一、HTTP的方法
|---------|-------------|-----------------|
| 方法 | 说明 | 支持的HTTP协议版本 |
| GET | 获取资源 | 1.0、1.1 |
| POST | 传输实体主体 | 1.0、1.1 |
| PUT | 传输文件 | 1.0、1.1 |
| HEAD | 获得报文首部 | 1.0、1.1 |
| DELETE | 删除文件 | 1.0、1.1 |
| OPTIONS | 询问支持的方法 | 1.1 |
| TRACE | 追踪路径 | 1.1 |
| CONNECT | 要求用隧道协议连接代理 | 1.1 |
| LINK | 建立和资源之间的联系 | 1.0 |
| UNLINE | 断开连接关系 | 1.0 |
GET:从服务器上获取某个资源
POST:向服务器上传xxx个资源
PUT:向服务器上传xxx资源(文件)
DELETE:删除服务器的xxx资源
其余的方法,使用的非常少,因此我们忽略不计
(1)GET
(一)
HTTP中最常见到的方法,有着很多操作,都会触发HTTP GET请求
1.直接在浏览器地址栏中输入URL,点收藏夹也是一样的
2.在页面上点击一些连接跳转的时候
3.HTML间接加载其他资源的时候(CSS,JS,图片......)
HTML中通过link标签,加载css
通过script标签,加载js
通过img标签,加载图片


3.也可以通过js /java/c++/Python代码手动构造GET请求
(二)GET请求的特点
GET请求一般没有body,如果你通过代码构造一个get请求,故意添加上body,理论上也是可行的
GET请求要想给服务器传递数据,往往就是通过 路径/querys stirng 来进行传递

(2)POST请求
(一)
1.登录的时候

body提交的就是用户名和密码。
用户名密码,得是加密后再传输的,不能直接明文传输
对于GET请求这种没有body的情况,一般不会用来实现登录功能。如果非要去实现也行,可以把用户名密码加密之后,通过query string进行传输
2.上传资源/文件

body部分就是我们传输的图片和内容,图片属于"二进制文件"。通过HTTP body传输的时候,有时候就会把二进制的内容,通过base64进行编码,变成文本的内容
body中完全可以放二进制数据的(压缩的结果)
之所以用Base64转成文本,主要还是因为当前图片本身比较小,按照文本的方式,服务器代码处理起来好实现。
base64:把而仅仅只数据,用文本(ascii字符)进行重新编码,通过4个ascii字符,标识原来的3个字节的二进制数据。
body可以存二进制,但是url的query string不能
如果由二进制的数据想通过query string来进行保存,那么就可以通过base64进行编码
(二)POST请求的特点
带有body,通过body给服务器传递数据
不太需要query stirng传递了,通常情况下没有query string(不绝对)
post的body格式看起来好像是和 query string 差不多(但是这里还有其他情况)
HTTP的这些方法,在使用的时候不一定严格按按照官方提供的语义来进行
经典面试题------谈谈GET和POST的区别
核心结论:GET 和 POST其实没有本质区别,只是HTTP的两个不同的方法。大部分情况下,使用GET的场景,也可以替换成POST,使用POST的场景也可以替换成GET
但是从使用习惯来讲,还是存在差异的
(1)GET通常没有body,通过query stirng传递数据给服务器
POST通常由body,不需要通过query string 传递数据
*并不绝对,你自己写一个代码,构造GET请求,加上body;构造POST请求,加上query stirng 都是可行的
(2)语义上的区别:GET标识"获取",POST表示"提交"
*不绝对,目前HTTP的方法在时间中经常会混用
GET和 POST 的区别最主要就是上面这两个
网上还有一些其他的说法
*GET请求不安全,POST请求比GET更安全
比如登录场景中,GET的话,就会把用户名和密码显示到URL上,如果别人看一眼你的屏幕,就会知道你的密码❌
安全,得是通过"加密"来完成的
如果这个说法是正确的,那么即使没有人看你的屏幕,黑客一抓包,也就看到了
*幂等性 GET请求 官方建议实现成"幂等的"(也就是当你的请求一定的时候,得到的响应结果也就一定),而POST请求无要求(HTTP标准文档上)❌
标准文档只是"建议",实际开发的时候,不一定会遵守,尤其是在现在,很多的网站都开始讲究"个性化"
*可缓存,承接幂等
GET如果实现成幂等,就可以把结果缓存起来
POST不是先成幂等,就不能缓存❌
*传输的数据量
之前有一个说法,GET请求传输的数据量少,POST传输的数据两最大,GET请求的URL存在长度限(1MB,10MB,1KB,2KB...)❌
HTTP标准文档中没有对URL的长度给出限制,上面的限制主要来自于 浏览器/HTTP服务器的实现。
*数据的类型
GET传输数据的时候,通过query string只能传输文本,POST通过body传输,也可以传输二进制❌
query string虽然不能够直接传输二进制,但是可以通过Urlencode传输二进制
(3)PUT(和POST是差不多一样的)
(4)DELETE(和GET类似,一般不带有body,通过query stirng传输数据)
二、Restful 风格的API设计(HTTP的API)
API:应用程序编程接口 Application Programming interface
方法/类(库/框架提供的API)
有些服务器,也可以认为是API的提供者,是网络上的接口
你给这个服务器发一个xxx的请求,服务器给你返回一个xxx的响应,可能提供TCP级别的API(例如RPC框架,形如grpc,thrift,dubbo)
也可能是提供HTTP级别的API(后面在javaee进阶)
咱们需要写一些服务器,提供Http api给别人(浏览器/前端)进行调用,此时就需要有一定的规范约束设计风格
1.通过请求中的方法表示不同的语义
GET:查询
POST:新增
PUT:修改
DELETE:删除
2.通过URL的路径,表示操作的资源

3.请求和响应携带的数据,都尽量使用json格式的数据
json格式的数据:
{
key:value
key2:value2
}
4.通过HTTP响应的状态码,表示失败的原因
按照上述的约定,设计出来的API风格是统一的
三、HTTP的版本号


当前最主流的HTTP版本,响应的版本号,也是在首行,但是在前面
四、HTTP报头(header)
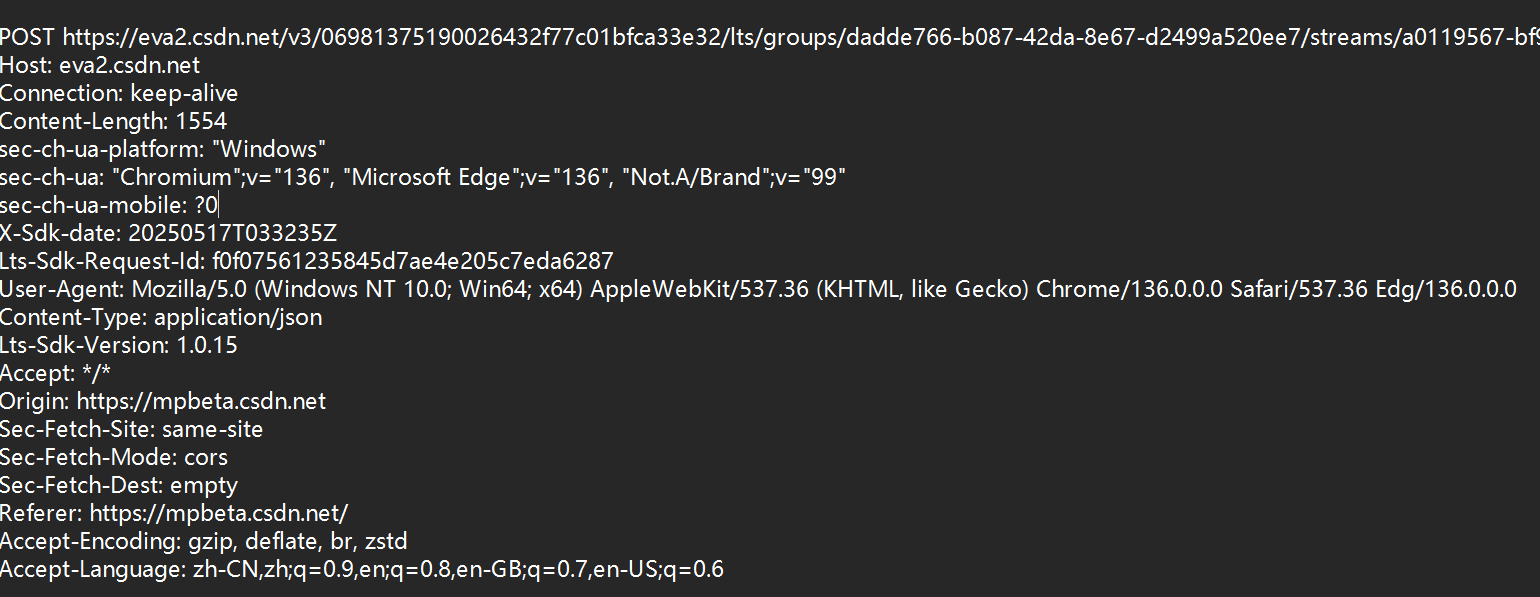
行文本,每一行都是一个键值对。键和值之间使用:空格来进行分割。
header 中的键值对都是标准规定的,(也允许用户自定义),这些header中就存在特定的含义
header的key太多了,不必一一介绍

请求中的header,描述了访问的服务器的IP(域名)和端口(可以省略)
URL中已经存在了访问的服务器的地址和端口,比如针对HTTPS来说,HTTPS是会把header部分都加密的。URL里的服务器的地址端口,就可以和Host加密后的服务器地址和端口做一个校验。
Content-Length: 1554
描述了body的长度
Content-Type: application/json
描述了body的数据格式
上述这两个东西,只有请求/响应中存在body才存在这两个属性
这两个东西共同解决了粘包问题(粘包问题在以前的帖子里有具体阐述,是一个面向字节流传输涉及到的问题,是一个TCP问题,而HTTP就是基于TCP的。如果一个TCP连接中传输多个HTTP请求/响应,此时就需要让应用程序能够区分从哪里到哪里是一个完整的应用层数据包)


byte\[\] body = new byten;
inputStream.ready(body);
HTTP协议,就是按照上述学习的格式,往TCP socket当中读写数据
服务器如何区分出,从哪里到哪里是一个完整的HTTP请求呢?
1)如果没有body,直接读到空行结束 就可以认为请求结束了
2)如果有Body,header中必然存在Content-Length,取出Content-Length的值(字节)。找到空行,空行后面就是body的开始,从开始位置,读Content-Length这么多字节就可以了
常见的Content-Type:
-
text/html
-
text/css
-
application/javascript
-
application/json
-
image/png
-
image/jpg 浏览器/服务器
根据这个 Content - Type 的值 决定 body 如何使用
如果一个请求/响应,虽然有 body 但是没有 Content - Type 或者 Content - Length 。那就是一个非法的"请求/响应" ,比如响应中如果没有 Content - Type ,浏览器会根据 body 中的数据,"猜"一个格式(有较大的概率能猜对) 。如果没有 Content - Length 浏览器也能猜(按照下一个请求一定是 GET/POST 开头)。
这就是鲁棒性:一个系统的 容错能力
英文音译robustness
鲁棒性:健壮性;强健性;耐用性;
即使你对浏览器很粗鲁的返回错误格式的数据,他仍然表现的很棒。
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0

30年前1995年左右的时候,这样的特性非常重要。
计算机/互联网 飞速发展的阶段, 最早的浏览器访问的网站是纯文本的。 后来,有了多媒体(图片,音频,视频) 再后来,有了交互能力(JS) 。再再后来,有了更复杂的交互体系(flash,现在更强的是js体系) 用户手上的浏览器,有的是老版本,只能支持文本 有的是新版本,能够支持上述所有功能。这些全都要,因此要提供多个版本的网站,有的版本只包含文字,有的包含文字和多媒体,有的则全都包含。但是,如今的网站形态基本就定型了,(下一个革命性的变化,可能是VR技术成熟)。在的浏览器上面的功能基本都有。
因此User - Agent现在只有一个作用,那就是可以区分PC端还是移动端 。PC屏幕比较大比较宽,手机屏幕比较窄比较小。有些系统,也开始往多设备上进行演化了。 针对上述区分规则,也不是完全解决问题。 C语言中, 一个指针变量,存地址 地址多长。 你的手机浏览器一般都有功能,修改UA, 在手机上通过修改UA就能够访问电脑版 ,根据用户请求的User - Agent,判定用户使用的浏览器/系统版本 是哪个(也就知道浏览器能支持哪些特性) 前端开发的流行的方式。不用给PC手机维护两个版本的网页。 就一套代码, 这一套代码可以根据浏览器窗口的宽度,自动适应.