在碎片化阅读时代,我们经常需要将网页上的精彩段落保存下来,整理成 PDF 或 EPUB 放入电子书阅读器中。现有的插件(如 Evernote、Pocket)虽然强大,但往往存在两个痛点:
- 格式混乱:直接抓取网页 HTML 会带入大量广告、乱七八糟的 CSS 和无效链接。
- 排版不可控:导出的文件往往字体难看,无法满足"像读纸质书一样"的审美需求。
- 路径限制 :无法直接归档到本地特定的资源目录(如个人知识库的
uploads文件夹)。
C:\myApp\WebClipper
为了解决这些问题,我基于 Chrome Manifest V3 开发了一个轻量级的网页摘录助手。本文将深度分析其核心代码实现,特别是纯文本清洗 、手工构建 EPUB 以及 突破沙箱限制的文件保存 策略。
1. 核心架构设计
插件采用标准的 MV3 架构:
- Content Script: 负责在网页端"提纯"内容。
- Background: 负责上下文菜单(右键菜单)的消息中转。
- Popup: 核心逻辑所在,负责数据可视化、渲染排版、文件生成与下载。
- Storage : 使用
chrome.storage.local在不同页面间持久化暂存摘录列表。
2. 特色代码分析
2.1 数据源头:由繁入简的"降噪"处理
早期的版本尝试抓取 innerHTML,但网页的 DOM 结构过于复杂。最终方案改为只抓取纯文本,并在后期重新排版。
Content Script (content.js):
javascript
// 获取用户选区
const selection = window.getSelection();
// 核心:toString() 丢弃所有 HTML 标签,只保留文本
const text = selection.toString().trim();
if (text) {
sendResponse({
data: {
text: text,
title: document.title, // 保留来源标题
url: window.location.href // 保留来源链接
}
});
}分析 :
这一步看似简单,却是整个插件"排版美观"的基石。通过丢弃原始 CSS,我们获得了一个干净的数据源,为后续的"自定义 CSS 注入"提供了可能。
2.2 统一排版引擎:复刻"纸质书"质感
为了满足特定的审美(如宋体/衬线体混排、金色标题),插件在 popup.js 中定义了一套通用的 CSS 常量 READ_STYLE。这套样式被同时注入到 PDF 和 EPUB 的生成流程中,保证了体验的一致性。
Popup Logic (popup.js):
css
const READ_STYLE = `
body {
/* 核心:优先使用衬线体,营造沉浸式阅读感 */
font-family: "Georgia", "SimSun", "Songti SC", "Times New Roman", serif;
line-height: 1.8;
background-color: #ffffff;
}
/* 模仿实体书的标题配色:深金/土黄 */
.item-title {
font-size: 18px;
font-weight: bold;
color: #b8860b; /* DarkGoldenRod */
}
/* 自动首行缩进,这是中文排版的灵魂 */
.item-content p {
text-indent: 2em;
text-align: justify; /* 两端对齐 */
}
`;在生成 PDF 时,我们通过动态创建一个 DOM 容器,将这段 Style 注入进去,再调用 html2pdf.js 进行截图渲染。
2.3 硬核实现:手工构建 EPUB 文件结构
浏览器端生成 EPUB 通常很难找到完美的库。本插件选择使用 JSZip 手动构建 EPUB 的文件系统(因为 EPUB 本质就是特定结构的 ZIP 包)。
难点 1:流式排版 vs 分页
早期的实现是每条摘录存为一个 .xhtml 文件,导致阅读时强制分页。改进后的代码采用了单文件流式结构:
javascript
// 将所有摘录拼接为一个 HTML 字符串
let bodyContent = `<h1 class="doc-title">阅读汇编</h1>`;
data.forEach((item, index) => {
// 使用 escapeXml 防止特殊字符破坏 XML 结构
bodyContent += `
<div class="chapter-item">
<div class="item-title">${escapeXml(item.title)}</div>
<div class="item-content">${textToHtml(item.text)}</div>
</div>`;
});
// 生成 content.xhtml
oebps.file("content.xhtml", xhtmlTemplate(bodyContent));难点 2:XML 的严苛性 (escapeXml)
EPUB 基于 XHTML,对语法要求极严。如果文本中包含 & 或 <,会导致阅读器报错。必须进行转义处理:
javascript
function escapeXml(unsafe) {
if (!unsafe) return "";
return unsafe.replace(/[<>&'"]/g, c => {
switch (c) {
case '<': return '<';
case '>': return '>';
case '&': return '&';
// ...
}
});
}这段代码虽然基础,但却是 EPUB 导出功能稳定运行的关键。
2.4 突破沙箱:如何"保存到 C 盘"
Chrome 插件最令人头疼的限制是 chrome.downloads API 禁止写入用户默认下载目录以外的绝对路径(例如 C:\myApp\uploads)。
解决方案:强制触发"另存为"
我们在代码中巧妙地利用了 saveAs 参数:
javascript
function triggerDownload(blobUrl, filename) {
// 强制 saveAs: true
const useSaveAs = true;
chrome.downloads.download({
url: blobUrl,
filename: filename, // 这里只能指定文件名,不能指定路径
saveAs: useSaveAs, // 关键:触发系统原生弹窗
conflictAction: 'uniquify'
});
}UX 权衡分析 :
虽然代码无法自动后台写入特定路径,但通过勾选"总是显示另存为",用户在第一次选择目标文件夹(如 C:\myApp\...)后,Chrome 通常会记忆该位置。这在安全性(浏览器限制)和灵活性(用户需求)之间找到了最佳平衡点。
3. 运行界面
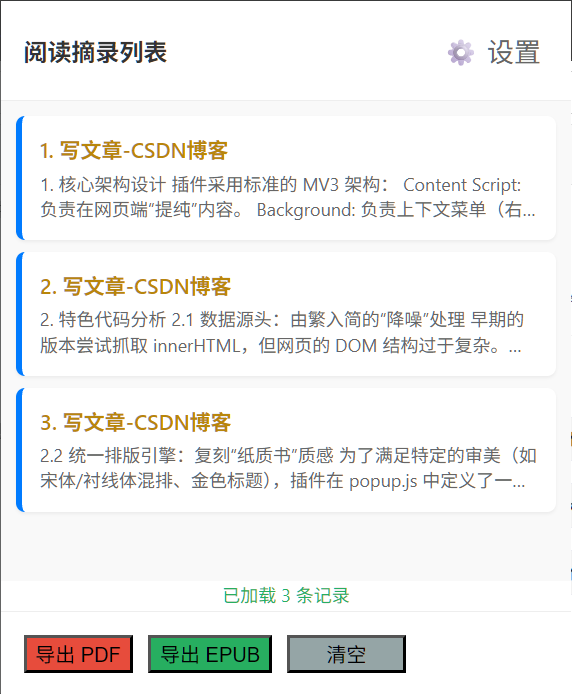
路径设置
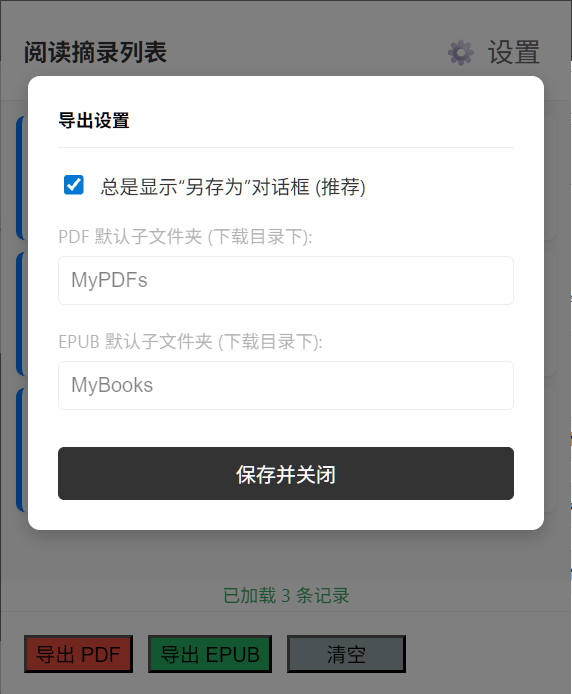
导出效果
