本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴
前言
在数字化办公与内容创作的浪潮中,将 PDF 文件转换为 JPG 图片格式的需求日益频繁。无论是学术文献中的图表提取,还是宣传资料的视觉化呈现,PDF 转 JPG 都能为后续编辑、分享和展示提供极大便利。然而,这一看似简单的转换过程,却暗藏诸多痛点。与此同时,一款强大的编程辅助工具 ------CodeBuddy,正以其卓越的 AI 编程能力,为开发者攻克这些难题提供有力支持。
并且网络上都是要钱的,效果还不咋地,那么我们就自己使用CodeBuddy造一个
PDF 转 JPG 图片的常见痛点
- 转换质量参差不齐
市面上许多在线转换工具虽然操作简便,但转换后的 JPG 图片往往存在清晰度下降、色彩失真等问题。尤其是对于包含复杂图形、公式或高精度图像的 PDF 文件,转换后可能出现边缘模糊、文字重影等现象,严重影响图片的可用性。而一些专业软件虽然转换质量较高,但操作复杂,且可能存在付费门槛,对于普通用户而言成本过高。
- 批量处理效率低下
当需要处理大量 PDF 文件时,手动逐一转换不仅耗时耗力,还容易出现遗漏或错误。部分工具虽支持批量转换,但在处理过程中可能出现程序卡顿、崩溃等情况,导致转换任务中断,用户不得不重新操作,极大降低了工作效率。
- 编程实现难度较大
对于有一定编程基础,希望通过 Python 等编程语言开发自定义 PDF 转 JPG 工具的用户来说,也面临着不小的挑战。Python 中涉及 PDF 处理的库(如 PyPDF2、ReportLab 等)和图像操作库(如 Pillow)功能丰富但学习曲线较陡,开发者需要花费大量时间学习库的使用方法、调试代码,且在处理复杂 PDF 文件时,容易出现内存溢出、多线程处理不当等问题,增加了开发难度和时间成本。
使用CodeBuddy的原因
- 智能代码生成与优化
CodeBuddy 基于先进的ai代码编程,能够根据用户输入的需求快速生成高质量的 Python 代码。当开发者想要开发 PDF 转 JPG 图片小工具时,只需简单描述功能需求,如 "将 PDF 文件的每一页转换为 JPG 图片,保持高清晰度并支持批量处理",CodeBuddy 就能迅速分析需求,自动生成包含文件读取、页面解析、图像转换等核心功能的代码框架。不仅如此,它还能对生成的代码进行智能优化,针对 PDF 处理过程中可能出现的性能瓶颈,如内存占用过高、转换速度慢等问题,自动调整代码逻辑,采用更高效的算法和数据结构,提升程序运行效率。
在 Python 编程过程中,代码报错是不可避免的问题。CodeBuddy 的实时错误诊断功能能够在开发者编写代码时立即检测到语法错误、逻辑漏洞等问题,并给出详细的错误提示和修复建议。例如,当开发者在使用 Pillow 库保存 JPG 图片时,因参数设置错误导致图片保存失败,CodeBuddy 会精准定位到错误代码行,指出是图像质量参数设置不当,并提供正确的参数设置示例,帮助开发者快速解决问题,避免因错误排查耗费大量时间,显著提高开发效率。
使用CodeBuddy生成PDF 转 JPG 图片小工具
我们打开vscode进入到拓展中直接搜索CodeBuddy,点击安装这个插件就行了
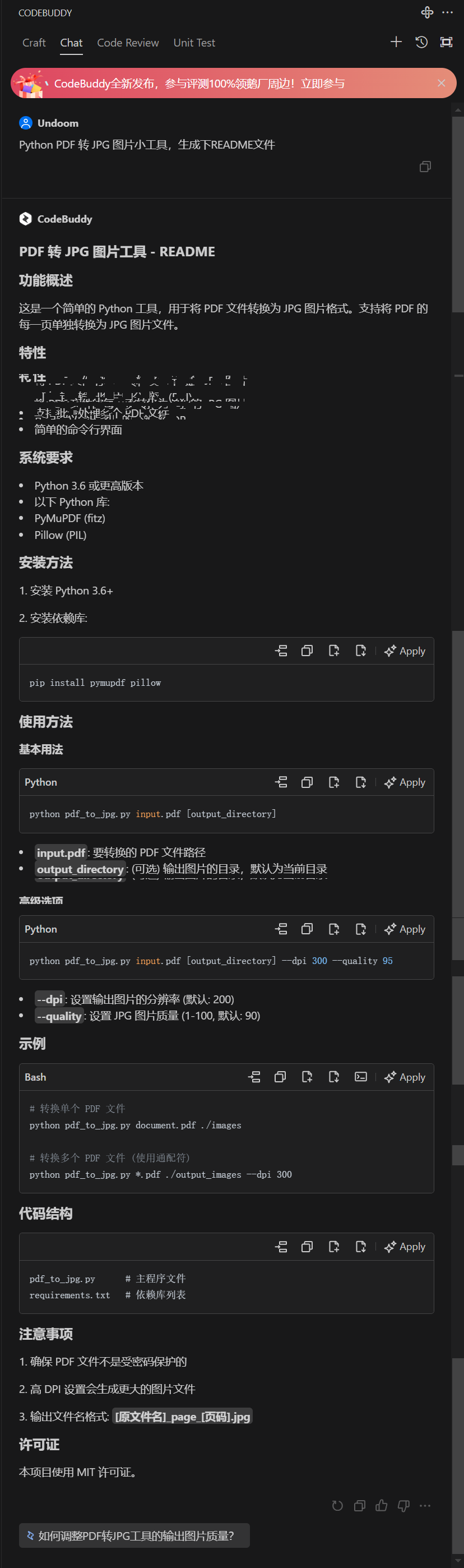
我们先在chat模式生成出我们需要的对应的README文件
我们直接将生成的信息复制到我们的README文件里面
可是看到这里我们有详细的运行介绍操作
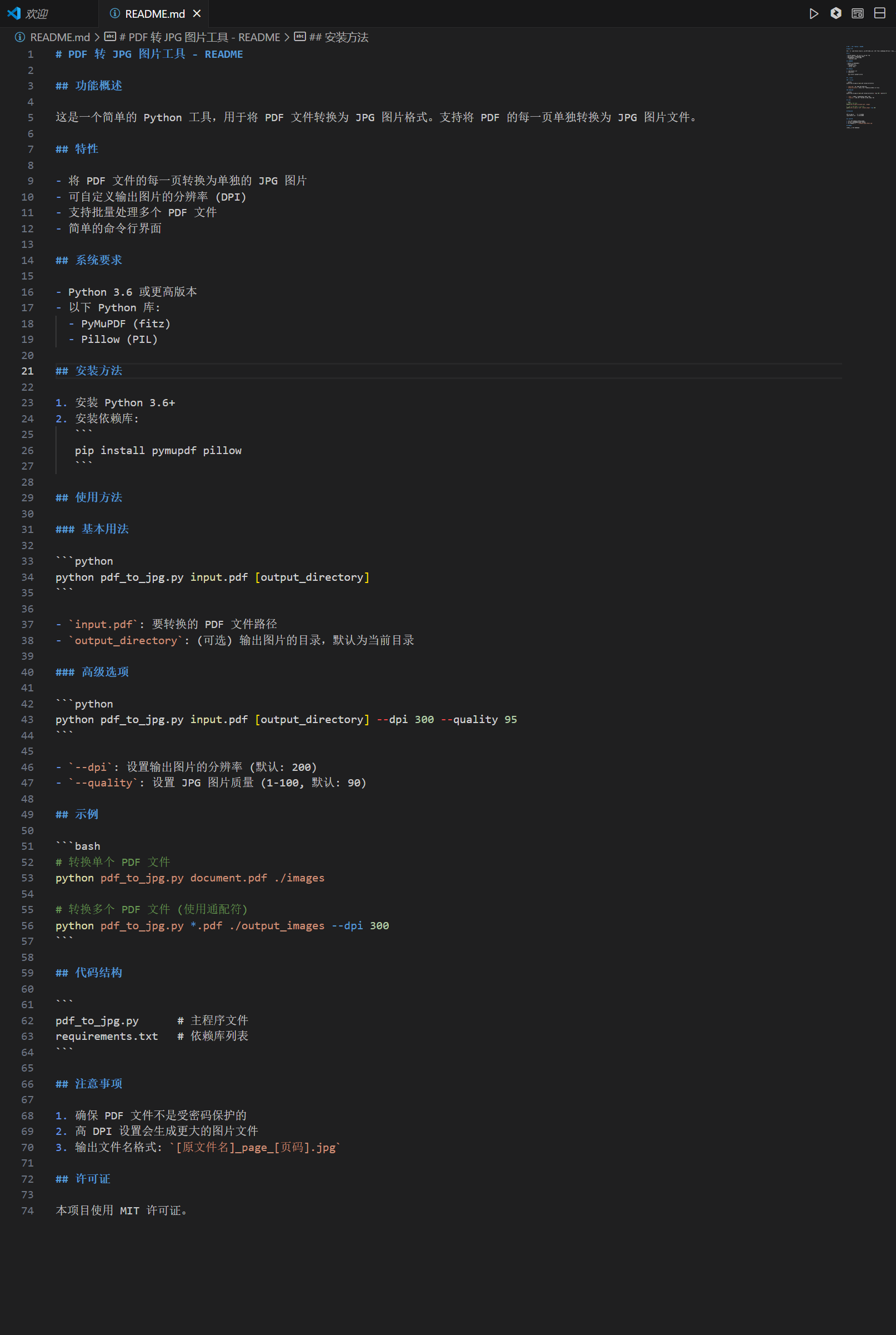
还是老样子,我们直接艾特上README文件进行代码的编程操作
这里我们就开始了自动化编程,我们都不用管,CodeBuddy他会自动帮我们进行运行操作
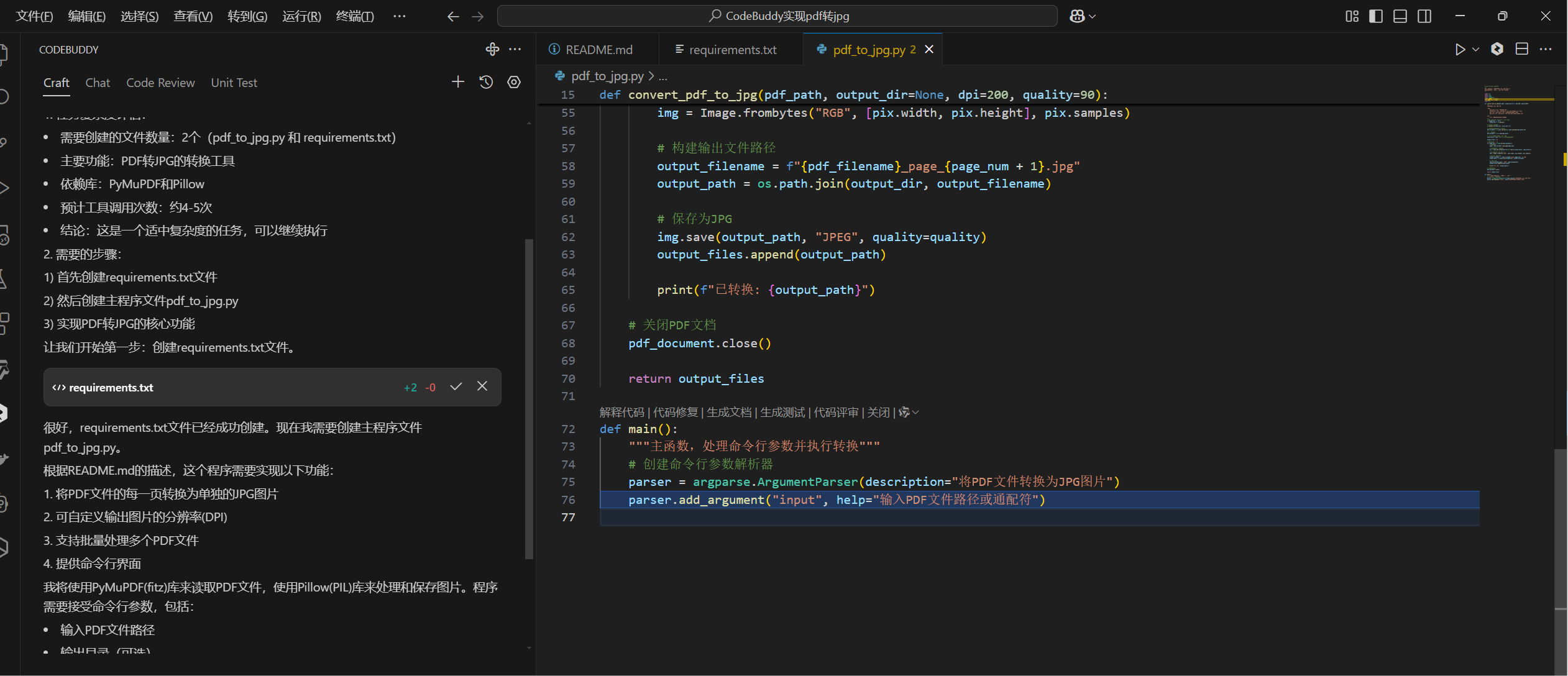

我们运行下代码试试,效果还是不错的
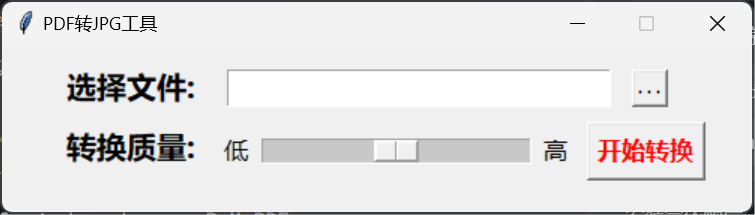
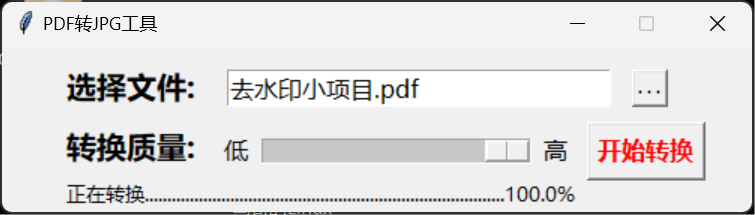
这里程序会根据我们的pdf篇幅进行转换操作,我们这里生成了3个jpg文件
内容还是很清晰的

代码如下:感兴趣的可以去试试呢
Python
#coding:utf-8
import tkinter as tk
from tkinter import Label
from tkinter import Entry
from tkinter import filedialog
from tkinter.font import Font
import os
import fitz
from tkinterdnd2 import DND_FILES,TkinterDnD
def center_window(root, width, height): #创建窗口居中
screen_width = root.winfo_screenwidth()
screen_height = root.winfo_screenheight()
x = int((screen_width - width) / 2)
y = int((screen_height - height) / 2)
root.geometry(f"{width}x{height}+{x}+{y}")
def open_file(): #浏览文件按钮代码
filetypes = (('pdf files', '*.pdf'),('All files', '*.*'))
file = filedialog.askopenfilename(title='选择PDF文件',initialdir=os.getcwd(),filetypes=filetypes)
pathname.delete(0, tk.END)
pathname_2.delete(0, tk.END)
if str.upper(file[-3:])=='PDF':
pathname.insert(0, os.path.split(file)[1])
pathname_2.insert(0, file)
def main(): #开始转换按钮代码
path = pathname_2.get()
name = pathname.get()[:-4]
value_list = [1/3,2/3,4/3,8/3,16/3]
# 图片缩放倍数(0.25,0.5,原分辨率,2倍,4倍)
value_base =int(slider.get())
value = value_list[value_base]
pdf = fitz.open(path)
for page_num in range(len(pdf)):
page = pdf.load_page(page_num)
mat = fitz.Matrix(value,value)
pix = page.get_pixmap(matrix=mat)
# 图片缩放
if len(pdf) == 1:
outpath = path[:-4]+'.jpg'
else:
if not os.path.exists(path[:-4]):
os.mkdir(path[:-4])
outpath = os.path.join(path[:-4] , f'{name}_{page_num}.jpg')
pix.save(outpath)
num = (page_num+1)/len(pdf)*100//1.25
text = '正在转换'+'.'* int(num)+str(round((page_num+1)/len(pdf)*100,1))+'%'
label.config(text=text)
win.update()
def drop(event): #支持拖拽文件
file =event.data
label.config(text='')
pathname.delete(0, tk.END)
pathname_2.delete(0, tk.END)
if ' ' in file:
file = file[1:-1] #文件名有空格时,会生成大括号
if str.upper(file[-3:])=='PDF':
pathname.insert(0, os.path.split(file)[1])
pathname_2.insert(0, file)
win = TkinterDnD.Tk()
win.title('PDF转JPG工具')
center_window(win, 500, 110)
win.resizable(False, False) #锁定窗口大小
win.wm_attributes('-topmost', 1) #窗口保持前置
ft = Font(family='微软雅黑', size=15, weight='bold')
Label(text='选择文件:',font=ft).place(x=40, y=10)
Label(text='转换质量:',font=ft).place(x=40, y=50)
Label(text='低',font=Font(family='微软雅黑', size=12)).place(x=145, y=55)
Label(text='高',font=Font(family='微软雅黑', size=12)).place(x=358, y=55)
entry_font = ('微软雅黑', 12)
pathname = Entry(win, width=28,font=entry_font)
pathname.place(x=150, y=15)
#文本框,用于显示文件名
pathname_2 = Entry(win, width=28,font=entry_font)
pathname_2.place(x=150, y=150)
#隐藏文本框,用于获取完整路径
browser_button = tk.Button(win, text='. . .',font=Font(family='微软雅黑', size=7,weight='bold') ,command=open_file)
browser_button.place(x=420, y=15)
win.drop_target_register(DND_FILES)
win.dnd_bind('<<Drop>>',drop)
label = tk.Label(win,text='', font=Font(family='微软雅黑', size=10))
label.place(x=40, y=85)
#用于显示进度
button = tk.Button(win, text='开始转换',fg='red',font=Font(family='微软雅黑', size=12,weight='bold') ,command=main)
button.place(x=390, y=50)
slider = tk.Scale(win, from_=0, to=4,orient=tk.HORIZONTAL,length=180,sliderlength=30,sliderrelief=tk.RIDGE,showvalue=False,resolution=1)
slider.place(x=170, y=58)
slider.set(2)
win.mainloop()总结
在 PDF 转 JPG 的实际应用中,用户普遍面临转换质量差、批量处理效率低、格式兼容性不足以及编程实现困难等痛点。而 CodeBuddy 凭借智能代码生成与优化、实时错误诊断修复、助力代码学习拓展,以及支持多场景适配与个性化定制等强大的 AI 编程能力,精准直击这些难题。使用 CodeBuddy 开发 Python PDF 转 JPG 小工具,能够有效提升转换效率与质量,降低开发门槛和成本,为用户带来高效、优质的文件格式转换体验。
感兴趣的可以来试试哦!