一、什么是 Milvus?
Milvus 是一款开源的向量数据库,用于存储、管理和检索高维向量数据。它适合构建各种 AI 场景下的向量检索系统,如推荐、图像搜索、问答系统等。
概念关系图(逻辑结构)
json
Milvus数据库
├── Collection集合
│ ├── Partition分区
│ │ └── Entity实体
│ │ └── Fields字段(向量 + 元数据)
│ ├── Schema结构
│ └── Index索引
├── 查询操作(Search / Query)
└── 数据一致性机制二、Milvus 核心概念速查表

实体 Entity 示例
json
{
"id": 1,
"embedding": [0.1, 0.2, 0.3, ...],
"title": "iPhone",
"price": 999.0
}三、核心操作流程

四、一致性模型与数据安全保障
Milvus 提供以下一致性保证:

五、索引类型选择指南
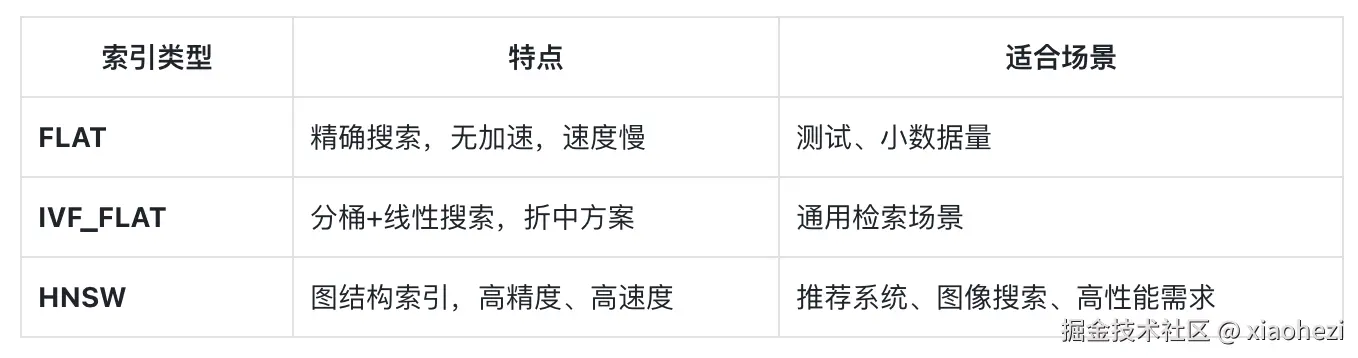
六、进阶知识点补充

七、实战:使用 Python SDK 完整示例(基于 Milvus 2.x)
环境准备
python
pip install pymilvus初始化连接
python
from pymilvus import connections
connections.connect(alias="default", host="localhost", port="19530")创建 Collection
python
from pymilvus import FieldSchema, CollectionSchema, DataType, Collection
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128)
]
schema = CollectionSchema(fields, description="商品向量集合")
collection = Collection(name="product_vectors", schema=schema)插入数据
python
import numpy as np
titles = ["iPhone", "MacBook", "AirPods"]
vectors = [np.random.rand(128).tolist() for _ in range(3)]
collection.insert([titles, vectors])
collection.flush()创建索引 & 加载数据
python
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128}
}
collection.create_index(field_name="embedding", index_params=index_params)
collection.load()向量搜索 + 条件过滤(Hybrid Search)
python
query_vector = [np.random.rand(128).tolist()]
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
results = collection.search(
data=query_vector,
anns_field="embedding",
param=search_params,
limit=5,
expr="title like 'Mac%'"
)
for hits in results:
for hit in hits:
print(f"id: {hit.id}, distance: {hit.distance}")八、常见踩坑提醒

九、真实应用场景参考:电商推荐系统

十、快速上手建议
✅ 推荐
- 从创建 Collection 开始,理解字段与向量的对应关系
- 一步步插入数据、构建索引、执行搜索
- 多关注向量维度、索引类型和内存管理
❌ 避免
- 向量维度不统一
- 未加载数据就开始搜索