在最新发布的 JuiceFS v1.3 Beta1 版本中,我们引入了一种全新的二进制备份机制,旨在更高效地应对亿级文件规模下的备份与迁移场景。相比现有的 JSON 备份方式,该机制在导入导出元数据时不仅大幅提升了处理速度,还显著降低了内存占用。
01 JSON 备份机制回顾
JuiceFS 自 v0.15 版本支持通过 JSON 格式进行元数据的导入与导出。该功能不仅可用于日常容灾备份,还支持在不同元数据引擎间做迁移,适配因业务规模或数据要求变化所带来的引擎切换场景. 如因数据可靠性要求,用户需要从 Redis 迁移到 SQL DB,或者因数据量级增长,从 Redis 等切换到 TiKV 等。
JSON 格式的一大优势在于其良好的可读性, 其在备份过程中保持了完整的目录树结构, 将文件对象的属性、拓展属性、chunks 等都一起展示,一目了然。然而,在导入与导出时,为了保持这种结构和输出顺序,系统需要处理上下文信息,带来了额外的计算与内存开销。尽管此前版本已针对性地做了多项优化,但在处理大量级的备份时,耗时和占用内存仍然比较大。此外,随着系统规模的持续扩大,可读性的重要性逐渐下降,用户更关注的是整体备份的统计信息和数据校验机制。
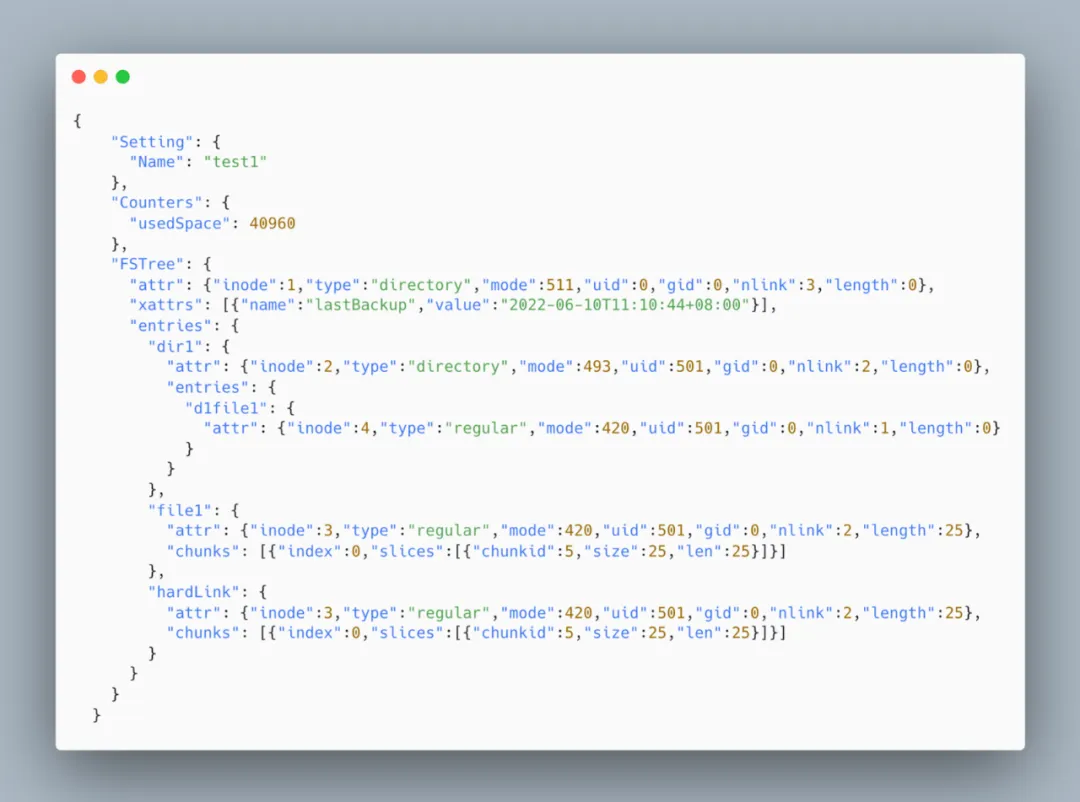
原社区版本提供两种导出 JSON 备份方式:
- 普通导出,占用内存少但性能低;
- Fast 模式,通过快照缓存上下文信息,减少随机查询,性能高但是占用内存太高。
当前社区许多文件系统规模已经过亿,性能与内存就凸显得更加重要。在这类大规模场景下,现有的两种 JSON 备份方式均显现出明显的性能瓶颈和资源限制。
此外,虽然不同元数据引擎提供了原生的备份工具,能够高效的对元数据进行备份,比如 Redis 的 RDB,MySQL 的 mysqldump 工具,TiKV 的 BR 工具等。但是这些工具都需要额外处理JuiceFS 元数据的一致性问题,也不支持跨引擎间迁移。
02 二进制备份实现机制
为了提升导入导出的性能与可扩展性,JuiceFS v1.3 引入了基于 Google Protocol Buffer(Protobuf) 的二进制备份格式。该格式以性能优先为核心设计原则,同时综合兼顾了兼容性、备份体积控制与跨场景的通用性,该格式性能可参考此链接。
与传统的 JSON 格式不同,二进制格式采用了扁平化的存储结构,不再依赖树状目录所需的上下文信息。这样在导出时,既可以避免普通模式中频繁的随机查询,也无需像 Fast 模式那样依赖大量内存缓存,从而同时提
升了性能并降低了资源消耗。
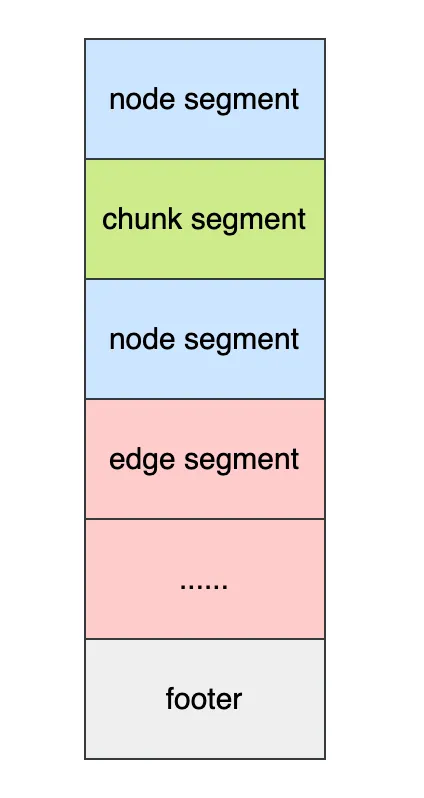
存储结构设计
- 整体结构类似于 SQL DB 中的存储结构,每种元数据(ex. node, edge, chunk...)独立存储,与其他元数据没有关联, 保证导入导出过程可以独立处理;
- 主体由多个段(segment)构成,同一类型的元数据可以拆分成多个段,不同类型的元数据段可交叉,便于在导入导出时做并发分批处理。
- 文件尾部有一个 footer 段,包含版本号,以及其他元数据段的索引信息,包括位移、数量信息。这使得备份文件支持随机访问,便于按类型或特定数据段进行处理、分析或校验。
1.3 版本 load 工具新增了对二进制备份的解析功能,支持用户快速查看备份信息。由于备份格式采用的是 Protocol Buffer (PB) 格式,用户也可以方便的实现一些备份处理分析工具。
以下是 load 工具的一些示例,展示新版二进制的备份内容:
bash
# 查看备份元数据类型统计信息
$ juicefs load redis.bak --binary --stat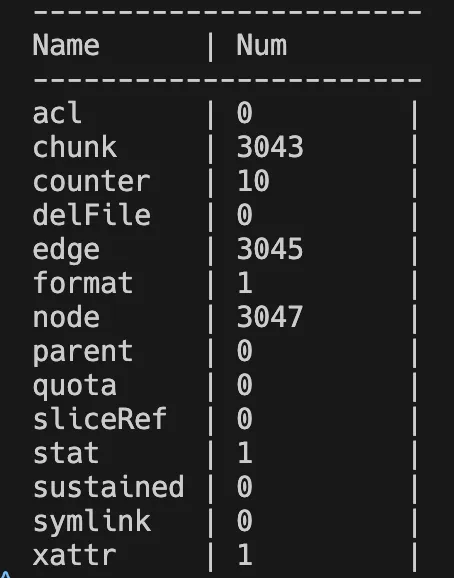
bash
# 查看备份元数据段信息(获取offset)
$ juicefs load redis.bak --binary --stat --offset=-1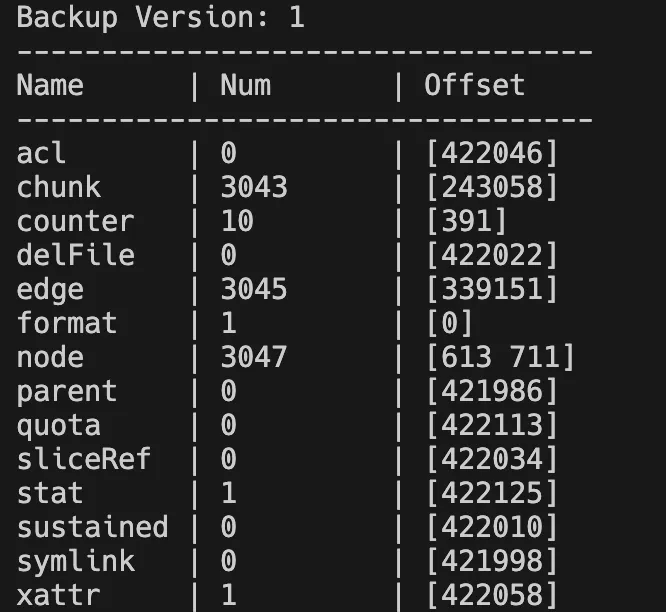
bash
# 查看备份指定段(指定offset)信息
$ juicefs load redis.bak --binary --stat --offset=0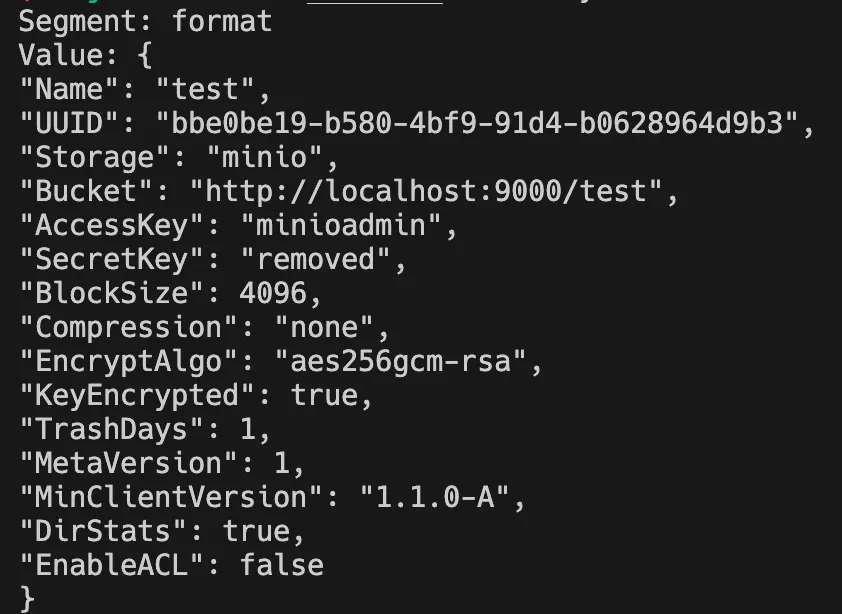
导入导出流程解析
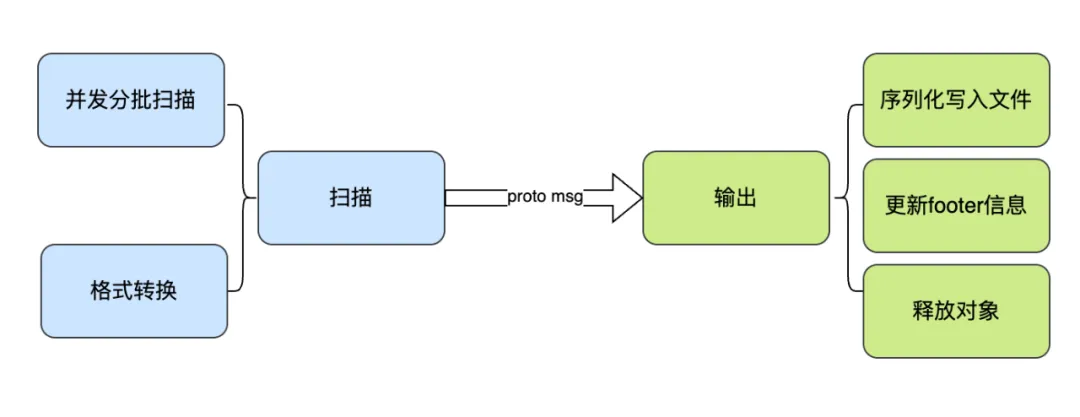
导出过程分为两个阶段:扫描和输出。其中,输出阶段主要负责备份文件相关的处理操作;扫描阶段根据不同元数据引擎, 实现方式略有差异。
例如,对于 SQL DB,不同类型的元数据存储于不同表,因此导出时只需分别扫描这些表,并按格式转换保存。对于超大体量的表(ex. node, edge, chunk),系统会采用分批并发查询的方式提升处理效率。
而 Redis 和 TiKV 是 kv 格式,并且部分类型的 key 以 inode 作为前缀,这样的设计是为了访问同一个 inode 的元数据时更高效。为避免重复访问底层引擎,在导出过程中会对这些类型的元数据统一一次扫描,然后在内部做区分处理。
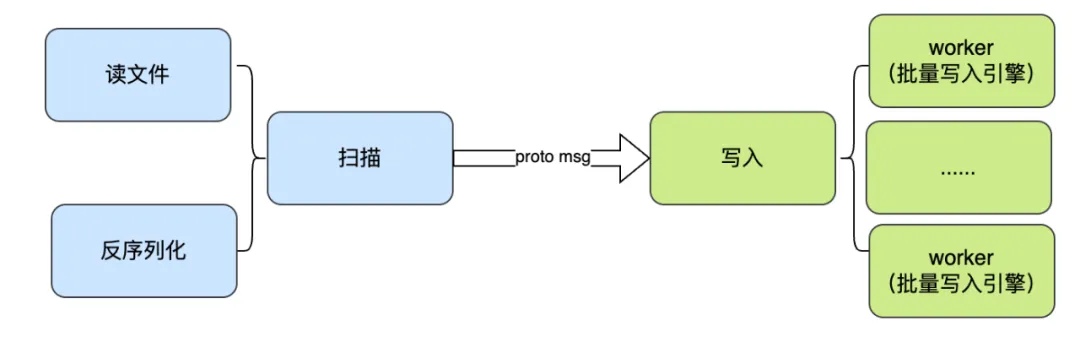
导入过程也分扫描和写入两部分,扫描是对备份文件的读取和格式处理;写入通过多并发批量写入元数据引擎。对于 KV 引擎,比如 TiKV 底层是 LSM 存储结构,为了减少覆盖冲突,会将数据先做排序后再并发写入。
03 性能优化测试
大小
新版本 PB 格式备份在未压缩前只需要原先 JSON 格式的三分之一大小
性能
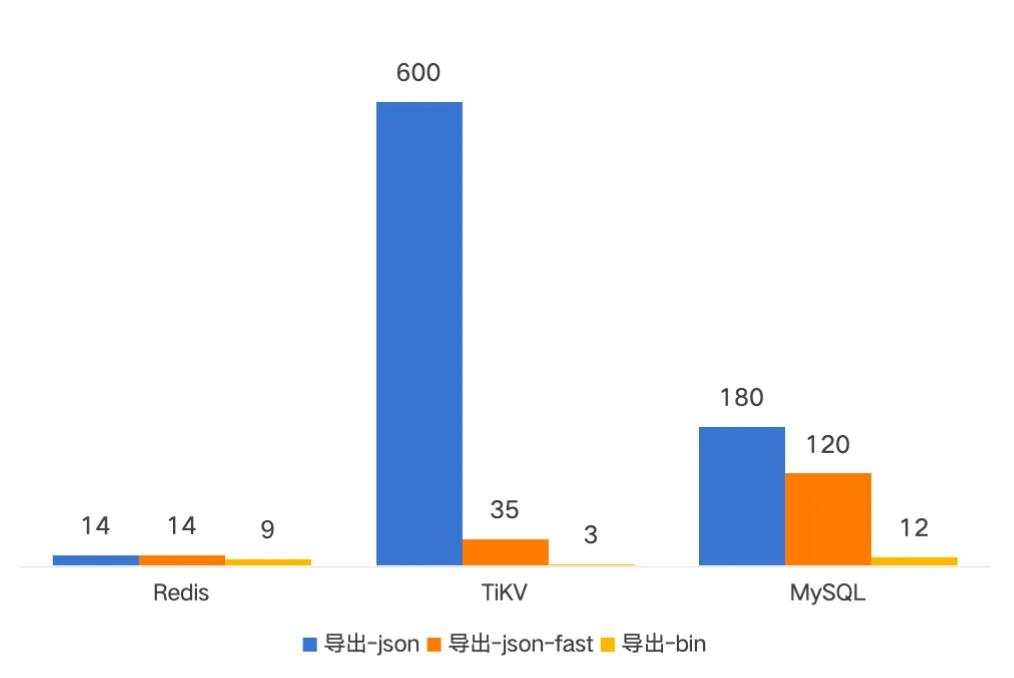
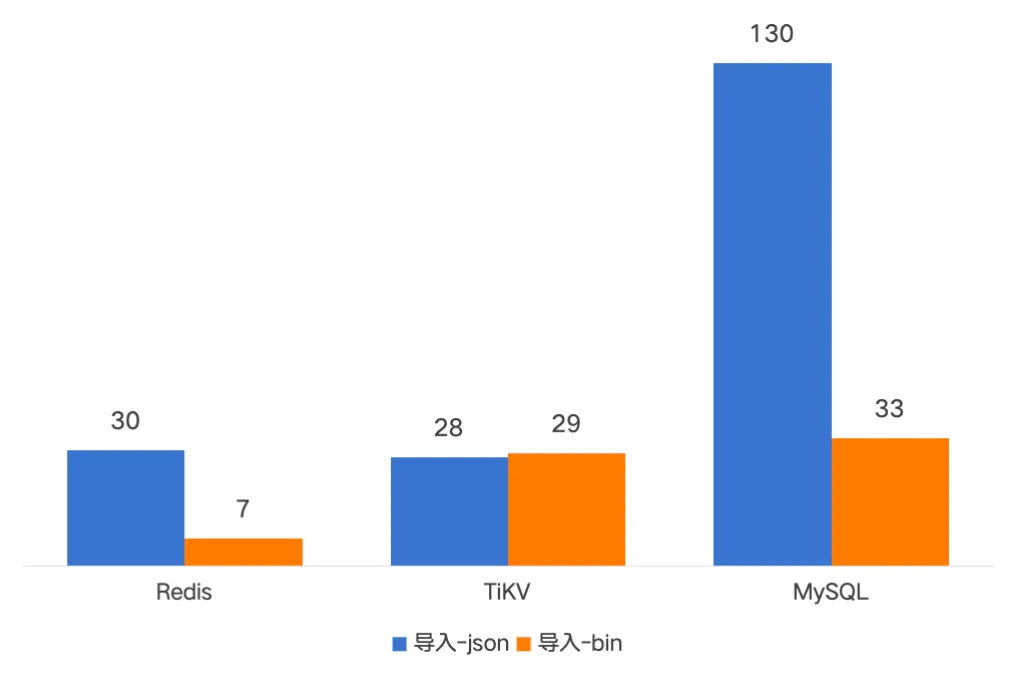
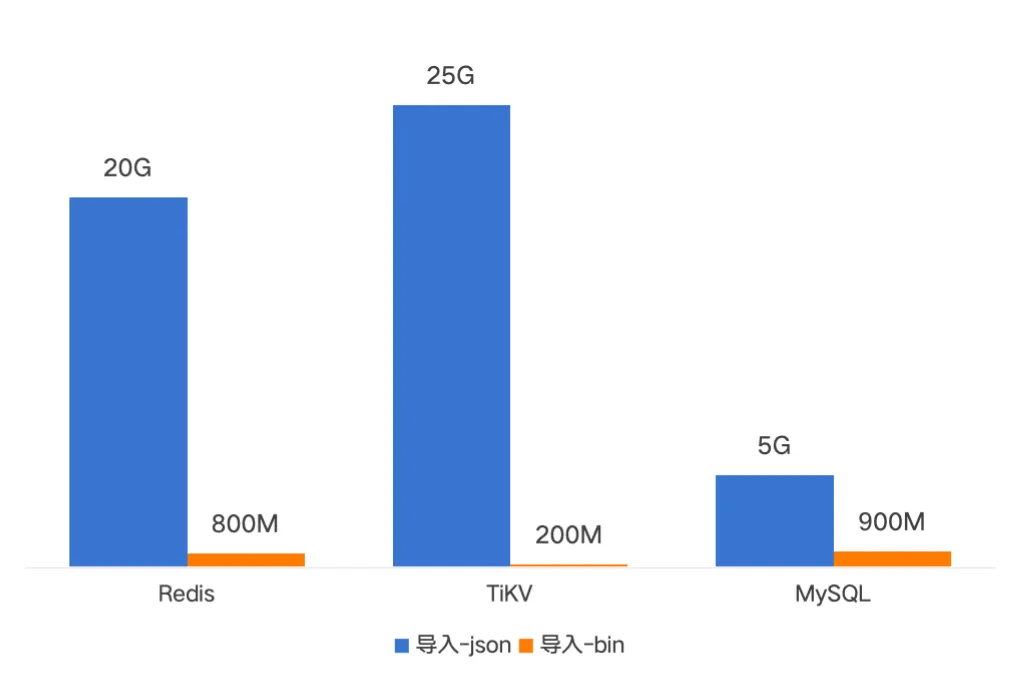
下面是一亿文件的备份导入导出的耗时对比,新版备份耗时基本在分钟级别。导入时间是原先的二分之一到十分之一;导出时间是原先的四分之一左右。
内存
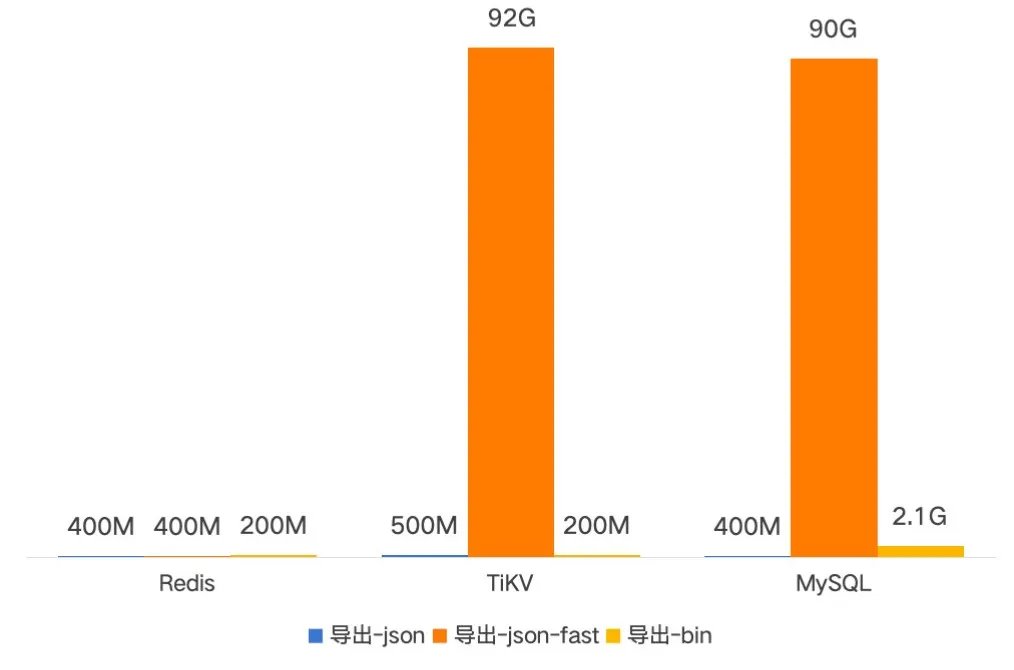
新版本备份内存占用小于1GiB,并且与并发相关,可以通过调整并发大小和批次大小控制。
04 小结
随着社区中越来越多用户面对亿级规模的文件系统的挑战,备份机制的性能、内存占用和跨引擎适配能力变得尤为关键。JuiceFS 在 v1.3 版本中引入的二进制备份格式:通过采用 Protocol Buffer 和扁平化设计,显著提升导入导出效率,降低资源消耗,并提升备份结构的灵活性与可操作性。未来,我们将继续围绕数据保护、容灾迁移、工具链完善等方面进行优化,欢迎社区用户反馈更多实际场景中的需求。
希望这篇内容能够对你有一些帮助,如果有其他疑问欢迎加入 JuiceFS 社区与大家共同交流。