范式的反例
有一个学生表
学号,姓名,年龄,班级名,学校
这些字段前四个都可以用数据类型来表示
bigint ,varchar,int,varchar
但是学校这个字段并没有数据类型来表示学校
学校还可以拆分成:学校名称,学校网址...
拆分后就可以用varchar数据类型表示
像这样可以继续拆分的字段在关系型数据库中是绝对不允许的
🪐正例
- 第一范式正例
学生表
学号,姓名,年龄,班级编号,学校名称,学校网址
虽然这样不符合数据库设计的规范,但是每一列是不可再拆分的,最起码可以表明一个学生和班级学校的关系
每一个字段都可以有一个数据类型表示,那么这个表就天然满足第一范式
💫第二范式 2NF
- 在满足第一范式的基础上,不存在非关键字段对任意候选键的部分函数依赖(存在复合主键的情况下)

- 场景:学生可以选修课程,课程有对应的学分,学生考试之后会针对每一门选修课生成相应的成绩
- 使用数据库中的表记录学生的成绩
🪐反例
- 第二范式反例

学生相关的信息通过学号确定
学分相关的信息通过课程确定
成绩通过 学生和 课程共同区分.一个学生选修的课程,经过一次考试之后会生成成绩也就是说这个表中的 学生和课程作为复合主键来确定一个学生当前选修课的成绩
学生的姓名,年龄和课程没有关系,即姓名,年龄只依赖于学号,不依赖与课程
学分与学生没关系,即学分只依赖于课程,不依赖与学生
这里的依赖关系一定要梳理清楚
由两个或多个关键字段决定一条记录,如果一行数据中的有些字段只与关键字段中的一个有关系,我们就把这种情况叫做他存在部分函数依赖,那么这个表就不满足第二范式
我们借用这个反例继续完成这个数据表,看看可能会出现的问题
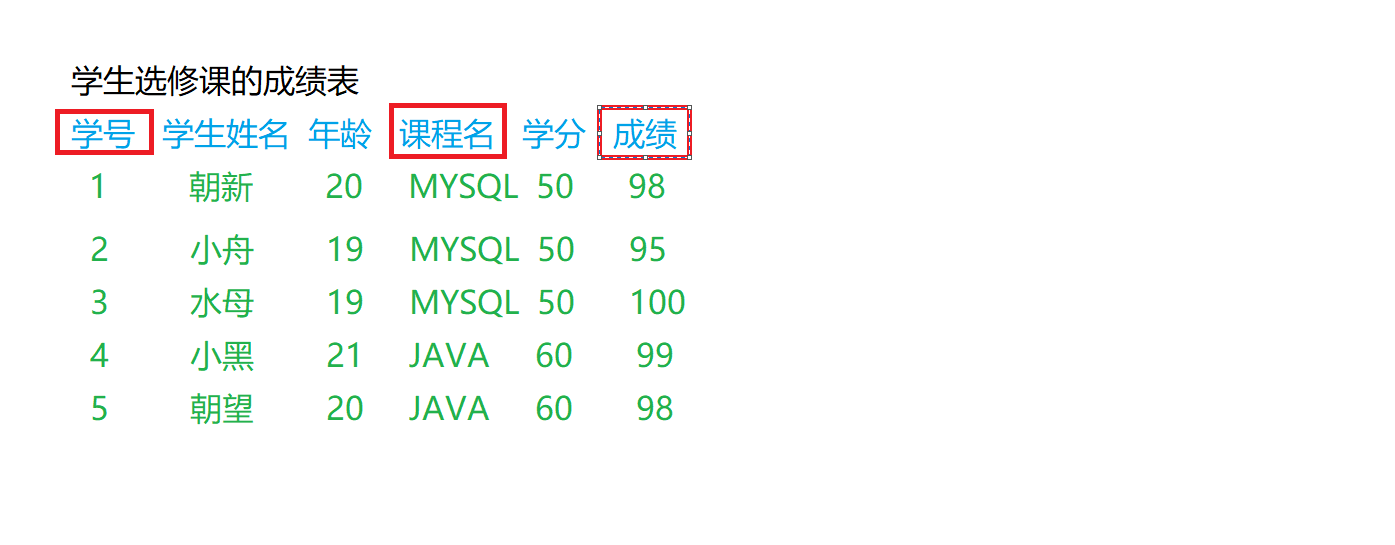
- 不满足第二范式可能会出现的问题:
-
数据冗余
学生姓名、年龄、学分这些字段都是重复出现,造成了大量的数据冗余
-
更新异常
若需要对MYSQL的学分进行调整,那么就需要更新所有记录中关于MYSQL的记录,如果一旦数据库出现异常,某些记录更新成功,某些更新失败,就会造成数据表同一门课程不同学分,数据不一致
-
插入异常
学校新开设了一门课程,已经定义好学分了,但是目前这样的表设计,每一门课程与学生的考试是对应关系,只有进行考试才会生成一条关于课程的成绩记录 ,记录里保存了课程的学分,也就是说,新课程在之前的数据库中没有相应的记录.因为学生成绩为空时记录没有意义
-
删除异常
毕业的学生需要全部删除,删除记录的同时,也可能把课程对应的学分全部删除,导致一段时间内,数据中没有课程和学分相应的信息
🪐正例
- 第二范式正例

这样的表设计,每张表都有非主键字段,都强依赖于主键,满足第二范式
也就是说一个表中没有复合主键(主键只有一列)那么这种表就天然满足第二范式
💫第三范式 3NF
- 在第二范式的基础上,不存在非关键字段,对任一候选键的传递依赖
场景:描述学生就读于哪个学院
🪐反例
- 第三范式反例

现在要描述学生,可以很明显的判定出 学号就是学生表的主键
这个表的设计中,姓名和年龄与学号强相关
学院网址与所属学院强相关
描述清楚学生所属学院,只需要把学生和学院建立一个关联关系,此时可以看出两种强相关关系出现在同一条记录
两个强相关系存在传递现象
学号-->所属学院-->学院网址
这种传递关系称之为 传递依赖
这样的表设计不满足第三范式,因为存在传递依赖
🪐正例
- 第三范式正例
根据学生和学院的关系,拆分为两张表即可

这样的表设计,两张表都依赖于自己表中的主键,学生表可以通过外键与学院之间建立关联关系
第三范式可以解决数据冗余,更新异常,插入异常,删除异常的问题
💫表的设计方法
1.在场景中找到实体
2.确定实体与实体间的关系
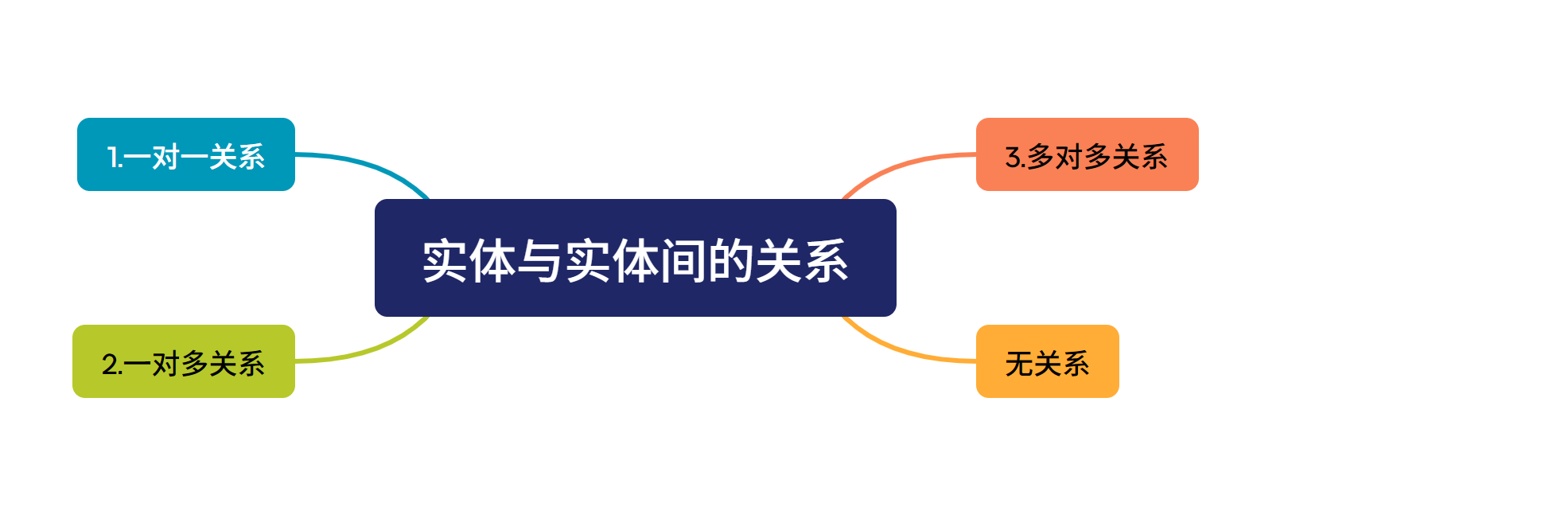
🛰️一对一关系
比如教务系统的登录界面
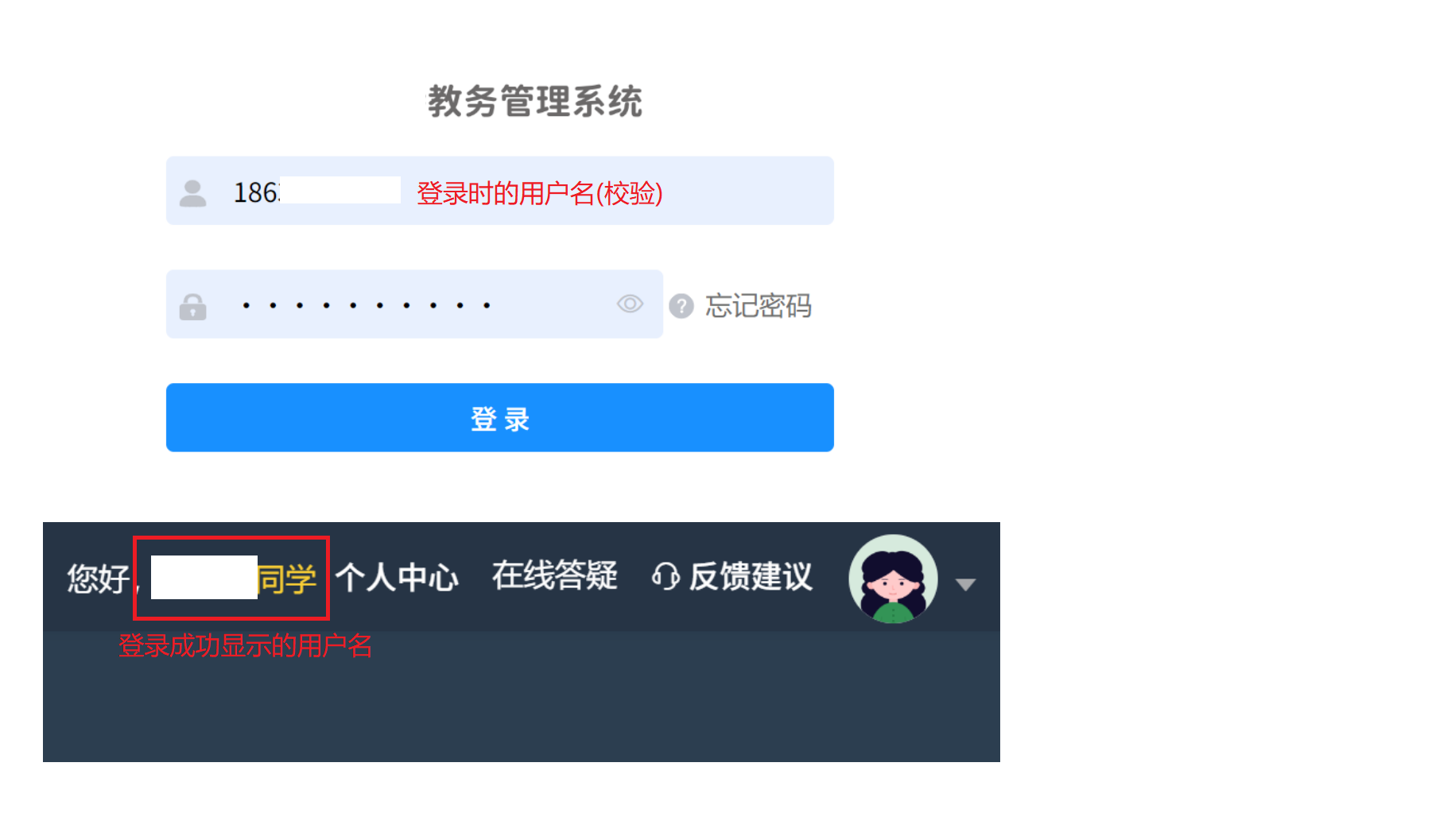
像这样的场景,一般对应着两个实体,一个实体是用户(包括学生,老师),另一个实体是账号
用户:记录个人信息,姓名,班级,QQ号,手机号
账号:登录名,密码
一个用户只能有一个账号,一个账号只能给一个用户使用,不能共享
在设计表之前先按上面的句式把实体之间的关系列出来
- 针对一对一关系,设计表时,有两种方式

🛰️一对多关系
比如学生和班级之间的关系
一个学生只能存在于一个班级,一个班级中可以有多个学生
- 创建表:
1.分别为不同的实体创建表--学生表,班级表
2.建立表与表之间的关联关系
class(class_id,name);
student(student_id,name,age,class_id);
通过学生记录中的class_id 可以表示学生在哪个班级,每个学生都关联了一个班级
🛰️多对多关系
一个学生可以选修多门课程
一门课程也可以被多名学生选修
-
分别创建实体表

-
创建关系表,在关系表中为实体之间创建关联关系

通过关系表,就可以把学生修改的课程清楚的记录下来,这样设计同时也满足了第二范式的要求,如果要修改学生的年龄只需要修改学生表中的年龄字段即可,不会影响关系表
- 学生选修课成绩表
1.班级表(班级编号,班级名)
cpp
create table class(
class_id bigint primary key auto_increment,
name varchar(50) not null
);2.学生表(学生编号,学号,姓名,年龄,右键,班级编号)
cpp
create table student(
student_id bigint primary key auto_increment,
sn varchar(6) unique,
name varchar(50) not null,
mail varchar(50),
class_id bigint,
foreign key (class_id) references class(class_id)
);3.课程表(课程编号,课程名)
cpp
create table course(
course_id bigint primary key auto_increment,
name varchar(50) not null
); 4.成绩表(编号,学生编号,课程编号,成绩)
cpp
create table score(
score_id bigint primary key auto_increment,
student_id bigint,
course_id bigint,
score decimal(5,2),
foreign key (student_id) references student (student_id),
foreign key (course_id) references course (course_id)
);班级表与学生表之间是一对多的关系
学生表与课程表之间是多对多的关系,通过一个关系表进行关联
🌟表设计总结

💫新增-插入查询
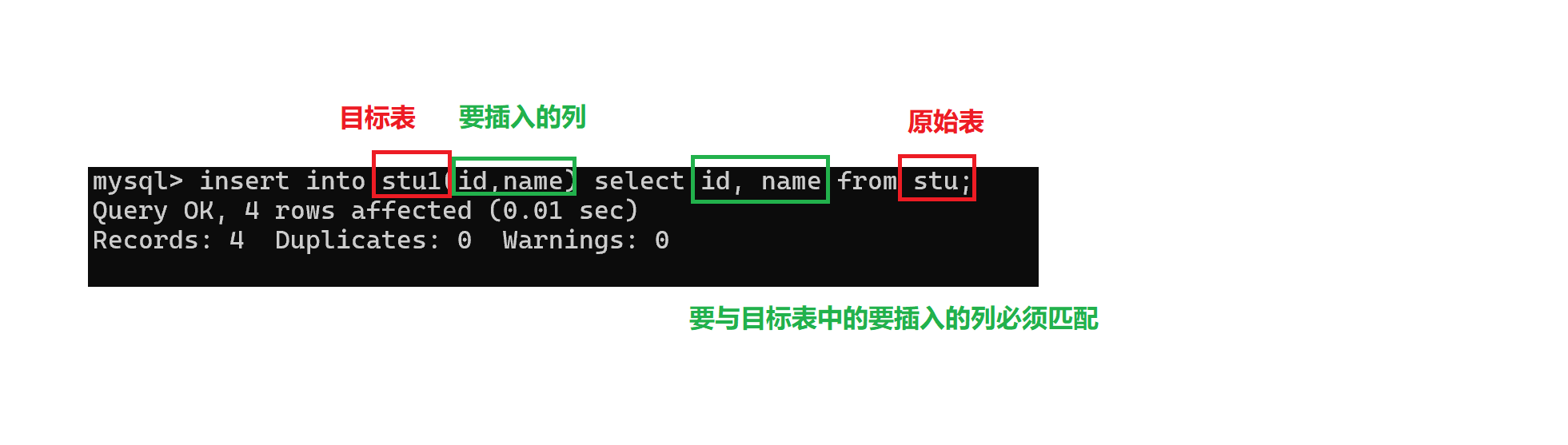
- 插入查询结果
新建一张表,把旧表的指定列数据导入到新表中
语法:
c
insert into table_name [(column [,..])] select ...
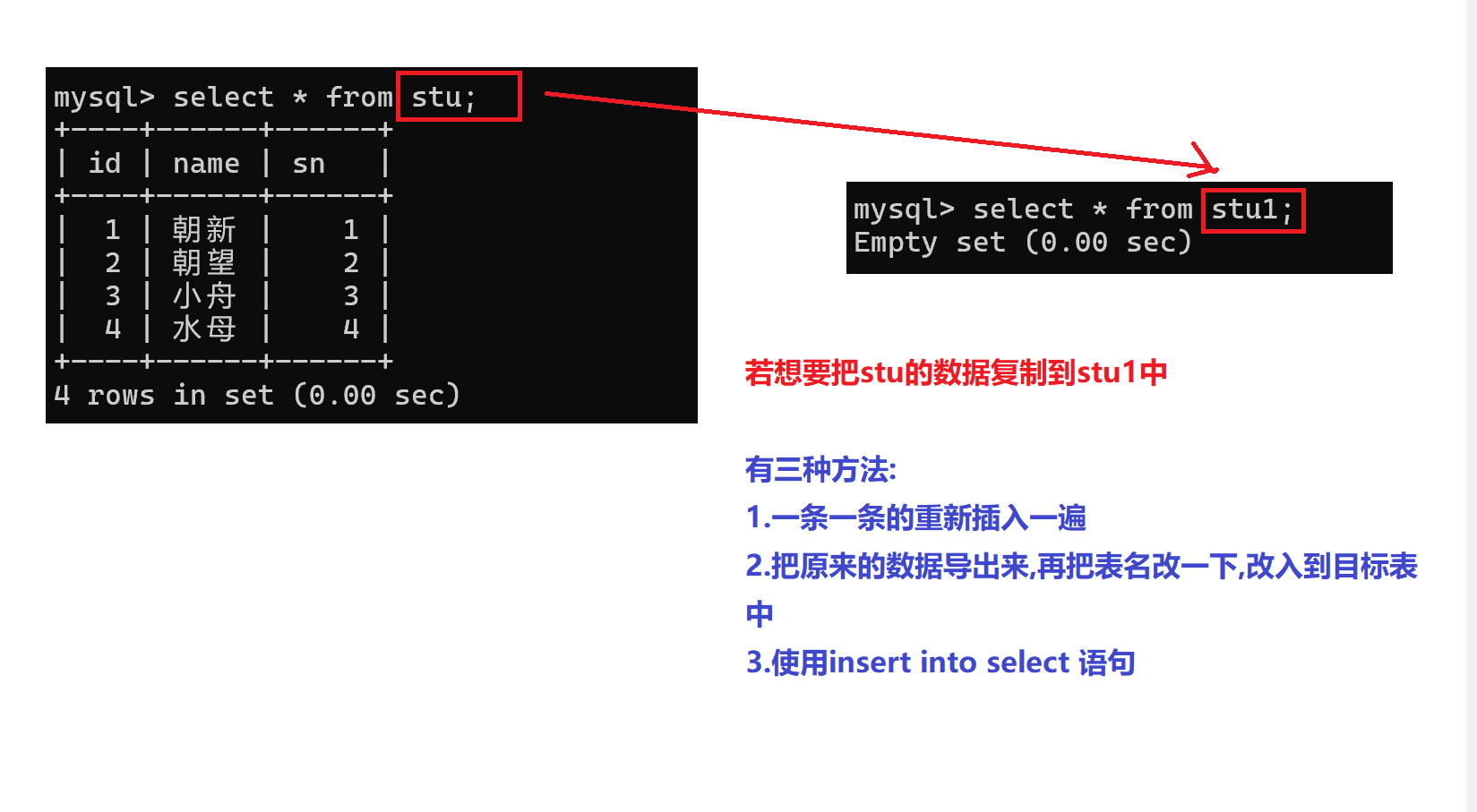
- 使用insert into select 语句将旧表插入到目标表