全网第二细致的Verl GRPO实现拆解讲解
标题党致歉,纯引流
观前提示,内含大量注释代码,善用左侧目录跳过可改善阅读体验
本篇文章是在锝人的报告下继续撰写,主要着重于讲解verl实现中一些GRPO的具体细节,如在策略更新、奖励计算、优势计算时,这个mask长什么样,这里是怎么算的,这些都是啥。
TinyZero最详细复现笔记(二):VeRL框架与PPO训练细节 - 锝人的文章 - 知乎
https://zhuanlan.zhihu.com/p/1903855264207200959
1. 整体训练框架
Verl的入口在main_ppo.py中的main_task函数,比较抽象的是,不管啥算法在Verl中全部都用这个函数,然后这个文件还叫main_ppo.py,不清楚为啥。
1.0 main_task大致框架
-
杂七杂八的环境初始化:
- 如各种config,准备模型、分词器什么的
- 初始化资源池,包括硬件如何调用
-
初始化worker:
- 实例化
RayPPOTrainer,传入所有必要的配置、对象(如分词器、worker 映射、资源管理器、奖励函数等)。 - 调用
trainer.init_workers()初始化各种worker group,作为后续调用的根据 - 如Actor worker group,Critic worker group,后续以group为单位调用各个角色模型
- 实例化
-
PPO 训练器 (Trainer) 实例化与执行:
- 调用
trainer.fit()开始 PPO 训练流程。 - 后续所有训练都在fit里进行,出来代表整个流程全部结束
- 调用
1.1 杂七杂八的环境初始化(可跳过此节阅读)
-
环境初始化与配置加载:
- 导入必要的库和模块。
- 打印并解析传入的
config配置对象。 - 设置断点(
breakpoint())用于调试。
-
模型与分词器准备:
- 从 HDFS 下载预训练模型的检查点到本地。
- 根据下载的模型路径实例化分词器 (
tokenizer)。
-
Worker 类定义与选择:
- 根据配置 (
config.actor_rollout_ref.actor.strategy) 判断使用fsdp还是megatron策略。 - 根据策略导入相应的
ActorRolloutRefWorker、CriticWorker以及RayWorkerGroup(或其 Megatron 版本)。
- 根据配置 (
-
角色与资源池配置:
- 定义
Role(如ActorRollout,Critic,RefPolicy)。 - 创建
role_worker_mapping,将角色映射到具体的 Ray远程 actor 类。 - 定义
resource_pool_spec,指定全局资源池的 GPU 配置。 - 创建
mapping,将角色映射到资源池 ID。
- 定义
-
奖励模型 (Reward Model) 配置 (条件性):
- 检查
config.reward_model.enable是否启用奖励模型。 - 如果启用,根据
config.reward_model.strategy选择fsdp或megatron版本的RewardModelWorker。 - 将
RewardModel角色及其 worker 添加到role_worker_mapping和mapping中。
- 检查
-
奖励函数 (Reward Function) 实例化:
- 实例化
RewardManager作为训练用的reward_fn。 - 实例化
RewardManager作为验证用的val_reward_fn(通常会打印更多信息)。
- 实例化
-
资源池管理器实例化:
- 使用之前定义的
resource_pool_spec和mapping实例化ResourcePoolManager。
- 使用之前定义的
下面给出具体代码及注释:
python
def main_task(config):
# 从 verl.utils.fs 模块导入 copy_local_path_from_hdfs 函数,用于从 HDFS 复制文件到本地
from verl.utils.fs import copy_local_path_from_hdfs
# 从 transformers 库导入 AutoTokenizer,用于自动加载预训练模型的分词器
from transformers import AutoTokenizer
# 打印初始配置信息
from pprint import pprint # 导入 pprint 模块,用于更美观地打印 Python 对象
from omegaconf import OmegaConf # 导入 OmegaConf 库,用于处理配置文件
pprint(OmegaConf.to_container(config, resolve=True)) # resolve=True 会解析配置中的符号值(例如,${xxx})
OmegaConf.resolve(config) # 再次确保所有配置值都已解析
breakpoint() # 设置一个断点,方便调试时检查程序状态
# 从 HDFS 下载检查点文件
# config.actor_rollout_ref.model.path 指定了模型在 HDFS 上的路径
local_path = copy_local_path_from_hdfs(config.actor_rollout_ref.model.path)
# 实例化分词器
from verl.utils import hf_tokenizer # 从 verl.utils 模块导入 hf_tokenizer 函数
# 使用下载到本地的模型路径来初始化分词器
tokenizer = hf_tokenizer(local_path)
# 定义 worker 类
# 根据配置中 actor_rollout_ref.actor.strategy 的值来选择不同的 worker 实现
if config.actor_rollout_ref.actor.strategy == 'fsdp':
# 如果策略是 'fsdp' (Fully Sharded Data Parallel)
# 断言 actor 和 critic 的策略必须相同
assert config.actor_rollout_ref.actor.strategy == config.critic.strategy
# 从 verl.workers.fsdp_workers 模块导入 FSDP 版本的 ActorRolloutRefWorker 和 CriticWorker
from verl.workers.fsdp_workers import ActorRolloutRefWorker, CriticWorker
# 从 verl.single_controller.ray 模块导入 RayWorkerGroup,用于管理 Ray worker
from verl.single_controller.ray import RayWorkerGroup
ray_worker_group_cls = RayWorkerGroup # 将 RayWorkerGroup 赋值给 ray_worker_group_cls
elif config.actor_rollout_ref.actor.strategy == 'megatron':
# 如果策略是 'megatron' (一种大规模模型训练框架)
# 断言 actor 和 critic 的策略必须相同
assert config.actor_rollout_ref.actor.strategy == config.critic.strategy
# 从 verl.workers.megatron_workers 模块导入 Megatron 版本的 ActorRolloutRefWorker 和 CriticWorker
from verl.workers.megatron_workers import ActorRolloutRefWorker, CriticWorker
# 从 verl.single_controller.ray.megatron 模块导入 NVMegatronRayWorkerGroup
from verl.single_controller.ray.megatron import NVMegatronRayWorkerGroup
ray_worker_group_cls = NVMegatronRayWorkerGroup # 将 NVMegatronRayWorkerGroup 赋值给 ray_worker_group_cls
else:
# 如果策略不是 'fsdp' 或 'megatron',则抛出 NotImplementedError
raise NotImplementedError
# 从 verl.trainer.ppo.ray_trainer 模块导入 ResourcePoolManager 和 Role
# ResourcePoolManager 用于管理资源池,Role 用于定义不同 worker 的角色
from verl.trainer.ppo.ray_trainer import ResourcePoolManager, Role
# 定义角色到 worker 类的映射
# Role.ActorRollout: 对应 ActorRolloutRefWorker,用于生成经验数据
# Role.Critic: 对应 CriticWorker,用于评估状态价值
# Role.RefPolicy: 对应 ActorRolloutRefWorker,作为参考策略(通常是初始模型或SFT模型)
role_worker_mapping = {
Role.ActorRollout: ray.remote(ActorRolloutRefWorker), # 将 ActorRolloutRefWorker 声明为 Ray远程 actor
Role.Critic: ray.remote(CriticWorker), # 将 CriticWorker 声明为 Ray远程 actor
Role.RefPolicy: ray.remote(ActorRolloutRefWorker) # 将 ActorRolloutRefWorker 声明为 Ray远程 actor
}
global_pool_id = 'global_pool' # 定义全局资源池的 ID
# 定义资源池的规格
# global_pool_id 对应一个列表,列表中的每个元素代表一个节点的 GPU 数量
# config.trainer.n_gpus_per_node 是每个节点的 GPU 数量
# config.trainer.nnodes 是节点的数量
resource_pool_spec = {
global_pool_id: [config.trainer.n_gpus_per_node] * config.trainer.nnodes,
}
# 定义角色到资源池的映射
# 所有角色都使用 'global_pool' 资源池
mapping = {
Role.ActorRollout: global_pool_id,
Role.Critic: global_pool_id,
Role.RefPolicy: global_pool_id,
}
# 这里将采用多源奖励函数:
# - 对于基于规则的奖励模型 (RM),直接调用奖励分数函数
# - 对于基于模型的 RM,调用一个模型进行评估
# - 对于代码相关的提示,如果存在测试用例,则发送到沙箱执行
# - 最后,将所有奖励组合起来
# - 奖励类型取决于数据的标签
# 如果启用了奖励模型 (config.reward_model.enable 为 True)
if config.reward_model.enable:
# 根据奖励模型的策略选择不同的 RewardModelWorker 实现
if config.reward_model.strategy == 'fsdp':
from verl.workers.fsdp_workers import RewardModelWorker
elif config.reward_model.strategy == 'megatron':
from verl.workers.megatron_workers import RewardModelWorker
else:
raise NotImplementedError
# 将 RewardModelWorker 添加到角色 worker 映射中
role_worker_mapping[Role.RewardModel] = ray.remote(RewardModelWorker)
# 将 RewardModel 角色也映射到全局资源池
mapping[Role.RewardModel] = global_pool_id
# 实例化奖励管理器,用于训练过程中的奖励计算
# tokenizer: 之前实例化的分词器
# num_examine: 打印到控制台的已解码响应的批次数,这里设置为 0,表示不打印
reward_fn = RewardManager(tokenizer=tokenizer, num_examine=0)
# 注意:验证过程始终使用基于函数的奖励模型 (RM)
# 实例化用于验证的奖励管理器
# num_examine: 设置为 1,表示在验证时会打印一个批次的解码响应
val_reward_fn = RewardManager(tokenizer=tokenizer, num_examine=1)
# 实例化资源池管理器
# resource_pool_spec: 定义的资源池规格
# mapping: 定义的角色到资源池的映射
resource_pool_manager = ResourcePoolManager(resource_pool_spec=resource_pool_spec, mapping=mapping)
# 实例化 RayPPOTrainer,这是 PPO 算法的训练器
trainer = RayPPOTrainer(config=config, # 传入配置对象
tokenizer=tokenizer, # 传入分词器
role_worker_mapping=role_worker_mapping, # 传入角色到 worker 的映射
resource_pool_manager=resource_pool_manager, # 传入资源池管理器
ray_worker_group_cls=ray_worker_group_cls, # 传入 Ray worker 组的类
reward_fn=reward_fn, # 传入训练奖励函数
val_reward_fn=val_reward_fn) # 传入验证奖励函数
breakpoint() # 设置另一个断点,方便调试
trainer.init_workers() # 初始化所有 worker
trainer.fit() # 开始训练过程1.2 初始化worker
init_workers函数会设置好每个worker接下来所需的一些设置
-
创建资源池
- 这个资源池我也不太熟悉,主要似乎是一些关于计算资源(CPU,GPU)的规格和调用方式
- 通过RayResourcePool对象管理
pyclass RayResourcePool(ResourcePool): def __init__(self, process_on_nodes: List[int] = None, use_gpu: bool = True, name_prefix: str = "", max_colocate_count: int = 5, detached=False) -> None: super().__init__(process_on_nodes, max_colocate_count) self.use_gpu = use_gpu # print(f"in RayProcessDispatchConfiguration: name_prefix = {name_prefix}") self.name_prefix = name_prefix self.pgs = None self.detached = detached -
具体配置每个角色
- 构建角色到资源池的映射(如用Actor对象索引到一个资源池对象)
- 根据配置设定一些属性
- 给Actor分资源池(如果使用引擎混合模式,Actor和Rollout就合并在一个Worker内)
- 如果
self.config.algorithm.adv_estimator使用GAE,就配一个Critic对象 - 如果
self.config.algorithm.adv_estimator使用GRPO,就不使用Critic对象(self.use_critic = False) - 给Ref分资源池
-
初始化WorkGroup
-
将WorkGroup分配给各个角色模型,初始化模型
1.3 PPO 训练器 (Trainer) 实例化与执行
这一步就执行fit,进入正式训练了
fit 函数详细介绍
fit函数的主要流程如下:
-
验证一遍测试集,获取测试集分数
- 这里会对整个训练集跑分,获取模型最初在训练集上的评分
-
开始正式训练循环
-
预设数据:
- 以下这些数据会在后续说明时用到
pythonactor_rollout_ref.rollout.n=5 total_epochs = 15 train_batch_size = 32 ppo_mini_batch_size=16 ppo_micro_batch_size=8 data.max_response_length=1024 -
循环条件:
- 外层循环:遍历总的训练轮数epochs
- 内层循环:每个epochs循环使用
train_dataloaderload数据,这个loader设置好了size是train_batch_size,因此每个batch_dict里包含train_batch_size个对象。
python# 外层循环:遍历总的训练轮数 (epochs) for epoch in range(self.config.trainer.total_epochs): # 内层循环:遍历训练数据加载器中的每个批次 (batch) for batch_dict in self.train_dataloader: -
循环内容:
-
调用
generate_sequences函数,传入一个变量gen_batch,包含
train_batch_size个prompt,生成出的当前循环所需的所有response。generate_sequences: 函数init的时候,会查找config里的变量n作为GRPO rollout的次数。
pykwargs = dict( n=1, logprobs=1, # can be set to 0 and let actor to recompute max_tokens=config.response_length, )这里对于输入的每个prompt,会生成n个response,即总共5 * 32个1024长度的response。
py-> len(prompts) 32 -> response.shape torch.Size([160, 1024])最后计算log_probs,以
old_log_probs的名字加入output中一并返回。这里的old_log_probs指的是当前response生成时,具体选中的每个token的对数概率;它是通过forward_micro_batch函数得到的(如果不了解可看后文2.1详解)。 -
检查是否使用Ref策略
- Ref是一个参考模型,通常使用相同的模型初始化
- GRPO需要使用,于是forward获得
ref_log_prob,用于后续计算KL散度
-
检查是否使用Critic网络
- GRPO不使用Critic,跳过
-
计算优势 (Advantage) 和奖励 (Reward)
-
如果使用奖励模型:
- 使用compute_rm_score计算分数,让入reward tensor
- 合并reward_tensor至batch中
-
如果使用奖励规则算分:
- 使用reward_fn计算分数,放入reward_tensor
- 合并reward_tensor至batch中。
-
检查是否使用KL散度
- GRPO使用
-
使用奖励计算优势
pybatch = compute_advantage( batch, adv_estimator=self.config.algorithm.adv_estimator, gamma=self.config.algorithm.gamma, lam=self.config.algorithm.lam, num_repeat=self.config.actor_rollout_ref.rollout.n )
-
-
更新Critic网络
- 我们没使用critic网络,跳过
-
更新Actor网络(如果Critic预热完毕)
- 使用前面获得的优势来计算目标函数,并计算梯度,更新Actor的参数
-
计算目前策略的分数
-
如果是检查点,保存模型
-
-
下面给出详细注释的完整代码:
python
def fit(self):
"""
PPO 的训练循环。
驱动程序进程只需要通过 RPC 调用工作组的计算函数来构建 PPO 数据流。
轻量级的优势计算在驱动程序进程上完成。
"""
# 从 verl.utils.tracking 模块导入 Tracking 类,用于实验跟踪和日志记录
from verl.utils.tracking import Tracking
# 从 omegaconf 模块导入 OmegaConf,用于处理配置文件
from omegaconf import OmegaConf
# 初始化 Tracking 对象,用于记录实验的指标和配置
# project_name: 项目名称,从配置中获取
# experiment_name: 实验名称,从配置中获取
# default_backend: 日志记录的后端,从配置中获取 (例如,wandb, tensorboard)
# config: 将 OmegaConf 配置对象转换为字典,并解析所有变量
logger = Tracking(project_name=self.config.trainer.project_name,
experiment_name=self.config.trainer.experiment_name,
default_backend=self.config.trainer.logger,
config=OmegaConf.to_container(self.config, resolve=True))
# 初始化全局训练步数
self.global_steps = 0
# 在训练开始前执行验证
# 目前,我们只支持使用 reward_function 进行验证。
# 如果配置了验证奖励函数 (self.val_reward_fn) 并且配置允许在训练前验证
if self.val_reward_fn is not None and self.config.trainer.get('val_before_train', True):
# 调用 _validate 方法执行验证
val_metrics = self._validate()
# 打印初始验证指标
pprint(f'Initial validation metrics: {val_metrics}')
# 使用 logger 记录验证指标
logger.log(data=val_metrics, step=self.global_steps)
# 如果配置了 'val_only' 为 True,则只进行验证,不进行训练,直接返回
if self.config.trainer.get('val_only', False):
return
# 训练从第 1 步开始
self.global_steps += 1
# 外层循环:遍历总的训练轮数 (epochs)
for epoch in range(self.config.trainer.total_epochs):
# 内层循环:遍历训练数据加载器中的每个批次 (batch)
for batch_dict in self.train_dataloader:
# 打印当前的 epoch 和全局步数
print(f'epoch {epoch}, step {self.global_steps}')
# 初始化用于存储当前批次指标的字典
metrics = {}
# 初始化用于存储当前批次各阶段耗时的字典
timing_raw = {}
# 将从 dataloader 获取的字典转换为 DataProto 对象,这是一种自定义的数据结构
batch: DataProto = DataProto.from_single_dict(batch_dict)
# 从批次数据中弹出用于序列生成的键 ('input_ids', 'attention_mask', 'position_ids')
# 这些键对应的数据将用于 actor 模型生成响应序列
gen_batch = batch.pop(batch_keys=['input_ids', 'attention_mask', 'position_ids'])
# 使用 _timer 上下文管理器记录整个训练步骤 (step) 的耗时
with _timer('step', timing_raw):
# 1. 生成序列 (Rollout 阶段)
# 使用 _timer 记录序列生成 (gen) 的耗时
with _timer('gen', timing_raw):
# 调用 actor_rollout_wg (Actor-Rollout Worker Group) 的 generate_sequences 方法生成响应序列
gen_batch_output = self.actor_rollout_wg.generate_sequences(gen_batch)
# 为批次中的每个样本生成一个唯一的 ID (uid)
batch.non_tensor_batch['uid'] = np.array([str(uuid.uuid4()) for _ in range(len(batch.batch))],
dtype=object)
# 根据配置中的 rollout.n (每个 prompt 生成的响应数量) 重复批次数据,以与 rollout 过程中生成的多个响应对齐
# interleave=True 表示交错重复
batch = batch.repeat(repeat_times=self.config.actor_rollout_ref.rollout.n, interleave=True)
# 将生成的序列数据 (gen_batch_output) 合并回原始批次数据 (batch)
batch = batch.union(gen_batch_output)
# 2. 平衡每个数据并行 (DP) rank 上的有效 token 数量
# 注意:这会打乱批次内数据的顺序。
# 如果实现基于组的优势计算(如 GRPO 和 RLOO),需要特别注意。
self._balance_batch(batch, metrics=metrics)
# 计算全局有效 token 数量,并存储在批次的 meta_info 中
batch.meta_info['global_token_num'] = torch.sum(batch.batch['attention_mask'], dim=-1).tolist()
# 3. 如果使用参考策略 (Reference Policy)
if self.use_reference_policy:
# 计算参考策略的 log_prob
with _timer('ref', timing_raw):
# 调用 ref_policy_wg (Reference Policy Worker Group) 计算参考 log_prob
ref_log_prob = self.ref_policy_wg.compute_ref_log_prob(batch)
# 将计算得到的 ref_log_prob 合并到批次数据中
batch = batch.union(ref_log_prob)
# 4. 如果使用 Critic 网络
if self.use_critic:
# 计算价值 (values)
with _timer('values', timing_raw):
# 调用 critic_wg (Critic Worker Group) 计算状态价值
values = self.critic_wg.compute_values(batch)
# 将计算得到的 values 合并到批次数据中
batch = batch.union(values)
# 5. 计算优势 (Advantage) 和奖励 (Reward)
with _timer('adv', timing_raw):
# 计算得分 (scores)。支持基于模型和基于函数的奖励。
# 首先使用奖励模型 (Reward Model, RM) 计算得分,然后调用 reward_fn 结合奖励模型的结果和基于规则的结果。
if self.use_rm: # 如果使用奖励模型
# 首先计算奖励模型的得分
reward_tensor = self.rm_wg.compute_rm_score(batch)
# 将奖励模型的得分合并到批次数据中
batch = batch.union(reward_tensor)
# 结合基于规则的奖励模型 (rule-based RM)
# 调用 self.reward_fn (通常是一个 RewardManager 实例) 计算最终的 token 级别得分
reward_tensor = self.reward_fn(batch)
# 将最终的 token 级别得分存储在批次数据中
batch.batch['token_level_scores'] = reward_tensor
# 计算奖励 (rewards)。如果可用,则应用 KL 惩罚。
# 如果配置中 actor 不使用 KL 损失 (use_kl_loss 为 False)
if not self.config.actor_rollout_ref.actor.use_kl_loss:
# 应用 KL 惩罚,调整 token_level_scores 得到 token_level_rewards
# kl_ctrl: KL 控制器 (AdaptiveKLController 或 FixedKLController)
# kl_penalty: KL 惩罚的类型
batch, kl_metrics = apply_kl_penalty(batch,
kl_ctrl=self.kl_ctrl,
kl_penalty=self.config.algorithm.kl_penalty)
# 更新指标字典
metrics.update(kl_metrics)
else:
# 如果 actor 使用 KL 损失,则 token_level_rewards 直接等于 token_level_scores
batch.batch['token_level_rewards'] = batch.batch['token_level_scores']
# 计算优势 (advantages),在驱动程序进程上执行
# adv_estimator: 优势估计算法 (例如 'gae', 'grpo')
# gamma: 折扣因子
# lam: GAE 的 lambda 参数
# num_repeat: rollout 的重复次数
batch = compute_advantage(batch,
adv_estimator=self.config.algorithm.adv_estimator,
gamma=self.config.algorithm.gamma,
lam=self.config.algorithm.lam,
num_repeat=self.config.actor_rollout_ref.rollout.n)
# 6. 更新 Critic 网络
if self.use_critic:
with _timer('update_critic', timing_raw):
# 调用 critic_wg 更新 Critic 网络
critic_output = self.critic_wg.update_critic(batch)
# 从 Critic 更新的输出中提取指标,并进行归约 (例如,计算均值)
critic_output_metrics = reduce_metrics(critic_output.meta_info['metrics'])
# 更新指标字典
metrics.update(critic_output_metrics)
# 7. 实现 Critic 预热 (warmup)
# 如果当前全局步数大于等于 Critic 预热步数
if self.config.trainer.critic_warmup <= self.global_steps:
# 更新 Actor 网络
with _timer('update_actor', timing_raw):
# 调用 actor_rollout_wg 更新 Actor 网络
actor_output = self.actor_rollout_wg.update_actor(batch)
# 从 Actor 更新的输出中提取指标,并进行归约
actor_output_metrics = reduce_metrics(actor_output.meta_info['metrics'])
# 更新指标字典
metrics.update(actor_output_metrics)
# 8. 执行验证 (Validation)
# 如果配置了验证奖励函数,并且验证频率大于 0,并且当前全局步数是验证频率的倍数
if self.val_reward_fn is not None and self.config.trainer.test_freq > 0 and \
self.global_steps % self.config.trainer.test_freq == 0:
with _timer('testing', timing_raw):
# 调用 _validate 方法执行验证
val_metrics: dict = self._validate()
# 更新指标字典
metrics.update(val_metrics)
# 9. 保存检查点 (Checkpoint)
# 如果保存频率大于 0,并且当前全局步数是保存频率的倍数
if self.config.trainer.save_freq > 0 and \
self.global_steps % self.config.trainer.save_freq == 0:
with _timer('save_checkpoint', timing_raw):
# 调用 _save_checkpoint 方法保存模型检查点
self._save_checkpoint()
# 10. 收集和记录指标
# 计算与数据相关的指标 (例如,奖励、优势、价值的均值/最大值/最小值等)
metrics.update(compute_data_metrics(batch=batch, use_critic=self.use_critic))
# 计算与时间相关的指标 (例如,各阶段耗时,每 token 耗时)
metrics.update(compute_timing_metrics(batch=batch, timing_raw=timing_raw))
# TODO: 创建一个支持多种后端的规范化 logger
# 使用 logger 记录当前步骤的所有指标
logger.log(data=metrics, step=self.global_steps)
# 全局步数加 1
self.global_steps += 1
# 如果当前全局步数达到总训练步数
if self.global_steps >= self.total_training_steps:
# 在训练结束后执行最终验证
if self.val_reward_fn is not None:
val_metrics = self._validate()
pprint(f'Final validation metrics: {val_metrics}')
logger.log(data=val_metrics, step=self.global_steps)
# 结束训练
return2. 具体概念、行为详解
2.1 关于计算log_prob
这里涉及到几个概念,分别是
-
Logits:
- 模型对每个词的原始、未归一化的预测分数。对于一个response,他的logits.shape应是seq_len, vocab_len。每一个logit包含了这个位置对应vocab中每个词的预测分数。
-
熵:
- 先将 logits 转换为概率分布(使用 Softmax),然后根据熵的定义(-sum(p * log(p)))计算得到的,它衡量了模型预测的不确定性。具体在verl中是这么计算的:
pythondef entropy_from_logits(logits: torch.Tensor): """Calculate entropy from logits.""" pd = torch.nn.functional.softmax(logits, dim=-1) entropy = torch.logsumexp(logits, dim=-1) - torch.sum(pd * logits, dim=-1) return entropy这是一个等价的更稳定的实现。
-
对数概率(log_prob):
- 对于response中的这个位置,最后选到的token的对数概率
2.2 关于计算奖励
使用compute_rm_score 或 reward_fn
这里的reward_tensor是一个token level的张量
py
-> reward_tensor.shape
torch.Size([160, 1024])代表了对Response中每一个token的reward
使用奖励模型的计算过程如下(这里GRPO没有使用,仅作学习):
compute_rm_score
-
检查是否用了动态批次,如果用了,按照序列并行大小计算最大token长途
-
切分batch
- 这里输入的batch是最大的train_batch_size(32)
- 如果使用动态批次:
- 按照最大token数切分
- 如果没使用:
- 按照micro_batch_size切分train_batch_size
- 对于每个microbatch:
- forward计算得分
-
如果使用动态批次大小,将打乱的得分恢复到原始顺序
具体注释版本如下
py
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def compute_rm_score(self, data: DataProto):
"""
计算给定数据批次的奖励模型 (Reward Model, RM) 得分。
Args:
data (DataProto): 包含输入数据的数据对象。
期望包含 'input_ids', 'attention_mask', 'position_ids', 'responses'。
如果配置了 _do_switch_chat_template,还需要 'raw_prompt'。
Returns:
DataProto: 包含计算得到的 token 级别奖励模型得分 ('rm_scores') 的数据对象。
"""
import itertools # 用于处理可迭代对象,如此处的 indices
from verl.utils.seqlen_balancing import rearrange_micro_batches, get_reverse_idx # 用于动态批次大小处理
# 将输入数据移动到 CUDA 设备
data = data.to('cuda')
# 如果配置了需要切换聊天模板 (例如,RM 使用的 tokenizer 或模板与 Actor/Rollout 不同)
if self._do_switch_chat_template:
# 调用 _switch_chat_template 方法对输入数据进行预处理,
# 将原始的 prompt 和 response 转换为 RM 期望的格式和 tokenizer。
rm_data = self._switch_chat_template(data)
else:
# 如果不需要切换模板,直接使用原始数据作为 RM 的输入。
# 注意:这里应该确保 rm_data 被正确赋值,即使不切换模板。
# 通常情况下,如果 _do_switch_chat_template 为 False,rm_data 应该就是 data。
# 为了代码的健壮性,显式赋值。
rm_data = data
# breakpoint() # 调试断点,通常在开发和调试时使用。
# 将(可能经过模板切换的)RM 输入数据中的批次数据移动到 CUDA 设备。
# 确保 rm_data.batch 存在,如果 _switch_chat_template 可能不返回 batch,需要处理。
# 假设 _switch_chat_template 返回的 DataProto 对象总是包含 batch 属性。
rm_data.batch = rm_data.batch.cuda()
# 执行前向计算,在 Ulysses Sharding Manager 的上下文中进行,
# 这会处理数据在序列并行维度上的分发和收集。
with self.ulysses_sharding_manager:
# 对 RM 输入数据进行预处理(例如,根据序列并行策略进行切分)
rm_data = self.ulysses_sharding_manager.preprocess_data(data=rm_data)
# 对原始输入数据也进行预处理,因为后续 _expand_to_token_level 需要原始数据的 attention_mask 等信息。
# 这一步确保了原始 data 和 rm_data 都经过了与 sharding manager 一致的处理。
data = self.ulysses_sharding_manager.preprocess_data(data=data)
# 获取是否使用动态批次大小的配置
use_dynamic_bsz = self.config.use_dynamic_bsz
if use_dynamic_bsz:
# 如果使用动态批次大小,根据每个 GPU 的最大 token 长度和序列并行大小计算总的最大 token 长度。
# forward_max_token_len_per_gpu 应该是 RM 的配置项。
max_token_len = self.config.forward_max_token_len_per_gpu * self.ulysses_sequence_parallel_size
# 使用 rearrange_micro_batches 将 rm_data.batch 动态地重新排列成微批次,
# 以便每个微批次的总 token 数大致均衡,并记录原始样本的索引。
micro_batches, indices = rearrange_micro_batches(batch=rm_data.batch, max_token_len=max_token_len)
else:
# 如果不使用动态批次大小,则按固定的 micro_batch_size 将 rm_data.batch 切分成微批次。
micro_batches = rm_data.batch.split(self.config.micro_batch_size)
output_scores = [] # 初始化一个列表来存储每个微批次计算得到的 RM 得分
# 遍历每个微批次
for micro_batch in micro_batches:
# 调用 _forward_micro_batch 方法计算当前微批次的 RM 得分。
# _forward_micro_batch 内部会处理模型的前向传播,并提取每个序列的单个标量得分。
rm_score_micro_batch = self._forward_micro_batch(micro_batch)
output_scores.append(rm_score_micro_batch)
# 将所有微批次的得分在批次维度上拼接起来,得到整个批次的 RM 得分。
scores = torch.cat(output_scores, dim=0) # 形状为 (batch_size)
# 如果使用了动态批次大小,需要将打乱顺序的得分恢复到原始顺序。
if use_dynamic_bsz:
# 将 rearrange_micro_batches 返回的嵌套索引列表展平。
indices = list(itertools.chain.from_iterable(indices))
# 断言检查,确保展平后的索引数量与计算得到的得分数量一致。
assert len(indices) == scores.size(0), f"{len(indices)} vs. {scores.size()}"
# 获取反向索引,用于将得分恢复到原始顺序。
revert_indices = torch.tensor(get_reverse_idx(indices), dtype=torch.long)
# 根据反向索引对得分进行重新排序。
scores = scores[revert_indices]
# 调用 _expand_to_token_level 方法将每个序列的标量 RM 得分扩展为 token 级别的得分。
# 通常是将标量得分赋给响应序列的最后一个有效 token (或 EOS token) 的位置。
# 使用原始的 data 对象,因为它包含了原始的 attention_mask 和 responses 信息。
token_level_scores = self._expand_to_token_level(data, scores)
# 注意:这里的 scores 只是 RM 模型直接输出的得分,可能不是最终用于 RL 训练的奖励。
# 例如,可能还需要进行归一化、与 KL 惩罚结合等后处理。
# 创建一个新的 DataProto 对象来存储计算得到的 token 级别 RM 得分。
output = DataProto.from_dict(tensors={'rm_scores': token_level_scores})
# 对输出数据进行后处理(例如,从序列并行设备收集数据)
output = self.ulysses_sharding_manager.postprocess_data(data=output)
# 将最终的输出数据移动到 CPU
output = output.to('cpu')
# 清空 CUDA 缓存以释放未使用的 GPU 内存
torch.cuda.empty_cache()
return output如果不使用奖励模型,则使用对应的reward_fn 进行打分,二者互斥 ;
这里reward_fn是一个函数指针,根据具体的数据集获取对应的奖励函数。比如我这里使用的是CountDown任务,给出一组数(通常3-4个),给出一个target值,要求模型通过加减乘除这一组数来获得target值。这个任务的奖励函数就是答对了给1分,答错了0分。
reward_fn
这里给出伪代码
py
初始化一个reward_tensor,shape是 [rollout.n * train_batch_size, max_response_length],这里我的实际上是[160, 1024]。这个reward_tensor记录response的每个位置应该有的奖励
for i in range(len(data)):
1. 通过掩码提取出有效的prompt和response的ids
2. 将对应ids解码为文字形式,获得人类语言的prompt + response
3. 从数据集的元数据中查看是哪个数据集,选取对应的 **compute_score_fn**
4. 调用上面选出的函数计算分数
# 计算出的分数只赋给当前轮的对话的最后一个有效token
5. reward_tensor[i, valid_response_length - 1] = score
return reward_tensor这里比较难理解的是第五步,按照我之前的直观理解,获得的分数应该是赋给整个response的每个token的,但实际上只赋给最后一个有效token。
但其实仔细想想也可以明白,计算的 score 通常是对整个生成的 sequences_str (prompt + response) 的一个整体评估。例如,在 GSM8K(数学问题解答)任务中,score 可能是 1(如果答案正确)或 0(如果答案错误)。这个分数是针对整个解决方案的,而不是针对解决方案中的某一个词或数字。
2.3 关于计算优势
优势是奖励的具现化,由奖励计算而来
compute_advantage
compute_advantage()函数是优势计算的入口,这个函数的输入是DataProto: Data,函数内部会提取出元数据,并根据adv_estimator选择专门的优势计算器。这里我们的adv_estimator == 'grpo',因此调用compute_grpo_outcome_advantage函数,传入reward,eos_mask,index
源代码
py
def compute_advantage(data: DataProto, adv_estimator, gamma=1.0, lam=1.0, num_repeat=1):
# prepare response group
# TODO: add other ways to estimate advantages
if adv_estimator == 'gae':
values = data.batch['values']
responses = data.batch['responses']
response_length = responses.size(-1)
attention_mask = data.batch['attention_mask']
response_mask = attention_mask[:, -response_length:]
token_level_rewards = data.batch['token_level_rewards']
advantages, returns = core_algos.compute_gae_advantage_return(token_level_rewards=token_level_rewards,
values=values,
eos_mask=response_mask,
gamma=gamma,
lam=lam)
data.batch['advantages'] = advantages
data.batch['returns'] = returns
elif adv_estimator == 'grpo':
token_level_rewards = data.batch['token_level_rewards']
index = data.non_tensor_batch['uid']
responses = data.batch['responses']
response_length = responses.size(-1)
attention_mask = data.batch['attention_mask']
response_mask = attention_mask[:, -response_length:]
advantages, returns = core_algos.compute_grpo_outcome_advantage(token_level_rewards=token_level_rewards,
eos_mask=response_mask,
index=index)
data.batch['advantages'] = advantages
data.batch['returns'] = returns
else:
raise NotImplementedError
return datacompute_grpo_outcome_advantage
输入参数如下:
py
-> token_level_rewards.shape # token_level_rewards[i][j] 代表第i个response的第j个token的奖励
torch.Size([160, 1024])
-> eos_mask.shape # 无用的padding位置是0,有内容的是1
torch.Size([160, 1024])
-> index.shape # 每个response对应的字符串id
(160,)
-> epsilon
1e-6
-> index
['86fdf296-c41b-4667-a7d8-6fe154b804a2', '86fdf296-c41b-4667-a7d8-6fe154b804a2', '86fdf296-c41b-4667-a7d8-6fe154b804a2', '86fdf296-c41b-4667-a7d8-6fe154b804a2', '86fdf296-c41b-4667-a7d8-6fe154b804a2', 'acfad52a-efca-420f-a436-8a6cc2ac36d1', 'acfad52a-efca-420f-a436-8a6cc2ac36d1', 'acfad52a-efca-420f-a436-8a6cc2ac36d1', 'acfad52a-efca-420f-a436-8a6cc2ac36d1', 'acfad52a-efca-420f-a436-8a6cc2ac36d1', '7a564203-02e2-4086-abe3-71549b0446e5', '7a564203-02e2-4086-abe3-71549b0446e5', '7a564203-02e2-4086-abe3-71549b0446e5', '7a564203-02e2-4086-abe3-71549b0446e5', '7a564203-02e2-4086-abe3-71549b0446e5', '4ce88d65-cd57-4fd0-90b0-c7fd4c18677c', '4ce88d65-cd57-4fd0-90b0-c7fd4c18677c', '4ce88d65-cd57-4fd0-90b0-c7fd4c18677c', '4ce88d65-cd57-4fd0-90b0-c7fd4c18677c', '4ce88d65-cd57-4fd0-90b0-c7fd4c18677c', '0cb174ec-df24-4073-a46a-1b74ddfeb36e', '0cb174ec-df24-4073-a46a-1b74ddfeb36e', '0cb174ec-df24-4073-a46a-1b74ddfeb36e', '0cb174ec-df24-4073-a46a-1b74ddfeb36e', '0cb174ec-df24-4073-a46a-1b74ddfeb36e', ...]
"""
Compute advantage for GRPO, operating only on Outcome reward
(with only one scalar reward for each response).
Args:
token_level_rewards: `(torch.Tensor)`
shape: (bs, response_length)
eos_mask: `(torch.Tensor)`
shape: (bs, response_length)
Returns:
advantages: `(torch.Tensor)`
shape: (bs, response_length)
Returns: `(torch.Tensor)`
shape: (bs, response_length)
"""在GRPO中,对于一条response只会给予最后一个token奖励,但这里的分数计算是把这条response里所有token的奖励相加。这是一个健全的写法。
eos_mask
这里的eos_mask和response mask是一个东西,它来自上面的compute_advantage函数:
response_mask = attention_mask[:, -response_length:]
py
-> attention_mask.shape
torch.Size([160, 1280])
-> response_mask.shape
torch.Size([160, 1024])
-> response_length
1024
attention_mask: [0,0,0,0,1,1,1,1, | 1,1,1,0,0,0,0,0]
[(prompt_pad)(prompt_tokens) | (response_tokens)(response_pad)]attention_mask包括了两部分,propmt的和response的,上面是它的大致结构。其中prompt部分是左padding,response部分是右padding。
因此attention_mask的长度是max_prompt_length + max_response_length = 256 + 1024 = 1280
response_mask = attention_mask[:, -response_length:]
因此这句代码实际上是切出了attention的所有response的部分,即
py
[1,1,1,0,0,0,0,0]
[(response_tokens)(response_pad)]index
这里的index指的是具体每条对话的id,具体样例可以参考上面;
排布是把来源于一个prompt的所有rollout放在一起,我这里rollout.n设置的是5,因此可以看到一个id会重复5次。
这个index这里主要用于后续计算同一个rollout的内容(均值、标准差)
具体优势计算
py
# 对当前样本的得分进行归一化:(score - mean) / (std + epsilon)。
# 使用对应提示索引的均值和标准差。
# > len(id2mean)
# 32
# > len(id2std)
# 32
# > scores.shape
# [160]
for i in range(bsz): # bsz = 160
scores[i] = (scores[i] - id2mean[index[i]]) / (id2std[index[i]] + epsilon)
scores = scores.unsqueeze(-1).tile([1, response_length]) * eos_mask
# scores.shape
# [160, 1024]
# 对于每一个response[i],把scores[i]复制response_length次作为这条response最后的token_level_advantage
# [1.44] ->
# [1.44, 1.44, 1.44, ... , 1.44] (response_length个)下面给出详细注释代码
py
def compute_grpo_outcome_advantage(token_level_rewards: torch.Tensor,
eos_mask: torch.Tensor,
index: torch.Tensor,
epsilon: float = 1e-6):
"""
Compute advantage for GRPO, operating only on Outcome reward
(with only one scalar reward for each response).
Args:
token_level_rewards: `(torch.Tensor)`
shape: (bs, response_length)
# 包含了每个 token 可能的奖励。在 outcome supervision 的情况下,
# 通常只有一个非零值,位于响应序列的末尾,代表整个序列的标量奖励。
eos_mask: `(torch.Tensor)`
shape: (bs, response_length)
# 结束符 (End-Of-Sequence) 掩码。值为 1 的位置表示有效的响应 token,
# 通常在实际的 EOS token 处为 1,之后为 0。
# GRPO 论文中提到,优势被放置在 EOS token 的位置。
index: `(torch.Tensor)`
shape: (bs,)
# 每个样本的提示 (prompt) 索引。用于对具有相同提示的响应进行分组,
# 以便在同一提示下对它们的得分进行归一化。
epsilon: `(float)`
# 一个小的常数,用于防止在归一化时除以零(如果标准差为零)。
Returns:
advantages: `(torch.Tensor)`
shape: (bs, response_length)
# 计算得到的优势值。在 outcome supervision 的情况下,这通常是归一化后的标量奖励,
# 扩展到响应序列的长度,并由 eos_mask 掩码。
Returns: `(torch.Tensor)`
shape: (bs, response_length)
# 在这个特定的 GRPO outcome 实现中,返回值 (Returns) 与优势值 (advantages) 相同。
# 这是因为 GRPO 的 outcome 奖励直接作为优势,没有使用值函数进行基线扣除或 GAE 计算。
"""
# 获取响应序列的长度。
response_length = token_level_rewards.shape[-1]
# 创建一个掩码,标记 token_level_rewards 中非零元素的位置。
# 在 outcome supervision 中,这通常会标记出包含标量奖励的那个 token。
non_zero_mask = (token_level_rewards != 0)
# 将 token_level_rewards 与 non_zero_mask 相乘,确保只考虑非零奖励,
# 然后在最后一个维度(序列长度维度)上求和,提取出每个响应的标量得分。
# scores 的形状是 (bs,)。
scores = (token_level_rewards * non_zero_mask).sum(dim=-1)
# 初始化一个字典,用于按提示索引 (index) 对得分 (scores) 进行分组。
#键是提示索引,值是对应提示下所有响应得分的列表。
id2score = defaultdict(list)
# 初始化字典,用于存储每个提示索引对应的得分均值。
id2mean = {}
# 初始化字典,用于存储每个提示索引对应的得分标准差。
id2std = {}
# 在不计算梯度的上下文中执行以下操作,因为这些是数据处理步骤。
with torch.no_grad():
# 获取批次大小。
bsz = scores.shape[0]
# 遍历批次中的每个样本。
for i in range(bsz):
# 将当前样本的得分 scores[i] 添加到其对应提示索引 index[i] 的列表中。
id2score[index[i]].append(scores[i])
# 遍历 id2score 字典中所有的唯一提示索引。
for idx in id2score:
# 如果某个提示索引下只有一个响应得分。
if len(id2score[idx]) == 1:
# 将该提示的均值设为 0.0。
# 将该提示的标准差设为 1.0。
# 这样做是为了避免当只有一个样本时无法计算标准差,并提供一个默认的归一化行为。
id2mean[idx] = torch.tensor(0.0)
id2std[idx] = torch.tensor(1.0)
# 如果某个提示索引下有多个响应得分。
elif len(id2score[idx]) > 1:
# 计算这些得分的均值。
id2mean[idx] = torch.mean(torch.tensor(id2score[idx]))
# 计算这些得分的标准差。
id2std[idx] = torch.std(torch.tensor(id2score[idx]))
# 如果某个提示索引下没有得分(理论上不应发生,因为前面已经添加了)。
else:
raise ValueError(f"no score in prompt index: {idx}")
# 再次遍历批次中的每个样本,以对其得分进行归一化。
for i in range(bsz):
# 获取当前样本的提示索引。
prompt_idx = index[i]
# 对当前样本的得分进行归一化:(score - mean) / (std + epsilon)。
# 使用对应提示索引的均值和标准差。
scores[i] = (scores[i] - id2mean[prompt_idx]) / (id2std[prompt_idx] + epsilon)
# 将归一化后的标量得分 scores (形状 (bs,)) 扩展到响应序列的长度。
# 1. unsqueeze(-1) 将 scores 变为 (bs, 1)。
# 2. tile([1, response_length]) 将其复制 response_length 次,变为 (bs, response_length)。
# 3. 乘以 eos_mask,确保只有在 eos_mask 为 1 的位置(通常是 EOS token 及其之前)才有非零值。
# 这意味着归一化的奖励被放置在 EOS token 的位置。
scores = scores.unsqueeze(-1).tile([1, response_length]) * eos_mask
# 返回处理后的 scores 作为优势 (advantages) 和回报 (Returns)。
# 在这种 outcome-only 的 GRPO 设置中,归一化的 outcome 奖励直接用作优势和回报。
return scores, scores2.4 关于更新策略
update_actor -> update_policy -> compute_policy_loss
update_actor
这一步主要是使用刚刚获得的优势来更新Actor的策略(基于前面的token,下一个token的logits生成)
这一步主要是数据在硬件之间的转移和切换事项(CPU和GPU之间),中间使用封装好的update_policy 函数来更新模型的参数。
下面给出伪代码:
py
1. 处理一些硬件上的优化,如开启了参数卸载、优化器状态卸载,这一步就需要把参数重新加载回GPU
进入GPU操作:
2. 如果有序列并行设置,对数据做切分
3. 执行actor.update_policy(更新模型参数)这个方法会执行 PPO 算法的核心更新逻辑,包括计算损失、反向传播和参数更新。data 对象包含了训练所需的所有信息,如 input_ids, attention_mask, old_log_probs, advantages, returns 等
4. 更新学习率
5. 更新训练结果日志
6. 输出meta数据到cpu
7. 如果配置了参数卸载、优化器状态卸载,就把状态重新卸载到CPU
8. 清空缓存下面给出完整注释版本代码
py
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def update_actor(self, data: DataProto):
# 将输入数据(包含批次数据和元信息)整体移动到 CUDA 设备。
# 这通常意味着 DataProto 内部的 TensorDict 中的张量会被移到 GPU。
data = data.to('cuda')
# breakpoint() # 调试断点,通常在开发和调试时使用。
# 断言检查,确保当前 worker 实例确实扮演 Actor 的角色。
# self._is_actor 是在 __init__ 中根据传入的 role 设置的布尔标志。
assert self._is_actor
# 如果配置了参数卸载 (offload_param),则在更新前将 FSDP 包装的 Actor 模型的参数和梯度加载回 GPU。
# self._is_offload_param 和 self._is_offload_grad 是根据配置设置的标志。
if self._is_offload_param:
load_fsdp_param_and_grad(module=self.actor_module_fsdp, # FSDP 包装的 Actor 模型
device_id=torch.cuda.current_device(), # 当前 CUDA 设备 ID
load_grad=self._is_offload_grad) # 是否也加载梯度
# 如果配置了优化器状态卸载 (offload_optimizer),则在更新前将优化器状态加载回 GPU。
if self._is_offload_optimizer:
load_fsdp_optimizer(optimizer=self.actor_optimizer, # Actor 的优化器
device_id=torch.cuda.current_device()) # 当前 CUDA 设备 ID
# 再次确保批次数据在 CUDA 设备上。
# 尽管 data.to('cuda') 已经执行,这可以视为一个双重检查或针对特定情况的处理。
data.batch = data.batch.cuda()
# 记录更新策略前的 GPU 显存使用情况,用于调试和性能分析。
log_gpu_memory_usage('Before update policy', logger=logger)
# 使用 Ulysses Sharding Manager 的上下文管理器。
# 这个管理器负责处理序列并行 (Sequence Parallelism) 相关的数据切分和收集。
with self.ulysses_sharding_manager:
# 对输入数据进行预处理,以适应序列并行的需求。
# 例如,如果启用了序列并行,数据可能会在序列维度上被切分并分发到不同的 GPU。
data = self.ulysses_sharding_manager.preprocess_data(data=data)
# 执行实际的训练步骤(策略更新)
# 使用 Timer 来记录 update_policy 方法的执行时间。
with Timer(name='update_policy', logger=None) as timer:
# 调用 self.actor (通常是 DataParallelPPOActor 实例) 的 update_policy 方法。
# 这个方法会执行 PPO 算法的核心更新逻辑,包括计算损失、反向传播和参数更新。
# data 对象包含了训练所需的所有信息,如 input_ids, attention_mask, old_log_probs, advantages, returns 等。
metrics = self.actor.update_policy(data=data)
# 获取 update_policy 的执行时间
delta_time = timer.last
# 从元信息中获取全局处理的 token 数量
global_num_tokens = data.meta_info['global_token_num']
# 使用 FlopsCounter 估算本次更新的 FLOPs (浮点运算次数) 和 MFU (模型浮点运算利用率)。
# promised_flops 是模型的理论峰值 FLOPs。
estimated_flops, promised_flops = self.flops_counter.estimate_flops(global_num_tokens, delta_time)
# 计算 MFU (Model FLOPs Utilization) 并存入 metrics 字典。
# ppo_epochs 是 PPO 算法在一个批次数据上迭代的次数。
# world_size 是分布式训练中的总进程数 (GPU 数量)。
metrics['mfu/actor'] = estimated_flops * self.config.actor.ppo_epochs / promised_flops / self.world_size
# 更新学习率调度器 (Learning Rate Scheduler)
self.actor_lr_scheduler.step()
# 获取当前的学习率
lr = self.actor_lr_scheduler.get_last_lr()[0]
# 将当前学习率存入 metrics 字典
metrics['actor/lr'] = lr
# 记录更新策略后的 GPU 显存使用情况。
log_gpu_memory_usage('After update policy', logger=logger)
# TODO: here, we should return all metrics
# 创建一个新的 DataProto 对象,用于存储返回的 metrics。
# 注意:此时的 output 只包含 meta_info,不包含批次数据 (batch=None 默认)。
output = DataProto(meta_info={'metrics': metrics})
# 对输出数据 (仅含 metrics) 进行后处理,以适应序列并行的需求。
# 如果有序列并行,可能需要从不同设备收集或同步 metrics。
output = self.ulysses_sharding_manager.postprocess_data(data=output)
# 将最终的输出数据 (metrics) 移动到 CPU。
output = output.to('cpu')
# 如果配置了参数卸载,则在更新后将 FSDP 包装的 Actor 模型的参数和梯度卸载回 CPU (或指定的存储)。
if self._is_offload_param:
offload_fsdp_param_and_grad(module=self.actor_module_fsdp, offload_grad=self._is_offload_grad)
# 如果配置了优化器状态卸载,则在更新后将优化器状态卸载回 CPU。
if self._is_offload_optimizer:
offload_fsdp_optimizer(optimizer=self.actor_optimizer)
# 清空 PyTorch 的 CUDA 缓存,尝试释放未被引用的 GPU 显存。
torch.cuda.empty_cache()
# 返回包含训练指标 (metrics) 的 DataProto 对象。
return outputupdate_policy
这个函数的输入是一个DataProto变量 data,data中包含了所有更新策略需要的参数,input_ids, attention_mask, old_log_probs, advantages, returns
流程:
- 对于总的batch(32):
-
根据是否使用动态批次大小(use_dynamic_bsz)来切分
如果使用:
根据max_token切
不使用:
根据mini_batch_size(16)切分
-
对于microbatch in minibatch:
-
前向传播,获取熵(Entropy)和每个token的对数概率(log_prob)
pyentropy, log_prob = self._forward_micro_batch(micro_batch=data, temperature=temperature)` # > data.shape # torch.Size([40]) # > entropy.shape # torch.Size([40, 1024]) # > log_prob.shape # torch.Size([40, 1024]) -
计算策略梯度损失
pycompute_policy_loss(old_log_prob=old_log_prob, log_prob=log_prob, advantages=advantages, eos_mask=response_mask, # 使用响应掩码确保只在有效 token 上计算损失 cliprange=clip_ratio) -
计算熵损失
entropy_loss = verl_F.masked_mean(entropy, response_mask) -
计算最终的策略损失
- PPO 损失项减去熵损失项 (熵正则化,鼓励探索)
policy_loss = pg_loss - entropy_loss * entropy_coeff - 这是一个单独的值,指的是这个microbatch的平均的policy_loss
- PPO 损失项减去熵损失项 (熵正则化,鼓励探索)
-
-
(处理完了一个microbatch)
-
梯度累积算均值
-
反向传播梯度
-
-
(处理完了一个minibatch)
-
更新优化器
-
给出详细注释版本
py
def update_policy(self, data: DataProto):
# 确保 Actor 模型处于训练模式 (例如,启用 Dropout 等)。
self.actor_module.train()
# 断言检查:PPO 的小批次大小 (ppo_mini_batch_size) 必须能被微批次大小 (ppo_micro_batch_size) 整除。
# 这是梯度累积正确工作的前提。
assert self.config.ppo_mini_batch_size % self.config.ppo_micro_batch_size == 0
# 计算梯度累积的步数。在一个小批次 (mini-batch) 中,梯度会累积 gradient_accumulation 个微批次 (micro-batch) 后再进行一次参数更新。
self.gradient_accumulation = self.config.ppo_mini_batch_size // self.config.ppo_micro_batch_size
# 从输入数据的元信息中获取温度参数。温度参数用于缩放 logits,影响概率分布的平滑度。
# 注释强调了温度参数必须在 meta_info 中,以避免静默错误。
temperature = data.meta_info['temperature']
# 定义需要从 DataProto 对象中选择的数据字段,用于 Actor 策略更新。
select_keys = ['responses', 'input_ids', 'attention_mask', 'position_ids', 'old_log_probs', 'advantages']
# 如果配置了使用 KL 散度损失 (use_kl_loss),则额外选择 'ref_log_prob' (参考策略的对数概率)。
if self.config.use_kl_loss:
select_keys.append('ref_log_prob')
# 从 DataProto 对象中提取这些选定的字段,形成一个批次数据 (TensorDict)。
batch = data.select(batch_keys=select_keys).batch
# 将整个批次数据 (batch) 按照 PPO 的小批次大小 (ppo_mini_batch_size) 切分成多个小批次。
# 这种做法遵循 PPO 论文中的细节,即在多个 epoch 中迭代这些小批次数据进行更新。
# dataloader 是一个可迭代对象,每次迭代返回一个小批次 (mini-batch) 数据。
dataloader = batch.split(self.config.ppo_mini_batch_size)
metrics = {} # 初始化一个字典来存储训练过程中的各种指标。
# 遍历每个小批次 (mini-batch) 数据。
for batch_idx, data in enumerate(dataloader):
# 当前的 data 就是一个小批次 (mini-batch) 数据。
mini_batch = data
# 如果配置了使用动态批次大小 (use_dynamic_bsz)。
if self.config.use_dynamic_bsz:
# 计算每个 GPU 在考虑序列并行后的最大 token 长度。
max_token_len = self.config.ppo_max_token_len_per_gpu * self.ulysses_sequence_parallel_size
# 使用 rearrange_micro_batches 将当前小批次 (mini_batch) 动态地重新排列成微批次 (micro-batches),
# 以便每个微批次的总 token 数大致均衡。忽略返回的索引,因为这里不需要恢复顺序。
micro_batches, _ = rearrange_micro_batches(batch=mini_batch, max_token_len=max_token_len)
else:
# 如果不使用动态批次大小,则按固定的微批次大小 (ppo_micro_batch_size) 将小批次 (mini_batch) 切分成微批次。
micro_batches = mini_batch.split(self.config.ppo_micro_batch_size)
# 在处理每个小批次 (mini-batch) 之前,清零 Actor 优化器的梯度。
# 这是因为梯度是按小批次累积的(如果 gradient_accumulation > 1),或者在每个小批次后更新。
self.actor_optimizer.zero_grad()
# 遍历当前小批次中的每个微批次 (micro-batch) 数据。
for data in micro_batches:
# 将微批次数据移动到 CUDA 设备。
# 注释提到,当使用卸载 (offload) 时,Actor 的设备可能是 CPU,所以这里确保数据在 GPU 上进行计算。
data = data.cuda()
# 从微批次数据中提取响应序列、其长度、注意力掩码、旧的对数概率和优势值。
responses = data['responses']
response_length = responses.size(1)
attention_mask = data['attention_mask']
# 提取响应部分的注意力掩码,用于在计算损失时只考虑有效 token。
response_mask = attention_mask[:, -response_length:]
old_log_prob = data['old_log_probs'] # 由旧策略(行为策略)计算的对数概率
advantages = data['advantages'] # 估计的优势函数值
# 从配置中获取 PPO 裁剪比率和熵损失系数。
clip_ratio = self.config.clip_ratio
entropy_coeff = self.config.entropy_coeff
# 调用 _forward_micro_batch 方法,使用当前 Actor 模型对微批次数据进行前向传播,
# 获取当前策略下的熵 (entropy) 和对数概率 (log_prob)。
# 返回的 entropy 和 log_prob 的形状都是 (bsz, response_length)。
entropy, log_prob = self._forward_micro_batch(micro_batch=data, temperature=temperature)
# 使用 core_algos.compute_policy_loss 计算 PPO 的策略梯度损失 (pg_loss)。
# 同时返回裁剪部分的比例 (pg_clipfrac) 和新旧策略间的 KL 散度近似值 (ppo_kl)。
pg_loss, pg_clipfrac, ppo_kl = core_algos.compute_policy_loss(old_log_prob=old_log_prob,
log_prob=log_prob,
advantages=advantages,
eos_mask=response_mask, # 使用响应掩码确保只在有效 token 上计算损失
cliprange=clip_ratio)
# 从前向传播得到的熵计算熵损失。
# verl_F.masked_mean 会根据 response_mask 计算掩码后的平均熵。
entropy_loss = verl_F.masked_mean(entropy, response_mask)
# 计算最终的策略损失,PPO 损失项减去熵损失项 (熵正则化,鼓励探索)。
policy_loss = pg_loss - entropy_loss * entropy_coeff
# 如果配置了使用 KL 散度损失。
if self.config.use_kl_loss:
# 获取参考策略的对数概率。
ref_log_prob = data['ref_log_prob']
# 计算当前策略与参考策略之间的 KL 散度惩罚。
kld = core_algos.kl_penalty(logprob=log_prob,
ref_logprob=ref_log_prob,
kl_penalty=self.config.kl_loss_type) # KL 惩罚的类型
# 计算掩码后的平均 KL 散度损失。
kl_loss = masked_mean(kld, response_mask)
# 将 KL 散度损失项添加到总的策略损失中。
policy_loss = policy_loss - kl_loss * self.config.kl_loss_coef
# 记录 KL 散度损失和系数到 metrics 中。
metrics['actor/kl_loss'] = kl_loss.detach().item()
metrics['actor/kl_coef'] = self.config.kl_loss_coef
# 将计算得到的策略损失除以梯度累积步数。
# 这是梯度累积的标准做法,确保在多次累积后,等效的损失与直接使用大批次计算的损失一致。
loss = policy_loss / self.gradient_accumulation
# 对该微批次的损失进行反向传播,计算梯度。梯度会累积在模型参数上。
loss.backward()
# 准备当前微批次的指标数据。
# .detach().item() 用于获取标量值,并从计算图中分离,避免不必要的梯度跟踪。
data = {
'actor/entropy_loss': entropy_loss.detach().item(),
'actor/pg_loss': pg_loss.detach().item(),
'actor/pg_clipfrac': pg_clipfrac.detach().item(),
'actor/ppo_kl': ppo_kl.detach().item(),
}
# 将当前微批次的指标追加到总的 metrics 字典中 (通常是累加或取平均)。
append_to_dict(metrics, data)
# 在处理完一个小批次 (mini-batch) 内的所有微批次后,执行优化器步骤。
# _optimizer_step 内部会进行梯度裁剪并调用 self.actor_optimizer.step() 来更新模型参数。
grad_norm = self._optimizer_step()
# 准备梯度范数的指标数据。
data = {'actor/grad_norm': grad_norm.detach().item()}
# 将梯度范数指标追加到总的 metrics 字典中。
append_to_dict(metrics, data)
# 在所有小批次处理完毕后(即一个 PPO epoch 完成后),再次清零优化器的梯度。
# 这是一个良好的习惯,确保下一个 PPO epoch 开始时梯度是干净的。
self.actor_optimizer.zero_grad()
# 返回包含本次策略更新所有相关指标的字典。
return metricscompute_policy_loss
这个函数会返回一个policy_loss值,反映了当前策略对比之前策略的好坏,反映了在这个micro_batch上遵循了优势信号的平均表现。这个值将用于反向转播更新当前策略的梯度。通常来讲,loss越小越好,我们通常在优化中最小化损失函数。
公式如下:
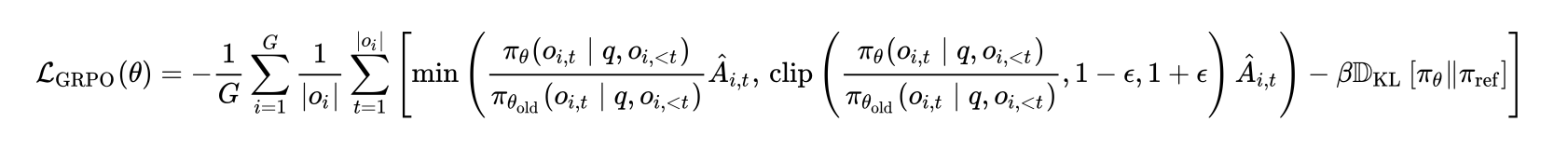
含义:
py
对于rollout中的所有response:
对于response中每一个token:
1. 计算当前策略和之前策略选取这个token的概率的比值(记作重要性权重`ratio`)
2. 计算`ratio * 这个token的优势值`(如果这个动作的优势值大,那么你多选就会收到鼓励--值为正数,少选就会收到惩罚--值为负数)
3. 减去KL散度(衡量两个策略的差异)。
返回平均值(求和后除以token数量)
返回平均值(求和后除以response数量)verl实现:
py
对于一个micro_batch中的所有response:
1. 计算`ratio`矩阵
2. 计算`ratio矩阵 * -advantages矩阵`
3. 计算`clip(ratio矩阵 * -advantages矩阵)`
4. 通过`response_mask`计算micro_batch所有的值的平均值?????没懂为什么可以在micro_batch的范围上求解
TODO:
搞清楚这个
完整详细注释版本代码:
py
def compute_policy_loss(old_log_prob, log_prob, advantages, eos_mask, cliprange):
"""Adapted from https://github.com/huggingface/trl/blob/main/trl/trainer/ppo_trainer.py#L1122
Args:
old_log_prob: `(torch.Tensor)`
shape: (bs, response_length)
# 旧策略(行为策略)下,每个响应 token 的对数概率。
# 对应 PPO 公式中的 log(π_θ_old(a_t | s_t))。
log_prob: `(torch.Tensor)`
shape: (bs, response_length)
# 当前策略(新策略)下,每个响应 token 的对数概率。
# 对应 PPO 公式中的 log(π_θ(a_t | s_t))。
advantages: `(torch.Tensor)`
shape: (bs, response_length)
# 估计的优势函数值。
# 对应 PPO 公式中的 A_t。
eos_mask: `(torch.Tensor)`
shape: (bs, response_length)
# 结束符掩码,用于确保只在有效的响应 token 上计算损失。
cliprange: (float)
# PPO 中使用的裁剪范围,通常是一个小值,如 0.2。
# 对应 PPO 公式中的 ε。
Returns:
pg_loss: `a scalar torch.Tensor`
# 通过 PPO 计算得到的策略梯度损失。
pg_clipfrac: (float)
# 一个浮点数,表示被裁剪的策略梯度损失的比例。
ppo_kl: (float)
# 新旧策略之间 KL 散度的近似值。
PPO Clipped Surrogate Objective:
L_CLIP(θ) = E_t [ min(r_t(θ) * A_t, clip(r_t(θ), 1 - ε, 1 + ε) * A_t) ]
通常我们最大化这个目标,或者最小化其负值。
"""
# 计算 log(π_θ(a_t | s_t)) - log(π_θ_old(a_t | s_t))
# 这等于 log(π_θ(a_t | s_t) / π_θ_old(a_t | s_t)) = log(r_t(θ))
# negative_approx_kl 实际上是 log(ratio),即重要性权重 r_t(θ) 的对数。
# KL 散度 D_KL(P || Q) ≈ E_P[log P - log Q]。这里 P 是旧策略,Q 是新策略,所以是 D_KL(π_θ_old || π_θ)。
# 因此,-negative_approx_kl = old_log_prob - log_prob 是 D_KL(π_θ || π_θ_old) 的一个近似(或者说,是逐点 KL)。
negative_approx_kl = log_prob - old_log_prob
# 计算重要性权重 r_t(θ) = π_θ(a_t | s_t) / π_θ_old(a_t | s_t)
# ratio = exp(log_prob - old_log_prob)
ratio = torch.exp(negative_approx_kl)
# 计算新旧策略之间 KL 散度的近似值的掩码后均值。
# -negative_approx_kl = old_log_prob - log_prob
# ppo_kl 是 E_t[log π_θ_old - log π_θ] 的一个估计,可以看作是 KL(π_θ_old || π_θ) 的近似。
# 有些实现也用 (ratio - 1) - log_ratio 作为 KL 散度的一个更精确的估计。
ppo_kl = verl_F.masked_mean(-negative_approx_kl, eos_mask)
# 计算 PPO 目标函数的第一项(未裁剪部分): -A_t * r_t(θ)
# 注意这里的负号,因为我们通常是最小化损失,而 PPO 目标是最大化。
# 所以,pg_losses 对应于 - (r_t(θ) * A_t)
pg_losses = -advantages * ratio
# 计算 PPO 目标函数的第二项(裁剪部分): -A_t * clip(r_t(θ), 1 - ε, 1 + ε)
# torch.clamp(ratio, 1.0 - cliprange, 1.0 + cliprange) 对应于 clip(r_t(θ), 1 - ε, 1 + ε)
# pg_losses2 对应于 - (clip(r_t(θ), 1 - ε, 1 + ε) * A_t)
pg_losses2 = -advantages * torch.clamp(ratio, 1.0 - cliprange, 1.0 + cliprange)
# PPO 目标函数是取未裁剪和裁剪项中较"差"(对于最大化目标而言是较小,对于最小化损失而言是较大)的一项。
# torch.max(pg_losses, pg_losses2) 对应于 min(-pg_losses, -pg_losses2) 如果目标是最大化。
# 由于 pg_losses 和 pg_losses2 已经是负的目标项,所以 torch.max 实际上是选择了
# min(r_t(θ) * A_t, clip(r_t(θ), 1 - ε, 1 + ε) * A_t) 的负值。
# pg_loss 是 E_t [ - min(r_t(θ) * A_t, clip(r_t(θ), 1 - ε, 1 + ε) * A_t) ]
# 即,pg_loss = - L_CLIP(θ)
pg_loss = verl_F.masked_mean(torch.max(pg_losses, pg_losses2), eos_mask)
# 计算被裁剪的比例。
# torch.gt(pg_losses2, pg_losses) 检查裁剪项是否比未裁剪项"更差"(即更大,因为它们是负值)。
# 当 pg_losses2 > pg_losses 时,意味着 -adv * clipped_ratio > -adv * ratio。
# 如果 adv > 0: -clipped_ratio > -ratio => clipped_ratio < ratio. 这意味着 ratio 被向下裁剪了。
# 如果 adv < 0: -clipped_ratio > -ratio => clipped_ratio > ratio. 这意味着 ratio 被向上裁剪了。
# 实际上,当 pg_losses2 > pg_losses 时,意味着未裁剪的项 pg_losses 被选择了(因为 max 操作),
# 这表明裁剪发生了作用,使得 pg_losses2 (基于裁剪后的 ratio) 比 pg_losses (基于原始 ratio) 更"有利"于优化器(即损失值更大)。
# 更准确地说,当 pg_losses2 > pg_losses 时,意味着原始的 ratio * advantages 项被裁剪了。
# 例如,如果 advantages > 0,且 ratio > 1 + cliprange,则 ratio 被裁剪为 1 + cliprange。
# 此时 pg_losses = -advantages * ratio (更小的负数,即更大的损失)
# pg_losses2 = -advantages * (1 + cliprange) (更大的负数,即更小的损失)
# 此时 pg_losses2 < pg_losses,所以 torch.gt(pg_losses2, pg_losses) 为 False。
# 当裁剪发生时,意味着 pg_losses (未裁剪) 和 pg_losses2 (裁剪) 中,有一个不是原始的 -advantages * ratio。
# pg_clipfrac 计算的是 pg_losses2 > pg_losses 的情况的比例,
# 这表示裁剪后的损失项 (-advantages * clipped_ratio) 比原始损失项 (-advantages * ratio) 更大(即更差)。
# 这发生在 ratio 被裁剪到离1更近,并且 advantages 的符号使得这个裁剪导致了更大的损失值。
# 简单来说,它衡量了有多少比例的样本因为裁剪而选择了 clip(ratio) * advantages 这一项的负值。
pg_clipfrac = verl_F.masked_mean(torch.gt(pg_losses2, pg_losses).float(), eos_mask)
# 返回计算得到的策略损失、裁剪比例和 KL 散度近似值。
return pg_loss, pg_clipfrac, ppo_kl2.5 关于重要性采样
PPO / GRPO的公式都是基于重要性采样的。重要性采样指的是用另一种更简单的分布来估计原有分布的期望。在PPO中,就是使用(新的策略选择当前动作的比率/旧的策略选择当前动作的比率 )* 当前动作的优势来作为目标函数。
它的目的:
-
修正概率不匹配:
- PPO 是一种离策略(Off-Policy)算法。这意味着用于训练当前策略
π_θ(新策略)的数据(经验)通常是由一个较早版本的策略π_θ_old(行为策略或旧策略)生成的。 - 由于
π_θ和π_θ_old对于相同的状态可能会以不同的概率选择相同的动作,直接使用旧数据来评估新策略的期望回报是不准确的。 - 重要性采样通过引入一个重要性权重(或重要性比率) 来修正这种概率上的差异。这个权重是新策略下采取某个动作的概率与旧策略下采取同一个动作的概率之比:
r_t(θ) = π_θ(a_t | s_t) / π_θ_old(a_t | s_t) - 这个比率
r_t(θ)告诉我们,相对于旧策略,新策略选择动作a_t的可能性是增加了还是减少了。
- PPO 是一种离策略(Off-Policy)算法。这意味着用于训练当前策略
-
调整优势函数:
- 在 PPO 的目标函数中,这个重要性比率
r_t(θ)会乘以从旧策略经验中计算出来的优势函数A_t(advantages)。 r_t(θ) * A_t可以被看作是对优势函数的一个调整,使其能够反映在新策略π_θ下采取动作a_t的"价值"。
- 在 PPO 的目标函数中,这个重要性比率
-
实现离策略更新:
- 通过这种方式,PPO 可以使用由
π_θ_old收集的经验来估计在π_θ下的期望回报,从而进行策略改进。这提高了数据利用效率,因为不需要在每次策略微小更新后都重新收集全新的经验。
- 通过这种方式,PPO 可以使用由
重要性采样在哪里工作?
在 update_policy 函数(dp_actor.py)中,重要性采样的机制主要体现在以下几个方面,并最终在 core_algos.compute_policy_loss 函数中被显式或隐式地使用:
-
输入数据包含旧策略的对数概率:
old_log_prob = data['old_log_probs']- 这个
old_log_probs张量存储的是log(π_θ_old(a_t | s_t)),即行为策略(用于生成当前批次数据的策略)下,每个响应 token 的对数概率。这是计算重要性比率的分母部分(的对数)。
-
计算新策略的对数概率:
entropy, log_prob = self._forward_micro_batch(micro_batch=data, temperature=temperature)- 这个
log_prob张量存储的是log(π_θ(a_t | s_t)),即当前正在优化的 Actor 模型(新策略)下,每个响应 token 的对数概率。这是计算重要性比率的分子部分(的对数)。
-
在
core_algos.compute_policy_loss中使用:pg_loss, pg_clipfrac, ppo_kl = core_algos.compute_policy_loss(old_log_prob=old_log_prob, log_prob=log_prob, advantages=advantages, eos_mask=response_mask, cliprange=clip_ratio)- 这个函数是 PPO 核心算法实现的地方。它接收
old_log_prob和log_prob作为输入。 - 在
compute_policy_loss内部,会计算重要性比率r_t(θ),通常是通过exp(log_prob - old_log_prob)来计算。 - 然后,这个计算出的
r_t(θ)会被用于 PPO 的裁剪替代目标函数 (Clipped Surrogate Objective) :
L_CLIP(θ) = E_t [ min(r_t(θ) * A_t, clip(r_t(θ), 1 - ε, 1 + ε) * A_t) ]
其中A_t是优势函数 (advantages),ε是裁剪参数 (clip_ratio)。 pg_loss就是这个L_CLIP(θ)(或者其负值,因为通常是最小化损失)。
总结:
重要性采样在 PPO 中通过以下方式工作:
- 获取概率: 从数据中获取旧策略(行为策略)选择动作的(对数)概率 (
old_log_probs)。 - 计算新概率: 使用当前正在训练的策略(目标策略)计算其选择相同动作的(对数)概率 (
log_probs)。 - 计算重要性比率: 在损失函数计算的核心部分(
core_algos.compute_policy_loss),利用这两个概率计算出重要性比率r_t(θ) = π_θ / π_θ_old。 - 应用到目标函数: 将这个比率乘以优势函数
A_t,并应用 PPO 特有的裁剪机制,形成最终的策略梯度损失。
2.6 关于长短response样本对结果的影响
这是一个很有意思的问题
py
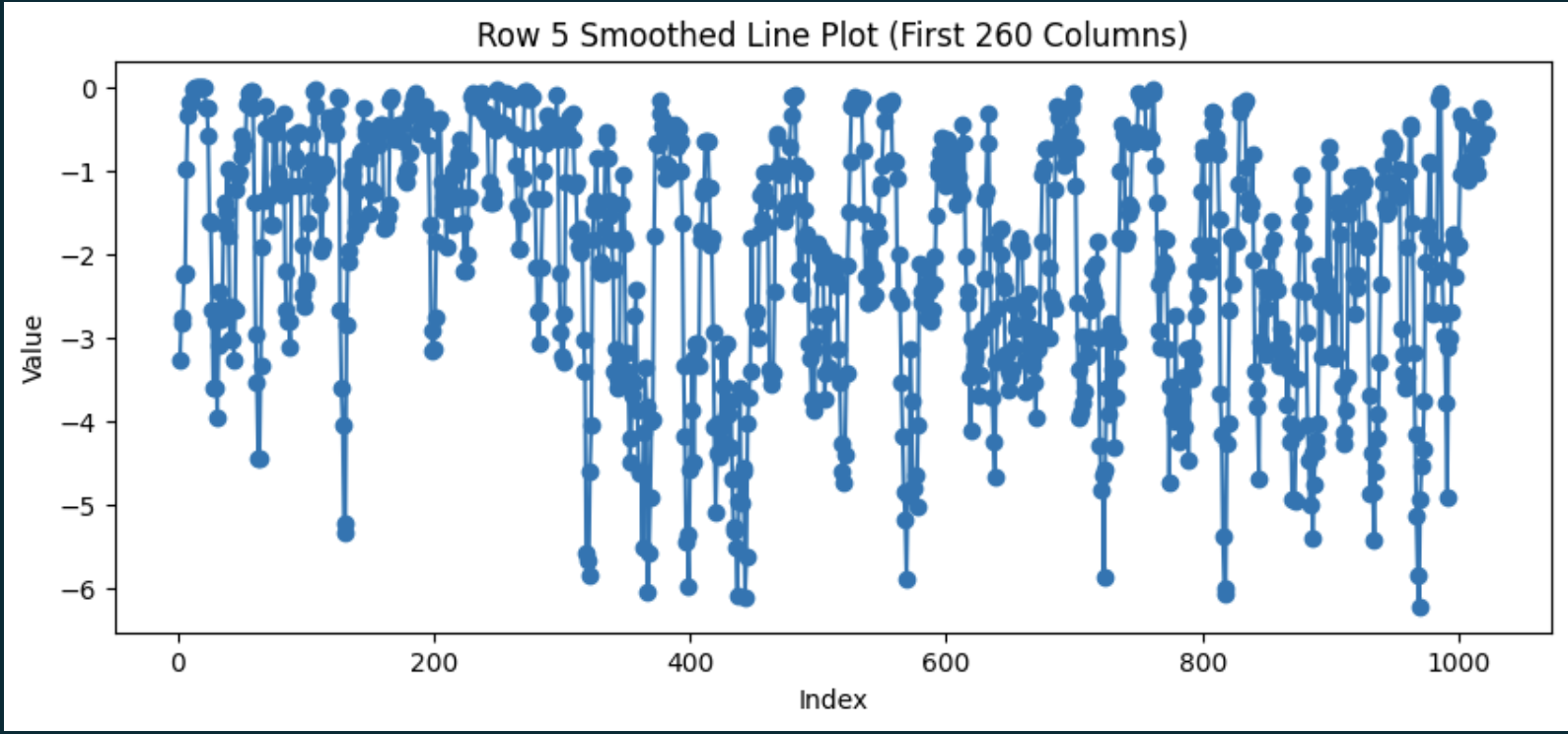
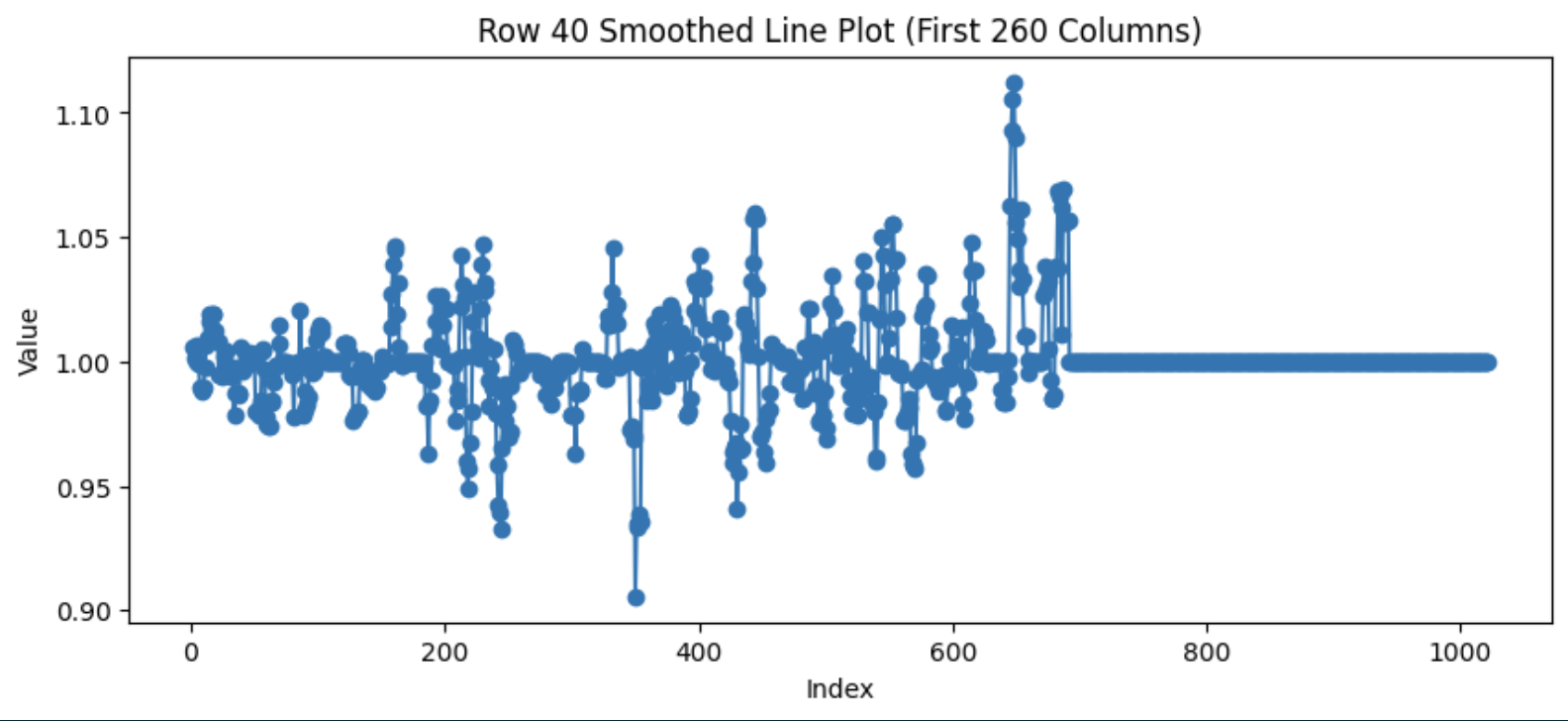
首先解释下,为什么会出现这种现象 ------ 因为对于LLM来说,模型生成下一个 token 的概率并不是一成不变的, 而是随着生成句子长度的增加,下一个 token 的概率在整体上是越来越高的,也就是不确定性越来越低。如果统计下整个 repsonse 的log_prob 变化,大概如下面的形状,也就是越往后面 log_prob 是越来越大的(绝对值越来越小)。所以对于长度越长的repsonse,如果直接除以自身的长度值 |oi| ,得到的平均 log_prob 就是越大(绝对值越小),其内部的 token 在总体损失中的贡献就会被相对稀释,再结合advantage正负值,就会出现 "短的正确答案 > 长的正确答案 > 长的错误答案 > 短的错误答案" 的结果。
作者:Kangkang
链接:https://zhuanlan.zhihu.com/p/1891850600238519595
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。随着句子长度增加,下一个token对数概率(log_prob)在整体上是越来越高(绝对值越来越小)的(呈现log曲线)。没有看懂为什么log_prob会直接影响梯度,我观察公式似乎是以ratio的形式影响loss。
假设修改的幅度越来越低,那么对于长的response,ratio * 优势 / token数的值就会低于短的token。
实验
在1000prompt长度未观测到变长变小的现象
log_prob:
ratio:
TODO:使用更长的上下文实验