1.概述
本文将围绕构建兼具本地运行大型语言模型(LLM)与MCP 集成能力的 AI 驱动工具展开,为读者提供从原理到实践的全流程指南。通过深度整合本地大模型的隐私性、可控性优势与 MCP 工具的自动化执行能力,帮助用户以低门槛、高效率的方式,打造个性化 AI 助手,实现任务自动化 ------ 无论是文档处理、数据分析,还是流程调度等场景,均可通过这一集成方案,借助大模型的语义理解与推理能力,结合 MCP 工具的标准化接口,构建端到端的智能工作流,让 AI 真正成为提升生产力的核心引擎。
2.内容
2.1 环境准备
- ollama
- python==3.13.2
- uv 0.6.12
- Linux / macOS
大模型服务部署
- 安装ollama服务框架
- 通过ollama部署所需的大语言模型
开发环境配置
- 准备Python 3.13运行环境(推荐使用最新稳定版)
- 安装mcp服务开发所需的Python包
开发工具推荐
- 使用uv工具链(新一代Python项目管理工具)
- 功能覆盖:
- Python版本管理
- 虚拟环境控制
- 依赖包管理
- 项目依赖维护
- 优势:提供全流程的Python开发环境管理方案
2.2 ollama安装
访问ollama地址:https://ollama.com/,然后根据自己的环境下载对应的安装包,如下图所示:
安装好ollama后,启动服务后,可以执行命令来检查服务是否启动成功,如下图所示:

然后,我们在ollama的模型页面选择我们需要下载的大模型,可以根据自身机器的性能来选择不同规模的模型,如图所示:

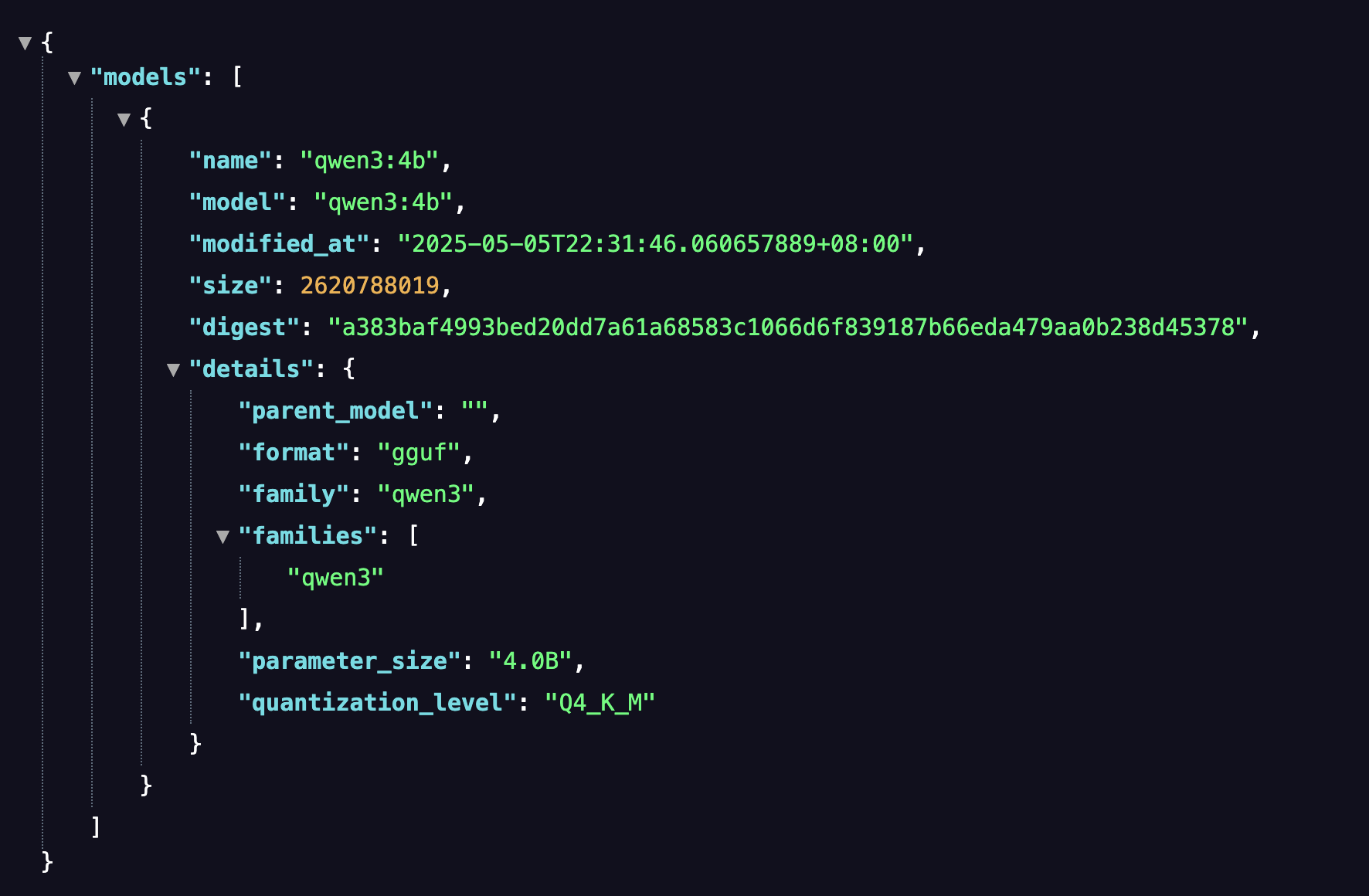
安装完成对应的模型后,可以通过http://localhost:11434/api/tags访问查看安装在本地的模型信息,如图所示:
2.3 安装uv工具
安装 uv(通常指 Rust 编写的超快 Python 包安装工具 uv,由 Astral 团队开发)的常用方法如下:
1. 使用官方安装脚本(推荐)
运行以下命令一键安装(适合 Linux/macOS):
curl -LsSf https://astral.sh/uv/install.sh | sh安装后按提示将 uv 加入 PATH 环境变量,或直接重启终端。
2. 通过 pip 安装
如果已配置 Python 环境,可直接用 pip 安装:
pip install uv3. 验证安装
运行以下命令检查是否成功:
uv --version3.编写MCP服务
环境准备好之后,我们就可以开始编写MCP服务了,这里我们编写一个简单的MCP服务,用于读取本地文件,实现代码如下所示:
import os
import uvicorn
import logging
from dotenv import load_dotenv
from argparse import ArgumentParser
from mcp.server.fastmcp import FastMCP
from starlette.applications import Starlette
from starlette.requests import Request
from starlette.routing import Route, Mount
from mcp.server import Server
from mcp.server.sse import SseServerTransport
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
# 加载环境变量
load_dotenv()
class Config:
"""应用配置类"""
HOST = os.getenv('HOST', '0.0.0.0')
PORT = int(os.getenv('PORT', 8020))
DEBUG = os.getenv('DEBUG', 'False').lower() == 'true'
FILE_PATH = os.getenv(
'FILE_PATH',
'/Users/smartloli/workspace/vscode/1/data.txt'
)
# 初始化MCP
mcp = FastMCP("file_reader")
@mcp.tool()
async def read_file():
"""
读取配置文件中的数据
Returns:
文件内容或错误信息
"""
file_path = Config.FILE_PATH
try:
logger.info(f"Reading file: {file_path}")
with open(file_path, 'r', encoding='utf-8') as file:
return file.read()
except FileNotFoundError as e:
logger.error(f"File not found: {file_path}")
return {"error": "File not found", "details": str(e)}
except Exception as e:
logger.exception(f"Error reading file: {file_path}")
return {"error": "Unexpected error", "details": str(e)}
def create_starlette_app(mcp_server: Server) -> Starlette:
"""创建基于Starlette的MCP服务器应用
Args:
mcp_server: MCP服务器实例
Returns:
Starlette应用实例
"""
sse = SseServerTransport("/messages/")
async def handle_sse(request: Request) -> None:
async with sse.connect_sse(
request.scope,
request.receive,
request._send
) as (read_stream, write_stream):
await mcp_server.run(
read_stream,
write_stream,
mcp_server.create_initialization_options(),
)
return Starlette(
debug=Config.DEBUG,
routes=[
Route("/sse", endpoint=handle_sse),
Mount("/messages/", app=sse.handle_post_message),
],
on_startup=[lambda: logger.info("Server starting...")],
on_shutdown=[lambda: logger.info("Server shutting down...")]
)
def parse_arguments():
"""解析命令行参数"""
parser = ArgumentParser(description='Run MCP SSE-based server')
parser.add_argument('--host', default=Config.HOST, help='Host to bind to')
parser.add_argument('--port', type=int,
default=Config.PORT, help='Port to listen on')
parser.add_argument('--debug', action='store_true',
help='Enable debug mode')
return parser.parse_args()
if __name__ == "__main__":
args = parse_arguments()
# 更新配置
Config.HOST = args.host
Config.PORT = args.port
Config.DEBUG = args.debug
# 启动服务器
mcp_server = mcp._mcp_server
starlette_app = create_starlette_app(mcp_server)
logger.info(f"Starting server on {Config.HOST}:{Config.PORT}")
uvicorn.run(
starlette_app,
host=Config.HOST,
port=Config.PORT,
log_level="info" if not Config.DEBUG else "debug"
)然后,我们使用uv来启动MCP服务,执行命令如下:
uv run file_list.py --host 0.0.0.0 --port 8020启动成功后,显示如下图所示信息:

4.集成LLM 和 MCP
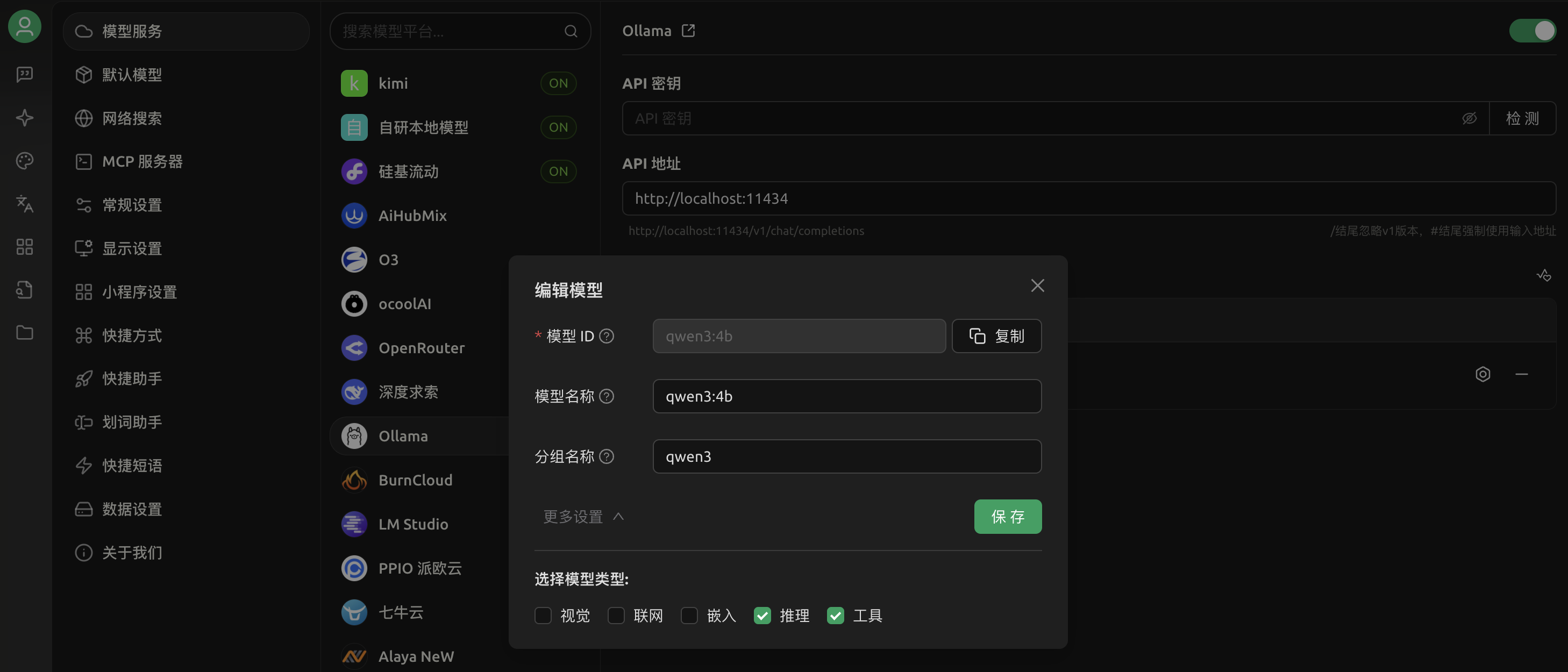
准备好LLM服务和MCP服务之后,我们在Cherry Studio客户端上集成我们本地部署的LLM 和 MCP 服务,如下图所示:
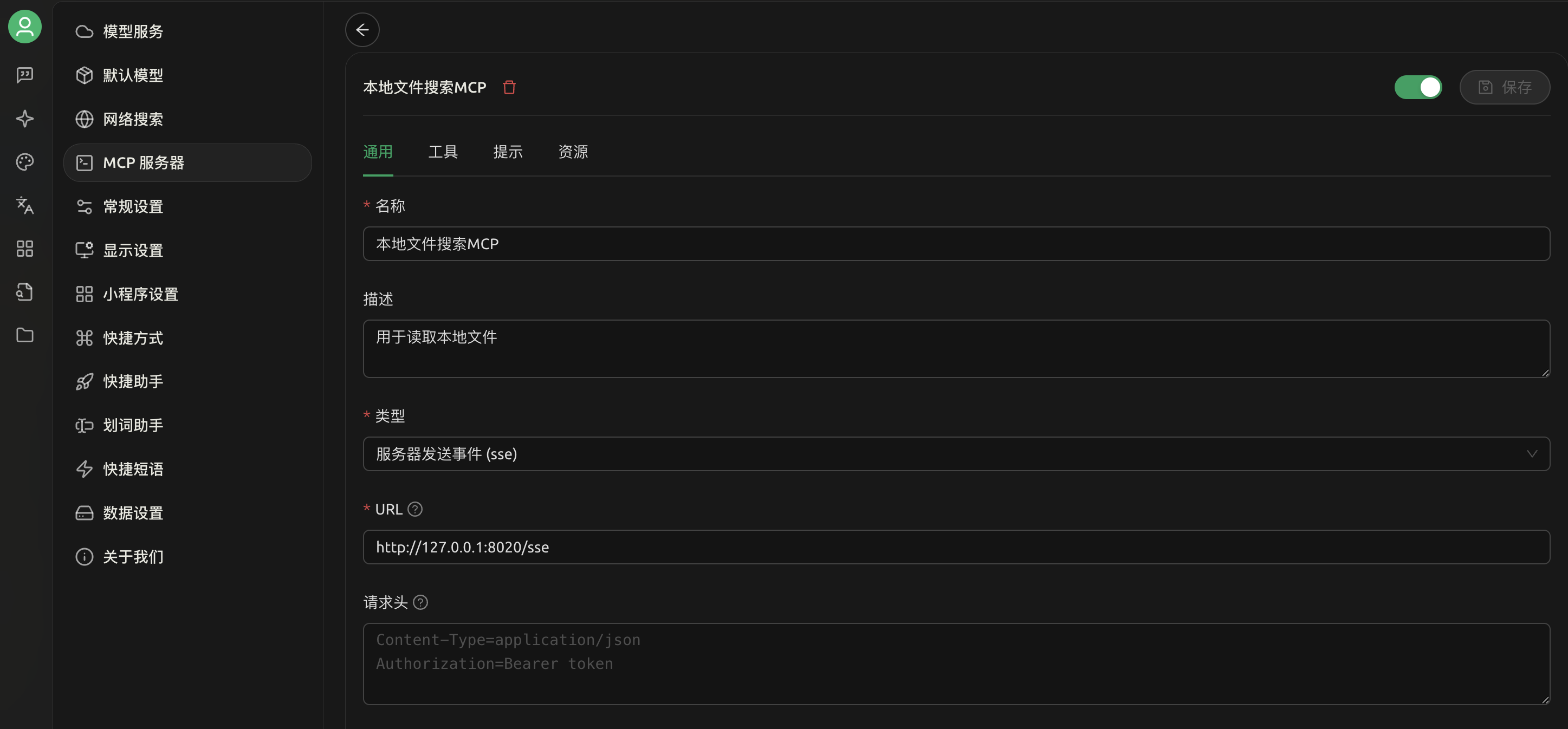
1.配置本地文件搜索MCP服务
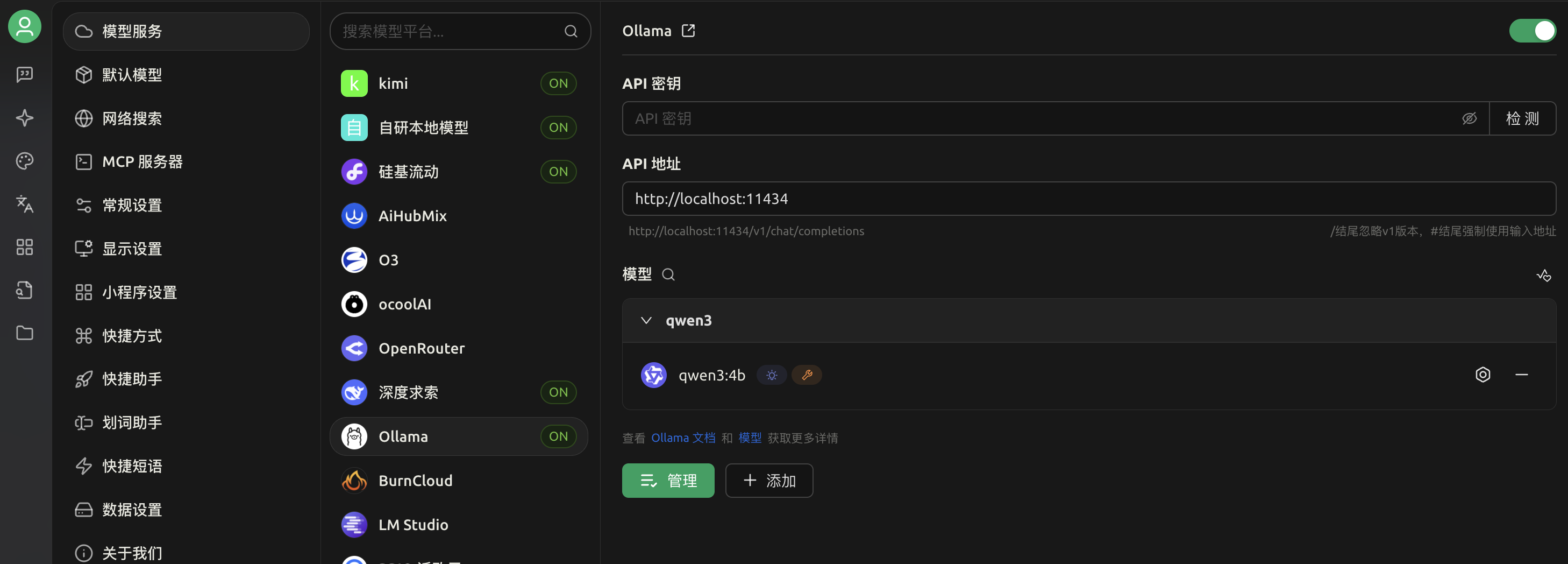
2.集成本地LLM
然后,在设置里面勾选"工具"就可以使用MCP服务了,如图所示:
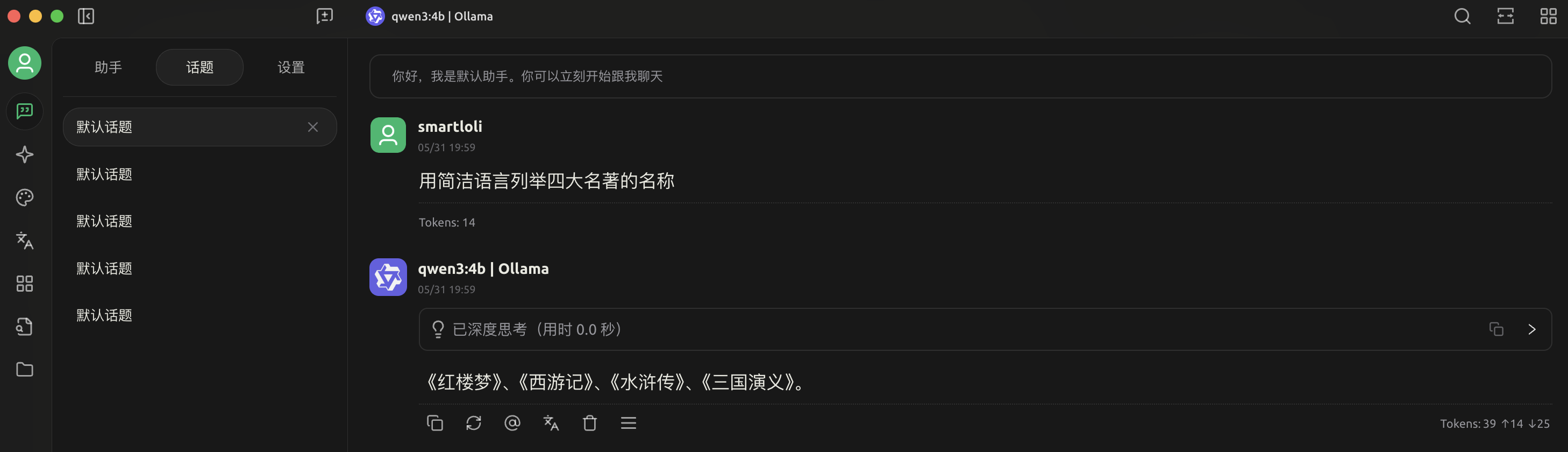
3.测试本地LLM回答
4.测试本地LLM & MCP调用
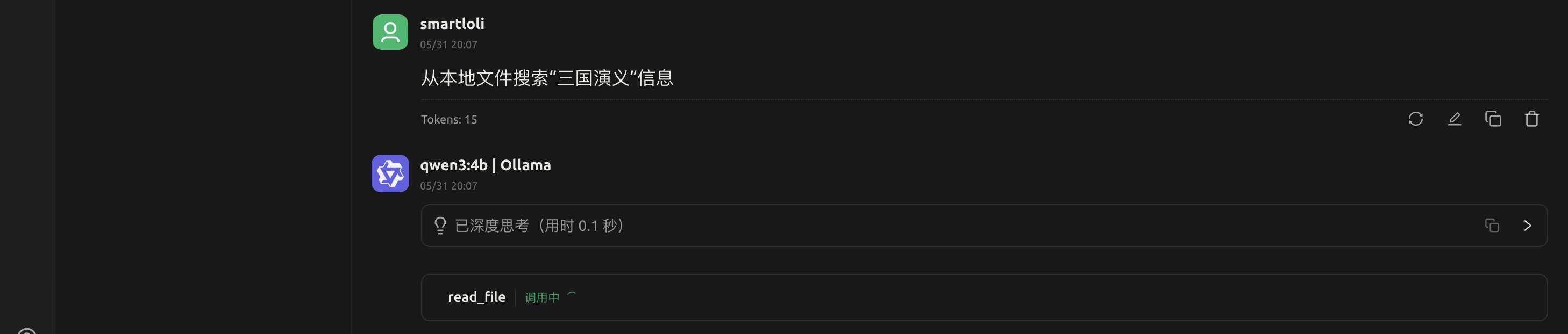
当我们开启MCP服务后,输入的搜索词中LLM会自行判断是否需要调用本地的MCP服务,这里我们通过搜索词触发LLM通过function去调用本地MCP服务。
5.总结
本文围绕本地大模型与模型上下文协议(MCP)的集成展开探索,重点揭示了通过 MCP 构建自定义 AI 工具的路径。通过适配不同开发环境与实际用例,MCP 为 AI 功能的跨场景整合提供了灵活框架,其核心优势体现在定制化能力上 ------ 从模型选型到集成策略的全流程可调节性,使开发者能够基于具体需求打造精准适配的 AI 解决方案,展现了 MCP 在整合本地大模型时的多功能性与实践价值。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出新书了《Hadoop与Spark大数据全景解析》、同时已出版的《深入理解Hive》、《Kafka并不难学》和《Hadoop大数据挖掘从入门到进阶实战》也可以和新书配套使用,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频。