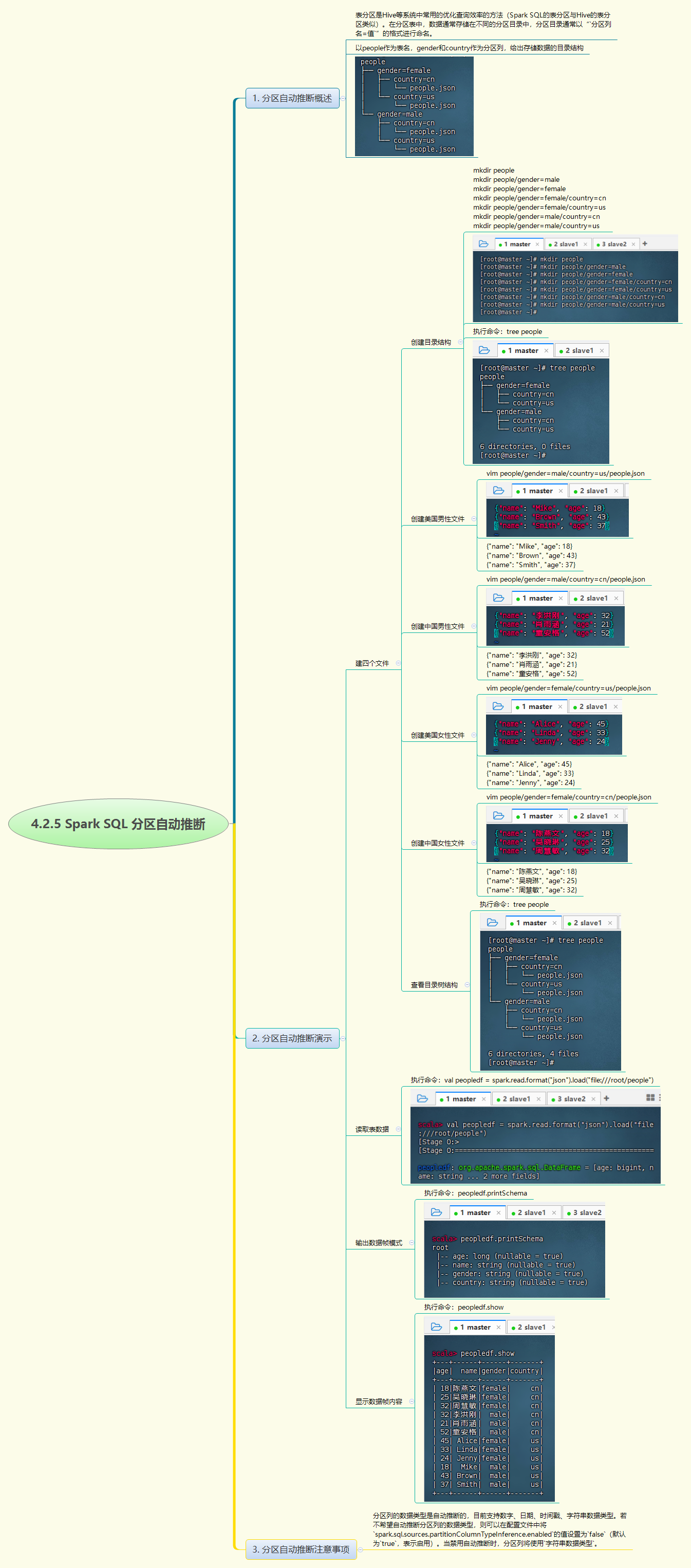
在本节实战中,我们学习了Spark SQL的分区自动推断功能,这是一种提升查询性能的有效手段。通过创建具有不同分区的目录结构,并在这些目录中放置JSON文件,我们模拟了一个分区表的环境。使用Spark SQL读取这些数据时,Spark能够自动识别分区结构,并将分区目录转化为DataFrame的分区字段。这一过程不仅展示了分区自动推断的便捷性,还说明了如何通过配置来控制分区列的数据类型推断。通过实际操作,我们加深了对Spark SQL分区管理的理解,并掌握了如何利用分区来优化数据处理流程,从而提高数据处理的效率和性能。