目录
摘要:分享JAVA JUC线程池干货,首先描述线程池的基本概念,然后介绍线程工厂和拒绝策略,其次逐步深入线程池实现原理和线程池状态机,最后结合实战讲解源码。
JUC干货系列目录:
-
JAVA JUC干货之线程池实现原理和源码详解
综述
世界唯一不变的事,就是世界一直在变,而且是瞬息万变,唯有不断学习、持续创新和迎接变化,才能立于不败之地。一位金融公司的CTO曾经问我"为什么使用线程池?线程池是怎样执行任务的?"我由于对这个知识点掌握的不透彻,只能临场发挥,导致结局尴尬。因此亡羊补牢,当天到家后就梳理了这个知识点,现在结合Java 21线程池源码落地到文档,分享一些关于线程池的干货,包括但不限于基本概念、执行流程、使用方法、最佳实践和大厂八股文。
我们下面认识一下什么是线程池。线程池从字面意思上来看就是一个基于池化技术管理同一组工作线程的池子,基本概念如下:是一种用于管理线程生命周期和任务执行的工具,它通过复用已有的工作线程,避免频繁创建和销毁工作线程的开销,从而显著提高应用程序的响应速度和吞吐量,提升资源利用率。通常,我们会使用 java.util.concurrent.ThreadPoolExecutor 或者 Spring 提供的 ThreadPoolExecutor 来创建和管理线程池。
Java在使用线程执行程序时,需要调用操作系统内核的API创建一个内核线程,操作系统要为线程分配一系列的系统资源;当该Java线程被终止时,对应的内核线程也会被回收。因此,频繁的创建和销毁线程需要消耗大量资源。此外,由于CPU核数有限,大量的线程上下文切换会增加系统的性能开销,无限制地创建线程还可能导致内存溢出。为此,Java在JDK1.5版本中引入了线程池。
在项目开发过程中为什么使用线程池?我们先看看的ThreadPoolExecutor类中英文注释是怎么描述的:
java
Thread pools address two different problems: they usually provide improved performance when executing large numbers of asynchronous tasks,
due to reduced per-task invocation overhead, and they provide a means of bounding and managing the resources,
including threads, consumed when executing a collection of tasks. Each {@code ThreadPoolExecutor} also maintains some basic statistics,
such as the number of completed tasks.中文意思大致就是线程池解决了两个不同的问题:在执行大量异步任务时,它们一般通过复用线程降低每个任务的调用开销来提高性能,同时线程池还提供了一种限制和管理执行任务时所消耗资源(包括线程)的方法。每个 {@code ThreadPoolExecutor} 还会维护一些基本的统计信息,例如已完成的任务数量。简而言之,线程池能够对线程进行统一分配、调优和监控:
- 通过线程复用机制降低资源开销。线程池维护了一个线程集合,尽可能复用线程完成不同的任务,避免了反反复复地创建和销毁线程带来的系统资源开销。
- 更有效的管理系统资源。使用线程池统一管理和监控系统资源,做到根据系统承载能力限制同时运行的线程数量,防止系统因创建过多线程而耗尽资源。还支持动态调整核心线程数。
- 提高响应速度。由于线程被提前预热,当有任务到达时立即被执行,因此显著减少了创建线程这段时间的开销,从而提高了系统的响应速度。据统计,创建一个线程大约耗时90微秒并占用1M内存。
鉴于以上线程池优势,合理使用线程池可以帮助我们构建更加高效、稳定和易于维护的多线程应用程序。在业务系统开发过程中,线程池的两个常见应用场景分别是快速响应用户请求和高效处理批量任务。本文将全方位深入探讨 Java 线程池,帮助读者掌握线程池使用技巧和精通其原理。线程池源码参考Java 21,具体版本是"21.0.6"。
七个核心参数
什么是任务执行器?它是实际执行任务的组件,包括执行任务的核心接口类 Executor和继承了 Executor 的 ExecutorService 接口。Executor 框架有几个关键类实现了 ExecutorService 接口:ThreadPoolExecutor 和 ScheduledThreadPoolExecutor、ForkJoinPool。Executor定义了一个简单的 execute(Runnable command) 方法用于异步执行任务;而ExecutorService 接口继承自 Executor,添加了更丰富的任务提交和生命周期管理轮子,如 submit(Runnable task)、submit(Callable task) 、isTerminated()、shutdown() 等。
楼兰胡杨在分析JUC线程池Executor框架体系时发现线程池的核心实现类是ThreadPoolExecutor,它是 Executor 框架中最重要的任务执行器实现,实现了 ExecutorService 接口。提供了一个可配置的线程池,用于执行异步任务。
正所谓"先穿袜子后穿鞋,先当孙子后当爷",如果要深入理解Java并发编程中的线程池,那么必须深入理解这个类的构造函数。我们来看一下ThreadPoolExecutor类中四个构造函数的源码:
java
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), handler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
// 设置线程容器名称
String name = Objects.toIdentityString(this);
// 创建线程容器,这就是线程池本尊,线程池的说法也是因为这个线程容器
this.container = SharedThreadContainer.create(name);
}SharedThreadContainer 是从 JDK 21 开始引入到源码中的类,目的是支持进一步优化虚拟线程,用于管理共享线程容器。从源码得知,ThreadPoolExecutor类提供了四个构造函数,事实上,前面三个构造器都是由第四个构造器衍生而来。下面基于入参最全的第四个构造函数解释线程池中的七大核心参数。
| 核心参数 | 业务含义 |
|---|---|
| int corePoolSize | 核心线程数 |
| int maximumPoolSize | 允许创建的最大线程数 |
| long keepAliveTime | 空闲时间,即空闲线程在终止之前等待新任务的最长时间 |
| TimeUnit unit | keepAliveTime的时间单位 |
| BlockingQueue workQueue | 任务队列 |
| ThreadFactory threadFactory | 线程工厂 |
| RejectedExecutionHandler handler | 拒绝策略 |
下面对上述七大核心参数逐一详细介绍。
corePoolSize:线程池中核心线程(常驻线程)的个数。
线程池被创建后,默认情况下其中并没有任何线程,而是等待有任务到来才创建线程去执行当前任务。如果调用了 prestartAllCoreThreads() 或者 prestartCoreThread()方法,那么可以预创建线程,即在没有任务到来之前就创建corePoolSize个或者一个线程。
关于corePoolSize的值,如果设置的比较小,则会频繁的创建和销毁线程;如果设置的比较大,则浪费系统资源,实际工作中需要根据业务场景调整。如果设置corePoolSize为 0,则表示在没有任务的时候,销毁线程池。
maximumPoolSize :线程池最大线程数,表示在线程池中最多允许创建多少个线程。它表示当核心线程已满且任务队列也满时,线程池可以创建线程的最大个数。通常情况下,无界阻塞队列可以视为无底洞,无论放入多少任务都填不满,故maximumPoolSize对于使用了无界队列的线程池而言就是花瓶,中看不中用。
keepAliveTime:线程的空闲时间或者存活时间,即当线程游手好闲没有任务执行时,继续存活的时间。
线程池的核心线程可以被回收吗?ThreadPoolExecutor默认不回收核心线程,即 keepAliveTime 对它不起作用。但是提供了allowCoreThreadTimeOut(boolean value)方法,当传的参数为true时,可以在无事可做时间达到线程存活时间后,回收核心线程,直到线程池中的线程数为0。
unit:参数keepAliveTime的时间单位,默认值为TimeUnit.MILLISECONDS,对应TimeUnit类中的7种静态属性:
java
TimeUnit.DAYS; //天
TimeUnit.HOURS; //小时
TimeUnit.MINUTES; //分钟
TimeUnit.SECONDS; //秒
TimeUnit.MILLISECONDS; //毫秒,默认值
TimeUnit.MICROSECONDS; //微妙
TimeUnit.NANOSECONDS; //纳秒workQueue:任务队列,采用阻塞队列临时存储等待执行的任务,会对线程池的运行过程产生重大影响。
当核心线程全部繁忙时,新提交的任务将存放在任务队列中,等待被空闲线程执行。在ThreadPoolExecutor线程池的API文档中,一共推荐了三种等待队列,它们分别是ArrayBlockingQueue、synchronousQueue和默认的LinkedBlockingQueue等。
threadFactory:线程工厂,主要用来创建线程。默认线程工厂是DefaultThreadFactory。
handler:饱和策略,又称拒绝策略,默认值为AbortPolicy。
线程工厂
线程工厂有哪些作用? 负责生产线程去执行任务,通过线程工厂可以设置线程池中线程的属性,包括名称、优先级以及daemon类型等内容。同一个线程工厂创建的线程会归属于同一个线程组,拥有一样的优先级,而且都不是守护线程。通过自定义的线程工厂可以给每个新建的线程设置一个具有业务含义、易于识别的线程名。
线程优先级的作用是什么? 线程优先级用整数表示,取值范围在 1-10 之间,默认优先级为 5。优先级表示当前线程被调度的权重,也就是说线程的优先级越高,被调度执行的可能性就越大。它会给线程调度器一个择优执行线程的建议,至于是不是优先级越高的越先执行存在不确定性。它这样设计的目的就是为了防止线程饿死。
例1 通过引入com.google.guava包创建线程工厂。
java
import com.google.common.util.concurrent.ThreadFactoryBuilder;
// %d 表示从0开始增长的自然数
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder().setNameFormat("demo-pool-%d").build();例2 通过Java原汁原味的JUC包ThreadFactory创建线程工厂。
java
// 自定义线程工厂
ThreadFactory jucFactory = new ThreadFactory() {
private final AtomicInteger mThreadNum = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
// 为线程池创建线程
Thread thread = new Thread(r);
// 设置线程名称
thread.setName("Wiener-" + mThreadNum.getAndIncrement());
// 设置线程优先级
thread.setPriority(Thread.MAX_PRIORITY);
// 设置线程类型 (前台/后台线程)
thread.setDaemon(false);
return thread;
}
};拒绝策略
假设线程数达到最大线程数maximumPoolSize且任务队列已满,如果继续提交新任务,那么线程池必须采取一种拒绝策略处理该任务,在ThreadPoolExecutor中预定义了4种拒绝策略,下面结合源码介绍。
AbortPolicy
ThreadPoolExecutor.AbortPolicy会拒绝执行任务并直接抛出RejectedExecutionException异常,是线程池的默认拒绝策略。源码如下:
java
/**
* A handler for rejected tasks that throws a
* {@link RejectedExecutionException}.
*
* This is the default handler for {@link ThreadPoolExecutor} and
* {@link ScheduledThreadPoolExecutor}.
*/
public static class AbortPolicy implements RejectedExecutionHandler {
/**
* Creates an {@code AbortPolicy}.
*/
public AbortPolicy() { }
/**
* Always throws RejectedExecutionException.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
* @throws RejectedExecutionException always
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
// 直接抛出RejectedExecutionException
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}CallerRunsPolicy
ThreadPoolExecutor.CallerRunsPolicy 由调用者所在的线程来执行新任务,而不是线程池中的线程执行。如果调用者线程已关闭,则抛弃任务。这种机制间接地对任务生产速率进行限流,有助于防止系统过载,同时确保没有任务被粗暴地丢弃。
java
/**
* A handler for rejected tasks that runs the rejected task
* directly in the calling thread of the {@code execute} method,
* unless the executor has been shut down, in which case the task
* is discarded.
*/
public static class CallerRunsPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code CallerRunsPolicy}.
*/
public CallerRunsPolicy() { }
/**
* Executes task r in the caller's thread, unless the executor
* has been shut down, in which case the task is discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run(); // 直接由调用者线程执行任务【r】,而不是线程池中的线程执行
}
}
}DiscardOldestPolicy
ThreadPoolExecutor.DiscardOldestPolicy丢弃阻塞队列中最靠前的任务,然后尝试执行新任务。
ThreadPoolExecutor.DiscardOldestPolicy先将阻塞队列中的头元素出队抛弃,再尝试提交任务。如果此时阻塞队列使用PriorityBlockingQueue优先级队列,将会导致最高优先级的任务被抛弃,因此不建议将该种策略配合优先级队列使用。
DiscardPolicy
ThreadPoolExecutor.DiscardPolicy直接丢弃任务,但是不抛出异常。源码如下:
java
/**
* A handler for rejected tasks that silently discards the
* rejected task.
*/
public static class DiscardPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardPolicy}.
*/
public DiscardPolicy() { }
/**
* Does nothing, which has the effect of discarding task r.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}自定义拒绝策略
我们也可以根据业务场景实现RejectedExecutionHandler中函数rejectedExecution,创建我们自己的饱和策略,如记录日志或持久化存储不能处理的任务。
下面是一个简单的例子,展示如何实现一个自定义的拒绝策略。这个策略会在任务被拒绝时打印一条消息,并记录被拒绝的任务信息,同时支持把此任务持久化到Redis。
java
public class RejectionImpl implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 这里写我们自定义的拒绝策略
System.out.println("被拒绝任务是 " + r.toString());
System.out.println("把此任务持久化到Redis");
}
}在创建线程池的时候,把 new RejectionImpl() 传入即可,下文会给出实战案例。自定义拒绝策略通常可以做两件事:
- 记录日志,以便追溯问题。
- 通知告警,摇相关人员解决问题。
面试官:你在实际工作中/项目中,使用的是哪一种拒绝策略?
参考答案:如果不知道怎么回答,建议回答自定义拒绝策略,因为它比较灵活,可以设置想设置的逻辑,我在里面呢,首先可以把错误记录下来,其次可以给任务队列发一个邮件,或者发一个 MQ(消息不丢失)。
面试官:如果不允许丢弃任务,应该选择哪种拒绝策略?
参考答案:如果不担心阻塞主线程,可以选择CallerRunsPolicy。更丝滑的方案是基于任务持久化自定义拒绝策略,持久化方案包括但不限于:
- 把任务存储到Redis中。
- 把任务存储到 MySQL 数据库中。
- 把任务提交到消息队列中。
这里以方案一为例,简单介绍一下实现逻辑:
步骤一 使用前面刚刚自定义的拒绝策略RejectionImpl,将线程池需要拒绝处理的任务持久化到Redis中。
步骤二 扩展LinkedBlockingQueue实现一个自定义阻塞队列。重写取任务的逻辑take()或者poll()方法,优先从Redis中读取最早存储的任务,Redis中无任务时再从线程池阻塞队列中取任务。
java
import java.util.concurrent.LinkedBlockingQueue;
/**
* @Author Wiener
* @Date 2025-04-17
* @Description: 自定义阻塞队列
*/
public class CustomBlockingQueue<E> extends LinkedBlockingQueue<E> {
@Override
public E take() throws InterruptedException {
E x;
if (redis中有任务?) {
// 从Redis读取最早放入的任务
} else {
// 从阻塞队列拿任务
x = super.take();
}
// 返回拿到的任务
return x;
}
}监控线程池运行状态
可以使用ThreadPoolExecutor以下方法实时监控线程池运行状态:
getTaskCount() Returns the approximate total number of tasks that have ever been scheduled for execution.
getCompletedTaskCount() Returns the approximate total number of tasks that have completed execution. 返回结果少于getTaskCount()。
getLargestPoolSize() Returns the largest number of threads that have ever simultaneously been in the pool. 返回结果小于等于maximumPoolSize
getPoolSize() Returns the current number of threads in the pool.
getActiveCount() Returns the approximate number of threads that are actively executing tasks.#
关闭和动态调整线程池|done
在应用程序结束时,要确保线程池能够被优雅地关闭。ThreadPoolExecutor提供了两个关闭线程池的轮子:
shutdown(): 等所有阻塞队列中的任务都执行完后才关闭线程池,但再也不会接收新的任务。
shutdownNow(): 立即尝试打断正在执行的任务,并且清空阻塞队列,返回尚未执行的任务。
它们的原理都是遍历线程池的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法被停止。
二者区别:shutdown函数将平缓的执行关闭过程,拒绝新提交的任务,完成所有运行中的任务,同时等待任务队列中的任务执行完成。shutdownNow方法将粗暴的执行关闭过程,它将尝试取消所有运行中的任务,并且无脑式地清空任务队列。
只要调用了这两个关闭方法中的任意一个,isShutdown函数就会返回true,当所有的任务都已关闭后,才表示线程池关闭成功,这时调用isTerminated方法会返回true。至于应该调用哪一种方法来关闭线程池,应该由提交到线程池的任务特性决定,通常调用shutdown方法来关闭线程池,如果任务不一定要执行完,则可以调用shutdownNow方法。
ThreadPoolExecutor提供了动态调整线程池容量大小的方法:
- setCorePoolSize 设置核心线程池大小。
- setMaximumPoolSize 动态调整线程池最大线程数maximumPoolSize。
当从小到大调整上述两个参数时,ThreadPoolExecutor实时调整线程池配置,可能导致立即创建新的线程来执行任务。
线程池的缺点
Java线程池虽然有很多优点,如在综述中提到的高效管理系统资源、减少资源消耗和提高响应速度等,但也存在一些缺点和需要格外留意的地方:
复杂的错误处理:在线程池中运行的任务如果抛出未捕获异常,可能会导致线程终止,进而影响整个线程池的工作效率。
资源耗尽:如果线程池配置得过小,当有大量并发请求时,可能导致请求排队时间过长甚至拒绝服务;相反,若线程池过大,则会消耗大量系统资源(如内存),还可能引起频繁的垃圾回收(GC)。
线程饥饿:在某些情况下,比如线程池中的线程都在执行长时间运行的任务,那么新来的短期任务就可能会长时间等待,造成线程饥饿现象。
死锁风险:如果线程池配置不当或者任务设计不合理,容易引发死锁问题。例如,线程池中的所有线程都在等待另一个任务完成,而这个任务又在等待线程池中的空闲线程,这样就会形成死锁。
任务丢失:如果线程池的队列满了且设置了拒绝策略为丢弃任务,那么新的任务可能会直接被丢弃。
为了克服上述缺点,合理地设置线程池参数、选择合适的线程池类型(如CachedThreadPool, SingleThreadExecutor等)以及正确实现任务逻辑是非常关键的。同时,也可以通过监控线程池的状态来动态调整其配置。
提交任务
既然谈到线程池如何执行任务,就必须先谈谈如何提交任务。我们在线程池中可以使用两种方式提交任务,一种是execute,另一种是submit。这两种方式的区别如下:
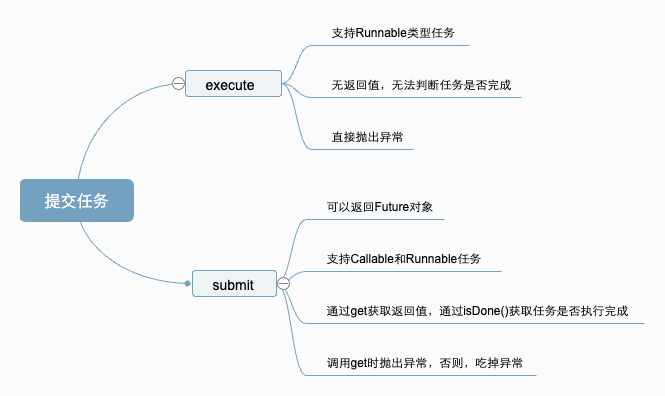
两种提交任务的方式
-
任务类型
- execute只支持提交Runnable类型的任务。
- submit提交的任务类型既能是Runnable也能是Callable。
-
执行结果
- execute没有返回值,故无法获取执行结果。
- submit可以获取执行结果。它返回一个Future类型的对象,通过这个对象可以拿到任务执行结果和任务是否执行成功。如
Future<Object> futureResult = executor.submit(task)。
-
异常处理
- execute会直接抛出执行任务时遇到的异常,可以使用try catch来捕获,这一点和普通线程的处理方式完全一致。
- submit函数会吃掉异常,但是如果调用Future的get方法,异常将重新抛出。
虽然两者提交任务的入参类型有差异,但是最终处理任务的方法是相同的,都是ThreadPoolExecutor类的函数execute。总之,如果不需要拿到任务执行结果,直接调用execute会提高性能。
在实际业务场景中,Future和Callable基本是成对出现的,Callable负责封装执行结果,Future负责获取结果。Future可以拿到异步执行任务的结果,不过,调用Future.get方法会导致主线程阻塞,直到Callable任务执行完成。
结束语
至此,已经介绍完线程池核心知识点,预祝各位读者在工作中能够迅速而准确地处理线程池相关需求,就像运斤成风一样。
在编程这个复杂严峻的环境中,请活得优雅坦然:也许你的钱包空空如也,也许你的工作不够好,也许你正处在困境中,也许你被情所弃。不论什么原因,请你在出门时,一定要把自己打扮地清清爽爽,昂起头,挺起胸,面带微笑,从容自若地面对生活和面对工作。人生就像蒲公英,没事尽量少吹风;只要你自己真正撑起来了一片天地,别人无论如何是压不垮你的,内心的强大才是真正的强大。