Redis JSON
RedisJSON 是 Redis Stack 提供的模块之一,允许你以 原生 JSON 格式 存储、检索和修改数据。相比传统 Redis Hash,它更适合结构化文档型数据,并支持嵌套结构、高效查询和部分更新。
bash
#设置⼀个JSON数据,其中$表示JSON数据的根节点
JSON.SET user:1 $ '{"name":"Alice","age":25,"skills":["Java","Redis"]}'
# 输出: "Alice"
JSON.GET user:1 $.name
# 添加数组元素
JSON.ARRAPPEND user:1 $.skills '"Docker"'
#查看数据类型
JSON.TYPE user:1 $.name
# 年龄+2
JSON.NUMINCRBY user:1 $.age 2优势
- Redis JSON存储数据的性能更⾼。
- Redis JSON使⽤树状结构来存储JSON。
- 与Redis⽣态集成度⾼。
Search And Query
在 RedisJSON 中,Search and Query(搜索与查询) 是通过 RediSearch 模块 实现的,这也是 Redis Stack 中最强大的功能之一。它让 Redis 不再只是一个 Key-Value 缓存,而是支持类数据库的多字段、高性能搜索查询。
- 传统Scan搜索
bash
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]- Search And Query搜索
RedisJSON 本身只能通过路径读取数据,不能进行模糊搜索、筛选年龄大于30的用户等复杂查询。这时候就需要 RediSearch。配合 RediSearch 使用 JSON 搜索(只有hash和json支持)
bash
JSON.SET user:1 $ '{"name":"Tom","age":30,"city":"Beijing"}'
JSON.SET user:2 $ '{"name":"Alice","age":25,"city":"Shanghai"}'
JSON.SET user:3 $ '{"name":"Jack","age":35,"city":"Guangzhou"}'
FT.CREATE idx:users ON JSON PREFIX 1 user: SCHEMA $.name AS name TEXT $.age AS age NUMERIC $.city AS city TAG
#查询 name 中包含 "Tom" 的用户
FT.SEARCH idx:users "@name:Tom"
#查询年龄在 26~40 岁之间的用户
FT.SEARCH idx:users "@age:[26 40]"
#查询城市是 "Beijing" 的用户
FT.SEARCH idx:users "@city:{Beijing}"
#多条件组合查询(AND)
FT.SEARCH idx:users "@age:[20 40] @city:{Shanghai}"Bloom Filter
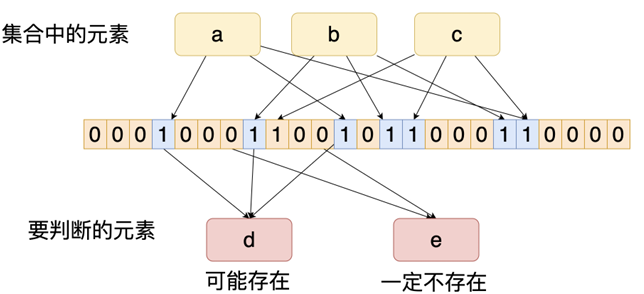
Bloom Filter 是一种高效、概率型的数据结构,用于判断某个元素是否存在于集合中。它的特点是:
- 快速判断某元素是否存在
- 空间效率高
- 存在一定概率的误判(可能"误判存在",但绝不会"误判不存在")
java可以使用Redisson和Guava的布隆过滤器
⼀句话解释:⼀种快速检索⼀个元素是否在⼀个海量集合中的算法。
bash
# 初始化一个布隆过滤器my_filter: 过滤器名称,0.01: 误判率(1%),10000: 预估元素数量(容量)
BF.RESERVE my_filter 0.01 10000
#添加元素
BF.ADD my_filter "alice"
#判断元素是否存在,返回 1(存在)
BF.EXISTS my_filter "alice"
#批量添加与判断
BF.MADD my_filter "a" "b" "c"
BF.MEXISTS my_filter "a" "x" "b"
# 返回: 1 0 1Cuckoo Filter
Cuckoo Filter(布谷鸟过滤器) 是一种替代布隆过滤器(Bloom Filter)的数据结构,它同样用于判断元素是否存在于集合中,但它在一些方面有显著优势。
| 特性 | Cuckoo Filter | Bloom Filter |
|---|---|---|
| 查询是否存在 | ✅ | ✅ |
| 添加元素 | ✅ | ✅ |
| 删除元素 | ✅(支持) | ❌(不支持) |
| 空间效率 | 较高 | 更高(一般情况) |
| 扩容能力 | 支持 | 支持(但较复杂) |
| 误判率 | 存在 | 存在 |
bash
#容量1000,这个是必填参数。后⾯⼏个都是可选参数
#BUCKETSIZE: 每个 bucket 存放的 fingerprint 数量,越大空间利用率越好但是误判率也越高,性能也更差
#MAXITERATIONS: 插入时的最大尝试次数,越小性能越好,越大空间利用率越好
#EXPANSION: 自动扩容因子(默认是 1),是指空间扩容的比例
CF.RESERVE cf 1000 BUSKETSIZE 2 MAXITERATIONS 20 EXPANSION 1
#删除元素
CF.DEL