Linux 网络编程
从我们熟悉的 printf 到复杂的分布式系统,几乎所有现代软件都离不开网络。本章将带领我们深入Linux的底层世界,学习如何使用最核心的套接字 (Socket) API 来构建网络应用程序。我们将从最基础的网络概念开始,逐步掌握TCP、UDP通信,深入理解高性能服务器的基石------I/O多路复用,最终将理论与实践结合,构建一个功能完备的网络服务。
第一部分:网络编程基础理论篇
总目标:在深入编程之前,彻底理解数据是如何从一台电脑的应用程序,穿越复杂的网络世界,精准抵达另一台电脑的应用程序的。本部分将理论与实践紧密结合,通过大量命令行工具来亲手验证每一个核心概念。
1. 计算机网络全景图
1.1 一次网络请求的奇幻漂流
我们从一个最经典、也最能贯穿所有知识点的问题开始:当你在浏览器地址栏输入 http://www.example.com 并按下回车后,究竟发生了什么?
这个问题看似简单,其背后却涵盖了从应用层到物理层的几乎所有核心网络协议和设备。我们可以将其分解为一场接力赛:
- 应用层 (DNS 解析) :浏览器首先需要知道
www.example.com这台服务器在哪。它会向 DNS (Domain Name System) 服务器发起请求(例如:DNS 服务器为 8.8.8.8),将这个"域名"翻译成一个具体的 IP 地址(例如93.184.216.34)。 - 传输层 (TCP 握手):浏览器准备与服务器建立一条可靠的数据通道。它会使用 TCP 协议,向目标 IP 地址的 80 端口(HTTP 默认端口)发起"三次握手",建立连接。
- 网络层 (路由决策) :操作系统将 TCP 数据段打包成一个 IP 数据包,源 IP 是本机 IP(如
192.168.1.100),目标 IP 是93.184.216.34。接下来是最关键的路由决策:- 子网判断 :操作系统取出自己的子网掩码 (如
255.255.255.0),与本机 IP 和目标 IP 分别进行"按位与"运算,得到它们各自的网络地址。 - 决策 :运算后发现,本机网络地址为
192.168.1.0,而目标网络地址为93.184.216.0。两者不相等,操作系统因此判定目标主机位于外部网络 ,数据包必须发送给默认网关 (通常是192.168.1.1,即你的家庭路由器)。
- 子网判断 :操作系统取出自己的子网掩码 (如
- 数据链路层 (ARP 解析与帧封装) :现在的目标是把 IP 包发送给网关。
- ARP 解析 :操作系统需要知道网关的 MAC 地址。它会先检查自己的 ARP 缓存表。如果找不到网关 IP (
192.168.1.1) 对应的 MAC 地址,就会发起一次 ARP 广播,向整个局域网喊话:"谁是192.168.1.1?请告诉我你的 MAC 地址!"网关收到后会单播回应自己的 MAC 地址。 - 帧封装 :操作系统将 IP 包封装成一个以太网帧。这里的关键在于地址的填写:帧头里的目标 MAC 地址 是网关的 MAC 地址 ,而 IP 头里的目标 IP 地址仍然是 最终服务器的 IP
93.184.216.34。
- ARP 解析 :操作系统需要知道网关的 MAC 地址。它会先检查自己的 ARP 缓存表。如果找不到网关 IP (
- 物理层 (发送):最终,这张新鲜出炉的以太网帧通过网卡,转换成电信号或光信号,在网线或空气中传播,第一站成功抵达你的路由器。
- 跨越广域网 :路由器收到数据帧后,解开它,看到 IP 头中的目标 IP 地址,然后查询自己的路由表,将数据包从连接外网的端口转发给下一个路由器。这个过程会重复很多次,数据包就像一个包裹,被无数个路由器接力转发,最终抵达
example.com的服务器。 - 服务器处理与响应:服务器收到数据包后,层层解开,发现是一个 HTTP 请求,于是处理该请求(例如,返回一个网页),然后将响应数据按照同样的方式,层层打包,再通过广域网传回你的电脑。
- 浏览器渲染:你的电脑收到响应数据,层层解包,最终浏览器拿到 HTML 内容,并将其渲染成你所看到的网页。
这个过程就像一次精心策划的跨国旅行,每一步都有严格的规则(协议)和专业的交通工具(设备)参与。
1.2 分层思想
为了管理如此复杂的通信过程,计算机科学家们引入了分层的思想,将庞大的问题分解成若干个更容易管理的小问题。最经典的模型就是 TCP/IP 五层模型。
| 层级 | 名称 | 核心功能 | 数据单位 | 典型协议/设备 |
|---|---|---|---|---|
| 应用层 | Application Layer | 为应用程序提供网络服务 | 消息 (Message) | HTTP, FTP, DNS, SMTP |
| 传输层 | Transport Layer | 提供端到端(进程到进程)的通信服务 | 段 (Segment) | TCP, UDP |
| 网络层 | Network Layer | 提供主机到主机的寻址和路由 | 包 (Packet) | IP, ICMP, OSPF / 路由器 (Router) |
| 数据链路层 | Data Link Layer | 在同一链路上的节点间传输数据 | 帧 (Frame) | Ethernet, PPP,ARP / 交换机 (Switch), 网卡 (NIC) |
| 物理层 | Physical Layer | 传输原始的比特流 (0101) | 比特 (Bit) | 网线, 光纤, WiFi 信号 |
核心思想:每一层都只关心自己的任务,并使用下一层提供的服务,同时为上一层提供服务。例如,传输层不关心数据包是怎么在网络中跳转的(这是网络层的任务),它只关心数据是否完整、有序地从一个进程到达了另一个进程。
1.3 数据封装与解封装
数据在发送时,会从上到下逐层"打包",这个过程称为封装。每一层都会在上一层的数据前面加上自己的"头部"信息(Header)。
- 应用层数据(如 "GET /index.html")
[TCP头]+ 应用层数据 -> TCP 段 (Segment)[IP头]+ TCP 段 -> IP 包 (Packet)[帧头]+ IP 包 +[帧尾]-> 以太网帧 (Frame)
当数据到达目的地后,会从下到上逐层"拆包",验证并移除头部信息,这个过程称为解封装。这个过程就像是套娃,一层层打开,最终拿到核心数据。
2. 数据链路层 - 局域网内的"面对面"通信
目标:理解在同一个局域网(例如,连接到同一个 WiFi 的所有设备)中,两台电脑是如何直接找到对方的。
2.1 MAC 地址 (Media Access Control Address)
- 它是什么 :
MAC地址,全称媒体访问控制地址 (Media Access Control Address),是一个烧录在网卡 (NIC, Network Interface Card) 上的全球唯一的物理地址。它就像是设备的"身份证号",一出厂就被确定,并且正常情况下不会改变。 - 格式 :它通常表示为 6 个字节(48位)的十六进制数,例如
08:00:27:7D:9E:0F。前 3 个字节是组织唯一标识符 (OUI),由 IEEE 分配给设备制造商;后 3 个字节由制造商自行分配。 - 作用:在局域网(如一个家庭、一个办公室)内部,设备之间通信最终依赖的是 MAC 地址,而不是 IP 地址。
MAC 地址的现实世界视角
从现实世界的硬件角度来看,MAC 地址的归属问题可以得到更清晰的解释。例如,像 ESP32 这样的 Wi-Fi 芯片,其网络模块在出厂时就被赋予了全球唯一的 MAC 地址。这揭示了一个核心原则:MAC 地址是网络接口 (Network Interface) 的物理属性,而非主机 (Host) 本身的属性。因此,我们应该说"网卡拥有 MAC 地址",而不是"电脑拥有 MAC 地址"。这个原则也自然地引出了两个重要推论:首先,一台主机完全可以拥有多个 MAC 地址,只要它配备了多个网络接口,比如同时安装了有线网卡和无线网卡。其次,一个设备如果没有任何网络接口,比如一块基础的 STM32 开发板,那么它就与 MAC 地址无关,因为它从物理上就无法接入需要 MAC 地址寻址的网络。
系统命令与验证:
在 Linux 系统中,你可以使用 ip addr 或 ifconfig (较旧的工具) 命令来查看你电脑的 MAC 地址。
bash
ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000
link/ether 00:0c:29:e0:56:0d brd ff:ff:ff:ff:ff:ff
altname enp2s1这段 ip addr 的输出报告了系统上两个网络接口的完整状态:
首先分析名为 lo 的接口,这是系统内部的回环(Loopback)接口 。它的第一行为状态标志:LOOPBACK 确认了这是一个用于本机进程间自我通信的虚拟接口;UP 表示此接口已被管理员(或系统默认)设置为启用状态;而 LOWER_UP 则表明其链路层是连通的。inet 127.0.0.1/8 scope host lo 详细定义了其 IPv4 配置:inet 指明这是一个 IPv4 地址,127.0.0.1 是全球标准的本地主机地址(即 localhost);/8 是 CIDR (Classless Inter-Domain Routing)表示法,等同于子网掩码 255.0.0.0,它将整个 127.x.x.x 网段都保留给了回环地址;scope host 则严格限制了此地址的有效范围仅在本机内部,数据包不会被发送到外部网络。同样,inet6 ::1/128 scope host 定义了其 IPv6 配置,::1 是 IPv6 的回环地址,/128 表示这是一个仅包含单个主机的子网,其作用域 scope host 同样限定于本机。
其次,名为 ens33 的接口是一个以太网卡 ,这一点可以从其 link/ether 后的 MAC 地址 00:0c:29:e0:56:0d 得到证实,其中 00:0c:29 的前缀属于 VMware, 说明这是一台虚拟机。BROADCAST 和 MULTICAST 表明它支持广播和多播,是网卡的标准能力。UP 意味着管理员已经尝试启用了这个接口。NO-CARRIER 是关键的标志 ,它明确指出物理链路层没有检测到载波信号,通俗地讲就是"网线没有插好"或者虚拟网卡没有连接到虚拟网络。这个标志直接导致了接口的最终工作状态为 state DOWN,即尽管被命令启用,但由于缺乏物理连接,它实际上是关闭且无法工作的。正因如此,该接口下面没有任何 inet (IPv4) 或 inet6 (IPv6) 地址信息,因为它根本无法在网络上进行通信来获取或配置一个 IP 地址。
2.2 以太网 (Ethernet) 与交换机 (Switch)
- 以太网:是当今最普遍的局域网技术。它定义了数据在局域网内如何打包成"帧 (Frame)"以及如何传输。一个以太网帧中包含了目标 MAC 地址、源 MAC 地址以及要传输的数据(例如一个 IP 包)。
- 交换机 :是构建局域网的核心设备。它像一个聪明的交通警察,内部有一张 MAC 地址表,记录着哪个 MAC 地址的设备连接在哪个物理端口上。当交换机收到一个数据帧时,它会查看帧中的"目标 MAC 地址",然后只将这个帧从对应的端口转发出去,直接送达目标设备,而不会干扰局域网内的其他设备。这种精确转发大大提高了局域网的通信效率。
2.3 核心协议:ARP (地址解析协议)
- 解决的问题 :ARP (Address Resolution Protocol) 协议专门用于解决一个核心问题:在同一个局域网内,当只知道一个设备的 IP 地址时,如何才能获取到它的 MAC 地址?
- 工作原理 :这个过程非常像是在一个房间里找人:
- 广播喊话 :当主机 A (IP:
192.168.1.100) 想要发送数据给主机 B (IP:192.168.1.101),但不知道其 MAC 地址时,它会向局域网内的所有设备发送一个 ARP 请求广播(广播帧中包含它所要查询主机的 IP 地址,目的 MAC 地址填的是 FF:FF:FF:FF:FF:FF,表示这是一个"广播"地址)。这个广播帧的内容可以通俗地理解为:"谁是192.168.1.101?请把你的 MAC 地址告诉我!" - 单播回应 :局域网内的所有设备都会收到这个广播,但只有 IP 地址是
192.168.1.101的主机 B 会响应。主机 B 会直接向主机 A 发送一个 ARP 响应包(这是一个单播,而不是广播),内容是:"我是192.168.1.101,我的 MAC 地址是xx:xx:xx:xx:xx:xx。" - 缓存结果 :主机 A 收到响应后,就知道了主机 B 的 MAC 地址,并将这个"IP-MAC"对应关系存入自己的 ARP 缓存表中,以备下次使用。这样就不用每次都去广播询问了。
- 广播喊话 :当主机 A (IP:
系统命令与验证:
你可以使用 arp -a 命令来查看你电脑当前的 ARP 缓存表。
bash
$ arp -e
Address HWtype HWaddress Flags Mask Iface
192.168.7.254 ether 00:50:56:fe:6d:37 C ens33
_gateway ether 00:50:56:f3:78:45 C ens33
$ arp -a
_gateway (192.168.7.2) at 00:50:56:f3:78:45 [ether] on ens33主机(通过名为
ens33的网卡)已经成功解析并缓存了同一局域网下的两个设备的物理地址:一个是 IP 为192.168.7.254的设备,其 MAC 地址是00:50:56:fe:6d:37;另一个则是网络的默认网关_gateway,它的 IP 地址为192.168.7.2,MAC 地址是00:50:56:f3:78:45。这个缓存的存在至关重要,它意味着当电脑需要访问互联网(通过网关)时,可以直接从表中查出网关的 MAC 地址来封装数据帧,而无需每次都通过广播去询问,从而实现了高效的本地网络通信。
至此,数据链路层如何在局域网内部实现点对点通信的核心原理已经清晰。接下来,我们将进入更广阔的世界------网络层,看看数据包是如何跨越一个个局域网,实现全球路由的。
2.4 本层封装:以太网帧
当网络层将一个 IP 数据包递交给数据链路层后,后者会将其封装成一个以太网帧 (Ethernet Frame)。这是数据在物理介质(如网线)上传输的基本单位。
- 封装过程 :数据链路层会在 IP 数据包的前面加上一个帧头 (Header) ,在末尾加上一个帧尾 (Trailer) 。
- 帧头 (Header) :长度固定为 14 字节 。包含了最关键的目标 MAC 地址 (6 字节) 和源 MAC 地址 (6 字节),以及一个类型字段 (2 字节),用于指明内部承载的数据是 IP 包、ARP 请求还是其他类型。
- 数据 (Data) :即 IP 数据包。其长度范围为 46 - 1500 字节。如果上层传来的 IP 包不足 46 字节,数据链路层会自动填充(pad)至 46 字节。1500 字节这个最大值被称为最大传输单元 (MTU)。
- 帧尾 (Trailer) :长度固定为 4 字节 。包含帧检验序列 (FCS),用于检测数据在传输过程中是否出现了错误。
- 数据结构:
Ethernet Frame IP Packet Data (Data) Ethernet Header Ethernet Trailer
3. 网络层 - 跨越山海的寻址
目标:理解数据包是如何从你的局域网出发,穿越无数个路由器,最终精准抵达世界上任何一个角落的服务器的。
网络层的由来:MAC 和 IP 地址为何两者皆需?
以太网协议,依靠 MAC 地址发送数据。理论上,单单依靠 MAC 地址,北京的网卡就可以找到深圳的网卡了,既然网卡已经有了全球唯一的 MAC 地址,为什么我们还需要 IP 地址,特别是其"主机部分"来再次标识一台设备呢?
这个问题触及了网络分层设计的核心。简单来说,它们分工不同,解决了不同规模下的寻址效率问题。把互联网比作一个全球邮政系统:MAC 地址如同每个人的身份证号 ,全球唯一,能最终确定身份,但邮局无法靠它来定位和送信。而 IP 地址则像是分级的家庭住址 (国家-城市-街道-门牌号)。网络部分 好比"街道",让主干路由器(邮政中心)能高效地将数据包路由到目标局域网,而无需关心网络内的具体设备。一旦数据包抵达了目标"街道",主机部分就如同"门牌号",结合 ARP 协议,在局域网内部找到对应 MAC 地址(身份证号)的设备,完成"最后一公里"的精准投递。这种分层寻址机制,使得全球路由既高效又可扩展。
3.1 IP 地址 (IP Address)
如果说 MAC 地址是设备的"身份证号",那么 IP 地址 (Internet Protocol Address) 更像是你家的"邮寄地址"。它是一个逻辑地址,由网络管理员分配,并且是可以改变的。其核心结构包含了两部分信息:网络部分 (Network ID)和主机部分(Host ID)。网络部分好比"街道名称",用于标识设备所在的局域网;主机部分则如同"门牌号",用于标识该网络中的具体设备。同一局域网内的所有设备,其IP地址的网络部分必须是完全相同的。
-
格式 (IPv4) :我们最常见的是 IPv4 地址,由 32 位二进制数组成,通常写成四个十进制数的形式,例如
192.168.1.101。 -
核心结构:一个 IP 地址并非一个单一的号码,它内部包含了两部分信息:
- 网络部分 (Network ID):标识设备所在的局域网。
- 主机部分 (Host ID):标识该网络中的具体设备。
例如,对于
192.168.1.101这个地址,可能192.168.1是网络部分,代表"xx小区xx栋",而101是主机部分,代表"101室"。同一个局域网内的所有设备,其 IP 地址的网络部分必须是相同的。
- 特殊的 IP 地址 :
127.0.0.1:一个特殊的回环地址 (Loopback Address),代表"本机"。发往这个地址的数据包不会离开本机,常用于本地测试。- 主机号全为 0 的地址:代表网络本身,如
192.168.1.0。 - 主机号全为 1 (二进制) 的地址:代表该网络的广播地址,如
192.168.1.255。
既然 MAC 地址属于网卡,那么如果一台主机有两张网卡(两个 MAC 地址),它会拥有几个 IP 地址?
这个问题的答案是:"网络层"出现以后,每台计算机有了两种地址,一种是 MAC 地址,另一种是网络地址。两种地址之间没有任何联系 ,MAC 地址是绑定在网卡上的,网络地址则是管理员分配的,它们只是随机组合 在一起。通常每个网络接口都会获取一个独立的 IP 地址。核心在于,IP 地址并不是直接分配给一台"主机"的,而是分配给主机的"网络接口 "。当一个网络接口(如一张网卡)被启用并接入网络时,它就会为自己获取一个 IP 地址。因此,一台拥有有线和无线两张网卡的主机,如果同时连接到网络,那么它将拥有两个 MAC 地址和两个对应的 IP 地址。此时,当主机上的程序需要访问外部网络时,操作系统会根据内部的**路由表 ** 规则,来决定数据包应该从哪个网络接口(即使用哪个源 IP 地址)发送出去。
3.2 子网掩码 (Subnet Mask)
我们如何知道一个 IP 地址哪部分是网络号,哪部分是主机号呢?这就是子网掩码 (Subnet Mask) 的作用。
- 作用:子网掩码像一把尺子,与 IP 地址进行"按位与"运算,从而计算出网络地址。
- 格式 :子网掩码的格式与 IP 地址类似,也是 32 位,由一串连续的 1 和一串连续的 0 组成。1 对应的部分是网络位,0 对应的部分是主机位。
- 例如,子网掩码
255.255.255.0(二进制为11111111.11111111.11111111.00000000) 意味着前 24 位是网络位,后 8 位是主机位。
- 例如,子网掩码
- 计算示例 :
- IP 地址:
192.168.1.101 - 子网掩码:
255.255.255.0 - 将两者按位与运算,得到网络地址:
192.168.1.0。
- IP 地址:
系统命令与验证:
再次使用 ip addr 命令,我们可以同时看到 IP 地址和子网掩码。
bash
$ ip addr show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:e0:56:0d brd ff:ff:ff:ff:ff:ff
altname enp2s1
inet 192.168.7.129/24 brd 192.168.7.255 scope global dynamic noprefixroute ens33
valid_lft 1406sec preferred_lft 1406sec
inet6 fe80::a2dc:7b3:9352:60d7/64 scope link noprefixroute
valid_lft forever preferred_lft forever这里的
/24就是子网掩码的另一种表示法,称为 CIDR (Classless Inter-Domain Routing) 表示法。它表示子网掩码的前 24 位是 1,即255.255.255.0。192.168.7.255指的是该网络的广播地址。
192.168.7.255:这是一个 IP 地址。- /24: 这就是前缀长度。它表示这个 IP 地址的二进制形式中,从左边数起的前 24 位是网络部分,用于标识网络本身。
- 剩下的 32 - 24 = 8 位是主机部分 ,用于标识该网络中的具体设备,意味着这个网络最多可以包含 256-2 个 IP 地址(在这 256 个地址中,有两个是特殊的,不能分配给普通主机:1.主机部分全为 0 的地址(**网络地址:**192.168.7.0)用来代表整个网络 2. 主机部分全为 1 的地址 (广播地址:
192.168.7.255)向这个地址发送数据包,网络内的所有主机都会收到)
3.3 IP 协议与路由 (IP Protocol & Routing)
- IP 协议 :IP 协议是网络层的核心。它规定了网络层数据的格式,即 IP 数据包 (IP Packet) 。IP 包的头部包含了最重要的两个信息:源 IP 地址 和目标 IP 地址。IP 协议的任务就是"尽最大努力"(Best-Effort) 将这个包从源头送到目的地,但它本身不保证可靠性------包可能会丢失、重复或乱序。
- 路由器 (Router) :路由器是连接不同网络的"交通枢纽"。一台路由器至少连接着两个网络,比如你的家庭路由器,一端连接你家的局域网,另一端连接运营商的网络。它的核心工作就是路径选择 和数据包转发。
- 路由表 (Routing Table) :每个路由器(以及你的电脑)内部都维护着一张路由表 ,这张表就像是 GPS 导航地图,告诉路由器去往不同网络的数据包应该从哪个"出口"(网络接口)发出去。
- 当路由器收到一个 IP 包,它会查看包头的目标 IP 地址。
- 然后,它会查询自己的路由表,看哪个条目能匹配这个目标地址。
- 最后,根据匹配到的条目,将数据包从正确的接口转发出去,交给"下一跳"(Next Hop) 的路由器。这个过程被称为"逐跳转发"。
- 网关 (Gateway) :在一个局-域网中,当一台主机想发送数据给另一个网络中的主机时,它需要将数据包先发给一个指定的设备,这个设备就是网关,通常由路由器担任。网关负责将局-域网的数据包转发到外部网络。
值得注意的是,网关的 IP 地址在局域网中通常被设置为
.1或.2(例如192.168.1.1)。这并非技术强制,更多是网络设备厂商和管理员为了便于记忆和管理的行业惯例。在实际部署中,路由器作为 DHCP 服务器,会把自身(如.1)配置为网段的网关,并从一个预设的地址池(如192.168.1.100-200)中为其他设备分配 IP。如果遇到网关是.2的情况,通常是因为网络中存在另一个设备(如光猫)已经占用了.1这个地址。因此,这个地址的设置是"惯例"与"具体网络环境"共同作用的结果。
理论联系现实:交换机、路由器与网关的交并关系
我们刚刚分别学习了交换机、路由器和网关这几个独立的网络概念,但它们在现实世界中是如何体现和关联的?这是一个核心且容易混淆的问题。要彻底理清它们,我们可以从它们各自的核心职能和最终的交并关系入手。
首先,交换机 是"局域网内部的智能交通警察",工作在数据链路层(二层),依据MAC地址在同一网络 内部精确转发数据帧;路由器 是"网络间的导航员",工作在网络层(三层),根据IP地址在不同网络 之间选择最佳路径来转发数据包;而网关则是一个更抽象的角色------"网络的出入境关口",其本质作用是连接两个异构网络并作为出口,这个角色在TCP/IP世界里通常就由路由器来扮演。
| 特性 | 交换机 (Switch) | 路由器 (Router) | 网关 (Gateway) |
|---|---|---|---|
| OSI层级 | Layer 2 (数据链路层) | Layer 3 (网络层) | 概念上任意层,通常指Layer 3+ |
| 使用地址 | MAC地址 (物理地址) | IP地址 (逻辑地址) | IP地址 |
| 核心功能 | 同一网段内的设备间转发 | 不同网段间的路径选择与转发 | 异构网络间的连接与协议转换 |
| 工作范围 | 局域网内部 (LAN) | 连接不同的网络 (LAN-LAN, LAN-WAN) | 作为一个网络的"出口" |
这种区别最终引出了它们在现代网络设备中的交并结构关系 。核心结论是:在今天的绝大多数场景下(尤其是家庭和小型办公网络),我们购买的"路由器"这个物理设备,既集成了交换机的功能,又扮演着网关的逻辑角色。
- 路由器
是网关 (Router IS a Gateway) : 当你的电脑需要访问外部网络时,它必须将数据包发往"默认网关",而这个网关地址,正是你的路由器的IP。因此,路由器扮演了网关的角色。 - 路由器
内置交换机 (Router CONTAINS a Switch) : 家用路由器背后的多个LAN口,其本质就是一个小型的交换机,负责局域网内部设备间的通信。因此,路由器包含了交换机的功能。
下图清晰地展示了现代家用路由器是如何成为一个"三合一"集成设备的:
你的局域网 (Your LAN - 内部网络) 你的'无线路由器'物理设备 网关角色 (Gateway Role) 交换机功能 (Switch Function) 无线功能 (Wireless AP) 互联网 (Internet - 外部网络) 连接内部与外部 管理内部网络 管理无线设备 有线连接 有线连接 无线连接 电脑1 电脑2 手机 Wi-Fi天线 LAN 1 | LAN 2 | LAN 3 | LAN 4 路由核心
NAT, 防火墙 Internet RouterBox
总结来说,路由器和网关在功能上有巨大交集(在TCP/IP网络中,路由器是实现网关功能最常见的设备),而我们购买的家用"路由器"产品,则是路由器核心 、交换机和**无线接入点(AP)**功能的组合体。
系统命令与验证:
-
查看路由表 : 你可以使用
ip route或route -n命令查看你电脑的路由表。bash$ ip route default via 192.168.7.2 dev ens33 proto dhcp metric 100 169.254.0.0/16 dev ens33 scope link metric 1000 192.168.7.0/24 dev ens33 proto kernel scope link src 192.168.7.129 metric 100第一条 (默认路由): 是最重要的默认路由 。它告诉操作系统:任何去往未知网络(即不在局域网内,通常指互联网)的数据包,都应该通过
ens33这个网络接口,发送给 IP 地址为192.168.7.2的网关。第二条 (本地链路): 是用于本地链路通信的地址范围,通常在无法从 DHCP 服务器获取 IP 地址时自动分配。
第三条 (局域网路由): 定义了本地局域网的路由。它说明任何发往
192.168.7.x网段内设备的数据包,都应该直接通过ens33接口发送,并在数据链路层通过 ARP 协议直接寻找目标 MAC 地址,而无需经过网关。metric 100: 这是路由的"成本"或"优先级"。当有多条路由可以到达同一个目标时,系统会优先选择 metric 值更低的路径。
169.254.0.0/16这条路由是什么?读者可能会注意到
169.254.0.0/16这条规则,它并非另一个物理网络,而是操作系统为实现网络健壮性而自动添加的一条备用规则。这个地址段是由IETF在RFC 3927中标准化的"链路本地地址 (Link-Local Address)",其设计目标是让同一物理链路上的设备,在没有手动配置IP、也没有DHCP服务器的"零配置"网络环境下,依然能自动获取一个IP地址并互相通信。其工作流程是:当设备通过DHCP获取IP失败后,它会在此地址段内随机挑选一个IP,并通过ARP确认未被占用后临时使用。因此,路由表中
169.254.0.0/16 dev ens33 scope link ...这条规则的含义就是:"任何发往此特殊地址段的数据包,都应被视为局域网内部通信,scope link表示直接通过ens33接口发送,而绝不能发往默认网关。" 在正常网络中,这条路由通常处于备用状态,但它的存在是现代操作系统网络协议栈健壮性的一个重要体现。
-
测试连通性 :
ping是一个家喻户晓的命令,它使用 ICMP 协议来测试你和目标主机之间是否"通畅"。bash$ ping www.baidu.com PING www.baidu.com (198.18.0.229) 56(84) bytes of data. 64 bytes from 198.18.0.229 (198.18.0.229): icmp_seq=1 ttl=128 time=0.535 ms 64 bytes from 198.18.0.229 (198.18.0.229): icmp_seq=2 ttl=128 time=0.689 ms 64 bytes from 198.18.0.229 (198.18.0.229): icmp_seq=3 ttl=128 time=0.677 ms 64 bytes from 198.18.0.229 (198.18.0.229): icmp_seq=4 ttl=128 time=0.669 m --- www.baidu.com ping statistics --- 4 packets transmitted, 4 received, 0% packet loss, time 3005ms rtt min/avg/max/mdev = 0.535/0.642/0.689/0.062 msttl(Time to Live) 是数据包的"生命周期",每经过一个路由器就会减 1,减到 0 就会被丢弃,以防止数据包在网络中无限循环。time则是往返延迟。 -
追踪路径 :
traceroute是一个更强大的工具,它可以显示出你的数据包从本机到目标地址所经过的每一个路由器。bash$ traceroute www.baidu.com traceroute to www.baidu.com (14.215.177.38), 30 hops max, 60 byte packets 1 _gateway (10.0.2.2) 0.370 ms 0.264 ms 0.244 ms 2 10.86.132.1 (10.86.132.1) 2.430 ms 2.411 ms 2.396 ms 3 * * * 4 124.74.244.49 (124.74.244.49) 2.623 ms 124.74.244.41 (124.74.244.41) 2.825 ms 2.810 ms ... (中间经过的许多路由器) 12 14.215.177.38 (14.215.177.38) 30.862 ms 30.896 ms 30.880 ms
3.4 本层封装:IP 数据包
当传输层将一个 TCP 段或 UDP 数据报递交给网络层后,后者会将其封装成一个 IP 数据包 (IP Packet)。
- 封装过程 :网络层将整个传输层的数据段(TCP 段或 UDP 数据报)作为自己的数据 (Data) 部分,并在其前面加上一个 IP 头 (IP Header) 。
- IP 头 (Header) :长度是可变的 ,范围为 20 - 60 字节。基础长度为 20 字节,包含了版本、头部长度、总长度、TTL、上层协议类型、源 IP 地址、目标 IP 地址等核心信息。额外的 40 字节可用于可选字段。
- 数据 (Data) :即 TCP 段或 UDP 数据报。理论上,由于 IP 头的总长度字段是 16 位,一个 IP 包最大可达 65535 字节,因此数据部分最大可为
65535 - 20 = 65515字节。但在实际传输中,如果 IP 包的总大小超过了下层(如以太网)的 MTU (1500 字节),则会被分片 (Fragment) 成多个较小的数据包进行传输。
- 数据结构:
IP Packet Ethernet Frame IP Header Ethernet Header Ethernet Trailer IP Packet Data (Data)
4. 传输层 - 进程间的对话管道
目标:理解数据到达目标电脑后,是如何准确地交给指定的应用程序(例如,浏览器而不是 QQ)的,以及如何实现可靠或高速的数据传输。
4.1 端口 (Port)
- 它是什么 :如果说 IP 地址是楼栋地址,那么端口 (Port) 就是房间号。每条 IP 地址在每个传输协议里都独立拥有一整套 16 位端口空间,也就是 0~65535 共 2¹⁶ 个端口,这份配额不会在不同 IP 之间共享,用于区分一台主机上的不同网络应用程序;同一个 IP 上的 TCP 和 UDP 端口空间也互不影响。换句话说:TCP/UDP + 某个具体 IP 这一对组合才决定了一段 65536 个端口号的空间
- 作用 :IP 地址解决了主机到主机的通信问题,而端口则解决了进程到进程的通信问题。操作系统通过端口号来决定将收到的数据包交给哪个应用程序处理。
- 端口分类 :
- 熟知端口 (Well-Known Ports):0 - 1023。这些端口被永久地分配给了特定的系统服务,例如 HTTP (80), HTTPS (443), FTP (21), SSH (22)。
- 注册端口 (Registered Ports):1024 - 49151。分配给用户进程或应用程序。
- 动态/私有端口 (Dynamic/Private Ports):49152 - 65535。客户端发起连接时,通常会由操作系统在本地的这个范围内随机选择一个端口作为源端口。
- 网络五元组 :在网络世界中,一个唯一的 TCP 连接是由一个五元组 来标识的:{协议, 源 IP 地址, 源端口, 目的 IP 地址, 目的端口}
只要这五个元素中有一个不同,操作系统就会视其为一条完全不同的连接。
客户端的临时端口 (Ephemeral Port) **
这里有一个至关重要的细节:当一个客户端程序 发起网络连接时,它只指定了服务器的 IP 和端口(目的地址)。那么客户端用哪个端口来接收数据呢(源地址)?答案是:操作系统会自动从一个 临时端口范围**(通常是 49152-65535)中为该连接随机分配一个未被占用的端口 作为本次连接的源端口。正是这个由客户端操作系统分配的随机源端口 ,保证了五元组的唯一性。即便有成百上千个不同的客户端同时连接到同一个服务器的同一个端口(例如
192.168.1.10:8080),内核依然能通过独一-无二的五元组(因为每个客户端的源IP:源端口组合都不同)来准确地区分每一条连接,并将数据包正确地派发给对应的进程。
4.2 UDP (用户数据报协议)
UDP (User Datagram Protocol) 是一个非常简单的传输层协议。
- 特点 :
- 无连接 (Connectionless):发送数据前不需要建立连接(不需要"握手")。就像寄平信,写上地址就直接扔进邮筒。
- 不可靠 (Unreliable):它不保证数据一定能送达,也不保证数据包的顺序,更不会处理重复的数据包。
- 速度快:因为它没有 TCP 那些复杂的确认、重传、流量控制等机制,所以开销小,传输效率高。
- 数据格式 :UDP 的数据单元称为数据报 (Datagram)。其头部非常简单,只包含了源端口、目的端口、长度和校验和。
- 适用场景 :对实时性要求高,但能容忍少量丢包的场景。例如:
- 在线视频会议、直播
- 网络游戏
- DNS 查询
4.3 TCP (传输控制协议)
TCP (Transmission Control Protocol) 是网络编程的绝对核心,它提供了面向连接的、可靠的字节流服务。
-
面向连接 :在数据传输之前,必须通过三次握手 ** 建立连接。数据传输结束后,还需要通过四次挥手** 来断开连接。
-
**可靠传输 **:TCP 使用多种机制来确保数据传输的可靠性:
- **序列号与确认应答 **:TCP 将发送的数据字节流进行编号(序列号),接收方收到数据后会发送一个确认号 (ACK),告诉发送方"我已经收到了 X 号之前的所有数据,下次请从 X 号开始发"。
- 超时重传:发送方发送数据后会启动一个计时器。如果超过一定时间还没收到对方的 ACK,就认为数据包丢失了,会重新发送该数据包。
- 流量控制:通过滑动窗口机制,接收方可以告诉发送方自己还有多少缓冲区空间,防止发送方发得太快导致接收方处理不过来。
- 拥塞控制:当网络发生拥堵时,TCP 会主动减慢发送速率,以缓解网络压力。
-
字节流:在应用程序看来,TCP 连接就是一个双向的、没有边界的字节流管道。应用程序无需关心数据是如何被打包成段(Segment)和包(Packet)的。
系统命令与验证:
你可以使用 netstat -anp 或 ss -anp (更现代的工具) 来查看系统上当前所有的网络连接状态。
bash
$ ss -antp
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 4096 127.0.0.53%lo:53 0.0.0.0:*
LISTEN 0 128 127.0.0.1:631 0.0.0.0:*
ESTAB 0 0 192.168.7.129:49464 198.18.0.27:443 users:(("code",pid=2311,fd=16))
LISTEN 0 128 [::1]:631 [::]:*
-a显示所有 socket,-n以数字形式显示地址和端口,-t显示 TCP 连接,-p显示关联的进程。
LISTEN状态表示服务器正在监听端口,等待客户端连接。
ESTAB(Established) 状态表示一个 TCP 连接已经成功建立。
4.4 本层封装:TCP 段 / UDP 数据报
当应用程序的数据来到传输层时,它会被封装成 TCP 段 (TCP Segment) 或 UDP 数据报 (UDP Datagram)。
- 封装过程 :传输层将应用程序的数据块作为自己的数据 (Data) 部分,并在其前面加上一个传输层头部 (Header) 。
- UDP 头 :长度固定为 8 字节 。包含源端口 (2字节)、目标端口 (2字节)、数据报总长度 (2字节) 和校验和 (2字节)。其数据部分长度范围为
0 - 65527字节 (65535- 8 字节UDP头)。 - TCP 头 :长度是可变的 ,范围为 20 - 60 字节 。基础长度为 20 字节,除了源/目标端口外,还包含了序列号、确认号、窗口大小等大量用于实现可靠传输的字段。其数据部分理论上最大可达
65535 - 20字节IP头 - 20字节TCP头 = 65495字节,但是受其数据链路层限制。
- UDP 头 :长度固定为 8 字节 。包含源端口 (2字节)、目标端口 (2字节)、数据报总长度 (2字节) 和校验和 (2字节)。其数据部分长度范围为
- 数据结构:
TCP 段
TCP Segment Application Data TCP Header
UDP 数据报
UDP Datagram Application Data UDP Header
5. 应用层 - 应用间的"语言"
目标:理解数据在抵达传输层"港口"之前,是如何被应用程序赋予具体"含义"的。
至此,我们已经完整地探讨了数据如何从一个进程的端口,穿越网络,抵达另一个进程的端口。然而,传输层(TCP/UDP)只负责"搬运"字节数据,它对这些字节的具体含义一无所知。
为这些字节数据定义格式、赋予含义,正是应用层的职责。它规定了不同应用程序之间通信所使用的"语言"和"规则"。例如,我们最熟悉的网页浏览,使用的就是应用层的 HTTP 协议。
一个 HTTP 请求的诞生
当我们浏览网页时,浏览器(作为客户端应用)会构建一个遵循 HTTP 协议的请求数据块。这个数据块本质上就是一段特定格式的文本,它告诉服务器我们想要做什么。
下图清晰地展示了这段应用层数据在整个网络数据包中的位置:它就是最核心的"货物 (Data)",被传输层、网络层和数据链路层层层打包保护。
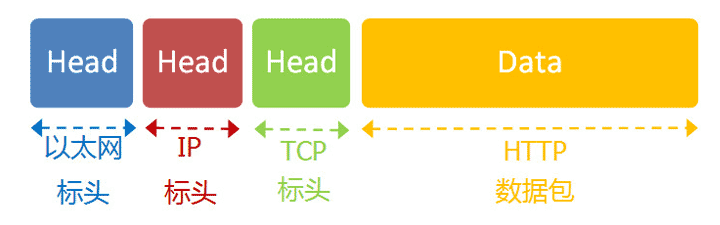
一个典型的 HTTP GET 请求数据包(即上图中的 HTTP 数据包 部分)可能如下所示:
http
GET / HTTP/1.1
Host: www.example.com
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) ...
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding: gzip,deflate,sdch
Accept-Language: zh-CN,zh;q=0.8GET / HTTP/1.1:这是请求的核心,表示"我想要获取该网站的根目录页面 (/),我使用的是 HTTP/1.1 版本的协议"。Host: www.example.com:指明了我想要访问的服务器域名。- 其他
Accept-*,User-Agent等头部,则是向服务器提供了关于客户端能力的额外信息(例如我能接收什么样的数据格式、我用的是什么浏览器等)。
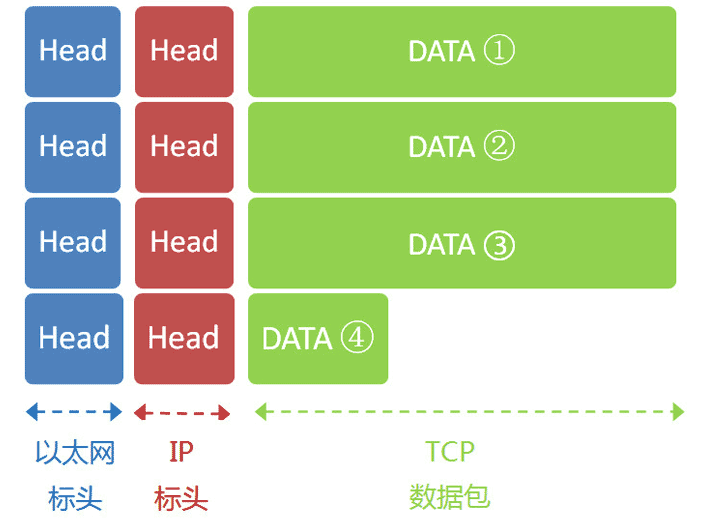
在应用层,浏览器将这样一段文本数据准备好。我们假定这个部分的长度为4960字节,它会被嵌在TCP数据包之中。TCP数据包的标头长度为20字节,加上嵌入HTTP的数据包,总长度变为4980字节。然后,TCP数据包再嵌入IP数据包。IP数据包需要设置双方的IP地址,IP数据包的标头长度为20字节,加上嵌入的TCP数据包,总长度变为5000字节。
最后,IP数据包嵌入以太网数据包。以太网数据包需要设置双方的MAC地址,发送方为本机的网卡MAC地址,接收方为网关192.168.1.1的MAC地址(通过ARP协议得到)。以太网数据包的数据部分,最大长度为1500字节,而现在的IP数据包长度为5000字节。因此,IP数据包必须分割成四个包。因为每个包都有自己的IP标头(20字节),所以四个包的IP数据包的长度分别为1500、1500、1500、560。
应用层是网络通信的"初心"和"目标",它决定了通信解读内容 。而我们接下来要学习的 Socket 编程,则专注于如何构建一个稳定、高效的通道(即打通传输层、网络层和数据链路层),来可靠地传输这些应用层的内容。我们的程序将扮演"快递员"的角色,负责把应用层准备好的"包裹"安全送达,但通常无需打开包裹检查里面的具体内容。
第二部分:Linux 网络编程实战篇
总目标:将第一部分学到的理论知识应用到实际的 C 语言编程中。通过编写、编译和运行网络程序,亲手实现并验证底层的通信过程。
1. Socket 编程入门
1.1 Socket 的本质
在 Linux 的世界里,我们信奉"一切皆文件 (Everything is a file)"的哲学。网络连接也不例外。
Socket (套接字) 本质上就是一种特殊的文件描述符。它为应用程序提供了一个统一的接口,使其能够像读写普通文件一样来收发网络数据,从而屏蔽了底层网络协议的复杂性。
当我们创建一个 Socket 时,操作系统会返回一个整数,这个整数就是文件描述符。后续所有与网络相关的操作(如建立连接、收发数据、关闭连接)都是通过操作这个文件描述符来完成的。
1.2 字节序 (Byte Order)
在编写网络程序时,我们遇到的第一个障碍就是字节序问题。
-
什么是字节序 :字节序指的是当一个大于 1 字节的数据类型(如
int,short)在内存中存储时,其字节的排列顺序。- 大端字节序 (Big-Endian):高位字节存储在内存的低地址处,低位字节存储在高地址处。这符合人类的阅读习惯。
- 小端字节序 (Little-Endian):低位字节存储在内存的低地址处,高位字节存储在高地址处。这是大多数现代 PC(如 Intel x86 架构)使用的模式。
-
问题所在 :不同的计算机体系结构可能使用不同的字节序。如果一台小端机器直接将数据
0x12345678发送给一台大端机器,大端机器会将其解析为0x78563412,导致数据错误。 -
解决方案:网络字节序 :为了解决这个问题,TCP/IP 协议规定,所有在网络中传输的数据都必须统一使用大端字节序 ,这被称为网络字节序 (Network Byte Order) 。而各主机内部使用的字节序则被称为主机字节序 (Host Byte Order)。
核心 API 讲解:Linux 提供了一组函数来帮助我们在主机字节序和网络字节序之间进行转换。
c
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong); // 主机 -> 网络 (32位)
uint16_t htons(uint16_t hostshort); // 主机 -> 网络 (16位)
uint32_t ntohl(uint32_t netlong); // 网络 -> 主机 (32位)
uint16_t ntohs(uint16_t netshort); // 网络 -> 主机 (16位)h代表 host,n代表 network,to就是 to,s代表 short (16位),l代表 long (32位)。- 函数名非常直观,例如
htons就是 "Host to Network Short"。 - 关键实践 :在向网络协议栈(如填充
sockaddr_in结构体)传递端口号和 IP 地址时,必须 使用htons()和htonl()将其转换成网络字节序。反之,从网络中接收数据后,需要用ntohs()和ntohl()转回主机字节序才能正确使用。
1.3 地址表示与转换
在程序中,我们通常用字符串来表示 IP 地址(如 "192.168.1.1"),但在网络协议栈中,IP 地址是以二进制整数(32位或128位)的形式存在的。因此,我们需要一组函数来进行这两种格式之间的转换。
核心 API 讲解:
-
inet_pton()- 字符串转网络二进制c#include <arpa/inet.h> int inet_pton(int af, const char *src, void *dst);- 函数命名 :
pton可以理解为 "p resentation to network" 的缩写,即从"表达形式"(字符串)转换到"网络形式"(二进制)。 - 作用 : 将一个点分十进制(或IPv6)的字符串
src转换为网络字节序的二进制整数,并存放在dst中。 - 参数 :
af: 地址族 (Address Family),AF_INET用于 IPv4,AF_INET6用于 IPv6。src: 指向包含 IP 地址字符串的指针。dst: 指向存放结果的内存地址(例如&my_addr.sin_addr)。
- 函数命名 :
-
返回值 : 成功返回 1,如果
src不是一个有效的地址字符串则返回 0,失败返回 -1。 -
inet_ntop()- 网络二进制转字符串c#include <arpa/inet.h> const char *inet_ntop(int af, const void *src, char *dst, socklen_t size);- 函数命名 :
ntop则是 "n etwork to presentation",即从"网络形式"转回"表达形式"。 - 作用 :
inet_pton的逆操作,将网络字节序的二进制整数src转换为字符串格式,并存放在dst中。 - 参数 :
af: 地址族,同上。src: 指向网络字节序地址的指针。dst: 用于存放结果字符串的缓冲区。size:dst缓冲区的长度。为安全起见,应使用预定义的宏INET_ADDRSTRLEN(IPv4) 或INET6_ADDRSTRLEN(IPv6) 来确保大小足够。
- 返回值 : 成功返回指向
dst的指针,失败返回NULL。
- 函数命名 :
这些现代函数 (
p和n系列) 能够同时处理 IPv4 和 IPv6,并且是线程安全的,推荐使用它们来替代旧的inet_addr()和inet_ntoa()函数。
1.4 核心地址结构:sockaddr, sockaddr_in, sockaddr_un
为了能让 Socket 知道应该与谁通信,我们需要一种方式来指定目标地址。系统为此提供了一系列标准化的结构体,它们是 Socket 编程的"名片"。
-
struct sockaddr- 通用地址结构这是所有 Socket API(如
bind,connect)在参数中使用的"通用"或"抽象"的地址结构。cstruct sockaddr { sa_family_t sa_family; // 地址族 (e.g., AF_INET) char sa_data[14]; // 具体的地址和端口信息 };它的设计是为了兼容多种不同的通信协议。但正因为它太通用,
sa_data字段难以被开发者直接操作。因此,在实际编程中,我们从不直接填充这个结构体,而是使用下面这些为特定协议族量身定制的"专用"结构体。 -
struct sockaddr_in- IPv4 网络地址结构这是进行 TCP/IP (IPv4) 网络编程时最常用的结构体,专门用于封装 IPv4 地址和端口号。
c
#include <netinet/in.h>
struct sockaddr_in {
sa_family_t sin_family; // 地址族, 必须设为 AF_INET
in_port_t sin_port; // 端口号 (必须是网络字节序)
struct in_addr sin_addr; // IPv4 地址结构体};
struct in_addr {
uint32_t s_addr; // 32位的 IPv4 地址 (必须是网络字节序)
};
```
它的每个字段都清晰明确,我们可以方便地为其赋值(sin前缀代表 socket internet)。**关键在于**:填充好 `sockaddr_in` 结构体后,在调用 `bind` 或 `connect` 等函数时,需要将它的指针强制类型转换为 `(struct sockaddr *)`。sin_addr.s_addr 的典型赋值方式
s_addr 字段需要以网络字节序的形式,指定服务器要监听的 IP 地址。通常有以下几种场景:
-
监听所有网络接口 (
INADDR_ANY) : 这是最常见的服务器配置。通过将s_addr设置为htonl(INADDR_ANY),服务器会绑定到本机所有可用的 IP 地址上。这意味着,无论客户端是通过哪个网卡(例如,有线网卡192.168.1.100或无线网卡10.0.0.5)访问服务器,只要目标端口正确,服务器都能接受连接。c// 示例 struct sockaddr_in server_addr; server_addr.sin_addr.s_addr = htonl(INADDR_ANY); // 推荐写法INADDR_ANY本身是一个值为 0 的常量,在所有字节序下都是一样的。但为了代码的清晰性和一致性(因为该字段要求网络字节序),使用htonl()来包裹它是一种广泛遵循的最佳实践。 -
监听特定 IP 地址 : 如果服务器只想接受来自特定网络接口的连接(例如,只对内网服务),可以指定一个具体的 IP 地址。这需要使用
inet_pton()将点分十进制的 IP 字符串转换为所需的网络字节序二进制格式。c// 示例: 只接受发往 192.168.1.100 的连接 struct sockaddr_in server_addr; inet_pton(AF_INET, "192.168.1.100", &server_addr.sin_addr.s_addr); -
监听本地回环地址 : 如果服务只应在本机内部访问(例如,数据库服务只给本机的应用使用),可以绑定到回环地址
127.0.0.1。c// 示例 struct sockaddr_in server_addr; inet_pton(AF_INET, "127.0.0.1", &server_addr.sin_addr.s_addr); // 或者使用 INADDR_LOOPBACK 常量 (效果相同) // server_addr.sin_addr.s_addr = htonl(INADDR_LOOPBACK);
-
struct sockaddr_un- 本地 IPC 地址结构这个结构体用于本地进程间通信 (IPC),它不涉及网络,而是使用 Linux 文件系统中的一个特殊文件(即 socket 文件)作为通信的"地址"。
c
#include <sys/un.h>
struct sockaddr_un {
sa_family_t sun_family; // 地址族, 必须设为 AF_UNIX 或 AF_LOCAL
char sun_path[108]; // socket 文件的路径
};
```
> **对比与应用场景**:
>
> * 当你需要让两个**不同主机**上的进程通过网络(如以太网、Wi-Fi)通信时,你必须使用 `struct sockaddr_in`(或用于 IPv6 的 `sockaddr_in6`)。
> * 当你只需要让**同一台主机**上的两个进程高效通信,且不希望数据经过复杂的网络协议栈时,`struct sockaddr_un` 是更优的选择,因为它绕过了网络层,直接在内核中交换数据,效率更高。
>
> **本章后续内容将主要围绕 `struct sockaddr_in` 展开,因为它专注于网络编程。**2. 构建 TCP 应用
2.1 TCP 服务器状态转换
在深入 API 之前,了解 TCP 连接的生命周期至关重要,特别是服务器端的各种状态,如 LISTEN, ESTABLISHED, CLOSE_WAIT, TIME_WAIT 等。这些状态反映了连接建立、数据传输和关闭过程中的不同阶段。对这些状态的理解有助于我们在出现问题时进行诊断(例如,通过 netstat 或 ss 命令)。
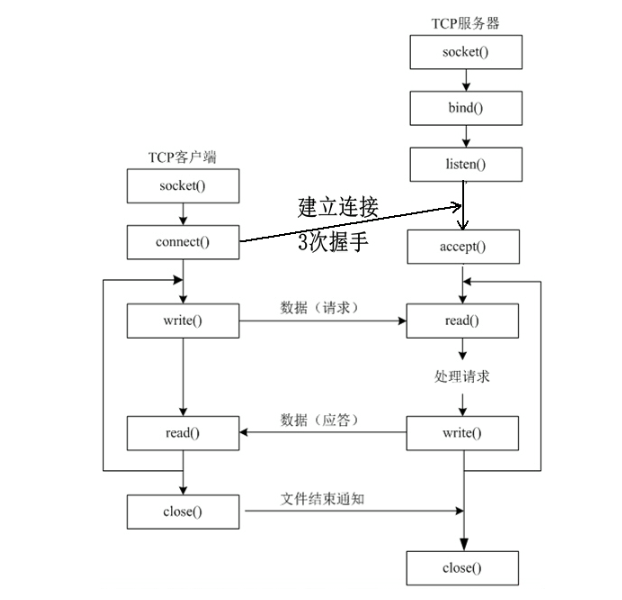
基于 TCP 的网络编程开发分为服务器端和客户端两部分,常见的核心步骤和流程如下:
2.2 核心 API 讲解
构建一个 TCP C/S (Client/Server) 应用主要围绕以下几个核心 API 展开。
通用 API
-
socket()- 创建套接字c#include <sys/socket.h> int socket(int domain, int type, int protocol);- 作用:创建一个通信端点,并返回一个文件描述符。
- 参数 :
domain:协议族。AF_INET用于 IPv4,AF_INET6用于 IPv6。type:Socket 类型。SOCK_STREAM用于 TCP (流式套接字),SOCK_DGRAM用于 UDP (数据报套接字)。protocol:具体协议。通常设为 0,让系统根据type自动选择。
- 返回值:成功则返回新的文件描述符,失败返回 -1。
服务器端专用 API
bind()- 绑定地址和端口
c
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);- 作用 :将
socket()创建的套接字与一个具体的 IP 地址和端口号关联起来。这就像是给电话机分配一个电话号码。 - 参数 :
sockfd:socket()返回的文件描述符。addr:这是bind()函数最核心的参数,它是一个指向通用地址结构sockaddr的指针,包含了要绑定的 IP 地址和端口号。在实际编程中,我们并不会直接操作这个结构体,而是根据使用的协议族(如 IPv4)来创建并填充一个更具体的结构体,通常是struct sockaddr_inaddrlen:addr结构体的长度。
listen()- 开始监听连接
c
int listen(int sockfd, int backlog);- 作用 :将一个主动的、用于连接的套接字(
connect)转换成一个被动的、用于接受连接的套接字。它告诉内核,这个套接字已经准备好接受外来的连接请求。它告诉操作系统内核:"请开始监听绑定在这个套接字上的 IP 地址和端口。如果有客户端发来连接请求(TCP 三次握手),请帮我处理。当握手成功后,请把这个已建立的连接放入一个队列中,等待我后续通过 accept() 函数来取走处理。" - 参数 :
sockfd:已bind的文件描述符。backlog:已完成三次握手、等待被accept()的连接队列的最大长度。
backlog队列满载时,存在两种处理策略。第一种是 Linux 的默认行为 (net.ipv4.tcp_abort_on_overflow = 0)------静默忽略 。服务器会直接丢弃请求,不作任何响应,依赖客户端 TCP 协议栈的超时重传机制来再次尝试连接,寄希望于届时队列已有空位。第二种策略是显式拒绝 (net.ipv4.tcp_abort_on_overflow = 1),服务器会立即发送一个 RST (Reset) 包,导致客户端的connect()调用立刻失败并返回ECONNREFUSED错误。
accept()- 接受连接
c
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);- 作用 :从
listen队列中取出一个已完成的连接。这是一个阻塞函数,如果队列中没有连接,它会一直等待,直到有新的连接到来。 - 参数详解 :
- ==**
addr(输出参数): **==一个指向sockaddr结构体的指针。如果非NULL,内核会将建立连接的客户端的地址信息(IP 和端口)填充到这个结构体中。这使得服务器可以获知"是谁连接了我"。 addrlen(输入输出参数): 这是一个值-结果 参数。- 作为输入: 在调用
accept前,你必须将addrlen指向的变量初始化为你为addr分配的缓冲区的大小(如sizeof(struct sockaddr_in))。 - 作为输出:
accept返回后,内核会修改这个变量,使其等于客户端地址的实际长度。
- 作为输入: 在调用
- ==**
- 返回值与并发核心机制 :
accept的返回值是理解 TCP 服务器如何实现高并发的精髓。要彻底理解它,我们必须抛弃"一个端口同时只能与一个客户端通信"的普遍误解,并引入一个更精确的"银行服务"模型。
银行服务模型:
accept的真正角色
- 端口 (如 8080) :是银行唯一的大门。所有客户都必须从这个门进入。
- 监听套接字 (
server_fd) : 是站在大门口的迎宾/叫号机 。它的唯一职责是接待新客户(处理TCP握手),给他们排队(放入listen队列),然后通过accept叫号,并为他们分配一个专属服务柜台。迎宾自己从不办理具体业务。- 已连接套接字 (
accept的返回值) : 就是那个分配给客户的专属服务柜台。这是一个全新的、完全独立的套接字文件描述符。后续所有的数据读写(办理业务),都在这个专属柜台上进行,而不会再占用大门口的迎宾资源。服务器的监听端口 像一个入口,它不直接参与通信 ,而是作为一个"工厂",通过
accept()不断生产 出新的、用于通信的套-接字。真正与成百上千个客户端进行read/write数据交换的,是accept()返回的那些已连接套接字。内核视角:五元组如何确保连接独立
内核之所以能区分成百上千个连接到同一端口的客户端,是因为它依赖五元组 (Five-Tuple) 来唯一标识一条TCP连接:
{协议, 源IP, 源端口, 目的IP, 目的端口}。假设服务器IP为
10.0.0.1:8080:
- 客户端 A (
192.168.1.100) 连接时,操作系统为其分配临时端口54321。- 客户端 B (
172.16.5.50) 连接时,操作系统为其分配临时端口12345。内核看到的将是两个完全不同的五元组:
- 连接 A :
{TCP, 192.168.1.100, 54321, 10.0.0.1, 8080}- 连接 B :
{TCP, 172.16.5.50, 12345, 10.0.0.1, 8080}因为每个五元组都是全球唯一的,内核会为它们分别创建独立的连接对象 (包含独立的收发缓冲区)。
accept()每成功一次,返回的新套接字就指向其中一个连接对象。因此,对不同已连接套接字的读写操作,是在内核层面完全隔离的,绝对不会互相干扰。客户端与服务器的非对称性
- 服务器端 :
listen()将server_fd变成了一个被动的"工厂"。它失去了直接收发数据的能力,必须通过accept()创建新的已连接套接字来与客户端通信。- 客户端 :它的套接字是主动的。
connect()成功后,这个套接字的状态就直接转变为"已连接",它本身就成了数据通道,无需再创建新的。
客户端专用 API
connect()- 发起连接
c
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);* **作用**:客户端使用此函数向服务器发起连接请求(触发 TCP 三次握手)。
* **参数**:与 `bind()` 类似,`addr` 中包含了服务器的 IP 地址和端口号。
connect()的幕后工作:临时端口的分配当客户端调用
connect()时,内核不仅会发起 TCP 三次握手,还会自动完成一个对程序员透明的关键步骤:为客户端的这个套接字隐式地绑定一个临时的、未被占用的高位端口 (例如54321)作为源端口 。这个过程无需程序员手动bind。因此,connect的请求实际上是:"你好,网络。我要从我的IP:54321出发,连接到服务器IP:8080"。这个由操作系统自动分配的源端口,是构成网络五元组的关键一环,也是服务器能够区分不同客户端连接的基础。
数据传输 API
一旦连接建立(服务器 accept 成功,客户端 connect 成功),双方就可以使用通用的文件 I/O 函数或专用的 Socket I/O 函数来收发数据。
c
// 和普通文件读写一样
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
// Socket 专用,提供了更多控制选项
ssize_t recv(int sockfd, void *buf, size_t len, int flags);
ssize_t send(int sockfd, const void *buf, size_t len, int flags);对于简单的 TCP 流式数据,
read和write通常已经足够。在深入编程实践之前,理解为何必须使用
while循环来读取 TCP Socket 数据是至关重要的,这触及了 TCP 协议的根本特性。其根本原因有二:首先,TCP是无边界的字节流 (Byte Stream)协议,它不保证发送方一次write()调用对应接收方一次read()调用;操作系统可能将多次小数据合并(粘包)或将一次大数据拆分(半包)进行传输。其次,read()函数的行为并非"读满为止",而是"尽力而读"------它只会从内核接收缓冲区中拷贝当前已存在 的数据,其实际读取的字节数可能远小于我们请求的大小。因此,while ((bytes_read = read(...)) > 0)这一经典范式成为了唯一健壮的解决方案。它的逻辑是:只要返回值bytes_read大于 0,就意味着连接正常且读到了数据,我们必须持续循环,将数据从内核缓冲区"搬运"到用户程序中,直到read()返回 0,这个返回值是对方已正常关闭连接(EOF)的唯一明确信号。若不使用循环,程序将极大概率只读到消息的一部分,造成数据丢失和协议解析错误。
2.3 编程练习:TCP 程序
任务要求
编写一个 TCP 回射 (Echo) 应用。服务器启动后监听指定端口,当有客户端连接时,服务器会读取客户端发送的任何数据,然后将同样的数据原封不动地发回给客户端。客户端则从标准输入读取用户输入,发送给服务器,然后接收并打印服务器返回的数据,直到用户输入 EOF (Ctrl+D, 它的作用是关闭标准输入 stdin 流)。
代码:server.c
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#define PORT 8080
#define BUFFER_SIZE 1024
void handle_client(int client_socket) {
char buffer[BUFFER_SIZE];
ssize_t bytes_read;
while ((bytes_read = read(client_socket, buffer, sizeof(buffer) - 1)) > 0) {
buffer[bytes_read] = '\0';
printf("Received from client: %s", buffer);
write(client_socket, buffer, bytes_read);
}
if (bytes_read == 0) {
printf("Client disconnected.\n");
} else {
perror("read");
}
close(client_socket);
}
int main() {
int server_fd, client_socket;
struct sockaddr_in serv_addr, client_addr;
socklen_t client_addr_len;
char client_ip[INET_ADDRSTRLEN];
// 创建 socket 文件描述符
if ((server_fd = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
perror("socket failed");
exit(EXIT_FAILURE);
}
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY); // 接受任何地址的连接(统一为网络序)
serv_addr.sin_port = htons(PORT);
// 将 socket 绑定到指定的 IP 和 port
if (bind(server_fd, (struct sockaddr *)&serv_addr, sizeof(serv_addr)) < 0) {
perror("bind failed");
exit(EXIT_FAILURE);
}
// 监听端口,等待客户端连接
if (listen(server_fd, 3) < 0) {
perror("listen");
exit(EXIT_FAILURE);
}
printf("Server listening on port %d\n", PORT);
// 接受客户端连接
while (1) {
client_addr_len = sizeof(client_addr);
client_socket = accept(server_fd, (struct sockaddr *)&client_addr, &client_addr_len);
if (client_socket < 0) {
perror("accept");
continue; // 继续接受下一个连接
}
// 打印客户端的 IP 地址和端口
inet_ntop(AF_INET, &client_addr.sin_addr, client_ip, INET_ADDRSTRLEN);
printf("----------------------------------------------\n");
printf("New connection accepted from IP=%s, PORT=%d\n", client_ip, ntohs(client_addr.sin_port));
printf("----------------------------------------------\n");
handle_client(client_socket);
}
close(server_fd);
return 0;
}代码:client.c
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#define SERVER_IP "127.0.0.1"
#define PORT 8080
#define BUFFER_SIZE 1024
int main() {
int sock = 0;
struct sockaddr_in serv_addr;
char buffer[BUFFER_SIZE] = {0};
char input_buffer[BUFFER_SIZE] = {0};
if ((sock = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
printf("\n Socket creation error \n");
return -1;
}
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(PORT);
// 将 IPv4 地址从文本转换为二进制形式
if (inet_pton(AF_INET, SERVER_IP, &serv_addr.sin_addr) <= 0) {
printf("\nInvalid address/ Address not supported \n");
return -1;
}
if (connect(sock, (struct sockaddr *)&serv_addr, sizeof(serv_addr)) < 0) {
printf("\nConnection Failed \n");
return -1;
}
printf("Connected to server. You can start typing.\n");
while (fgets(input_buffer, sizeof(input_buffer), stdin) != NULL) {
write(sock, input_buffer, strlen(input_buffer));
ssize_t used = 0;
for (;;) {
ssize_t n = read(sock, buffer + used, sizeof(buffer) - 1 - used);
if (n < 0) {
perror("read");
break; // read error
}
if (n == 0) {
printf("Server closed the connection.\n");
close(sock);
exit(0); // Server closed connection
}
used += n;
buffer[used] = '\0';
if (strchr(buffer, '\n')) {
break; // Received a full line
}
}
if (used > 0) {
printf("Server echo: %s", buffer);
} else {
// This happens if read() returned < 0 in the inner loop
break;
}
}
close(sock);
return 0;
}编译与运行
打开两个终端。在第一个终端编译并运行服务器,在第二个终端编译并运行客户端。
bash
# 终端 1: 服务器
gcc server.c -o server
./server
# > Server listening on port 8080
bash
# 终端 2: 客户端
gcc client.c -o client
./client
# > Connected to server. You can start typing.在客户端终端输入 hello world 并回车,服务器会将其回显。要观察网络状态,可以在第三个终端使用 ss 命令:连接前会看到服务器处于 LISTEN 状态 (ss -ltnp | grep 8080),连接后会看到双方都进入 ESTABLISHED 状态 (ss -tnp | grep 8080),并能识别出客户端的临时端口。
bash
# 在服务器启动后、客户端连接前
$ ss -ltnp | grep 8080
LISTEN 0 3 *:8080 *:* users:(("server",pid=6493,fd=3))
# > 这行输出清晰地表明,PID 为 6493 的 `server` 进程,通过其文件描述符 `3`,正在 `LISTEN` (监听) 所有 IP (`*`) 的 `8080` 端口。
# 状态验证示例 (连接后)
$ ss -tnp | grep 8080
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
ESTAB 0 0 127.0.0.1:8080 127.0.0.1:36746 users:(("server",pid=6493,fd=4))
ESTAB 0 0 127.0.0.1:36746 127.0.0.1:8080 users:(("client",pid=6505,fd=3))在客户端终端按 Ctrl+D 结束输入,连接即关闭。
通过这个练习,我们完整地实践了 TCP C/S 模型的编程流程。服务器端的核心流程是 socket -> bind -> listen -> accept -> read/write -> close。客户端的核心流程是 socket -> connect -> write/read -> close。accept 返回的新套接字是实现并发服务的关键(尽管我们的示例是迭代服务器)。
3. 构建 UDP 应用
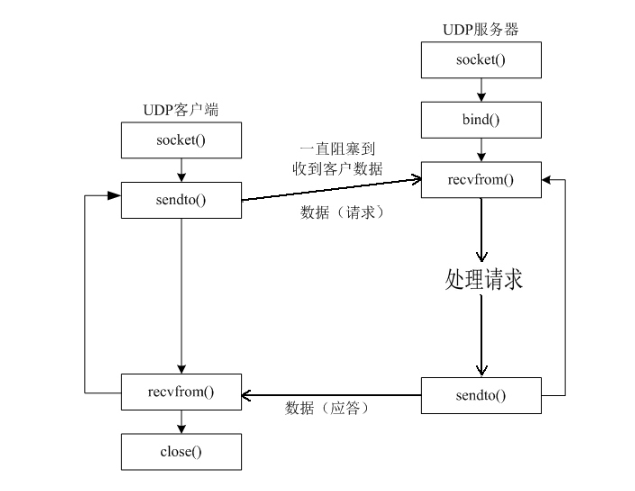
与 TCP 不同,UDP 是无连接的,这意味着我们不需要 listen() 和 accept(),也不需要 connect()(尽管 connect 也可以用于 UDP,但含义不同,此处我们先不讨论)。数据是以独立的数据报 (Datagram) 形式发送的,每个数据报都必须携带完整的目的地址信息。
基于 UDP 的网络编程开发,常见的核心步骤和流程如下:
3.1 核心 API 讲解
UDP 编程的核心是两个专门用于处理数据报的函数。
-
sendto()- 发送数据到指定地址c#include <sys/socket.h> ssize_t sendto(int sockfd, const void *buf, size_t len, int flags, const struct sockaddr *dest_addr, socklen_t addrlen);- 作用 :将数据
buf发送到dest_addr指定的目标地址。 - 关键参数 :
dest_addr和addrlen:在这里,我们必须明确指定每一个数据报要发往的目的地(IP 地址和端口)。
- 作用 :将数据
-
recvfrom()- 从任意地址接收数据cssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen);- 作用 :接收一个数据报。这是一个阻塞函数,会等待直到有数据到来。
- 参数详解 :
src_addr(输出参数): 一个指向sockaddr结构体的指针。当函数成功接收到一个数据报后,内核会把发送方 的地址信息填充到这个结构体中。这对于无连接的服务器来说至关重要,因为它必须知道是谁发来的消息,以便将响应发回给正确的地址。addrlen(输入输出参数): 与accept中的addrlen作用完全相同。作为输入时,需初始化为src_addr指向的缓冲区大小;作为输出时,被内核修改为发送方地址的实际大小。
recvfromvsaccept:无连接与面向连接的本质区别
accept()(TCP) : 只在连接建立的那一刻 ,通过addr参数告诉你一次对方的地址。之后,返回的client_fd就与该客户端永久绑定,后续的read/write都是自动定向的,无需再关心地址。recvfrom()(UDP) : 因为 UDP 没有"连接"的概念,服务器只有一个socket与所有客户端通信。因此,每一次 调用recvfrom()都必须填充地址信息,否则服务器就不知道这条独立的数据报是谁发的。地址信息是伴随每一条消息的。最佳实践:使用独立的地址结构体
一个常见的错误是,在 UDP 服务器中只使用一个
sockaddr_in结构体,既用于bind本地地址,又用于recvfrom接收客户端地址。这样做虽然有时能运行,但存在严重隐患:
- 覆盖数据 :
recvfrom会用客户端地址覆盖掉你原本的本地绑定地址,导致服务器丢失自己的地址信息。- 逻辑混乱: 代码语义不清,将"服务器配置"与"客户端会話"混为一谈。
- 并发问题 : 在并发服务器中,一个
recvfrom覆盖的地址可能被另一个处理流程错误地用于sendto,导致消息发错对象。正确做法:始终使用两个独立的结构体。
c// 用于 bind 服务器自己的地址 struct sockaddr_in servaddr; // 专门用于接收客户端地址 struct sockaddr_in cliaddr; socklen_t len = sizeof(cliaddr); // 每次循环都用 cliaddr 来接收 recvfrom(sockfd, buffer, SIZE, 0, (struct sockaddr *)&cliaddr, &len); // 用刚被填充的 cliaddr 来回复 sendto(sockfd, buffer, n, 0, (struct sockaddr *)&cliaddr, len);从函数原型看本质 :
const关键字揭示了一切。sendto的目标地址是const struct sockaddr *dest_addr(输入,只读),而recvfrom的源地址是struct sockaddr *src_addr(输出,可写)。
3.2 编程练习:UDP 程序
任务要求
编写一个 UDP 回射应用。服务器启动后在一个指定端口等待数据报。当收到任何客户端发来的数据报时,服务器会将其中的数据原封不动地通过同一个套接字发回给该客户端。客户端则从标准输入读取用户输入,将其打包成数据报发送给服务器,然后等待并打印服务器的响应。
代码:udp_server.c
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#define PORT 8080
#define BUFFER_SIZE 1024
int main() {
int sockfd;
char buffer[BUFFER_SIZE];
struct sockaddr_in servaddr, cliaddr;
char client_ip[INET_ADDRSTRLEN];
// 创建 UDP socket
if ((sockfd = socket(AF_INET, SOCK_DGRAM, 0)) < 0) {
perror("socket creation failed");
exit(EXIT_FAILURE);
}
memset(&servaddr, 0, sizeof(servaddr));
memset(&cliaddr, 0, sizeof(cliaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = INADDR_ANY;
servaddr.sin_port = htons(PORT);
// 绑定服务器地址
if (bind(sockfd, (const struct sockaddr *)&servaddr, sizeof(servaddr)) < 0) {
perror("bind failed");
exit(EXIT_FAILURE);
}
printf("UDP Server listening on port %d\n", PORT);
socklen_t len;
ssize_t n;
len = sizeof(cliaddr);
while(1) {
// 接收来自客户端的数据报
n = recvfrom(sockfd, (char *)buffer, BUFFER_SIZE, 0,
(struct sockaddr *) &cliaddr, &len);
if (n < 0) {
perror("recvfrom");
continue;
}
buffer[n] = '\0';
// 打印客户端信息
inet_ntop(AF_INET, &cliaddr.sin_addr, client_ip, INET_ADDRSTRLEN);
printf("----------------------------------------------\n");
printf("Received packet from IP=%s, PORT=%d\n", client_ip, ntohs(cliaddr.sin_port));
printf("----------------------------------------------\n");
printf("Client data: %s\n", buffer);
// 将收到的数据原样发回给客户端
sendto(sockfd, (const char *)buffer, n, 0,
(const struct sockaddr *) &cliaddr, len);
printf("Echo message sent.\n");
}
close(sockfd);
return 0;
}代码:udp_client.c
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#define SERVER_IP "127.0.0.1"
#define PORT 8080
#define BUFFER_SIZE 1024
int main() {
int sockfd;
char buffer[BUFFER_SIZE];
struct sockaddr_in servaddr;
if ((sockfd = socket(AF_INET, SOCK_DGRAM, 0)) < 0) {
perror("socket creation failed");
exit(EXIT_FAILURE);
}
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(PORT);
if (inet_pton(AF_INET, SERVER_IP, &servaddr.sin_addr) <= 0) {
perror("inet_pton failed");
exit(EXIT_FAILURE);
}
printf("You can start typing. (Type 'exit' to quit)\n");
while(fgets(buffer, BUFFER_SIZE, stdin) != NULL) {
if (strncmp(buffer, "exit", 4) == 0) {
break;
}
sendto(sockfd, (const char *)buffer, strlen(buffer), 0,
(const struct sockaddr *) &servaddr, sizeof(servaddr));
ssize_t n = recvfrom(sockfd, (char *)buffer, BUFFER_SIZE, 0, NULL, NULL);
if (n < 0) {
perror("recvfrom");
break;
}
buffer[n] = '\0';
printf("Server echo: %s", buffer);
}
close(sockfd);
return 0;
}编译与运行
在终端 1 启动 UDP 服务器:
bash
./udp_server
# 输出: UDP Server listening on port 8080在终端 2 启动 UDP 客户端:
bash
./udp_client
# 输出: You can start typing. (Type 'exit' to quit)UDP 的编程模型与 TCP 有着本质区别。服务器只有一个 socket,它通过这个 socket 与所有客户端进行通信,每次响应时都必须从 recvfrom 获取客户端地址,并将其传入 sendto。这种"无连接"的特性使得 UDP 程序更简单、开销更小,但也把处理数据丢失、乱序等问题的复杂性完全留给了应用程序开发者。
4. 高并发服务器模型:I/O 多路复用
4.1 问题背景:并发的挑战
我们之前编写的 TCP 服务器是"迭代式"的,handle_client 函数会一直阻塞在 read() 调用上,直到当前客户端断开连接,才能 accept 下一个客户端。这种模型一次只能服务一个客户,效率极低。
一种简单的并发思路是"一个连接一个进程/线程"模型:每当 accept 一个新连接时,就创建一个新的进程或线程专门为这个客户端服务。
- 优点:实现简单,逻辑清晰。
- 缺点:资源开销巨大。每来一个连接就要创建一个进程/线程,当连接数成千上万时,内存开销和上下文切换的成本会压垮服务器。这种模型也被称为 C10K (1万个并发连接) 问题的典型反面教材。
为了解决这个问题,我们需要一种更高效的机制,让我们能够用一个线程 来同时管理多个 I/O 通道(文件描述符) ,这就是 I/O 多路复用 (I/O Multiplexing)。与多线程和多进程相比,I/O 多路复用的最大优势是系统开销小,系统不需要建立新的进程或者线程,也不必维护这些线程和进程。
4.2 核心技术演进
I/O 多路复用的本质是:程序不再主动去调用 read() 等阻塞 API,而是将自己关心的所有文件描述符(监听套接字、已连接套接字等)交给内核,然后调用一个统一的阻塞函数,"委托"内核去监听这些文件描述符上是否有事件发生(例如,有新连接到来、有数据可读、可以发送数据等)。当有任何事件发生时,这个阻塞函数就会返回,并告诉我们是哪些文件描述符"准备好了"。
-
select- 经典但陈旧select是最早的 POSIX 标准 I/O 多路复用模型。c#include <sys/select.h> int select(int numfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);numfds: 要监视的文件描述符的范围,一般取监视的描述符数的最大值+1。readfds,writefds,exceptfds: 分别是指向"文件描述符集合"的指针,用于监控读、写和异常事件。timeout: 超时时间。NULL表示永久阻塞,timeval结构体中值为0表示非阻塞轮询。
fd_set及其操作 :fd_set本质上是一个位图(bitmap),每一位代表一个文件描述符。我们从不直接操作它,而是使用一组宏:FD_ZERO(fd_set *set): 清空集合。FD_SET(int fd, fd_set *set): 将fd添加到集合中。FD_CLR(int fd, fd_set *set): 将fd从集合中移除。FD_ISSET(int fd, fd_set *set): 检查fd是否仍在集合中。
核心陷阱:
select的"破坏性"行为
select函数最反直觉的一点是,它会修改 (或说"破坏")你传入的fd_set集合来返回结果。这意味着,select调用返回后,你传入的readfds将只包含已就绪的fd。因此,在下一次循环并再次调用select之前,你必须用原始的、完整的fd列表来重置fd_set。最常见的编程范式是维护一个不变的"主列表"master_fds,并在每次循环时将其复制到一个临时的read_fds中再传入select。
工作方式 :在事件循环中维护一个长期监听集合 master_fds,每轮开始先完整复制到临时集 read_fds,将 read_fds 交给 select() 阻塞等待;返回后 read_fds 仅保留已就绪的条目,程序遍历 0...max_fd 并用 FD_ISSET() 识别就绪 fd 逐一处理,随后再从 master_fds 复制出新的 read_fds 进入下一轮等待。
缺点 :受 FD_SETSIZE(常见为 1024)限制导致可监视 fd 上限过低;每次调用都需将整份 fd_set 在用户态与内核态间拷贝,即便仅少量活跃 fd;返回后还要从 0 到 max_fd 线性扫描并以 FD_ISSET 甄别就绪项,典型 O(n) 开销,在"大量空闲、少量活跃"场景下效率很差。
-
poll-select的改良版poll旨在解决select的fd数量限制问题。select() 和 poll() 系统调用的本质一样,前者在 BSD UNIX 中引入的,后者在 System V 中引入的。poll() 的机制与 select() 类似,与 select() 在本质上没有多大差别,管理多个描述符也是进行轮询,根据描述符的状态进行处理,但是 poll() 没有最大文件描述符数量的限制(但是数量过大后性能也是会下降)。poll() 和 select() 同样存在一个缺点就是,包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大。c#include <poll.h> int poll(struct pollfd *fds, nfds_t nfds, int timeout);
-
struct pollfd:poll不再使用位图,而是使用一个结构体数组。一个 pollfd 结构体数组,其中包括了你想测试的文件描述符和事件, 事件由结构中事件域 events 来确定,调用后实际发生的事件将被填写在结构体的 revents 域。cstruct pollfd { int fd; // 文件描述符 short events; // 【输入】请求监控的事件 short revents; // 【输出】实际发生的事件 };events和revents都是通过POLLIN(可读),POLLOUT(可写) 等标志位来设置的。- 返回值:poll() 返回结构体中 revents 域不为 0 的文件描述符个数;如果在超时前没有任何事件发生,poll()返回 0;
工作方式 :应用维护一张 pollfd 数组,为每个 fd 指定关注的事件后调用 poll() 阻塞等待;返回时内核已把就绪信息写入各元素的 revents 字段,程序遍历这张数组并依据 revents 处理相应 fd,随后按需更新数组进入下一轮等待。
缺点 :虽突破了 select 的 1024 上限,但每次仍需整体拷贝整张 pollfd 数组入内核且返回后需要线性遍历全表判别就绪项,时间复杂度依旧 O(n),在"少量活跃、大量空闲"场景下开销明显。
关于
select和poll更加详细的解析和具体示例,可以参考这篇博客:Linux系统编程------I/O多路复用select、poll、epoll的区别使用_pollrdband-CSDN博客
-
epoll- Linux 下的高性能终极武器
epoll彻底改变了 I/O 多路复用的工作模式,是 Linux 高性能网络编程的基石。它不再是"每次都问一遍所有fd",而是"当fd就绪时,请主动告诉我"。epoll 是在 2.6 内核中提出的,是之前的 select() 和 poll() 的增强版本。相对于 select() 和 poll() 来说,epoll 更加灵活,没有描述符限制。epoll 使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的 copy 只需一次。epoll的内部高效原理:红黑树与就绪队列epoll之所以能远超select和poll,其秘诀在于内核中高效的数据结构。当通过epoll_ctl()添加文件描述符时,内核会将这些fd存放在一棵红黑树 中,这使得对fd的增、删、改操作都能在高效的 O(log n) 时间复杂度内完成。而真正的性能飞跃来自于就绪队列 (Ready List) 。内核会维护一个独立的双向链表 ,专门用来存放那些已经就绪的
fd。当某个被监控的fd发生 I/O 事件时(例如,网卡收到数据,触发硬件中断),内核的中断处理程序会将其加入到这个就绪队列中。这样,当用户程序调用epoll_wait()时,内核根本无需遍历 所有被监控的fd。它只需要检查就绪队列是否为空:如果为空,则让进程休眠;如果不为空,则直接将队列中的fd信息拷贝给用户,并返回。正是这种"事件驱动"的机制,使得
epoll_wait()的时间复杂度为 O(k)(k 为就绪fd的数量),而不是像select那样总是 O(n),从而实现了极致的高性能。
核心 API 讲解 :epoll 将其功能分解为三个 API:
-
epoll_create()与epoll_create1()c#include <sys/epoll.h> int epoll_create(int size); // 旧版 API int epoll_create1(int flags); // 新版 API这两个调用都用于在内核中创建一个
epoll实例并返回代表它的文件描述符(epfd)。epoll_create(size)是早期接口,size仅是对内核预分配的提示,在 Linux 2.6.8 之后已被忽略,因此传入任意大于 0 的值即可;现代更推荐epoll_create1(flags),它去掉了无意义的size并引入更实用的flags,常用EPOLL_CLOEXEC以避免描述符在exec后泄漏;若传入0(即epoll_create1(0)),其行为与旧接口等价。
flag =
EPOLL_CLOEXEC
CLOEXEC代表 "close-on-exec"。如果在创建epoll实例时设置了这个标志 (epoll_create1(EPOLL_CLOEXEC)),那么当你的程序通过exec系列函数(如execl,execv)执行一个新程序时,这个epfd文件描述符会被内核自动关闭 。这是一种非常重要的编程实践,可以有效防止文件描述符泄漏到子进程中,避免潜在的资源浪费和安全问题。
-
epoll_ctl()cint epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);-
作用 :向
epoll实例中添加 (ADD)、修改 (MOD 或 删除 (DEL)fd。这是epoll与select/poll的根本区别:fd集合在内核中被持久化维护,无需每次调用都重新提交。 -
struct epoll_event:cstruct epoll_event { uint32_t events; /* Epoll events */ epoll_data_t data; /* User data variable */ }; typedef union epoll_data { void *ptr; int fd; uint32_t u32; uint64_t u64; } epoll_data_t;events:EPOLLIN,EPOLLOUT等需要监控事件的位掩码。data: 一个union,允许我们将一个fd与自定义数据关联起来(如data.fd = client_fd或data.ptr = &client_object),极大地简化了程序设计。
-
-
epoll_wait()cint epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);- 作用:等待事件发生,这是主循环中唯一需要调用的阻塞函数。
- 核心优势 :
epoll_wait返回时,它只返回那些已经就绪的fd,并将它们的epoll_event结构体拷贝到用户传入的events数组中。返回的数量就是就绪fd的数量。程序只需遍历这个小数组即可,时间复杂度是 O(k)(k 为就绪fd数),而不是select/poll的 O(n)。这是epoll高性能的根源。
- 工作模式 :
- LT (Level Triggered) - 水平触发:默认模式。epoll_wait 检测到描述符事件发生并将此事件通知应用程序,应用程序可以不立即处理该事件。下次调用 epoll_wait 时,会再次响应应用程序并通知此事件。
- ET (Edge Triggered) - 边沿触发:当 epoll_wait 检测到描述符事件发生并将此事件通知应用程序,应用程序必须立即处理该事件。如果不处理,下次调用 epoll_wait 时,不会再次响应应用程序并通知此事件。ET 模式在很大程度上减少了 epoll 事件被重复触发的次数,因此效率要比 LT 模式高。epoll 工作在 ET 模式的时候,必须使用非阻塞套接口,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务进入死锁。
在 select/poll中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而 epoll() 事先通过 epoll_ctl() 来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似 callback 的回调机制(软件中断 ),迅速激活这个文件描述符,当进程调用 epoll_wait() 时便得到通知。epoll 的优点主要是一下几个方面:
- 监视的描述符数量不受限制,它所支持的 FD 上限是最大可以打开文件的数目,这个数字一般远大于 2048,举个例子,在 1GB 内存的机器上大约是 10 万左右,具体数目可以 cat /proc/sys/fs/file-max 察看,一般来说这个数目和系统内存关系很大。select() 的最大缺点就是进程打开的 fd 是有数量限制的。这对于连接数量比较大的服务器来说根本不能满足。虽然也可以选择多进程的解决方案( Apache 就是这样实现的),不过虽然 Linux 上面创建进程的代价比较小,但仍旧是不可忽视的,加上进程间数据同步远比不上线程间同步的高效,所以也不是一种完美的方案
- I/O 的效率不会随着监视 fd 的数量的增长而下降。select(),poll() 实现需要自己不断轮询所有 fd 集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而 epoll 其实也需要调用 epoll_wait() 不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪 fd 放入就绪链表中,并唤醒在 epoll_wait() 中进入睡眠的进程。虽然都要睡眠和交替,但是 select() 和 poll() 在"醒着"的时候要遍历整个 fd 集合,而 epoll 在"醒着"的时候只要判断一下就绪链表是否为空就行了,这节省了大量的 CPU 时间。这就是回调机制带来的性能提升。
- select(),poll() 每次调用都要把 fd 集合从用户态往内核态拷贝一次,而 epoll 只要一次拷贝,这也能节省不少的开销。
核心思想
epoll 模型的核心思想是,服务器不再主动、逐个地去 accept 或 read 连接,而是将所有关心的套接字(包括监听套接字和已连接套接字)都"注册"到一个 epoll 实例中,然后只调用一次 epoll_wait() 等待事件发生。内核会高效地返回那些已经就绪的套接字,服务器主循环只需要处理这些就绪的事件即可。
这就像从"挨个打电话问谁有空"变成了"建一个群,谁有事谁在群里说一声"。
4.3 fcntl 与非阻塞 I/O
在我们深入 epoll 编程实践之前,必须先掌握一个关键的前置技能:非阻塞 I/O 。epoll 的边缘触发 (ET) 模式强制要求与之配合的文件描述符必须是非阻塞 的,否则整个事件循环都可能因为一个 read 或 write 操作而被阻塞,导致 epoll 失去其并发优势。而 fcntl 函数正是我们设置文件描述符为非阻塞模式的主要工具。
核心 API 讲解
c
#include <unistd.h>
#include <fcntl.h>
int fcntl(int fd, int cmd, ... /* arg */ );fcntl (file control) 是一个功能强大的函数,可以用于修改已打开文件描述符的多种属性。在网络编程中,我们主要用它来获取和设置文件描述符的状态标志。
-
获取状态标志:
int flags = fcntl(fd, F_GETFL, 0);cmd参数为F_GETFL时,fcntl返回fd当前的文件状态标志。
-
设置状态标志:
fcntl(fd, F_SETFL, flags | O_NONBLOCK);cmd参数为F_SETFL时,fcntl会将文件状态标志设置为第三个参数arg的值。- 为了在不覆盖原有标志的情况下添加 非阻塞属性,我们通常采用"先读-再改-后写 "的模式:先用
F_GETFL读出旧的flags,然后用位或操作|加上O_NONBLOCK,最后用F_SETFL将新计算出的flags写回去。
为什么 epoll (特别是 ET 模式) 强依赖非阻塞 I/O?
以 read 为例,在 ET 模式下,当数据到达时,内核只会通知你一次 。你必须在一个循环中持续调用 read,直到把内核缓冲区中的数据全部读完。如果 fd 是阻塞的,当数据读完后,下一次 read 调用就会永远阻塞在那里,等待永远不会再来的新通知,从而饿死其他所有 fd 上的事件。
但如果 fd 是非阻塞的,当数据读完后,再次调用 read 会立即返回 -1,并把 errno 设置为 EAGAIN 或 EWOULDBLOCK。这正是我们需要的信号,它告诉我们:"这次的数据已经读完了,你可以去处理其他事情了。" 同样,对于监听套接字,我们也需要用循环 accept 来处理一次性涌入的多个连接,而非阻塞的 accept 在处理完所有连接后会返回 EAGAIN,从而让我们知道何时可以停止循环。
4.4 编程练习:epoll 版 TCP 回射服务器
任务要求
使用 epoll 重构 TCP 回射服务器,使其能高效地同时处理新连接请求和已连接客户端的数据读写。程序需将监听套接使 epoll 的事件通知机制,特别是边缘触发(ET)模式。对于已连接的客户端,服务器应能响应其读事件,并将收到的数据回射。用 epoll 重构我们之前的 TCP 回射服务器,使其能够高效地并发处理多个客户端连接。服务器的主循环将使用 epoll_wait 来等待事件,而不是阻塞在 accept 或 read 上。
以下是 epoll 版 TCP 服务器交互的核心流程图。请注意 :epoll_wait() 函数本身是作用于 epoll 实例的文件描述符 epfd 上的。它阻塞等待,直到注册在 epfd 上的任何其他 fd (如 server_fd 或 client_fd) 产生事件。流程图中的分支代表 epoll_wait() 返回后,我们根据其返回的事件信息所做的不同处理。
TCP服务器 (事件驱动模型) 返回事件: server_fd 可读 返回事件: client_fd 可读 read()返回0
(客户端关闭) bind() socket() listen() epoll_create1() -> epfd epoll_ctl(epfd, ADD, server_fd) epoll_wait(epfd, ...)
阻塞等待 epfd 上的事件 循环 accept(server_fd)
接收所有新连接 epoll_ctl(epfd, ADD, new_socket) 循环 read(client_fd)
读取所有数据 处理请求 write(client_fd)
发送应答 epoll_ctl(epfd, DEL, client_fd)
close(client_fd)
代码:epoll_server.c
c
#define _GNU_SOURCE
#include <sys/socket.h>
#include <netinet/in.h>
#include <string.h>
#include <arpa/inet.h>
#include <stdio.h>
#include <fcntl.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <errno.h>
#include <unistd.h>
#define MONITOR_IP INADDR_ANY
#define PORT 8080
#define MAX_EVENTS 10
#define BUFFER_SIZE 1024
int main(){
int server_fd, epoll_fd;
server_fd = socket(AF_INET, SOCK_STREAM, 0);
if (server_fd == -1) { perror("socket"); exit(EXIT_FAILURE); }
// 允许地址复用
int opt = 1;
setsockopt(server_fd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
struct sockaddr_in server_socket = {0}, client_socket = {0};
struct epoll_event event, event_array[MAX_EVENTS];
server_socket.sin_family = AF_INET;
server_socket.sin_port = htons(PORT);
server_socket.sin_addr.s_addr = htonl(MONITOR_IP);
socklen_t addr_len = sizeof(server_socket);
// 设置 fd 为非阻塞模式
fcntl(server_fd, F_SETFL, fcntl(server_fd, F_GETFL) | O_NONBLOCK);
if(bind(server_fd, (struct sockaddr *)&server_socket, addr_len) < 0) { perror("bind"); goto FAIL_RETURN; }
if(listen(server_fd, SOMAXCONN) < 0) { perror("listen"); goto FAIL_RETURN; }
if((epoll_fd = epoll_create1(EPOLL_CLOEXEC)) < 0) { perror("epoll"); goto FAIL_RETURN; }
event.events = EPOLLIN;
event.data.fd = server_fd;
if(epoll_ctl(epoll_fd, EPOLL_CTL_ADD, server_fd, &event) < 0) { perror("epoll_create1"); goto FAIL_RETURN;}
printf("Server listening on port %d\n", PORT);
while(1){
int n = epoll_wait(epoll_fd, event_array, MAX_EVENTS, -1);
if(n == 0 ){
perror("epoll_wait");
break;
}
char client_ip[INET_ADDRSTRLEN] = "";
for(int i = 0 ; i < n; i++){
if(event_array[i].data.fd == server_fd){
// 有新的客户端连接: 循环 accept 直到没有为止(ET/LT 都推荐这样写)
int new_socket = accept4(server_fd, (struct sockaddr *)&client_socket, &addr_len, O_NONBLOCK | EPOLL_CLOEXEC);
if(new_socket == -1){
if (errno == EAGAIN || errno == EWOULDBLOCK) {
break;
}
perror("accept4");
break;
}
inet_ntop(AF_INET, &client_socket.sin_addr, client_ip, sizeof(client_ip));
printf("----------------------------------------------\n");
printf("New connection accepted: fd %d,client IP:%s, PORT:%d\n", new_socket, client_ip, ntohs(client_socket.sin_port));
printf("----------------------------------------------\n");
event.events = EPOLLIN | EPOLLET;
event.data.fd = new_socket;
if(epoll_ctl(epoll_fd, EPOLL_CTL_ADD, new_socket, &event) < 0){ perror("epoll_ctl"); goto FAIL_RETURN; }
}
else{
int bytes_read = 0, used = 0;
char buffer[BUFFER_SIZE];
int client_fd = event_array[i].data.fd;
getpeername(client_fd, (struct sockaddr *)&client_socket, &addr_len);
inet_ntop(AF_INET, &client_socket.sin_addr, client_ip, sizeof(client_ip));
for(;;){
// read函数处理非阻塞的fd的时候,当没有数据可以读取的话,会返回-1并且设置errno为EAGAIN
bytes_read = read(client_fd, buffer + used, sizeof(buffer) - 1 - used);
if(bytes_read < 0){
if(errno == EAGAIN || errno == EWOULDBLOCK ) break;
perror("read");
goto FAIL_RETURN;
}
else if(bytes_read == 0){
printf("----------------------------------------------\n");
printf("Disconnection: fd %d,client IP:%s, PORT:%d\n", client_fd, client_ip, ntohs(client_socket.sin_port));
printf("----------------------------------------------\n");
epoll_ctl(epoll_fd, EPOLL_CTL_DEL, client_fd, &event_array[i]);
close(client_fd);
break;
}
used += bytes_read;
buffer[used] = '\0';
if(strchr(buffer, '\n')) break;
}
if(used > 0){
printf("Receive from:fd %d,client IP:%s, PORT:%d,info:%s\n", client_fd, client_ip, ntohs(client_socket.sin_port), buffer);
write(client_fd, buffer, bytes_read);
}
}
}
}
close(epoll_fd);
close(server_fd);
return 0;
FAIL_RETURN:
exit(EXIT_FAILURE);
}编译与运行
启动服务器:
bash
./epoll_servers
# 输出: Server listening on port 8080打开多个 新的终端,并使用我们之前编译好的 client 程序去连接服务器。
bash
# 终端 2
./client
# 终端 3
./client
# 终端 4
./client- 在任何一个客户端终端输入消息,服务器都会正确地回射。
- 服务器的终端会打印出来自不同文件描述符 (fd) 的消息,证明它在同一个循环里处理了多个客户端的请求。
- 断开任意一个客户端,服务器会正确地移除对应的 fd,并继续为其他客户端服务。
I/O 多路复用技术,特别是 epoll,是构建高性能网络服务的基石。它通过"事件驱动"的方式,让一个单线程的程序能够高效地管理成千上万的并发连接,彻底解决了传统并发模型的资源瓶颈问题。理解 epoll 的工作原理和基于事件循环的编程范式,是成为一名合格的 Linux 后端开发者的必经之路。
第三部分:网络编程拓展补充篇
总目标: 掌握那些在生产环境中提升网络程序健robustness,性能和专业性的高级技术。本部分将深入探讨 Socket 选项、优雅的连接管理、信号处理以及守护进程化等关键主题。
1. Socket 选项:getsockopt 与 setsockopt
我们之前创建的套接字都使用了系统默认的配置,这在大多数情况下是可行的。然而,在真实的、复杂的网络环境中,我们常常需要对套接字的行为进行精细化的控制,例如:服务器重启后如何能立即重新绑定之前使用的端口?如何检测并剔除"僵尸连接"?如何为低延迟应用关闭数据合并优化?
这些问题都可以通过 getsockopt 和 setsockopt 这两个强大的函数来解决。它们为我们提供了一个通用的接口,用以查询和设置各种网络协议层(如 Socket 层、IP 层、TCP 层)的选项参数。
核心API
c
#include <sys/socket.h>
int getsockopt(int sockfd, int level, int optname, void *optval, socklen_t *optlen);
int setsockopt(int sockfd, int level, int optname, const void *optval, socklen_t optlen);sockfd: 目标套接字文件描述符。level: 选项所在的协议层,常用SOL_SOCKET(通用 Socket 层),IPPROTO_IP(IP 层),IPPROTO_TCP(TCP 层)。optname: 具体的选项名称,例如SO_REUSEADDR,SO_KEEPALIVE。optval: 一个指向通用缓冲区的指针 (void *)。这正是setsockopt设计的精妙之处:它不关心选项值的具体类型,只关心其内存地址和长度。实际应传入的数据类型(如int,struct timeval等)完全由optname决定。optlen:optval缓冲区的大小。
为何示例中的
optval总是int opt = 1?教程中的示例(
SO_REUSEADDR,SO_KEEPALIVE等)恰好都是布尔型开关 选项。对于这类选项,内核期望一个int类型的值来控制其开关状态:非 0 (通常约定为 1) 表示"启用",0 表示"禁用"。但
setsockopt的能力远不止于此。它的void *参数使其能接受任意数据类型。例如,设置接收超时SO_RCVTIMEO时,你需要传递一个struct timeval结构体:
cstruct timeval timeout = { .tv_sec = 5, .tv_usec = 0 }; // 设置5秒超时 setsockopt(sockfd, SOL_SOCKET, SO_RCVTIMEO, &timeout, sizeof(timeout));因此,必须根据具体
optname的手册来确定为其准备正确的数据类型和值,而非想当然地认为所有选项都使用int。
关键 Socket 选项详解
-
SO_REUSEADDR- 地址复用 :这是解决 TCP 服务器重启时 "Address already in use" 错误的关键。当一个监听端口因处于TIME_WAIT状态而无法立即重新bind时,在bind()之前 通过setsockopt启用此选项,即可允许内核立即重用该端口,极大地提高了开发和运维的便利性。cint opt = 1; setsockopt(server_fd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt)); -
SO_KEEPALIVE- TCP 保活机制:用于检测并关闭因客户端断电、网络中断等原因产生的"僵尸连接"。启用后,TCP 协议栈会在连接长时间(默认2小时)空闲后,自动发送探测包来确认对端是否存活。若探测失败,内核会自动关闭这个失效的连接,释放服务器资源。cint opt = 1; setsockopt(sockfd, SOL_SOCKET, SO_KEEPALIVE, &opt, sizeof(opt)); -
TCP_NODELAY- 禁用 Nagle 算法 :TCP 默认的 Nagle 算法会"攒积"小的TCP包以提高网络效率,但这会给实时应用(如SSH、网游)带来延迟。在IPPROTO_TCP层级设置此选项可以禁用该算法,确保write的数据被立即发送,以牺牲少量带宽为代价换取最低延迟。c
int opt = 1;
setsockopt(sockfd, IPPROTO_TCP, TCP_NODELAY, &opt, sizeof(opt));
```
SO_RCVBUF和SO_SNDBUF- 套接字缓冲区大小:这两个选项分别用于获取或设置套接字内核接收与发送缓冲区的大小。在高速数据传输等场景下,默认缓冲区可能成为瓶颈,适当增大它们可以提升吞吐量,但这需要通过实测来权衡内存开销与性能增益。
合理地使用 SO_REUSEADDR、SO_KEEPALIVE 和 TCP_NODELAY 等关键选项,是编写出专业、健壮且高性能的网络服务的必要技能。