1。pyspark是什么
PySpark 是 Apache Spark 的官方 Python 接口,它使得 Python 开发者能够访问 Spark 的核心功能,如:
Spark SQL :用于执行 SQL 查询以及读取数据的库,支持多种数据格式和存储系统。py.qizhen.xyz
DataFrame API :提供了一个分布式数据集合,使得数据处理和分析更加直观和高效。py.qizhen.xyz+1CSDN 博客+1
MLlib :用于进行机器学习的库。py.qizhen.xyz+1维基百科+1
GraphX :用于图形处理的库(在 PySpark 中通过第三方库如 GraphFrames 访问)。py.qizhen.xyz
Spark Streaming :用于实时数据流处理的库。py.qizhen.xyz
通过 PySpark,Python 开发者可以方便地进行大规模数据分析和数据挖掘工作,而无需深入了解分布式计算的复杂性。
2.实战
创建和管理 Spark 会话所需的类
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
#从 pyspark.sql.functions 模块中导入所有函数,并将其简写为 F
from pyspark.sql.types import *
#从 pyspark.sql.types 模块中导入所有的数据类型类。
from pyspark.sql.functions import udf
#使用 PySpark 创建和注册用户定义函数的第一步,允许将自定义的 Python 函数应用于 Spark 的数据处理流程中
spark = SparkSession.builder.appName('data_processing').getOrCreate()
#创建或获取一个 SparkSession 实例
schema = StructType().add('user_id',"string").add("country","string").add("browser","string").add("OS","string").add("age","integer")
#创建的 DataFrame 将具有预定义的列名和数据类型,有助于确保数据一致性和便于后续的数据处理操作
df_custom = spark.createDataFrame([("A203",'India',"Chrome","WIN",33),("A201",'China',"Safari","MacOS",35),("A205",'UK',"Mozilla","Linux",25)],schema = schema)
#这行代码使用 PySpark 创建了一个带有指定模式(schema)的 DataFrame。
df_custom.printSchema()
#用于以可读的层次结构格式展示 DataFrame 的结构信息。
df_custom.show()
#将 DataFrame 的前几行数据显示在控制台上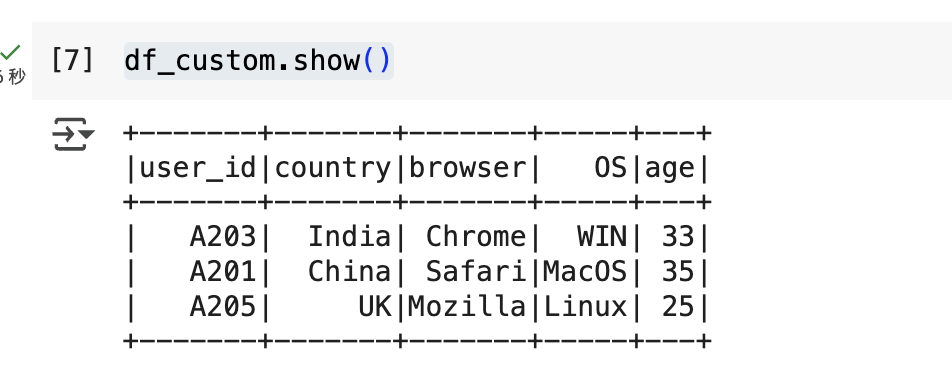
df_na=spark.createDataFrame([("A203",None,"Chrome","WIN",33),("A201",'China',None,"MacOS",35),("A205",'UK',"Mozilla","Linux",25)],schema=schema)
#使用指定的模式(schema)创建一个包含部分缺失值(None)的 DataFrame。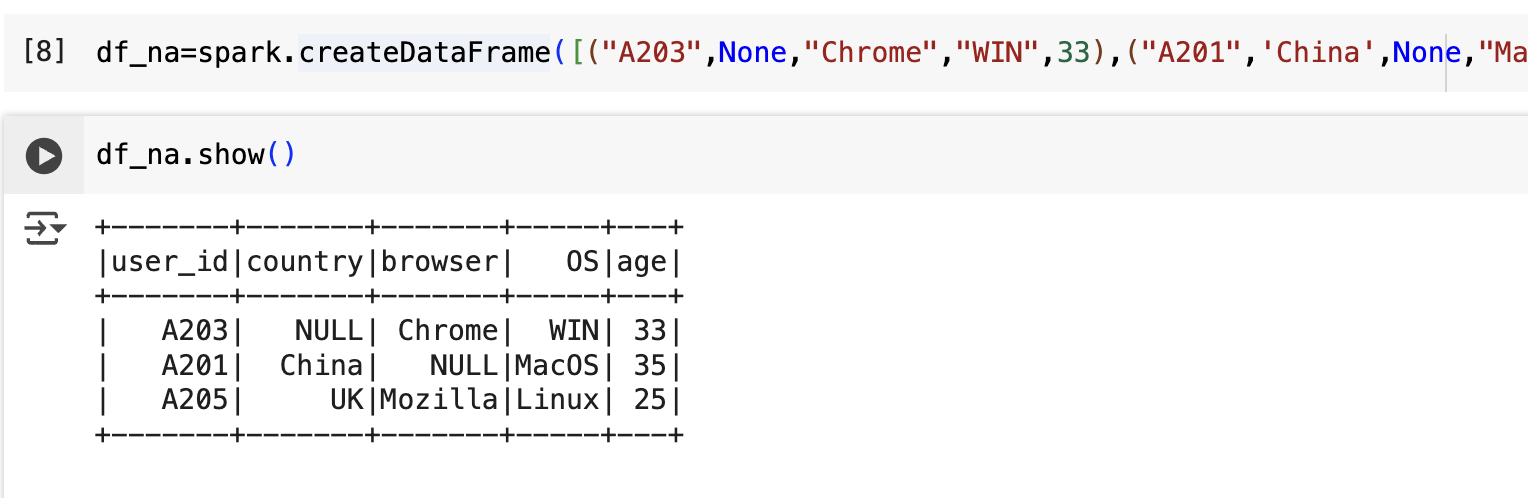
df_na.fillna('0').show()
#将 DataFrame df_na 中所有列的缺失值(null 或 None)替换为字符串 '0',然后以表格形式在控制台上显示前 20 行数据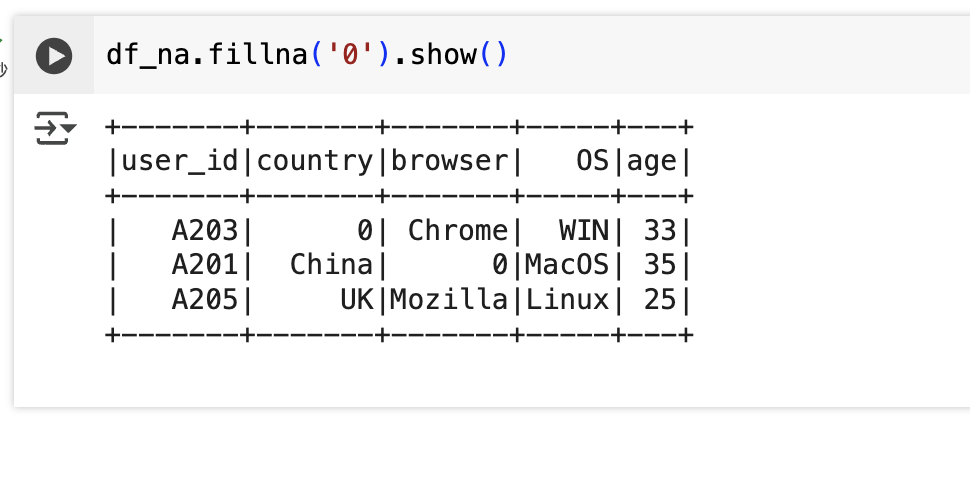
df_na.fillna({'country':'USA','browser':'Google Chrome'}).show()
#使用 fillna() 方法,将 DataFrame df_na 中 country 列的缺失值替换为 'USA',browser 列的缺失值替换为 'Google Chrome'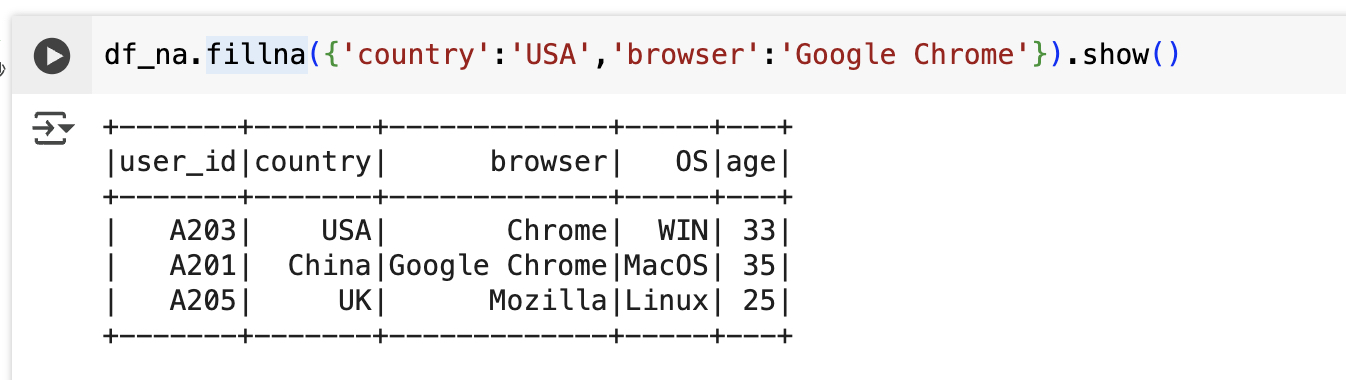
df_na.na.drop().show()
#删除包含缺失值的行:df_na.na.drop() 会从 DataFrame df_na 中删除任何包含 null(或 None)值的行。默认情况下,drop() 方法会移除任何列中存在缺失值的行。
df_na.na.drop(subset='country').show()
#删除特定列中包含缺失值的行:df_na.na.drop(subset='country') 会从 DataFrame df_na 中删除 country 列中包含 null 或 None 值的行。对csv文件进行处理
df = spark.read.csv("customer_data.csv",header = True, inferSchema=True)
#读取名为 customer_data.csv 的 CSV 文件,并将其加载为 DataFrame
df.count()
查看数量
len(df.columns)
#查看列数
df.columns
#查看列名
df.filter(df['Avg_Salary']>500000).filter(df['Number_of_houses']>2).show()
#筛选
df.where((df['Avg_Salary']>500000)&(df['Number_of_houses']>2)).show()
#where() 是 PySpark DataFrame 的方法,用于根据指定的条件筛选行。它是 filter() 方法的别名,两者功能相同
df.groupBy('Customer_subtype').count().show()
#按客户子类型分组并统计每组数量的常用方法,有助于了解不同客户子类型的分布情况。
for col in df.columns:
if col!='Avg_Salary':
print(f" Aggregation for {col}")
df.groupBy(col).count().orderBy('count',ascending=False).show(truncate=False)
#对 DataFrame df 中除 'Avg_Salary' 列以外的每一列进行分组计数,并按计数降序显示结果。
df.groupBy('Customer_main_type').agg(F.mean('Avg_Salary')).show()
#对 DataFrame df 按照 Customer_main_type 列进行分组,并计算每个主类型的平均薪资:
df.groupBy('Customer_main_type').agg(F.max('Avg_Salary')).orderBy('max(Avg_Salary)',ascending=False).show()
#用于对 DataFrame df 按照 Customer_main_type 列进行分组,并计算每个主类型的最高平均薪资,然后按降序排列结果
df.groupBy('Customer_subtype').agg(F.max('Avg_Salary').alias('max_salary')).orderBy('max_salary',ascending=False).show()
#在 PySpark 中,以下代码用于对 DataFrame df 按照 Customer_subtype 列进行分组,并计算每个子类型的最高平均薪资,然后按降序排列结果
df.groupBy("Customer_subtype").agg(F.collect_set("Number_of_houses")).show()
#是在 PySpark 中用于按客户子类型分组并收集每组房屋数量的唯一值的常用方法,有助于了解不同客户子类型的房屋数量分布情况。1. 初始化与数据创建
使用
SparkSession.builder.getOrCreate()初始化 Spark 环境。使用
StructType明确定义 schema。用
spark.createDataFrame()构造了两个 DataFrame(一个有缺失值)。2. DataFrame 基本操作
.printSchema():打印 schema 信息。
.show():展示数据内容。
.fillna():填充缺失值。
.na.drop()/.na.drop(subset=...):删除缺失值行。
.replace():替换字段值。
.drop():删除某一列。3. CSV 文件读取
spark.read.csv(..., header=True, inferSchema=True)读取并自动推断数据类型。4. 基础探索与过滤
.count()/len(df.columns)/df.columns:了解数据结构。
.summary().show():生成描述性统计。
.filter()/.where():条件筛选数据。
.select():选择列。5. 分组与聚合操作
.groupBy(...).count():分组计数。
.groupBy(...).agg(F.mean(...)):分组平均值。
.groupBy(...).agg(F.max(...)):分组最大值。
.agg(F.collect_set(...)):收集唯一值列表。
.orderBy(...):排序显示。6. 列操作
.withColumn("new_col", F.lit(...)):添加常量列。
.withColumn("new_col", udf(col)):使用自定义 UDF 添加新列。7. UDF / Pandas UDF
使用标准
udf()创建 age 分类函数。使用
pandas_udf()实现归一化薪资计算(注释掉了实际调用)。