数据清洗
先创建一个文档然后写几条数据
eg:如下姓名+年龄+性别 而数据中我们可明显看到第2,7行数据是错误的,现在我们把它洗掉
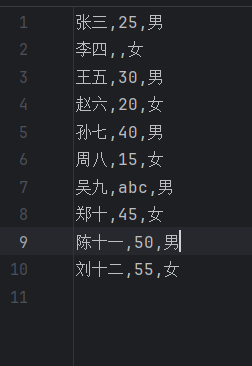
代码展示
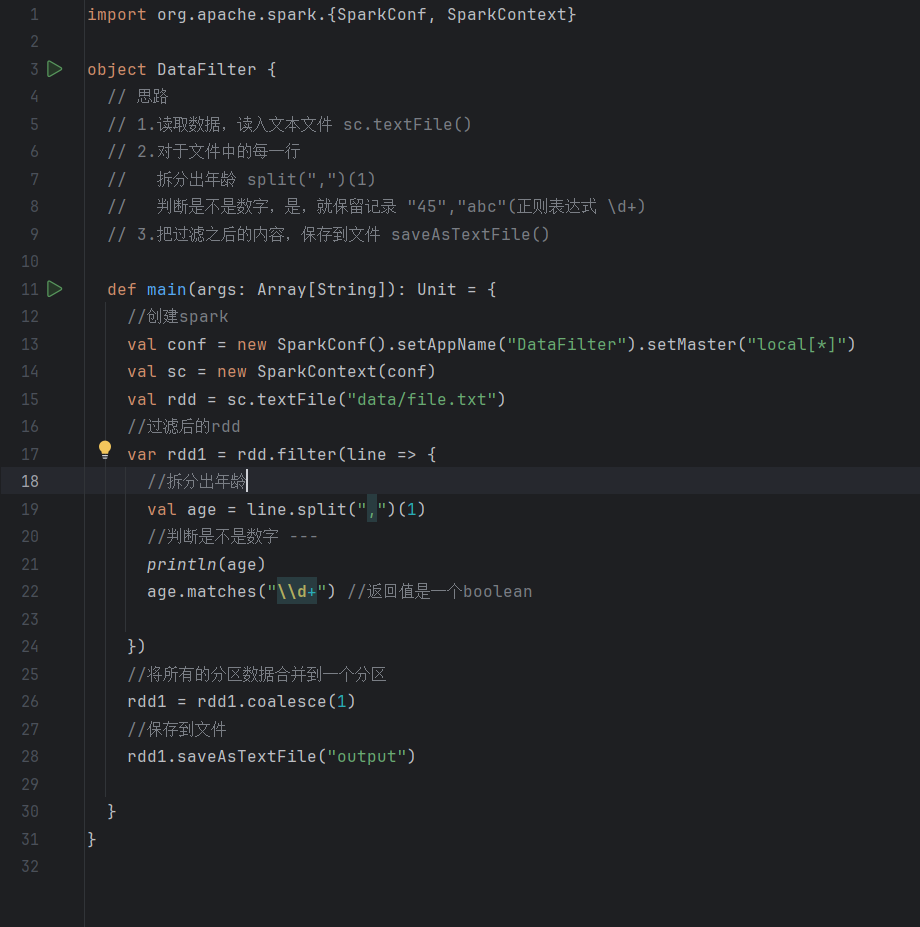
运行结果:可以看到"脏"数据已经被洗出去了
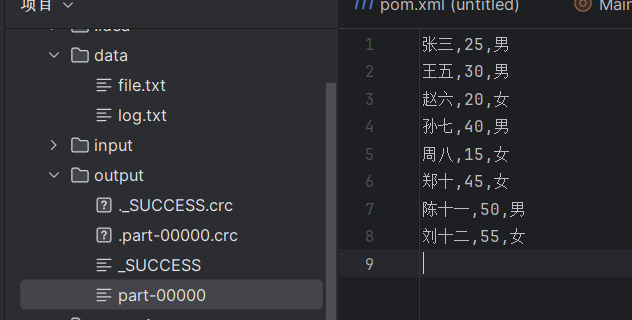
**【拓展】:**如何把清洗之后的数据保存到一个文件中?
答:可以使用coalesce(1)这个方法可以让结果全部保存在一个文件中。
val singlePartitionRDD = cleanedLines.coalesce(1)
// 保存清洗后的数据到文件
val outputPath = "path/to/your/output/file.txt"
singlePartitionRDD.saveAsTextFile(outputPath)
// 停止 SparkContext
sc.stop()