"JDK源码剖析网"目前只上线了一小部分的内容(而且还未更新完成),Javac编译器,HotSpot基础、垃圾收集器以及HotSpot运行时将在今年10月份之前做为付费内容努力更新完毕。到时候,整个JDK就完成了最核心的一块拼图,剩下2块最主要的拼图就是G1垃圾收集器和C2编译器了,G1垃圾收集器和C2编译器将在明年推出更新。
这一篇文章我们梳理一下JDK源码剖析网目前还未涉及到的源码内容,这些内容也将在以后慢慢补充上去。
1、JDK类库
现在大家分析的最多的就是JDK类库的源代码,相关的博客和书籍也非常多,所以这一块是JDK源码剖析网关注最少的。虽然关注少,但后续也会有专门分析JDK类库的模块,只是不会成体系的分析,仅重点分析一些类,如String、Unsafe类等。
2、高版本特性分析
目前的JDK源码剖析网分析的源代码都是JDK8版本的,而最新的JDK版本已经到JDK24了,这中间增加了许多重要的特性,这些重要的特性我们在将来也会一一分析。
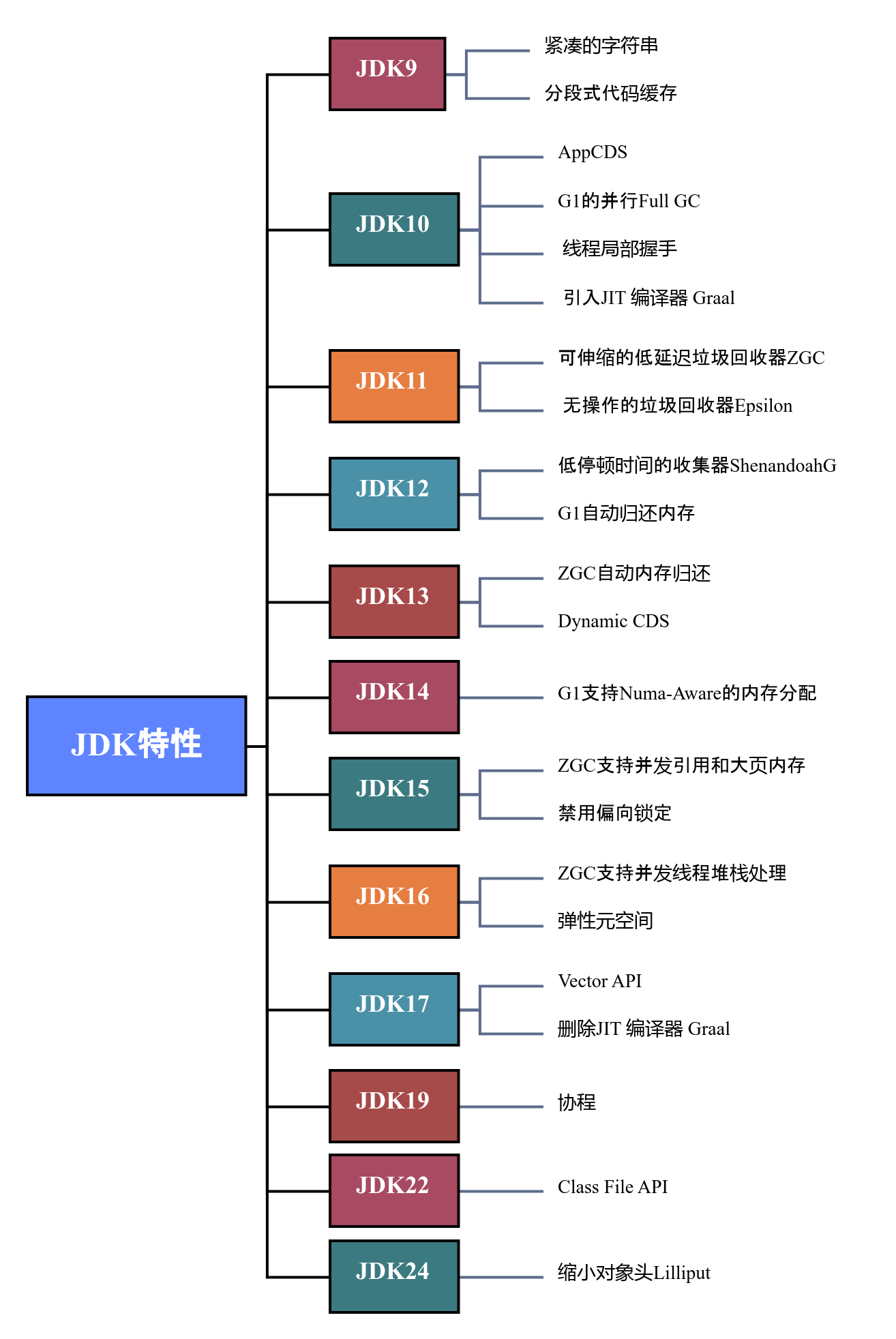
上图表示相关的特性首次出现在JDK中的JDK版本。
当前"JDK源码剖析网"剖析的源代码仅局限在JDK8版本上,不过如果我们研究明白JDK8,那么以此为基础,再研究后序版本出现的特性就会大大降低难度。
例如:
1、以G1为基础,后续增强了G1的并行Full GC、自动归还内存以及对Numa-Aware的支持,这些特性在分析完成后归纳到G1垃圾收集器部分。
2、以JDK8的CDS为基础,后序增加了AppCDS、Dynamic CDS,这一部分将补充到类加载器章节。
3、以线程实现为基础,后序会增加线程局部握手以及协程等。
即使我们后序研究一个全新的ZGC,那么这个ZGC的根如何扫描,如何做到自动内存归还以及大页支持等都可以轻松理解,因为和之前的GC实现比起来,原理是一模一样的,有些甚至代码都是共用的。
3、JEPs
JEP(JDK Enhancement Proposal,JDK增强提案)是Java社区用于提出、讨论和记录JDK改进及新特性的标准化机制。其实JDK高版本特性都是以JEP的形式出现和引入的,还有一些我认为比较重要的JEP需要关注,这些JEP可能在未来的版本中会被引入JDK。
"JDK源码剖析网"将来会重点关注以下几个提案:
3.1 Valhaha
Valhalla项目的主要目标有:
- 使JVM内存布局行为与现代硬件的成本模型相匹配;
- 扩展泛型以支持对所有类型进行抽象,包括基本类型、值,甚至void;
- 使现有的库(特别是JDK)能在保持兼容性的前提下持续演进,以充分利用这些特性。
当前Java只有基本类型和对象引用,没有提供对内存布局的底层控制,所以说其没有像C那样的struct类似的东西,任何复合数据类型都只能通过引用来访问。这就需要间接引用,会提高缓存未命中的概率,不过唯一的好处应该是实现简单。
3.2 Panama
Project Panama 是一项旨在将 JVM(Java虚拟机)与本地代码(如 C/C++)进行互连的项目。这个项目通过 Foreign Function & Memory API 和相关工具,如 Jextract,使得 Java 应用程序能够直接调用和操作本地内存和函数。
Foreign Function & Memory API 是 Project Panama 的核心组件之一,它提供了一组 API 类,用于处理本机内存、指向它的指针、内存布局和描述符、内存会话、链接器和符号查找等。这些 API 使得 Java 应用程序能够像操作Java对象一样直接操作本地内存和函数,从而提高了性能并降低了开销。
Jextract 是 Project Panama 的另一个重要工具,它可以将本地库(如 DLL 或 SO 文件)转换为 Java 可以直接使用的格式。通过 Jextract,Java 应用程序可以轻松地加载和使用本地库中的函数和数据。
Project Panama 的目标之一是减少 JNI(Java Native Interface)的使用,因为 JNI 在处理本地代码时存在一些限制和性能问题。通过 Foreign Function & Memory API 和 Jextract,Project Panama 提供了一个更加高效、灵活和易于使用的解决方案,使得 Java 应用程序能够更好地与本地代码进行互连。
4、C2和Graal编译器
C2编译器是用C++写的,相关的IR比较抽象,再加上混乱的代码以及部分糟糕的架构,代码阅读起来很费力,需要下一番功夫。
Graal编译器使用Java语言重写由C++写的C2编译器。虚拟机与Graal编译器通过JVM编译器接口(JVMCI)来交互。Graal 编译器借鉴了 C2 编译器优秀的思想同时,使用了新的架构。这让 Graal 在性能上很快追平了 C2,并且在某些特殊的场景下还有更优秀的表现。遗憾的是,Graal 编译器在 JDK10 中被引入,但是在 JDK17中被废除了,理由是开发者对其使用较少切维护成本太高。开发者也可以通过使用GraalVM来使用 Graal 编译器。
是否剖析AOT编译器要看Java以后的发展,目前来看用的还是比较少的,用起来比较麻烦,要折腾老半天。
5、垃圾收集器
关于垃圾收集器,"JDK源码剖析网"不会再分析CMS这款垃圾收集器,这款收集器在JDK 9 版本被标记弃用,JDK14版本中移除。
这个垃圾收集器在做垃圾回收时并不进行压缩,所以随着时间的推移,Java堆会碎片化,这最终会导致并发模式失败,然后需要执行一次完整的并行收集(这种并行收集可能会导致一次较长的STW暂停)。应用程序使用了CMS出现了一些突刺就是这个原因,只能添加参数来缓解,并不能更好的避免这个问题。
5.1、G1
G1(Garbage-First Collector)垃圾收集器关注延迟为目标、服务器端应用的垃圾收集器。这个收集器和之前的收集器Serial GC以及Parallel GC相比,内部结构发生了很大的变化,代码也变的复杂了许多,不过目前关于G1的源代码剖析资料也不算少,这其中也不乏有写的很好的书籍和文章。
5.2、Shenandoah
Shenandoah 作为一款第一个不由 Oracle 开发的 HotSpot 收集器,被官方明确拒绝在 OracleJDK12 中支持 Shenandoah 收集器,因此 Shenandoah 收集器只在 OpenJDK 才会包含。Shenandoah 收集器能实现在任何堆内存大小下都把垃圾停顿时间限制在十毫秒以内,这意味着相比 CMS 和 G1,Shenandoah 不仅要进行并发的垃圾标记,还要并发地进行对象清理后的整理
Shenandoah 和 G1 有相似的堆内存布局,在初始标记、并发标记等许多阶段的处理思路都高度一致,甚至直接共享一部分代码。不同的是,虽然 Shenandoah 也是基于 Region 的堆内存布局,回收策略也和 G1 一致,但在管理堆内存方面,它与 G1 至少有三个明显的不同:
- 支持并发的整理算法,G1 的回收阶段可以多线程并行,但不能与用户线程并发.Shenandoah是可以支持在这个阶段与用户线程并发的,通过读屏障和"Brooks"指针来实现
- Shenandoah 默认不使用分代收集
- Shenandoah 摒弃了在 G1 中需耗费大量资源去维护的记忆集,改用连接矩阵的全局数据结构来记录跨 Region 的引用关系
简单介绍一下Brooks指针,这个指针就是在原有对象布局结构的最前面增加一个额外内存字来指标该对象在垃圾收集的上一个阶段是否被移动过,同时给出新移动对象的位置.
Redhat 主导开发的 Pauseless GC 实现,主要目标是 99.9% 的暂停小于 10ms,暂停与堆大小无关等
和ZGC相比,Shenandoah GC 有稳定的 JDK8u 版本,在 Java8 占据主要市场份额的今天有更大的可落地性。
5.3、ZGC
ZGC(Z Garbage Collector)是一款在 JDK11 新加入的具有实验性质的低延迟垃圾收集器。ZGC 与 Shenandoah 的目标高度相似,都希望在对吞吐量影响不大的前提下,实现任意堆内存大小下垃圾收集停顿时间限制在十毫秒以内,但两者的实现思路又有显著差异。ZGC 是一款基于 Region 内存布局的,不设分代的,使用读屏障、染色指针和内存多重映射等技术来实现可并发的标记 - 整理算法的,以低延迟为首要目标的一款垃圾收集器。
可以看到,目前差的源码剖析还比较多,长路漫漫,吾将上下而求索。
更多文章可访问:JDK源码剖析网
