目录
[1 引言](#1 引言)
[2 整体架构简介](#2 整体架构简介)
[3 疑问](#3 疑问)
[3.1 我们的共享内存消息机制是用的posix还是system V](#3.1 我们的共享内存消息机制是用的posix还是system V)
[3.2 rmmt中,不同线程之间的比如访问同一个内存,用的什么锁控制的](#3.2 rmmt中,不同线程之间的比如访问同一个内存,用的什么锁控制的)
[3.3 疑问:假如一个进程发送给了另外两个进程,然后另外两个进程都同时操作这块内存怎么办](#3.3 疑问:假如一个进程发送给了另外两个进程,然后另外两个进程都同时操作这块内存怎么办)
[3.4 AITS的几个模块之间的关系](#3.4 AITS的几个模块之间的关系)
[3.5 rmmt的socket之间有同步吗](#3.5 rmmt的socket之间有同步吗)
[4 代码大体流程](#4 代码大体流程)
1 引言
整理一下公司的一个微服务架构的代码整体流程,不牵扯到完整代码,不算泄密,纯粹是当做自己个人的代码阅读简单笔记,用于帮助自己理解和记忆。
2 整体架构简介
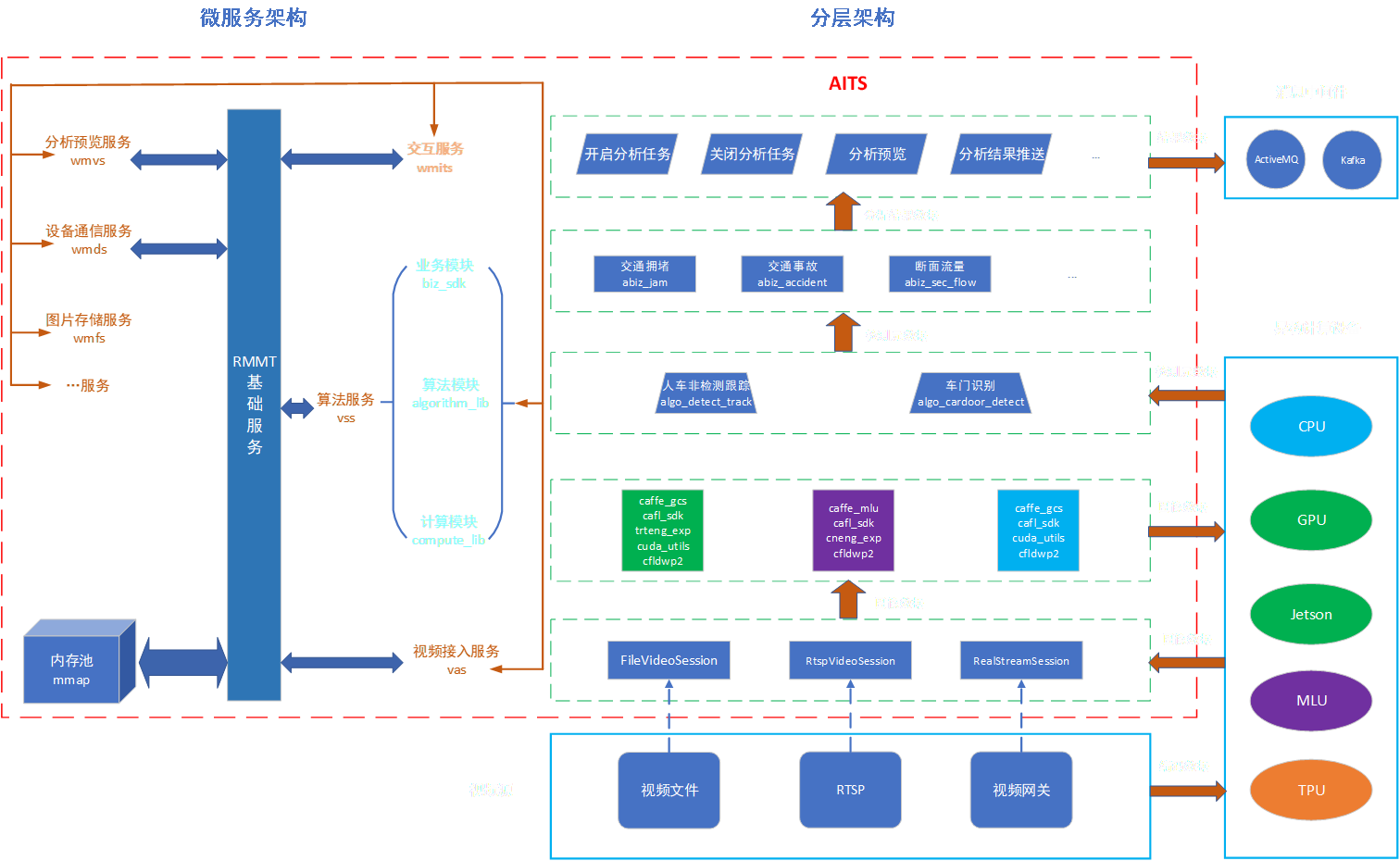
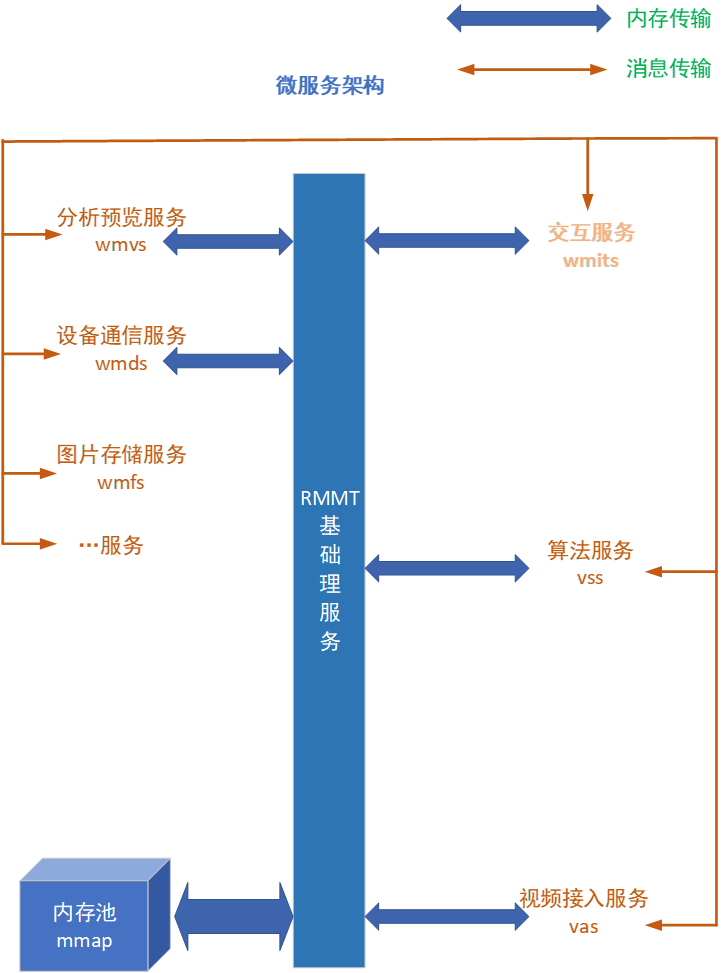
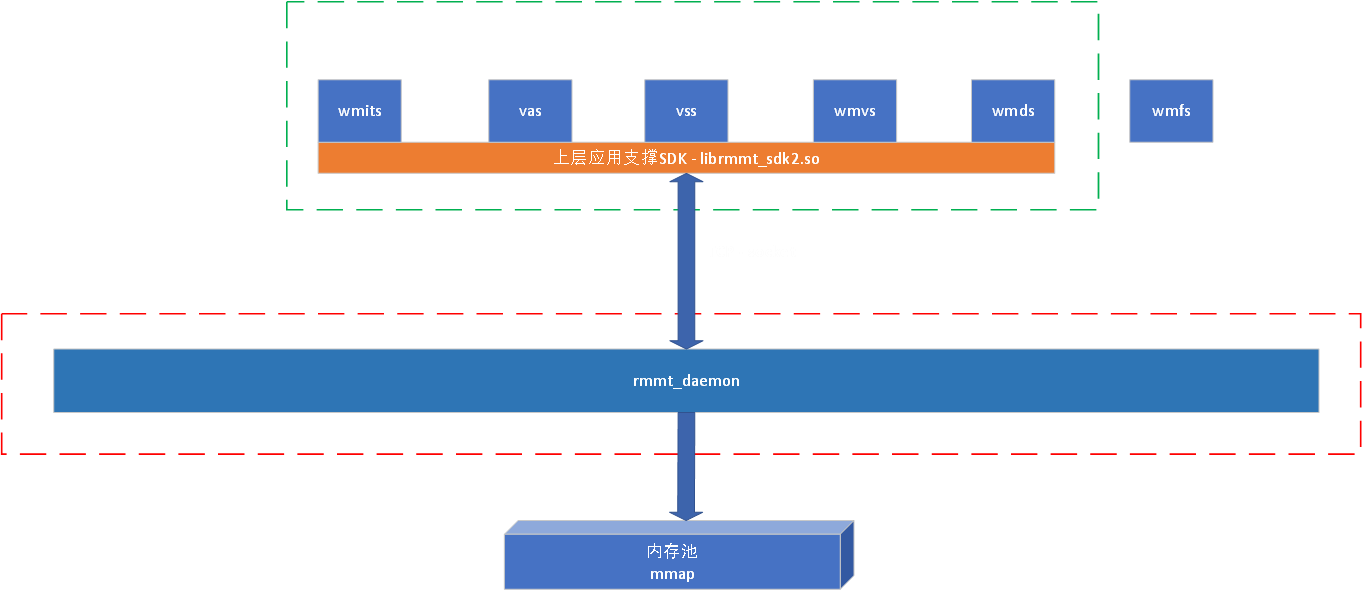
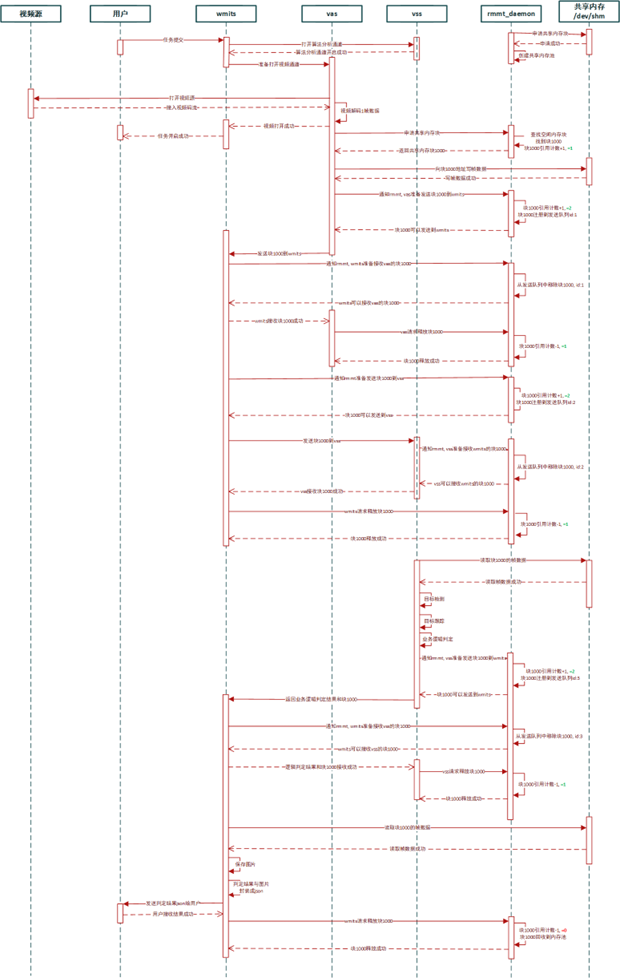
1:首先wmits vas vss三个他们是有socket通信的,然后wmits既做服务端也做客户端,然后vas和vss只做服务端,然后vas和vss之间是不通信的,都是由wmits去发起,比如wmits发起了一个任务,然后他就会通知vas,然后让vas去开始读取视频,读完视频之后要把视频帧的指针等一些信息发会给wmits,然后wmits再把这个指针发给vss,然后vss去做算法处理,然后vss处理完之后再把结果会发给wmits。
2:vas vss wmits都需要跟rmmt那个服务做交互,比如vas要申请一帧数据的共享内存,然后他就要跟rmmt交互申请内存,并且rmmt这时候也要增加一个共享内存指针的引用计数,然后vas要把指针发给wmits,这时候也要通知rmmt让rmmt知道vas把指针发送给了wmtis,然后wmits接收到了指针之后也要通知下rmmt让rmmt知道。
3 疑问
3.1 我们的共享内存消息机制是用的posix还是system V
答:用的posix的,以前应该是记错了,记成system V了。
其实不是自己记错了,aits中用的的就是shm_open然后mmap的方式,只不过你当初让大模型给你写一个共享内存通信的,结果大模型给你写了一个open一个文件然后mmap的方式,这个open文件+mmap既不属于posix也不属于system V。
3.2 rmmt中,不同线程之间的比如访问同一个内存,用的什么锁控制的
答:rmmt中,当其他进程也就是客户端发送命令过来的时候,在do_rtm_cmd里面处理,无非就是申请内存。释放内存、发送内存、接受内存,这四个命令rmmt在处理的时候都要加锁控制,
比如申请内存,加锁,是为了不让不同的进程申请同一块内存,加锁后,即便有多个进程申请内存,那么申请到的不是同一块内存,
比如释放、发送、接收,这个rmmt主要就是管理一些索引,这里也要加锁,比如释放内存,如果不加锁,那么可能多个线程同时减少同一内存节点的引用计数也会出错,发送也是,多个线程要是发送的都是同一个指针,那么引用计数也是会出错。
3.3 疑问:假如一个进程发送给了另外两个进程,然后另外两个进程都同时操作这块内存怎么办
答:只要不是同时写就行,同时读是没问题的,然后我们的业务决定了不会有两个进程同时写一块内存的,因为只有vas会写内存,其他模块都是读内存。所以即便是有多个进程在读内存也没什么问题。
3.4 AITS的几个模块之间的关系
vas和vss不直接通信,都是通过wmits进行管理的,
平台下发任务也是跟wmits进行对接,然后wmits会让vas接入视频,然后数据返回给wmits,然后wmits再跟rmmt说我要发送数据了,然后wmits把数据发给vss进行处理,我们的那些比如拥堵事故的逻辑也在vss里面,
我们aits比较常用的就是vas vss wmits rmmt然后就是视频预览和图片预览。
3.5 rmmt的socket之间有同步吗
答:没有,rmmt因为会把进程的id发过去,不需要
4 代码大体流程
首先/data/chw/AITS/src/rmmt/rmmt_daemon/rmmt_win_daemon.cpp里面的main函数,
就是create,然后mmap
cpp
int SharedMemory::create(const char* name, size_t size)
{
if (hdl) return 1;
int fd = shm_open(name, O_RDWR | O_CREAT, S_IRWXU | S_IRWXG | S_IRWXO);
if (fd == -1) {
return -1;
}
hdl = fd;
if (ftruncate(fd, size) < 0) {
return -2;
}
mapsize = size;
basep = mmap(NULL, size, PROT_WRITE, MAP_SHARED, fd, 0);
if (basep == MAP_FAILED) {
basep = 0;
return -3;
}
return 0;
}g_mpol.init_rst(shm_sz);
然后这里应该是相当于初始化内存池的大小。
cpp
void rmt_start_server(const std::string& suri, uint32_t concurrent_tasks)
{
auto xf = [](int af, int _sock) {
/*
每一个process的librmmt_sdk初始化连入,维护一个TCP|Unix-sock长连接。
初始接收pid(process-id),进行process-local数据结构初始化
然后一个for循环,不断接收命令请求并响应。
通用命令协议格式:(二进制)
流(整个命令体)[ u64(命令ctx), i32(命令类型id), ...(剩余部分为命令数据内容,不同命令类别不一样) ]
*/
sockwrapper sw(_sock);
if (af == AF_INET || af == AF_INET6) {
sk_set_tcpnodelay(sw, true);
}
int pid = 0;
//process本地mem-node引用计数。用来保存本process内有生存期的mem-node信息。
//核心功能是为了让本服务检测到process退出时,假如有部分mem-node未来得及调用析构(命令2),则可以通过此结构进行清理。
map_t<uint64_t, int> lmemRef;
atomic_int pending = {};
try {
cxx_recv(sw, pid);
assert(pid > 0);
cxx_send_string(sw, g_res);
cxx_send(sw, g_memsize_kb);
//step1: add new pid to Map
{
CFutex::scoped_lock wlg(gmt_memMap);
g_pids.insert(pid);
}
//step2: loop for new commands
for (;;) {
std::string cmddata = cxx_recv_string(sw);
assert(cmddata.size() >= 12);
pending.fetch_add(1);
{
uint64_t ucmdctx = *(uint64_t*)cmddata.data();
int cmdid = *(int*)(cmddata.data() + 8);
shared_ptr<MsgSendInfo> msi = make_shared<MsgSendInfo>(256, sw);
msi->bb_out.bset(4);
msi->bb_out << ucmdctx;
CharSeqReader chrd(cmddata.data() + 12, cmddata.size() - 12);
//针对不同命令的处理过程
do_rtm_cmd(pid, lmemRef, ucmdctx, cmdid, chrd, msi->bb_out);
g_taskQue.push([msi, &pending](){ //pipeline异步发送,提升处理效率
byte_buffer& bb = msi->bb_out;
int dsize = (int)bb.data_size();
*(int*)bb.raw_data() = dsize;
send_all(msi->sock, bb.raw_data(), dsize + 4);
pending.fetch_sub(1);
});
}//*/
}
}
catch (...) {
}
//wait for all pending tasks to be completed!
while (pending > 0) {
Sleep(5);
}
vector<int64_t> rc;
ostringstream oss;
oss << "[" << pid << "]#process quit! mn=[";
{//清理本process内来不及释放的内存(如果有的话)
CFutex::scoped_lock _lc(gmt_memMap);
g_pids.erase(pid);
pmem_clean2(pid, lmemRef, rc);
}
//释放清理掉的内存node
//free interprocess memnodes
for (int64_t m : rc) {
shm_free_memnode(m);
oss << m << ",";
}
oss << "]";
LOG_INFO(MSG_LOG,"{}", oss.str());
};///lambda 'xf' definition END.
//异步线程池实现
g_taskQue.set_capacity(concurrent_tasks + 4);
for (uint32_t i = 0; i < concurrent_tasks; i++) {
std::thread([]() {
for (function<void()> t;;) {
g_taskQue.pop(t);
t();
}
}).detach();
}
//启动socket-server
start_sock_raw_serverT(suri, xf, true);
}
cpp
void start_sock_raw_serverT(std::string server_uri, std::function<void(int af,int sock)>&& cb,bool bLoopHere)
{
using namespace std;
//step1> analysis uri
sockaddr_ex bindaddr;
{
size_t p1 = server_uri.find("://");
if (p1 == string::npos)
throw GeneralException(-1, "invalid server uri! not contain ://");
server_uri[p1] = 0;
if (strcmp(server_uri.data(), "ip") == 0) {
size_t p2 = server_uri.find(':', p1 + 3);
server_uri[p2] = 0;
int port = 0; sscanf(&server_uri[p2 + 1], "%d", &port);
char* ip = &server_uri[p1 + 3];
if (sk_tcp_addr(bindaddr, ip, port)) {
throw GeneralException(-1).format_errmsg("gen ip address failed! ip=%s,port=%d", ip, port);
}
}
else if (strcmp(server_uri.data(), "un") == 0) {
sk_unix_addr(bindaddr, &server_uri[p1 + 3]);
}
}
if (bindaddr.sa_family == 0)
throw GeneralException(-1, string("unrecognized protocol! uri=") + server_uri);
SOCKET server = sk_create(bindaddr.sa_family, SOCK_STREAM, 0);
if (server == INVALID_SOCKET) throw GeneralException(-2, system_errmsg());
if (bindaddr.sa_family == AF_INET || bindaddr.sa_family == AF_INET6) {
int on = 1;
setsockopt(server, SOL_SOCKET, SO_REUSEADDR, (char*)&on, 4);
}
if (::bind(server, &bindaddr, bindaddr.addr_len())) {
GeneralException e(-3, system_errmsg());
sk_close(server);
throw e;
}
if (listen(server, SOMAXCONN)) {
GeneralException e(-4, system_errmsg());
sk_close(server);
throw e;
}
auto loop = [cb](SOCKET sock) {
for (sockaddr_ex addr;;) {
SOCKET s = sk_accept2(sock,addr);
if (s == INVALID_SOCKET) {
perror("accept");
break;
}
std::thread(cb, (int)addr.sa_family, (int)s).detach();
}
perror("socket-accept!");
sk_close(sock);
};
if (bLoopHere) {
loop(server);
}
else {
std::thread(loop, server).detach();
}
}这里xf这个lambda表达式其实是相当于是当接收到请求之后的处理然后,然后start_sock_raw_serverT这个函数起了一个服务,当其他进程链接这个rmmt服务后,就会用哪个lambda表达式处理客户端发过来的请求,
cpp
static void do_rtm_cmd(int pid, map_t<uint64_t,int>& lmemRef, uint64_t uctx, int cmdid, CharSeqReader& chrd,byte_buffer& out)
{
/*
*/
try {
//printf("[%d]cmdId=%d\n", pid,cmdid); fflush(stdout);
switch (cmdid)
{
case 1: //alloc-memory
{
uint32_t msize, malign;
chrd >> msize >> malign;
int64_t mn = shm_alloc_memnode(msize, malign);
#ifdef _DEBUG_PRINT
printf("[%06d] alloc mem @%ld\n", pid, (long)mn);
#endif
if (mn < 0) {
out << (int)-1 << BBPW("memory allocate failed!");
return;
} {
CFutex::scoped_lock _l(gmt_memMap);
mem_addnew(mn);
}
lmemRef[mn]++; //*/
out << (int)0 << mn;
}break;
case 2: //free memory
{
int64_t mn = 0;
chrd >> mn;
lmemRef[mn]--; bool bf = false; {
CFutex::scoped_lock _l(gmt_memMap);
bf = mem_deref( mn);
}
if (bf) {
shm_free_memnode(mn);
}
#ifdef _DEBUG_PRINT
LOG_INFO(MSG_LOG,"[{}] free mem @{} {}", pid, (long)mn , bf ? "(Freed!)" : "");
#endif
out << (int)0;
}break;
case 4://pre-send memory!
{
static atomic<int64_t> uid_(1);
int64_t bid = uid_.fetch_add(1), mn = 0;
uint32_t n = 0;
chrd >> n;
#ifdef _DEBUG_PRINT
ostringstream oss;
oss << "[" << pid << "] pre-send mem(s),bid=" << bid << ",ct=" << n << "(";
#endif
SendinfMemInfo simi;
simi.from_pid = pid;
if (n > 0) {
simi.vmn.resize(n);
chrd.read_data((void*)simi.vmn.data(), n * sizeof(uint64_t));
#ifdef _DEBUG_PRINT
for (auto x : simi.vmn) {
oss << x << ",";
}
#endif // _DEBUG
}
chrd >> simi.to_pid;
{
CFutex::scoped_lock wlg(gmt_memMap);
for (auto x : simi.vmn) {
mem_addref(x);
}
g_sdmMap[bid].swap(simi);
}
out << (int)0 << bid;
#ifdef _DEBUG_PRINT
LOG_INFO(MSG_LOG,"{}).", oss.str());
#endif
}break;
case 5://recv memory!
{
uint32_t n = 0; int64_t bid = 0; int r_pid = 0;
chrd >> bid >> n >> r_pid;
#ifdef _DEBUG_PRINT
ostringstream oss;
oss << "[" << pid << "] recv mem(s),bid="<< bid << ",ct=" << n << "(";
#endif
{
CFutex::scoped_lock wlg(gmt_memMap);
auto it = g_sdmMap.find(bid);
assert(it != g_sdmMap.end());
auto& simi=(it->second);
assert(n == simi.vmn.size() && r_pid==simi.from_pid && pid==simi.to_pid);
for (uint32_t i = 0; i < n; i++) {
uint64_t mn = simi.vmn[i];
lmemRef[mn]++;
#ifdef _DEBUG_PRINT
oss << mn << ",";
#endif
}
g_sdmMap.erase(bid);
}
out << (int)0;
#ifdef _DEBUG_PRINT
LOG_INFO(MSG_LOG,"{}).", oss.str());
#endif
}break;
default:
out << (int)1001 << BBPW("invalid command id!");
break;
}
}
catch (std::exception& e) {
assert(e.what() == nullptr);
}
catch (GeneralException& e) {
printf("%d %s\n", e.err_code(), e.err_str());
}
}这个是真正处理发过来的命令的代码。