
文|乐乐
今天,无线蓝牙耳机(TWS)已经成为人人都用得起的产品。
但退回到9年前,苹果AirPods是全球第一款真正意义上的无线蓝牙耳机。靠着自研并申请专利的Snoop监听技术,苹果解决了蓝牙耳机左右延时和能耗不一的问题。由此,AirPods吃下了2016-2018年的大部分市场,直到两年后其它厂商才学会类似技术。
靠技术红利获胜,是苹果的经典操作,也是今天的手机厂商们在苹果身上学到的重要一课。
对于近两年的手机市场来说,AI无疑就是搅动手机市场的关键技术变量。
为了找到AI技术落地的杀手级功能,从Agent、AI修图到AI问答,智能终端在做的事情就是在AI生态上尽可能做各种各样的加法。
在高度同质化的AI手机赛道,手机厂商们亟需找到创新的AI技术落地功能。而荣耀,正在悄悄拿下多个首发优势。
在近期荣耀400的发布会现场,图生视频成了荣耀"吃螃蟹"的又一首发功能,这背后是合作方生数科技旗下的AI视频大模型在移动端的首次规模化落地。
联手生数科技Vidu,荣耀突破了三大难关------保持风格一致性、对物理世界的理解、端侧成本压缩,让用户免费体验"老照片复活术"。

而就在两个月前,生数科技 Vidu Q1模型刚以VBench双榜第一的成绩碾压Sora与Runway,如今就悄然钻进千万用户的口袋。
这场合作背后,一场更深层的变革正在发酵。
当前,多模态正在重构智能终端的交互体验,手机正成为图生视频技术普惠的战场之一。当大模型的技术竞赛从语言模型延伸到多模态,"让记忆重获生命"的图生视频,或许正是打开大众市场的第一把钥匙。
当图生视频在手机上跑起来
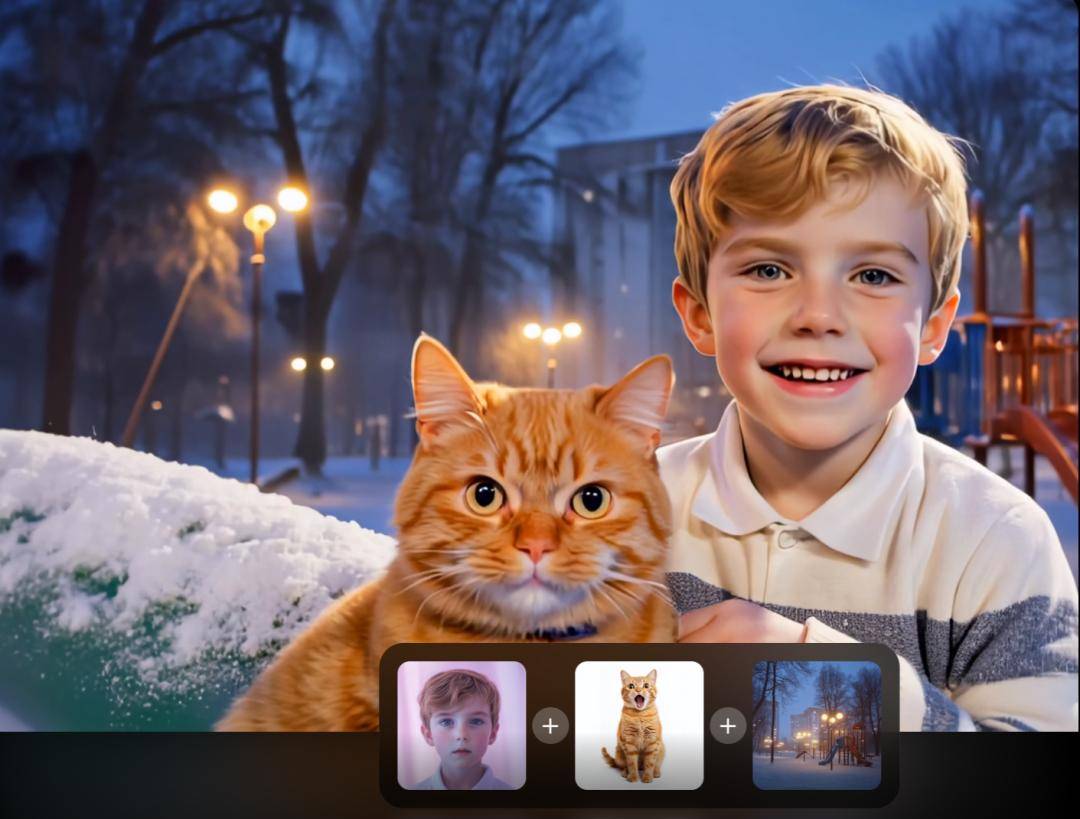
一张由AI制作的"Live Photo",成为了荣耀发布会现场众人讨论的焦点。
照片中,一个小孩抱着窗帘看向镜头微笑。经由图生视频功能加工后,小孩抓着窗帘向一边摇晃,头部也随着晃动方向微微倾斜,脸上挂着的笑容变成了动态,能看到嘴角咧起的弧度和鼓起的脸颊。
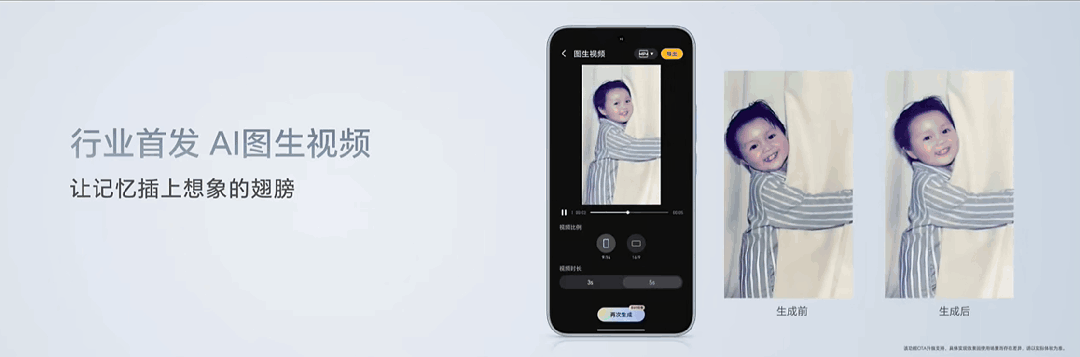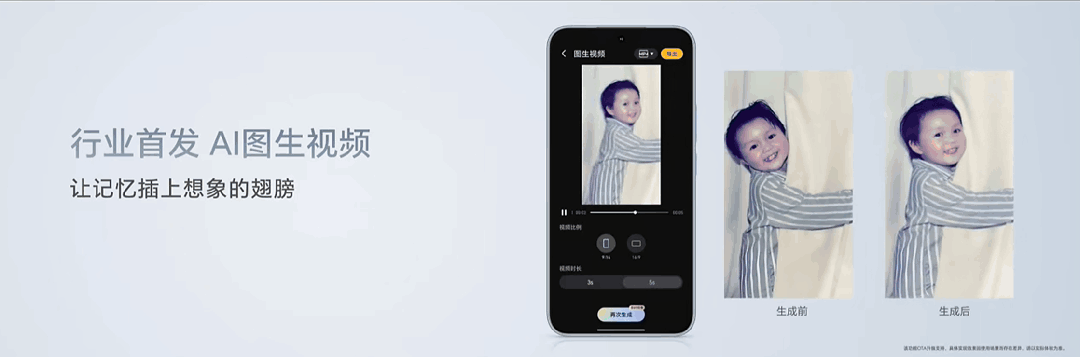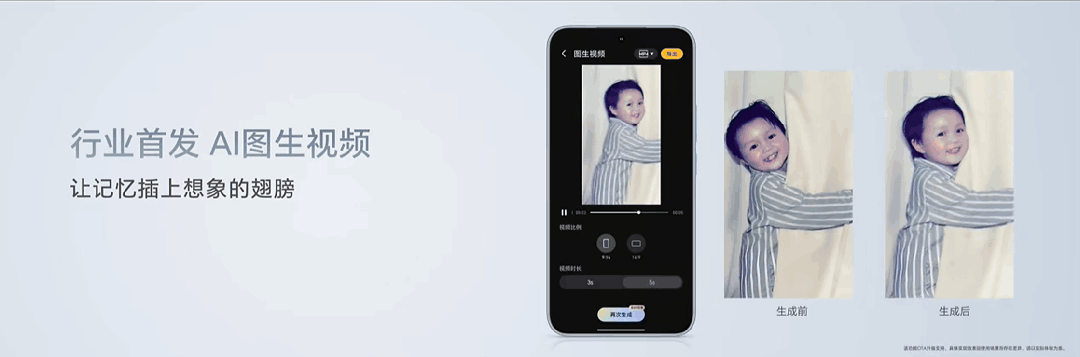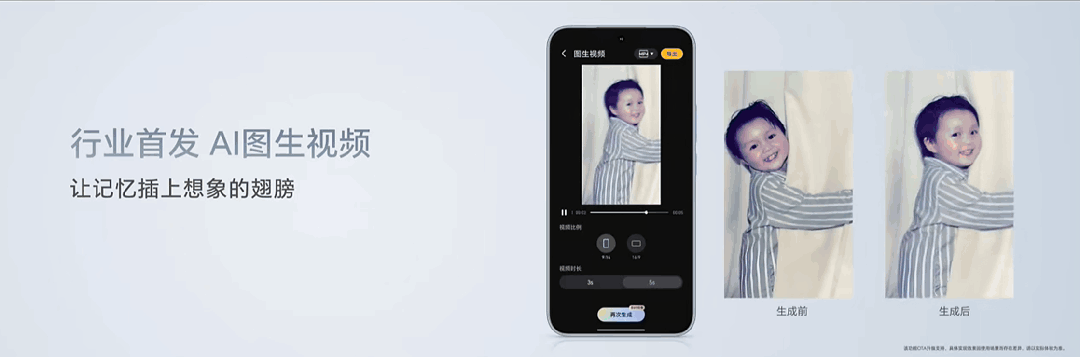
在荣耀产品线总裁方飞的演示中,只需要点击"AI生图"功能,选定相应照片和生成的视频时长(3秒/5秒),AI就能根据图片场景生成一段流畅的视频。上述案例就是由该功能生成。
早在3月宣布向AI终端生态公司转型的荣耀,在数字系列荣耀400上落地了一系列AI能力。光是照片一项,荣耀就上线了AI图生视频、AI去褶皱、AI去眼镜反光、AI去玻璃反光、图生视频等优化功能。

看起来简单的视频演示,背后是图生视频技术落地智能终端的一大步:攻克了技术难点,才能让AI视频看起来无限趋近于真实。
首先,要想让视频动起来的效果符合真实世界的运行规律,就是视频生成模型们早期的通病。比如提示词设定成两个人打羽毛球,交给AI来做,球可能会出现凭空飞起或者不按照球拍击打轨迹飞行等问题,导致生成出来的作品无法使用。
当下,如何更好地模拟物理世界规律,也成了大模型们面前的难关。就在3月份,生数科技发布的模型Vidu Q1,在VBench-1.0的视频质量、视频语义一致性和 VBench-2.0的常识推理、物理理解等综合维度上达到SOTA水平。靠着对提示词的理解力增强,Vidu能自动识别人物动作、光影、位置关系等内容,让生成的视频在动态上符合物理世界规律。
此外,在风格一致性上,擅长动漫、水墨等多种画风理解的Vidu,在保持原图风格一致上的表现相对稳定。相比于会把真实图片上传后随机转换成油画、动漫等风格的视频生成模型,Vidu显然在场景理解上的表现更胜一筹。
不过,要想让AI视频真正普及,还需要考虑的就是生成速度和成本问题。等待时间超过几分钟,用户体验感会直线下滑,成本太高也会拖垮手机厂商的钱包。
而荣耀和生数科技一起克服了这几个问题,把图生视频玩法搬上了手机。相对于各大视频应用靠会员制收费,荣耀的图生视频功能完全免费,让用户不花钱也能体验。
虽然这次并未公布具体的生成时长和成本,但根据此前Vidu 1.5版本做到几秒生成、Vidu 2.0单秒成本最低不到3毛钱的价格来看,AI视频已经具备了落地端侧的条件。
除此之外,AI视频大模型的技术一直在进步,未来或将在手机等智能终端中实现更多的功能。
比如,AI视频一直存在一个技术难点------主体一致性。主体一致性,是指保持人物、物体、环境等主体一致,不会面部五官乱飞,环境前后连贯
2024年,生数科技在新模型Vidu 1.5中实现多主体一致性,使用者可以上传背景和多个主体人物的照片,AI就能将这些自定义元素组合在一起,根据提示词生成视频。
以多主体一致性来说,海螺AI的"主体参考"功能和可灵的"多图参考"均在今年1月上线,比Vidu慢了2个月。
多模态,智能终端的新战场
多模态大模型,最近半年内正在肉眼可见的批量落地。
在App端,字节在5月23日给自家AI助手应用豆包装上了视频通话功能。背靠自研的视频推理模型,豆包不仅能"睁眼看世界",还能根据看到的画面推测接下来的动作,比如炒菜的时候,豆包能够根据原料猜出对应的菜,并且给出炒菜的具体步骤。
腾讯则在5月份发布了语音模型Human-Voice,并预告腾讯元宝将会在6月上线语音通话功能。同时,腾讯还会上线全球首个全模态模型"混元-O"。
在智能终端上,本身通过GUI(图形用户界面)实现交互的手机厂商们,就是多模态大模型的重要载体。
可以说,从这一轮生成式AI开始时,多模态AI就被厂商纳入了考虑范围。只是一开始在技术能力受限的情况下,大语言模型成为了端侧大模型落地最早的一种。
多模态模型在端测的应用更广,场景更多,不仅可以为以往场景赋能,还能有新的互动体验场景,受众范围也会更广,因为视频图像的受众总是大于文字的。
随着多模态能力的技术进步,端侧语音和视频交互的比重正在上升。
比如,一些在端侧运行的大语言模型逐渐被多模态大模型代替,相应应用的底座也升级为多模态:
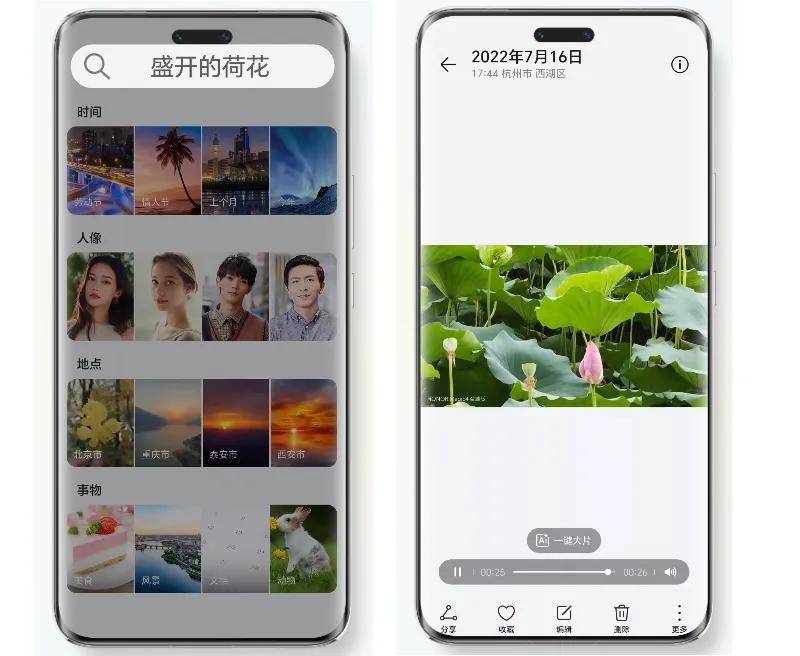
2024年1月,荣耀发布自研端侧70亿参数平台级AI大模型"魔法大模型"家族,包括语言大模型和图像、语音多模态大模型,支持智慧成片、图库语义搜索等功能,让AI能够"理解"图片;在购物、娱乐、办公等场景,开启跨时代交互体验。2024年5月,vivo发布多模态大模型技术应用"vivo看见-蓝心升级版",用于帮助视障用户理解世界。
伴随行业多模态能力的突破,以往受限于能力不足的AI应用,也迎来了能力突破。
其中,最突出的应用领域就是Agent(智能体)。通过调用手机屏幕截图,再将图片提供给多模态大模型的方式,AI开始能够真正"理解"屏幕信息,并根据用户指令工作。这就有了去年以荣耀为首等一系列手机厂商开卷智能体的动作,从荣耀的YoYo智能体到vivo蓝心智能体再到OPPO的"AI问屏",都是基于多模态能力实现的自主智能体产品。
基于多模态能力的AI修图系列功能,也是应用更加广泛的方向。早在2010年,手机厂商就开始探索基于图像理解的AI摄影算法,通过对图片的理解,用算法还原图片生成的细节。
而在生成式AI能力进化的当下,基于多模态大模型的一系列图片优化功能也是厂商重点宣传的方向。从各大手机厂商必备的一键修图、图片识别等功能,都是基于人们日常生活中的需求出发。
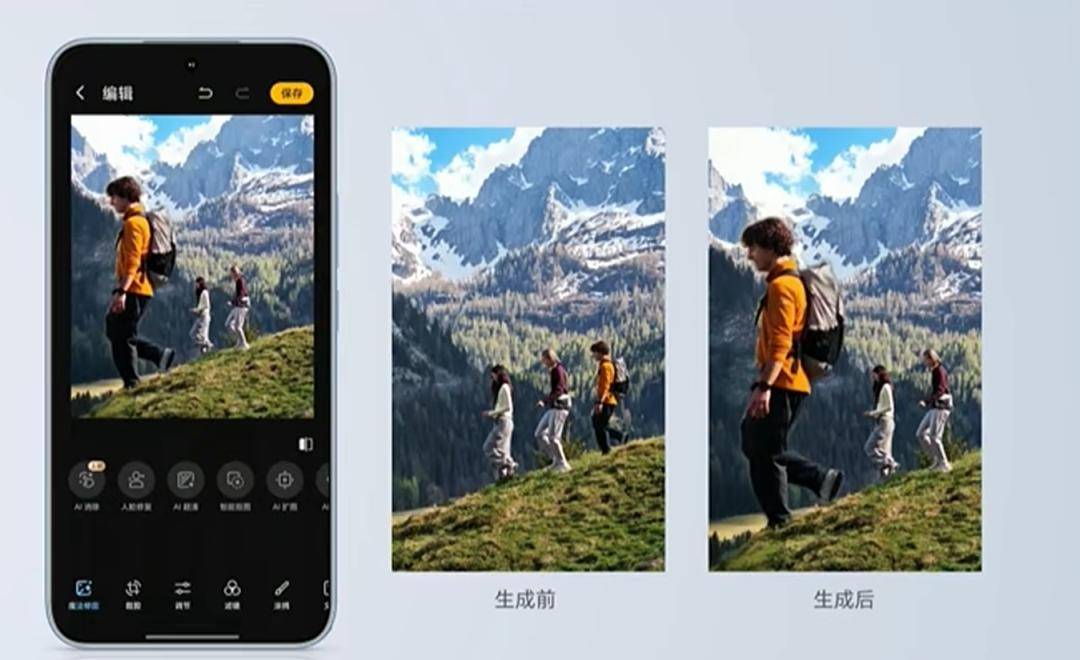
这一次,荣耀也在发布会上带来了AI修图带来的更多可能性。比如用AI实现"一键抠图",让没有PS功底的用户也能轻松从图片中抠出人像,自由移动编辑;再比如"AI消除眼镜反光"的功能,通过AI消除掉拍照时眼镜折射的色彩。
在智能终端需求和多模态能力普及的当下,二者一拍即合。
AI功能那么多,能用起来的有几个?
从大模型火热以来,手机厂商对AI的热情无比高涨,开发的功能也是多如牛毛。
从对话式聊天助手、AI笔记、AI修图到AI智能体,不上十几个原生的AI应用,那都没法叫AI手机。
图片来源于网络
不过,用户真正能日常使用起来的高频应用,并不多。很多AI功能,要么是独立APP上有更好的替代品,要么就是功能鸡肋用不起来。
另一方面,不少AI应用目前的使用门槛还比较高,一个是对用户的硬件环境有要求,需要PC端至少4090的显卡才能跑起来;另一个是对用户的技能有一定要求,下载、简单部署、甚至海外账号的设置都能拦截掉一大批人。
以上面提到的图生视频来说,虽然可灵、海螺的产品比较成熟,有了很高的可用性,但用户也仅仅局限于相对专业的用户范围内,比如设计师、动画制作师、新媒体从业者等,普通用户想自己用起来还非常难。
但荣耀和生数科技Vidu共同在端侧新推出的图生视频功能,无论是用来将过往的老照片变成视频,还是靠图生视频抓住鲜活的时刻,就又给用户记录生活,创作灵感增添了许多可能。
而一张照片的视频生成,只是一个开始。
智能终端与AI公司联手后,参考生视频、文生视频等AI视频的更多玩法,都有望进一步迁移到智能终端中。
当然,这将进一步考验双方端侧AI、云端协同的技术能力,成本降低的能力。但真正能让用户用起来,才能真正增强产品的竞争力,在手机竞争的红海中逆势上升。
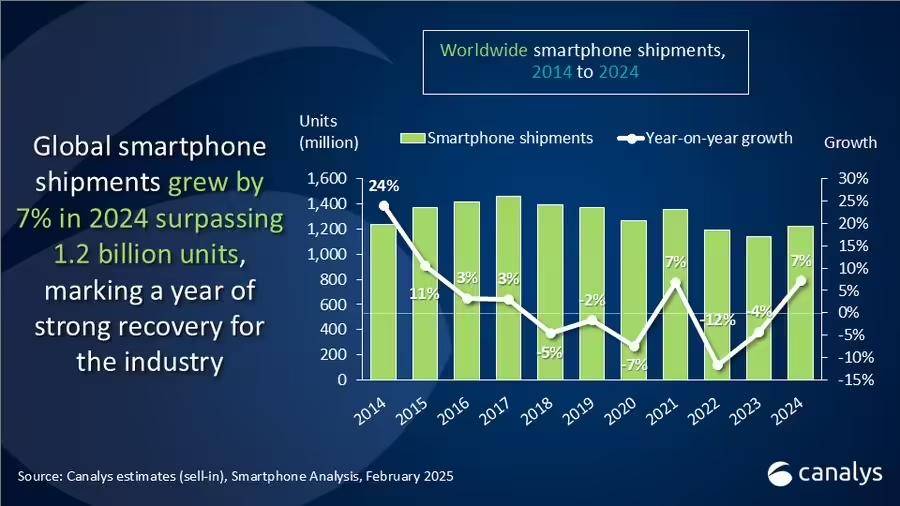
2024年,手机市场变化已经证明了AI对于手机销量的促进作用。在全球手机销量连续下滑两年后,于AI概念真正落地手机的2024年,全球已经连续4个季度实现了同比增长。市场调研机构Canalys提供数据显示,2024年全球手机销量达到12.2亿,同比增长7%。
比起在技术层的炫技,今年,AI在端侧的落地将给人带来更多惊喜。