QRSuperResolutionNet:一种结构感知与识别增强的二维码图像超分辨率网络(附代码解析)
趁着 web开发课程 期末考试前夕,写一篇博客。{{{(>_<)}}}
将我最近所做的工作整理一下,同时该工作已经写成论文,已被ei检索会议录取~~~
最近,我一直在回味过去这两三个月的项目经历,感慨万千。这个项目我从开始做到现在得有两三个月,立项前我也一直在看超分方向以及扩散模型方向的论文,看看自己适合什么样的。后来偶然间,感觉qrcode这个方向的论文比较少,就尝试入手。
可从项目开始到结束,我整个人一直处于忐忑不安的状态。心里就像悬着一块大石头,生怕自己花了大把时间,最后却一无所获。毕竟,这件事的成功与否,对我来说充满了不确定性。当我真正开始训练自己的模型时,才发现事情远没有我想象的那么简单。很多时候,我绞尽脑汁加上一些自认为很巧妙的模块,结果模型的收敛效果、准确率(ACC)等指标却差得一塌糊涂,甚至还不如原生(native)模型。那一刻,我只能苦笑,心里满是无奈。
那段时间,我几乎被压得喘不过气来。期末考试的压力如影随形,课程任务也堆积如山,而我还要挤出时间来训练模型。甚至在几门专业课考试前的几个小时,我还在忙着修改代码、调整论文格式。那种忙碌和焦虑,让我几乎要崩溃了。
好在,最后的结果还算不错,我的论文被一个EI检索会议录取了。虽然我知道EI检索会议的含金量可能并不算高,但对我来说,这却是我十几年学习生涯中第一篇真正属于自己的文章,是我独自摸索、独自奋斗的成果。没有依赖任何人,我凭借自己的努力走到了这一步,这份成就感已经让我心满意足。我也相信这个不是终点,是我的学习生涯的新的起点。
在代码完成后,为了找到一个时间合适、能赶上进度的会议,我又花了很长时间搜寻。然后,按照会议的要求修改论文格式,最让我头疼的就是用Word修改公式了。那一刻,我简直想抓狂,但又不得不咬着牙坚持下去。(っ °Д °;)っ
时光飞逝,转眼间我已经大三了,站在人生的又一个十字路口,回首过往三年的大学生活,心里五味杂陈。这三年,就像一场惊心动魄的冒险,我在里面尽情尝试、探索,但也免不了碰得头破血流。我收获了成长,积累了经验,也吸取了教训,可同时,也有不少后悔的地方,很多时候稀里糊涂地做着无用功,甚至到现在还不清楚自己真正想要什么。但即便如此,我也不忍心太苛责自己。毕竟,我一个人从山东鲁西南地区的乡镇小学,一路跌跌撞撞走到城里的初中,再到高中,在那所每年1600多人里,仅有400多人能本科上线,两三百人能有本科可读的高中里,一路拼杀,好不容易才走到了今天。这一路走来,每一步都写满了艰辛,可我也已经走了很远了。
写了很多,又删了很多,千言万语,很多话到了嘴边又咽了回去。我只希望自己能在接下来这一年多的本科生涯里,继续做好自己的本职工作,继续努力。
废话不多说,下面就是正式的讲解阶段。希望各位大佬多多提提意见,共同进步!
也希望可以给项目点个star,谢谢各位。~~~
项目地址:https://github.com/lizhongzheng13/QRSuperResolutionNet-for-qrcode
1. 背景介绍
二维码图像在实际应用中常常由于压缩、模糊、低分辨率采集等原因导致质量下降,直接影响解码准确率。传统图像超分方法主要关注视觉质量,但对二维码这类结构化强、容错模式敏感的图像来说,仅提升 PSNR 和 SSIM 并不足够。因此,我在ESRGAN的基础上进行改进,设计了一种融合了 残差密集模块(RRDB) 、通道注意力机制(SEBlock) 与 Transformer 编码器 的二维码图像超分辨率模型 ------ QRSuperResolutionNet(简称:QRSRNet),旨在同时提升图像质量与识别鲁棒性。
2. 网络设计思路
QRSuperResolutionNet 的目标是将输入的 64×64 灰度二维码图像重建为清晰度和结构都更优的 256×256 图像,同时最大限度提升下游识别工具(如 pyzbar)的解码成功率。
核心结构设计包括:
- 主干特征提取网络:堆叠多个带有通道注意力的 RRDB 模块;
- Transformer 编码器:用于建模二维码图案中的长程结构依赖;
- 双分支上采样 :
- 主分支采用 PixelShuffle 逐步上采样;
- 辅助分支采用 Bicubic 插值形成跳跃连接,增强稳定性;
- 多级损失函数融合:训练过程中结合 L1 损失、感知损失和识别损失,提高图像质量与可识别性。
3. 模块结构 && 代码详解
以下为模型中各个关键模块的 PyTorch 实现与功能解析。
3.1 SEBlock:通道注意力机制
SEBlock 引入了通道维度的显著性建模,强化关键通道响应,减弱冗余信息。
python
class SEBlock(nn.Module):
def __init__(self, channels, reduction=16):
super(SEBlock, self).__init__()
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channels, channels // reduction),
nn.ReLU(inplace=True),
nn.Linear(channels // reduction, channels),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y3.2 ResidualDenseBlock:残差密集块
源自 ESRGAN,结合了残差连接与密集连接,提升了特征流动与重用能力。
python
class ResidualDenseBlock(nn.Module):
def __init__(self, channels=64, growth_channels=32):
super().__init__()
self.conv1 = nn.Conv2d(channels, growth_channels, 3, 1, 1)
self.conv2 = nn.Conv2d(channels + growth_channels,
growth_channels, 3, 1, 1)
self.conv3 = nn.Conv2d(
channels + 2 * growth_channels, growth_channels, 3, 1, 1)
self.conv4 = nn.Conv2d(
channels + 3 * growth_channels, growth_channels, 3, 1, 1)
self.conv5 = nn.Conv2d(
channels + 4 * growth_channels, channels, 3, 1, 1)
self.lrelu = nn.LeakyReLU(0.2, inplace=True)
def forward(self, x):
x1 = self.lrelu(self.conv1(x))
x2 = self.lrelu(self.conv2(torch.cat([x, x1], 1)))
x3 = self.lrelu(self.conv3(torch.cat([x, x1, x2], 1)))
x4 = self.lrelu(self.conv4(torch.cat([x, x1, x2, x3], 1)))
x5 = self.conv5(torch.cat([x, x1, x2, x3, x4], 1))
return x + 0.2 * x53.3 RRDB:残差-in-残差模块
RRDB 模块由三个 ResidualDenseBlock 堆叠构成,并在末尾加入 SEBlock,用于加强局部建模能力。
python
class RRDB(nn.Module):
def __init__(self, channels):
super().__init__()
self.rdb1 = ResidualDenseBlock(channels)
self.rdb2 = ResidualDenseBlock(channels)
self.rdb3 = ResidualDenseBlock(channels)
self.se = SEBlock(channels)
def forward(self, x):
out = self.rdb1(x)
out = self.rdb2(out)
out = self.rdb3(out)
out = x + 0.2 * out
out = self.se(out)
return out3.4 TransformerBlock:结构感知模块
利用多头注意力机制对整个图像的结构进行建模,引入非局部信息,增强上下文一致性。
python
class TransformerBlock(nn.Module):
def __init__(self, dim, num_heads=4, mlp_ratio=2.0, dropout=0.1):
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.attn = nn.MultiheadAttention(
dim, num_heads, dropout=dropout, batch_first=True)
self.norm2 = nn.LayerNorm(dim)
self.mlp = nn.Sequential(
nn.Linear(dim, int(dim * mlp_ratio)),
nn.ReLU(inplace=True),
nn.Linear(int(dim * mlp_ratio), dim)
)
def forward(self, x):
b, c, h, w = x.shape
x_flat = x.view(b, c, -1).permute(0, 2, 1) # B x N x C
x_norm = self.norm1(x_flat)
attn_out, _ = self.attn(x_norm, x_norm, x_norm)
x = x_flat + attn_out
x = x + self.mlp(self.norm2(x))
x = x.permute(0, 2, 1).view(b, c, h, w)
return x3.5 主网络 QRSuperResolutionNet
主结构由以下几部分组成:
entry:输入卷积body:多个 RRDB 构成的特征提取主干transformer:结构感知编码器upsample:PixelShuffle 上采样两次,实现 4× 分辨率提升skip_up:Bicubic 上采样跳跃连接,提升图像稳定性exit:输出卷积,生成超分图像
python
class QRSuperResolutionNet(nn.Module):
def __init__(self, in_channels=1, out_channels=1, base_channels=64, num_blocks=5):
super().__init__()
self.entry = nn.Conv2d(in_channels, base_channels, 3, 1, 1)
# 主体 RRDB 模块
self.body = nn.Sequential(*[RRDB(base_channels)
for _ in range(num_blocks)])
# Transformer 编码模块
self.transformer = TransformerBlock(dim=base_channels)
# 上采样跳跃分支
self.skip_up = nn.Sequential(
nn.Upsample(scale_factor=4, mode='bicubic', align_corners=False),
nn.Conv2d(in_channels, out_channels, 3, 1, 1)
)
# PixelShuffle 上采样
self.upsample = nn.Sequential(
nn.Conv2d(base_channels, base_channels * 4, 3, 1, 1),
nn.PixelShuffle(2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(base_channels, base_channels * 4, 3, 1, 1),
nn.PixelShuffle(2),
nn.LeakyReLU(0.2, inplace=True)
)
self.exit = nn.Conv2d(base_channels, out_channels, 3, 1, 1)
def forward(self, x):
feat = self.entry(x)
feat = self.body(feat)
feat = self.transformer(feat) # 加入 transformer 结构
feat = self.upsample(feat)
out = self.exit(feat)
# 融合 Bicubic 分支输出
skip = self.skip_up(x)
out = out + skip
return torch.clamp(out, 0.0, 1.0)4. 模型测试代码
快速测试模型输出尺寸是否符合预期:
python
if __name__ == "__main__":
model = QRSuperResolutionNet()
dummy_input = torch.randn(1, 1, 64, 64)
output = model(dummy_input)
print("输出尺寸:", output.shape) # 预期:(1, 1, 256, 256)5.整体model代码展示
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class SEBlock(nn.Module):
def __init__(self, channels, reduction=16):
super(SEBlock, self).__init__()
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channels, channels // reduction),
nn.ReLU(inplace=True),
nn.Linear(channels // reduction, channels),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class ResidualDenseBlock(nn.Module):
def __init__(self, channels=64, growth_channels=32):
super().__init__()
self.conv1 = nn.Conv2d(channels, growth_channels, 3, 1, 1)
self.conv2 = nn.Conv2d(channels + growth_channels,
growth_channels, 3, 1, 1)
self.conv3 = nn.Conv2d(
channels + 2 * growth_channels, growth_channels, 3, 1, 1)
self.conv4 = nn.Conv2d(
channels + 3 * growth_channels, growth_channels, 3, 1, 1)
self.conv5 = nn.Conv2d(
channels + 4 * growth_channels, channels, 3, 1, 1)
self.lrelu = nn.LeakyReLU(0.2, inplace=True)
def forward(self, x):
x1 = self.lrelu(self.conv1(x))
x2 = self.lrelu(self.conv2(torch.cat([x, x1], 1)))
x3 = self.lrelu(self.conv3(torch.cat([x, x1, x2], 1)))
x4 = self.lrelu(self.conv4(torch.cat([x, x1, x2, x3], 1)))
x5 = self.conv5(torch.cat([x, x1, x2, x3, x4], 1))
return x + 0.2 * x5
class RRDB(nn.Module):
def __init__(self, channels):
super().__init__()
self.rdb1 = ResidualDenseBlock(channels)
self.rdb2 = ResidualDenseBlock(channels)
self.rdb3 = ResidualDenseBlock(channels)
self.se = SEBlock(channels)
def forward(self, x):
out = self.rdb1(x)
out = self.rdb2(out)
out = self.rdb3(out)
out = x + 0.2 * out
out = self.se(out)
return out
class TransformerBlock(nn.Module):
def __init__(self, dim, num_heads=4, mlp_ratio=2.0, dropout=0.1):
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.attn = nn.MultiheadAttention(
dim, num_heads, dropout=dropout, batch_first=True)
self.norm2 = nn.LayerNorm(dim)
self.mlp = nn.Sequential(
nn.Linear(dim, int(dim * mlp_ratio)),
nn.ReLU(inplace=True),
nn.Linear(int(dim * mlp_ratio), dim)
)
def forward(self, x):
b, c, h, w = x.shape
x_flat = x.view(b, c, -1).permute(0, 2, 1) # B x N x C
x_norm = self.norm1(x_flat)
attn_out, _ = self.attn(x_norm, x_norm, x_norm)
x = x_flat + attn_out
x = x + self.mlp(self.norm2(x))
x = x.permute(0, 2, 1).view(b, c, h, w)
return x
class QRSuperResolutionNet(nn.Module):
def __init__(self, in_channels=1, out_channels=1, base_channels=64, num_blocks=5):
super().__init__()
self.entry = nn.Conv2d(in_channels, base_channels, 3, 1, 1)
# 主体 RRDB 模块
self.body = nn.Sequential(*[RRDB(base_channels)
for _ in range(num_blocks)])
# Transformer 编码模块
self.transformer = TransformerBlock(dim=base_channels)
# 上采样跳跃分支
self.skip_up = nn.Sequential(
nn.Upsample(scale_factor=4, mode='bicubic', align_corners=False),
nn.Conv2d(in_channels, out_channels, 3, 1, 1)
)
# PixelShuffle 上采样
self.upsample = nn.Sequential(
nn.Conv2d(base_channels, base_channels * 4, 3, 1, 1),
nn.PixelShuffle(2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(base_channels, base_channels * 4, 3, 1, 1),
nn.PixelShuffle(2),
nn.LeakyReLU(0.2, inplace=True)
)
self.exit = nn.Conv2d(base_channels, out_channels, 3, 1, 1)
def forward(self, x):
feat = self.entry(x)
feat = self.body(feat)
feat = self.transformer(feat) # 加入 transformer 结构
feat = self.upsample(feat)
out = self.exit(feat)
# 融合 Bicubic 分支输出
skip = self.skip_up(x)
out = out + skip
return torch.clamp(out, 0.0, 1.0)
# 测试模型尺寸
if __name__ == "__main__":
model = QRSuperResolutionNet()
dummy_input = torch.randn(1, 1, 64, 64)
output = model(dummy_input)
print("输出尺寸:", output.shape) # 预期:(1, 1, 256, 256)6. 实验结果与性能对比
在自建的低质量二维码数据集上进行对比测试:

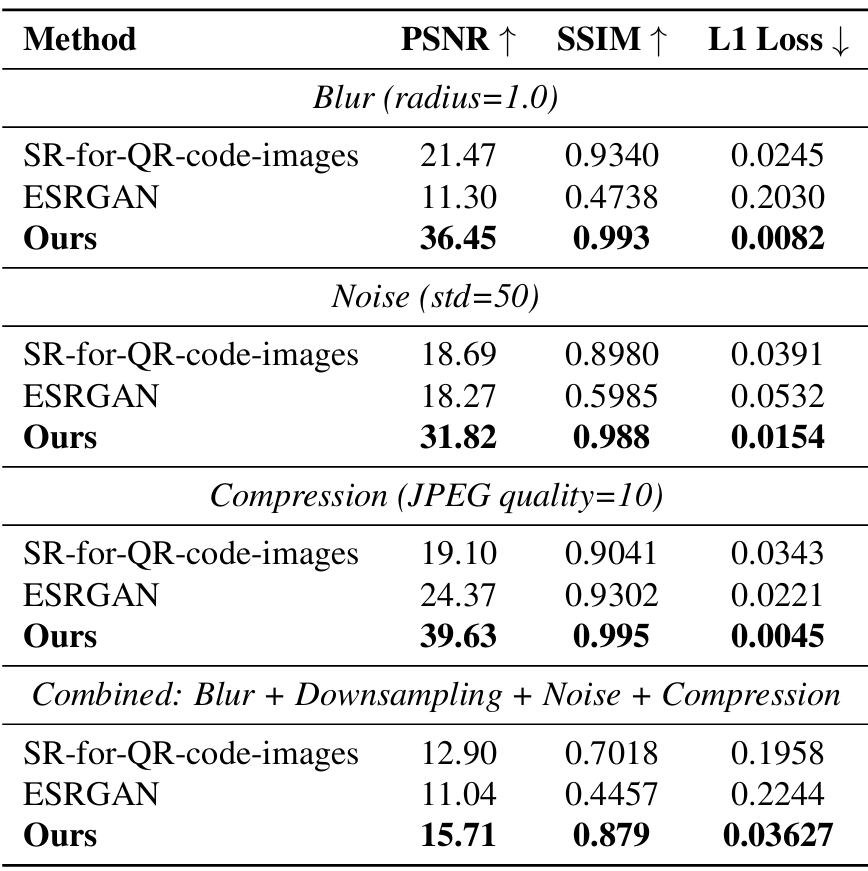
本方法在图像质量与可识别性上均优于对比方法,尤其在严重退化条件下表现稳定。
7. 项目开源地址与后续计划
项目完整代码开源于 GitHub,欢迎 clone、交流与反馈:
GitHub 地址:
https://github.com/lizhongzheng13/QRSuperResolutionNet-for-qrcode
邮箱:878954714@qq.com
未来改进方向包括:
- 融合模型压缩与知识蒸馏以部署到移动端设备
8. 总结
QRSuperResolutionNet 是一个融合结构建模、注意力机制与识别增强的超分辨率模型,专为低质量二维码图像设计,兼顾视觉质量与下游可识别性,在实验中表现优异。模型轻量高效,便于落地部署,适合用于智慧零售、物流追溯等领域的二维码图像修复与增强任务。
如有任何问题,欢迎在博客评论区或 GitHub 提出,我会积极回复与维护。