SmolVLM2轻量级视频多模态模型,应用效果测评
目 录
-
前言... 2
-
应用部署... 2
-
应用效果... 4
1.1 风景图像理解... 4
1.2 事故现场理解... 5
1.3 仿真图像理解... 6
1.4 数量统计描述... 7
1.5 图像文字理解... 8
1.6 物体识别理解... 10
-
待解决问题... 11
-
结论... 11
1. 前言
SmolVLM2 是由 Hugging Face 开发的一系列紧凑型但功能强大的大型模型,旨在为资源受限的设备(如智能手机和嵌入式系统)带来先进的语言和视觉语言处理能力。这些模型以其小型化设计著称,适合在设备上运行,填补了大型模型与小型设备性能差距的空白。本文将详细介绍这两个系列的背景、技术细节、性能和应用,旨在为研究者和开发者提供全面的理解。
SmolVLM2 扩展了 Smol 系列的能力,专注于视觉语言任务,可处理视频、图像和文本输入,生成文本输出。模型提供三种参数规模:2.2B、500M 和 256M,旨在实现高效的多模态处理。相较于前代产品,新版 22 亿模型在图像数学解题、图片文字识别、复杂图表解析和科学视觉问答方面表现显著提升。
2. 应用部署
模型下载:HuggingFaceTB/SmolVLM2-2.2B-Instruct · Hugging Face。
from transformers import AutoProcessor, AutoModelForImageTextToText
import torch
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
print(DEVICE)
model_path = "models/SmolVLM2-2.2B-Instruct"
processor = AutoProcessor.from_pretrained(model_path)
model = AutoModelForImageTextToText.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2" if DEVICE == "cuda" else "eager",
device_map="cuda").to(DEVICE)
#model = AutoModelForImageTextToText.from_pretrained(
# model_path,
# torch_dtype=torch.bfloat16,
# _attn_implementation="flash_attention_2" if DEVICE == "cuda" else "eager").to(DEVICE)
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "5.png"},
{"type": "text", "text": "结合图像上的内容,请问简单iNeuOS是什么?"},
]
},
]
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device, dtype=torch.bfloat16)
generated_ids = model.generate(**inputs, do_sample=False, max_new_tokens=5000)
generated_texts = processor.batch_decode(
generated_ids,
skip_special_tokens=True,
)
print(generated_texts[0])3. 应用效果
1.1 风景图像理解
User:请描述这张图像?
Assistant: 这张图片是一张美丽的花朵照片,其中主要的是一棵树的枝条和花朵。树枝的颜色是深红色,而花朵的颜色是白色和红色。树枝上有一层雪,雪的颜色是白色,这使得树枝和花朵的颜色显得更加美丽。花朵的颜色是红色和白色,这使得花朵的颜色显得更加独特。这张图片的背景是白色的,这使得树枝和花朵的颜色更加显得突出。这张图片的风格是美丽和美感的,它让人感受到花朵的美丽和树枝的美丽。
1.2 事故现场理解
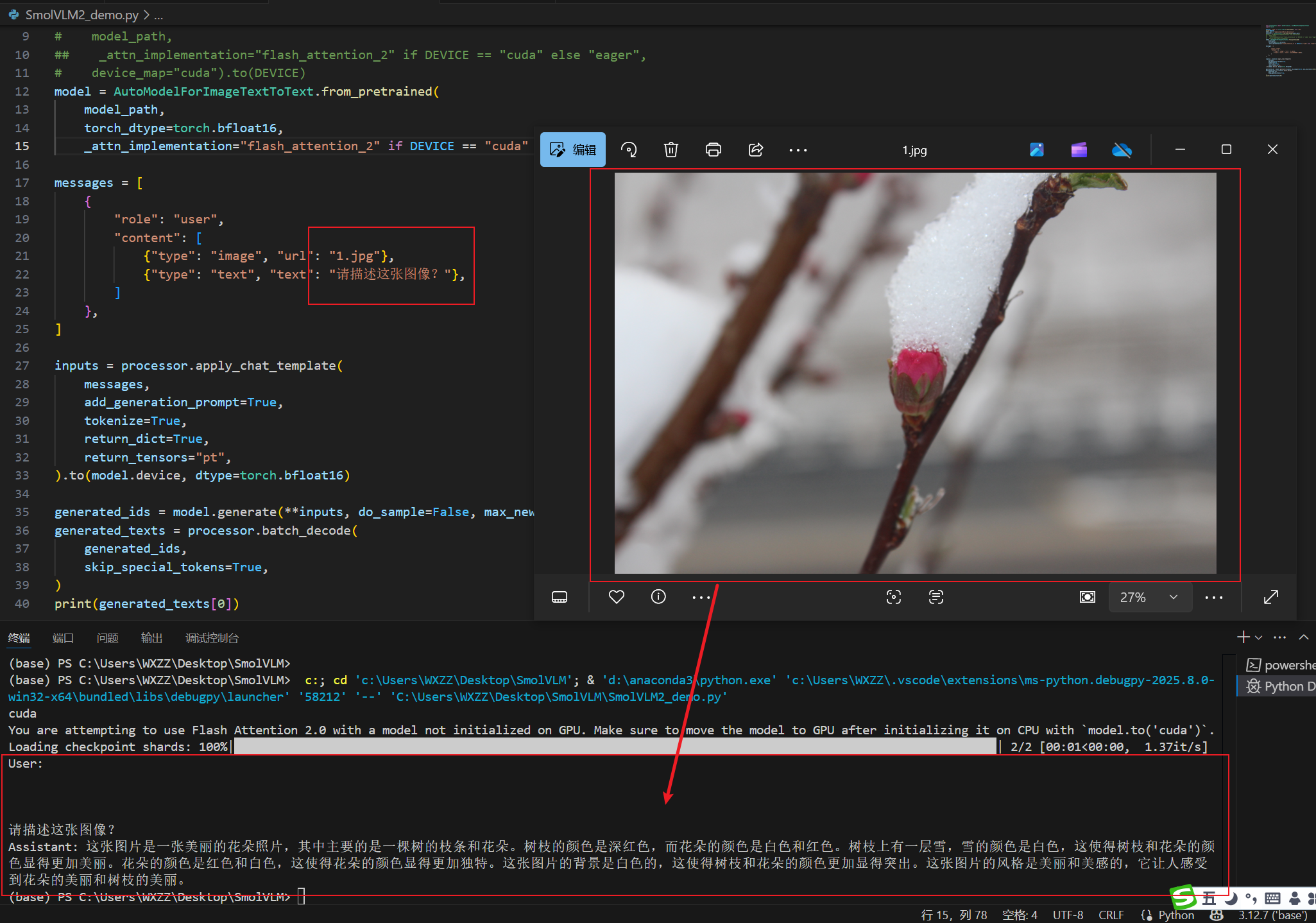
User:请描述这个事故现场?
Assistant: 这是一次火灾事故的事实场景,其中包含一个大型的炉子和一个高的柱子。炉子的外壁是灰色的,而柱子的外壁是黑色的。(注:后面有冗余的回复)
1.3 仿真图像理解
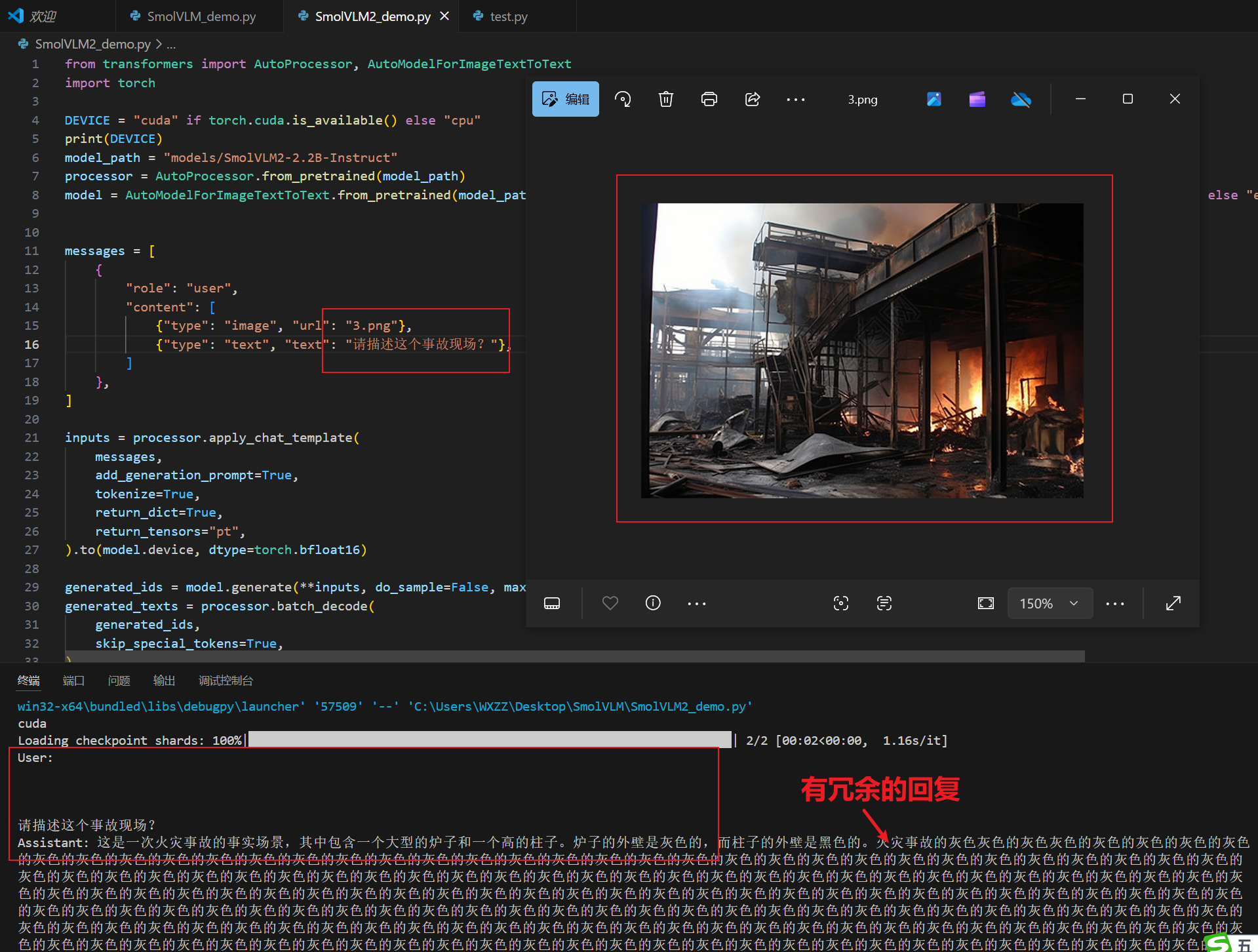
User:这是温度场仿真,请描述温度变化趋势?
Assistant: 温度变化趋势可以从图像中看出,温度在右侧高于左侧,这表明右侧的温度更高,左侧的温度更低。(注:后面有冗余和重复数据)
1.4 数量统计描述
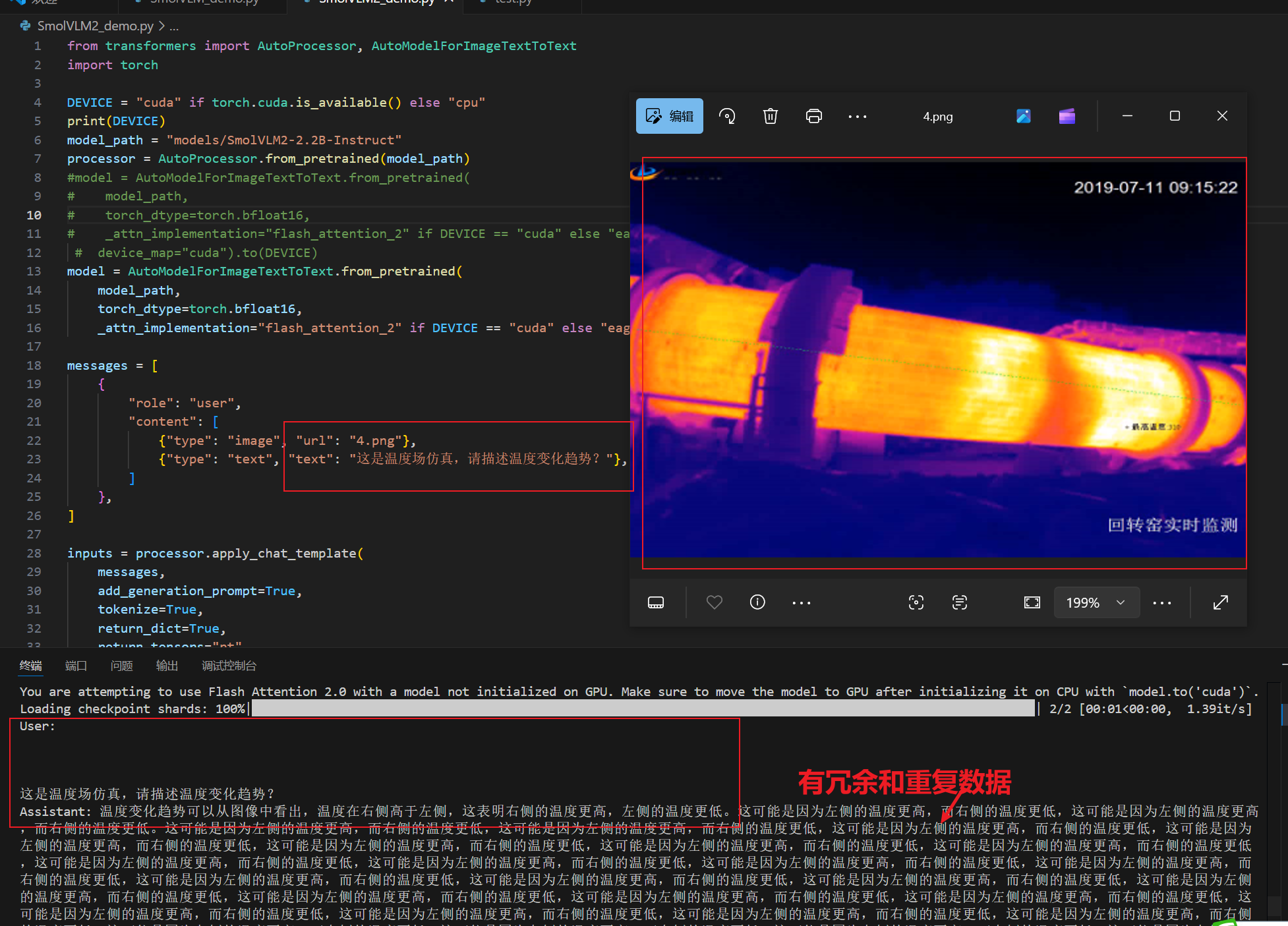
User:这是虾苗养殖图像,请分析虾苗数量?
Assistant: 虾苗数量为1000多个。
1.5 图像文字理解
User:结合图像上的内容,请问简单iNeuOS是什么?
Assistant: iNeuOS是一种操作系统,它是一种高级的操作系统,它可以被用来管理和管理计算机的系统,包括内存、硬盘和网络等。(注:后面是冗余和重复的数据)
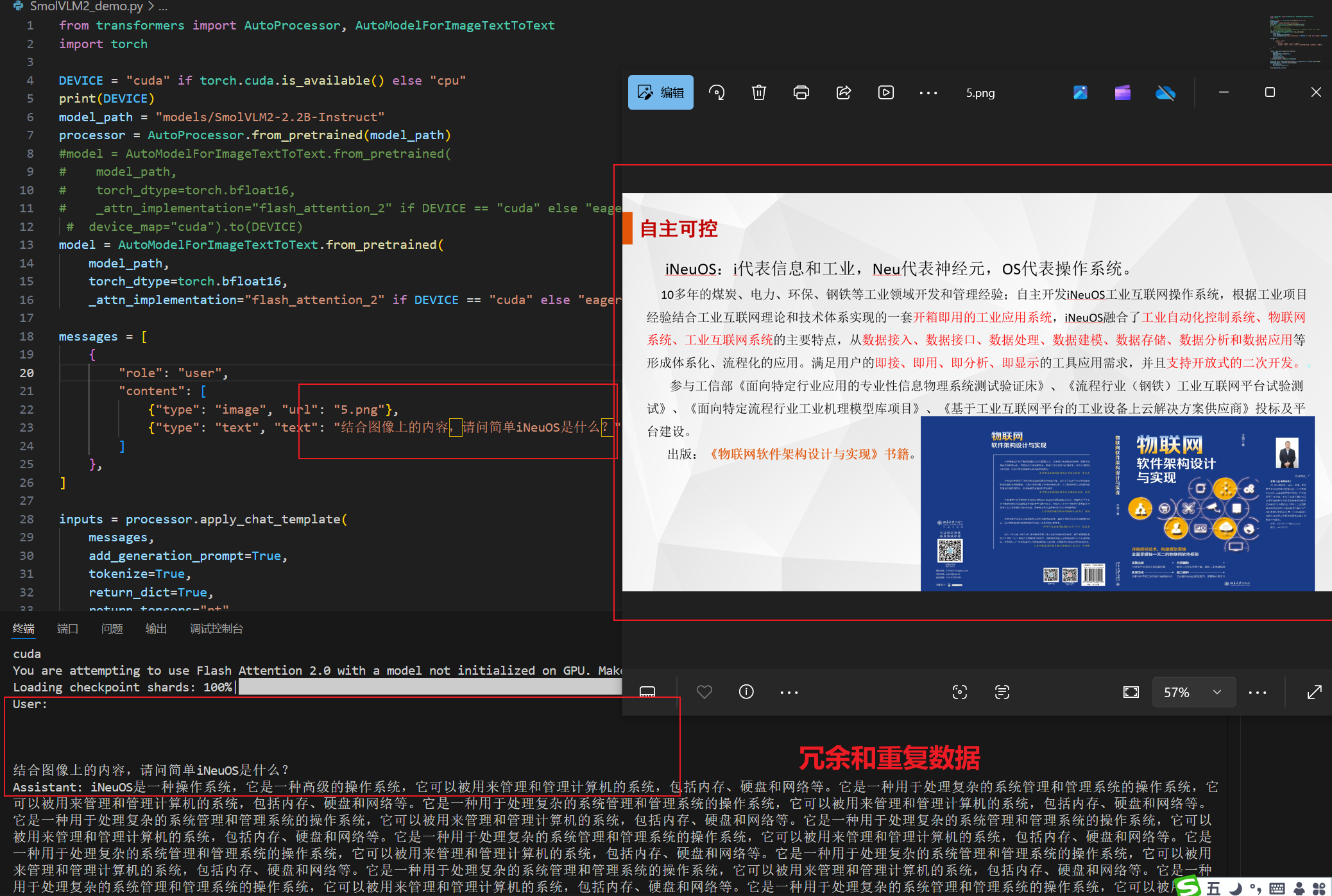
User:图像上的文字是什么?
Assistant: 这是一个英文和中文的图像,其中包含一些文字和图片。图像的左侧有一些英文文字,包括"iNeuOS"、"OS"和"NeuOS"。(注:毕竟不是 OCR ,所以文字识别和提取有限)
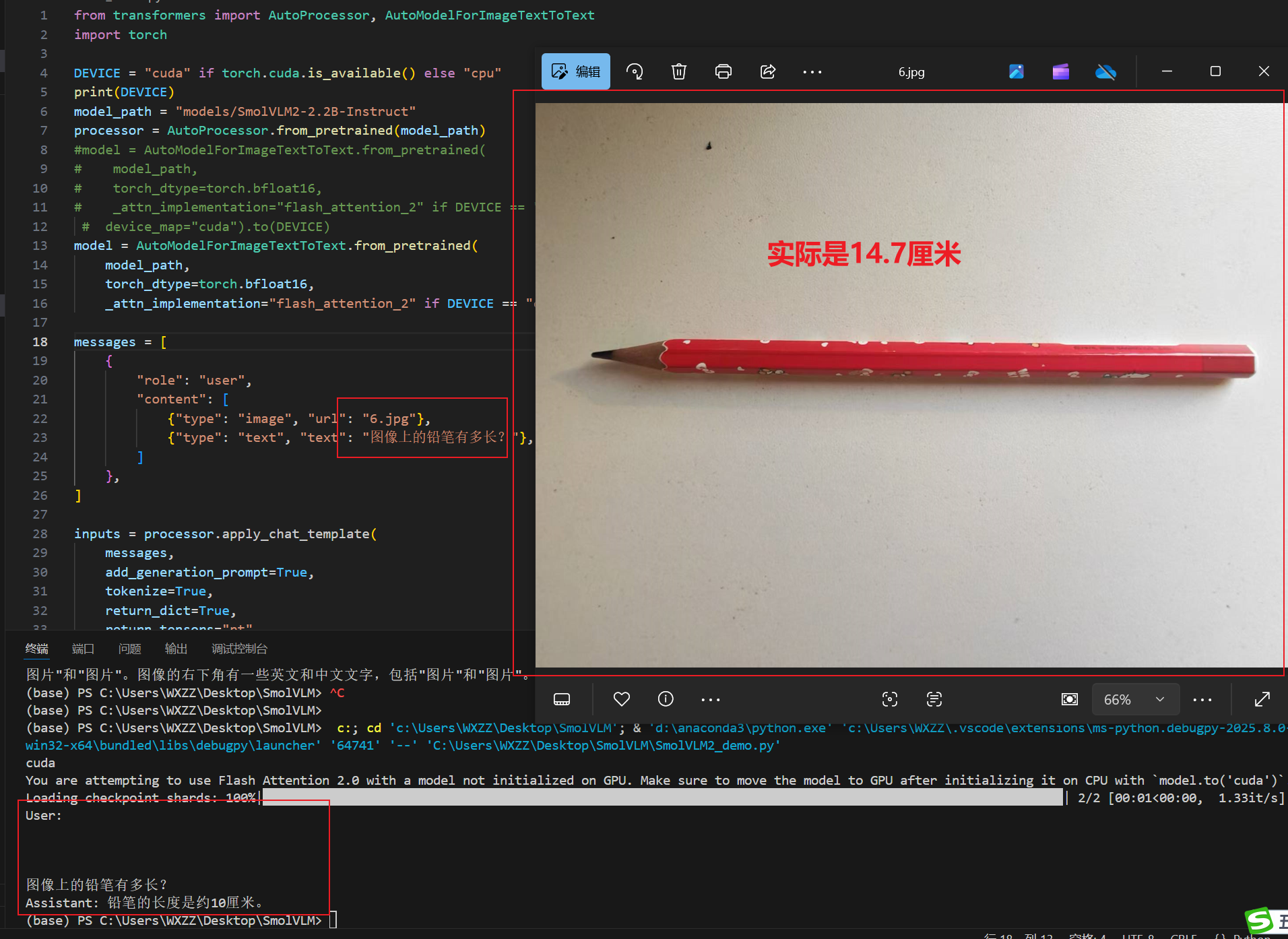
1.6 物体识别理解
User:图像上的铅笔有多长?
Assistant: 铅笔的长度是约10厘米。(注:实际长度为 14.7 厘米)
4. 待解决问题
问题:模型在回复的时候有冗余和重复的内容。
可能的原因:(1)提示词需求进行优化;(2)程序参数设置的问题。暂时还没有进一步测试。
5. 结论
测试比我预想的要好很多,但是针对特定应用场景,特别是工业领域,需要进一步调优。
物联网&大数据技术 QQ群:54256083
物联网&大数据项目 QQ群:727664080
QQ:504547114
微信:wxzz0151
博客:https://www.cnblogs.com/lsjwq
