目录
[1.1 用户定义的变量](#1.1 用户定义的变量)
[1.1.1 添加及引用方式](#1.1.1 添加及引用方式)
[1.1.2 测试得出用户定义变量的特点](#1.1.2 测试得出用户定义变量的特点)
[1.2 用户参数](#1.2 用户参数)
[1.2.1 概念](#1.2.1 概念)
[1.2.2 位置不同效果不同](#1.2.2 位置不同效果不同)
[1.2.3、用户参数的勾选框 - 每次迭代更新一次](#1.2.3、用户参数的勾选框 - 每次迭代更新一次)
[1.3 csv数据文件参数化](#1.3 csv数据文件参数化)
1、脚本参数化
在编写Jmeter脚本的时候,很多数据是不能写死固定的,比如注册的手机号码,那些做了唯一性检查的参数。此时我们就需要进行参数化,这样的值就可以动态发生变化。
重复调用的数据也建议参数化:避免修改的时候多次修改。
参数化: 先不写具体的值,然后使用变量先代替。
定义参数的方法有四种:
用户定义的变量
用户参数
csv数据文件参数化
属性:后边我们讲到函数的时候再着重说
1.1 用户定义的变量
1.1.1 添加及引用方式
添加方式1:在测试计划中直接创建
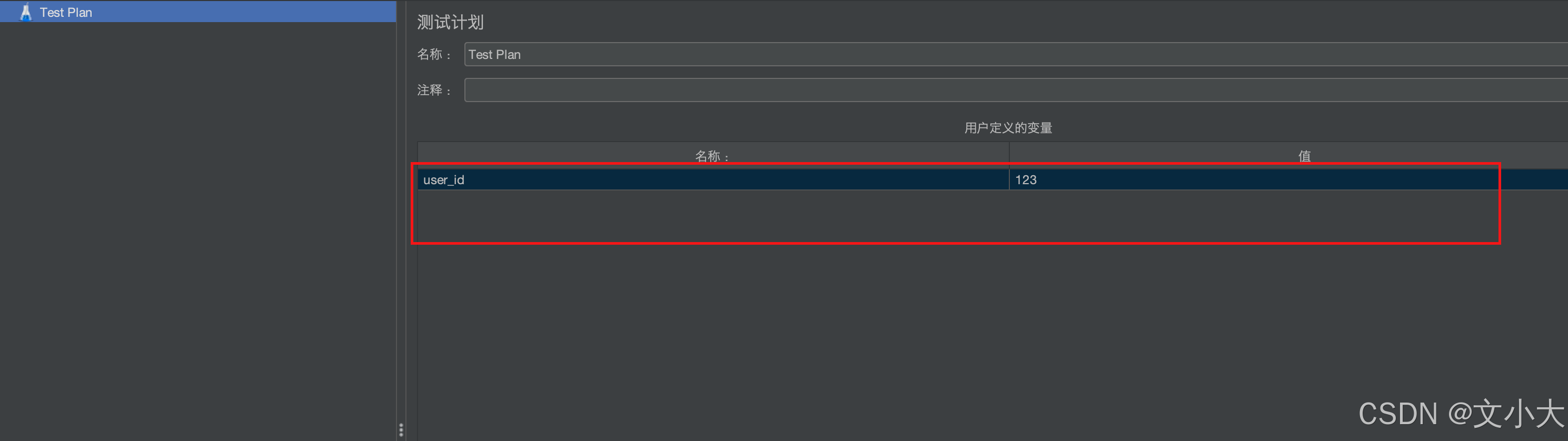
添加方式2:配置元件 -> 用户定义的变量
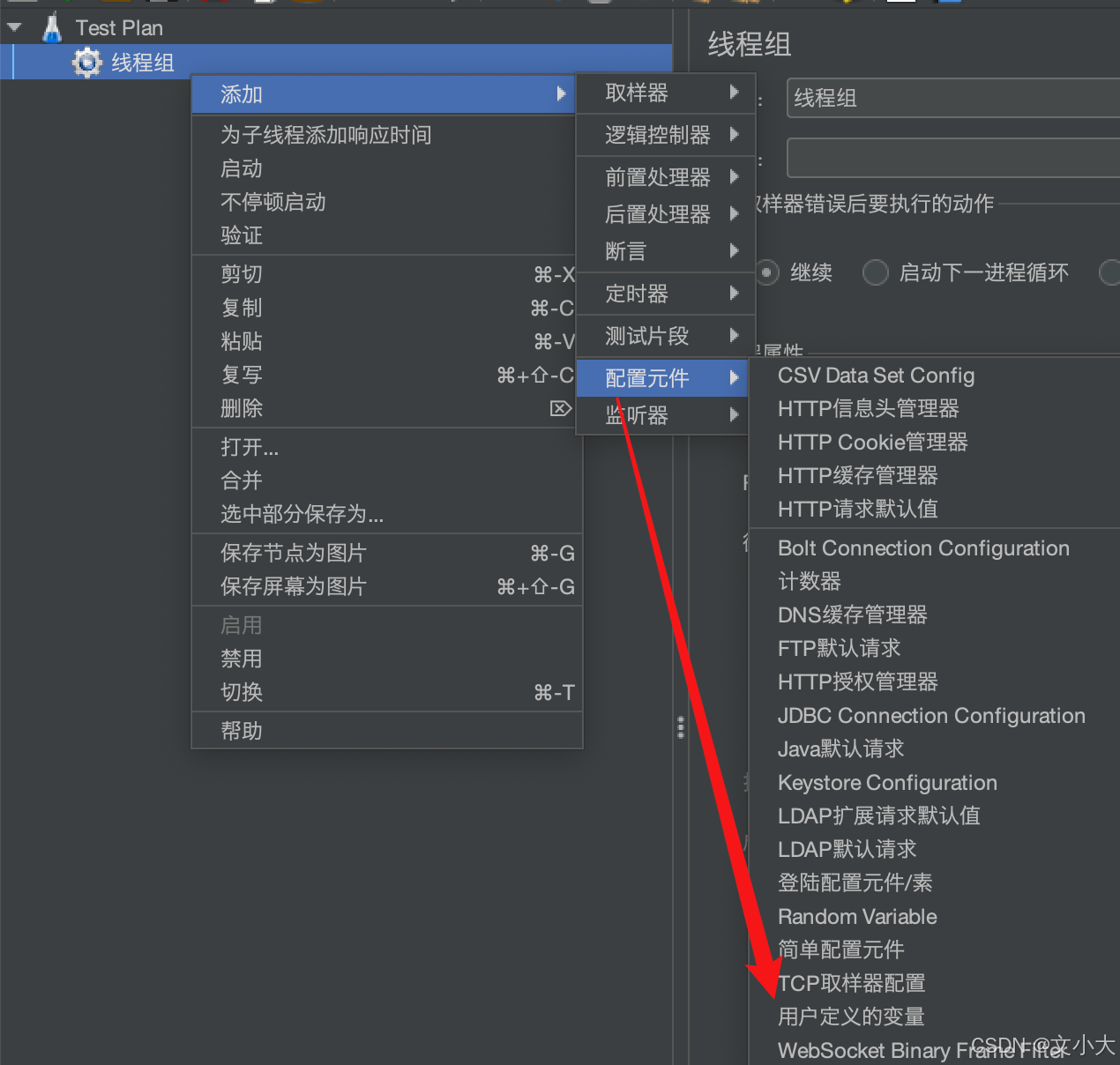
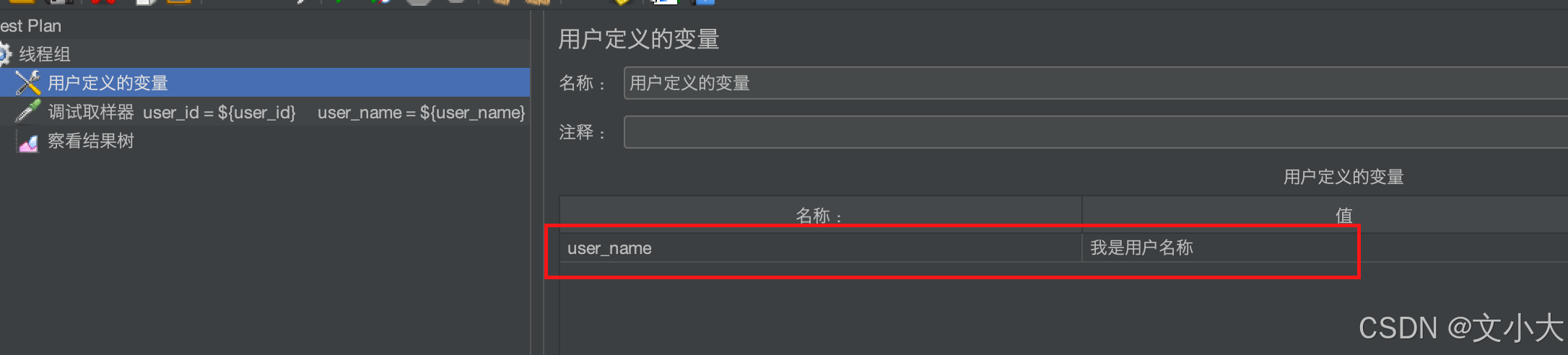
引用方式:${变量名} 变量名命名包含数字字母下划线
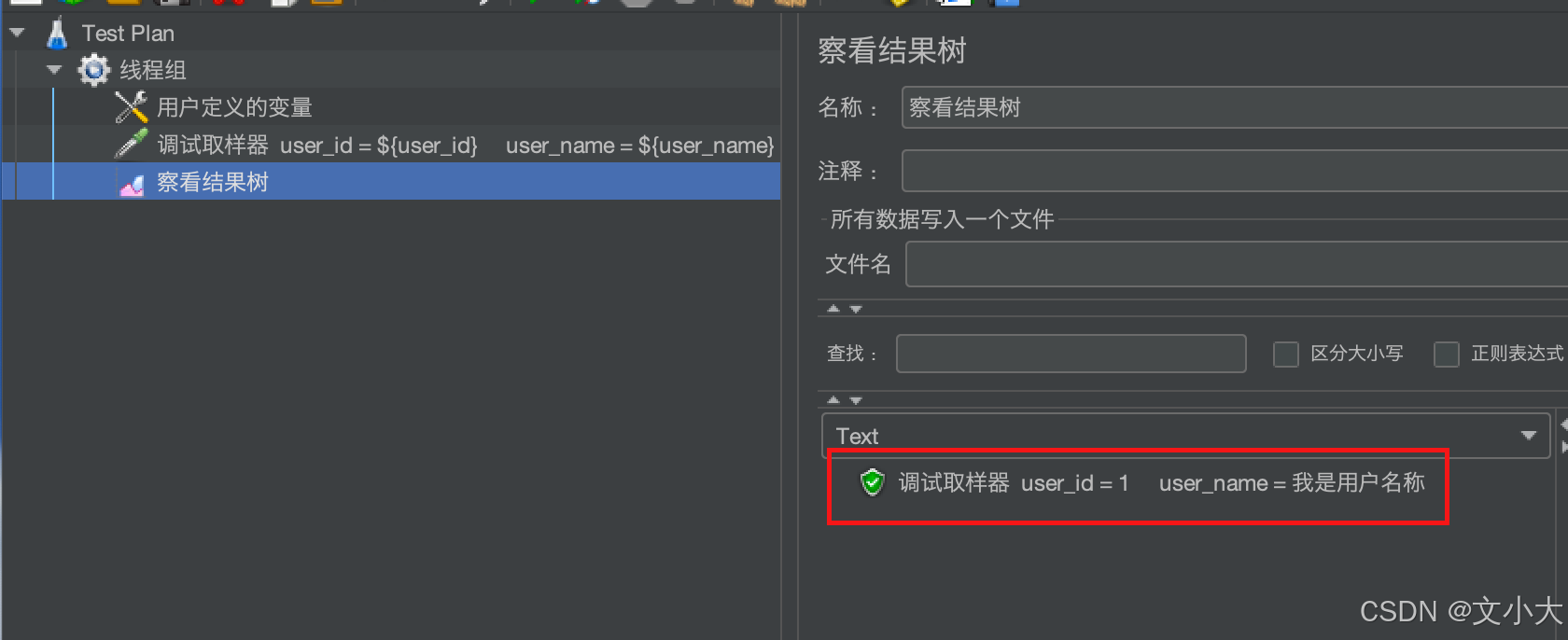
我们可以使用调试取样器查看变量的引用结果, 按照下图添加
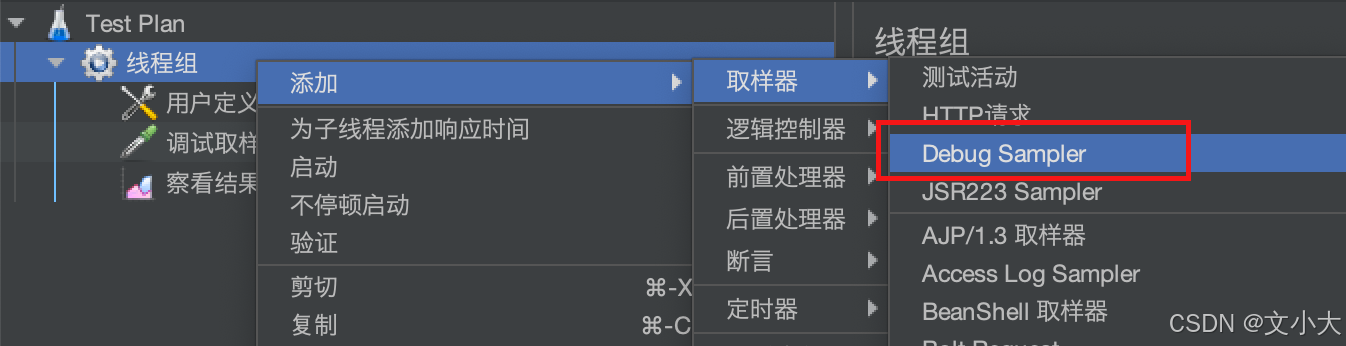

运行后我们可以看到,引用的参数已经被替换成具体的值
1.1.2 测试得出用户定义变量的特点
首先我们替换刚刚的值为一个随机数(具体的生成会在函数中讲,这里大家先用这个)
替换我们在测试计划中创建的user_id
在000-999之间随机生成3位数
${__Random(000,999,)}

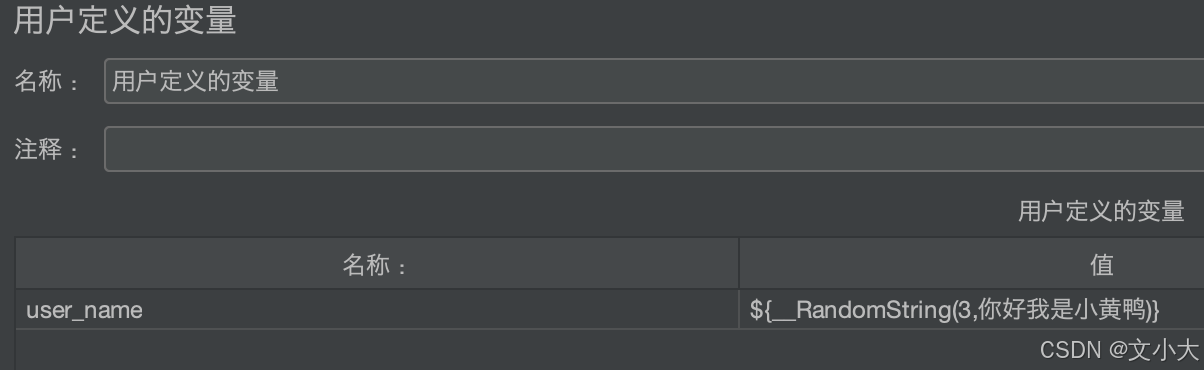
替换我们在线程组中创建的user_name
在"你好我是小黄鸭"中随机生成3个字
${__RandomString(3,你好我是小黄鸭)}
场景一:单个用户功能测试
运行后得到结果:我们只得到一个值,如果是用户注册,则每次都是新的数据,每次都可以成功获取。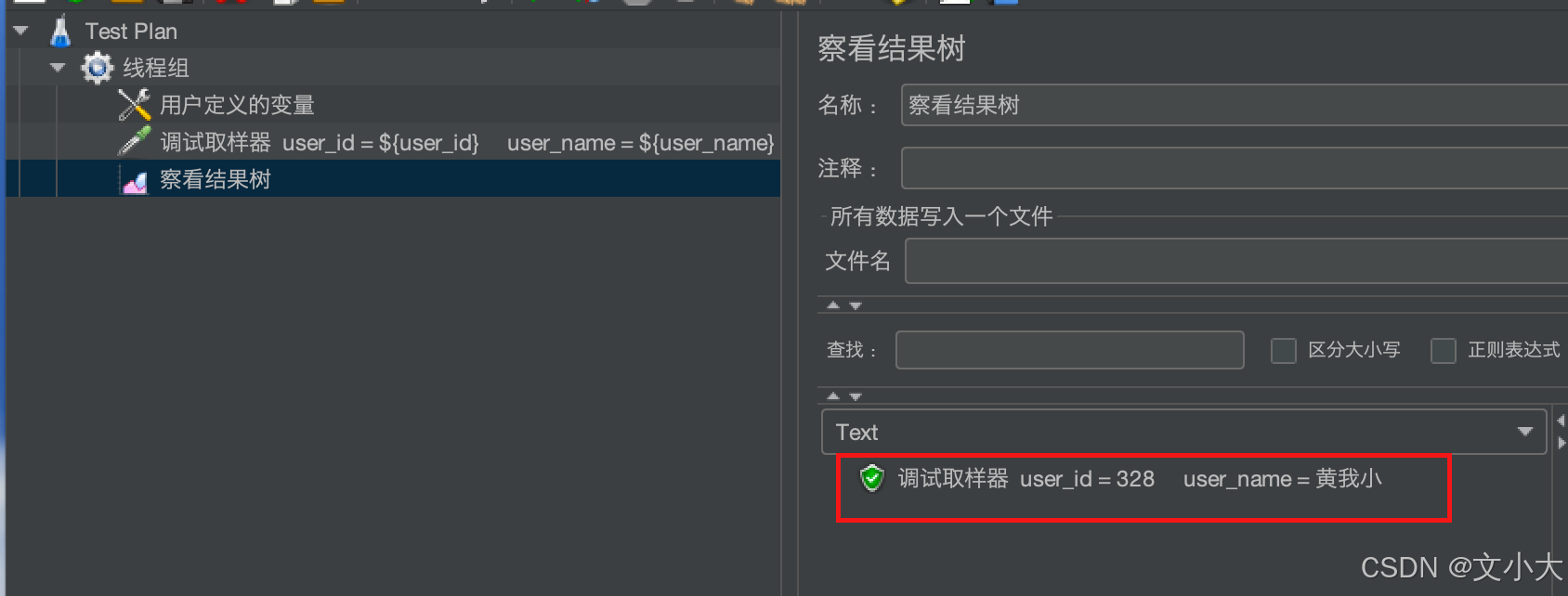
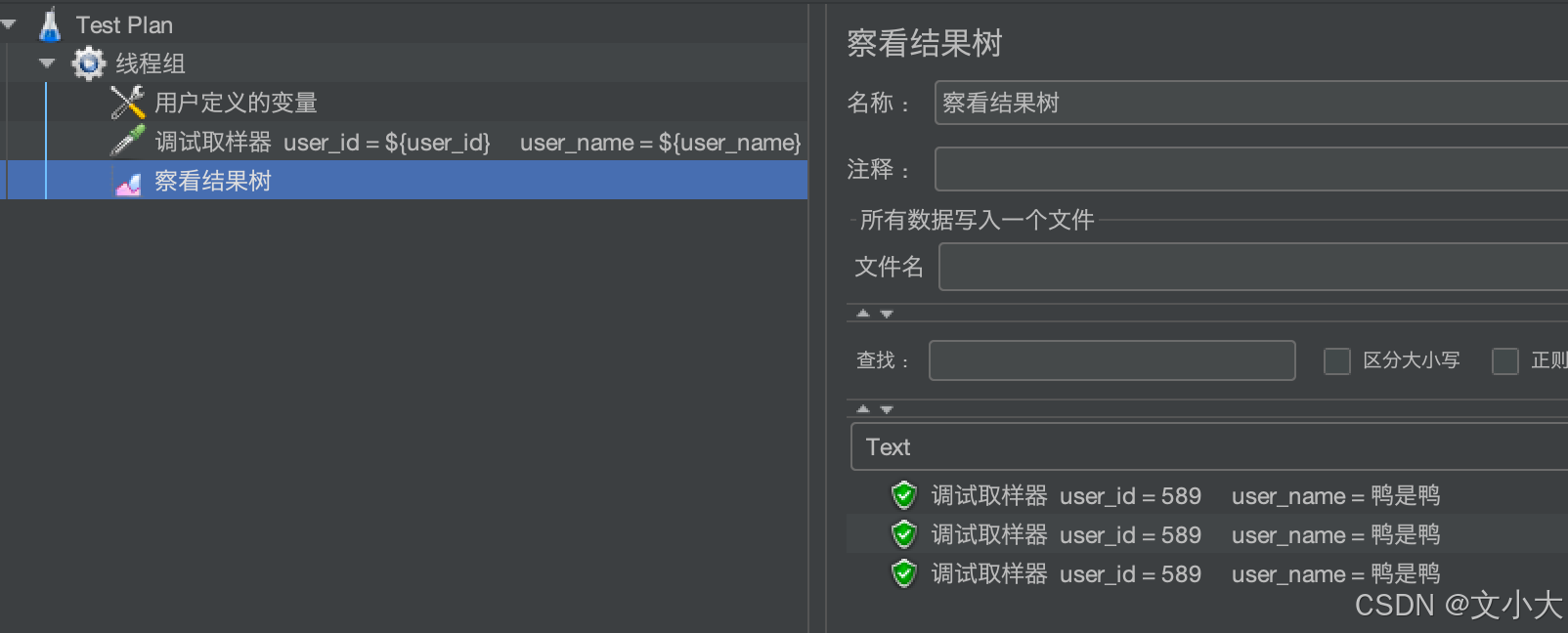
场景二:并发用户(多线程)测试
运行后结果:多个并发用户数一次运行的结果都是一样的,如果是用户注册那只会有第一个用户是成功的,后边的用户都hu失败,因为用户已经存在了
场景三:多个线程组
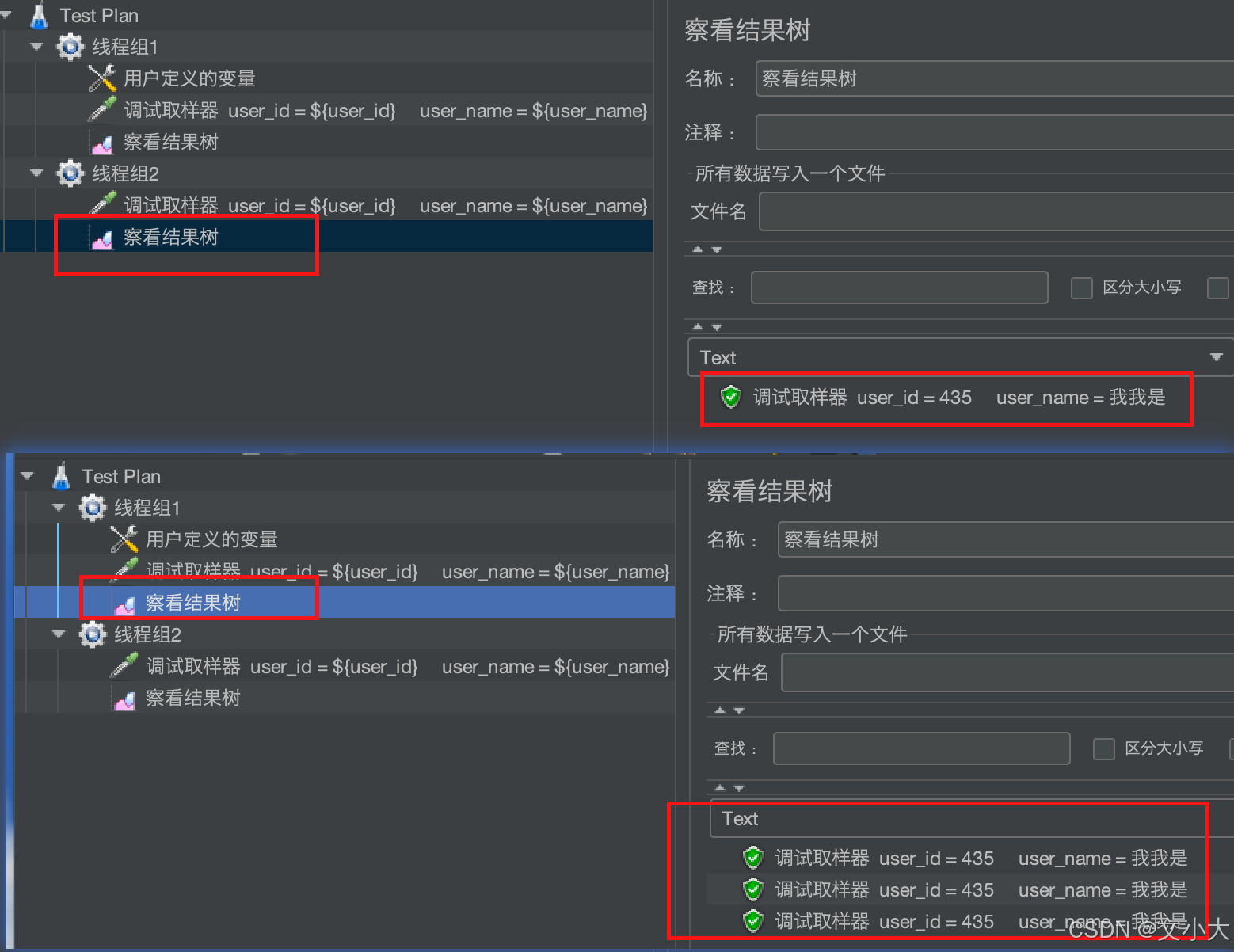
场景:我们新建线程组2,但是不定义用户定义的变量,直接在调试取样器中调用user_name
运行后结果:线程组1、线程组2得到的结果是一样的。 线程组2在没有定义"user_name"的情况下,直接引用也得到了值
++通过上述测试得出用户定义变量的特点总结:++
++1、每次启动值都会变一次,运行过程中不会改变值;所以在性能测试中很少用,因为不符合性能需求,一个用户不可能在系统中同一时间既登录有下单的,++
++2、用户定义的变量可以跨线程组使用,一次定义全局使用。++
1.2 用户参数
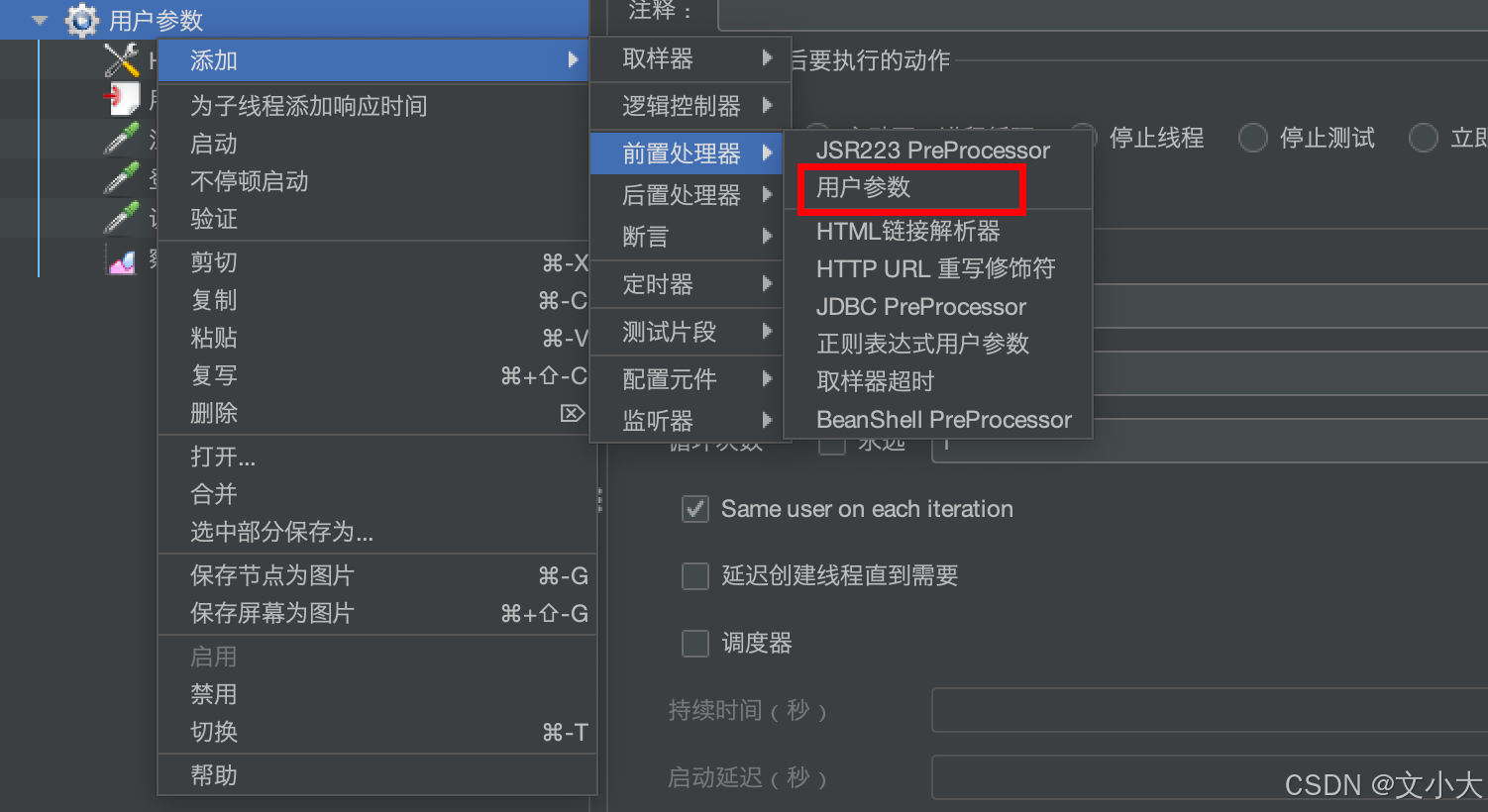
1.2.1 概念
作为前置处理器,每次接口请求之前都会调用执行这个用户参数;在性能测试时多个并发用户数同时运行请求,用户参数的值针对每个并发用户会动态变化。
1.2.2 位置不同效果不同
注:大家可以自己动手使用登录注册接口实操一下
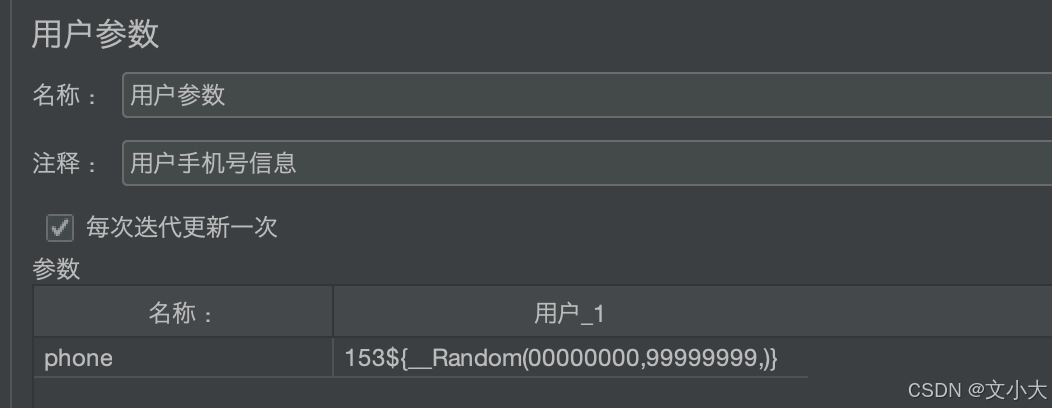
1、如果用户参数放在线程组下,里面所有的请求都会每次去调用:作用域是整个线程组,下面的取样器都可以使用,那么每个取样器每次都会拿到新的值。
引入问题: 注册新用户可以成功 但是登录也是新的用户没注册过就会报错;
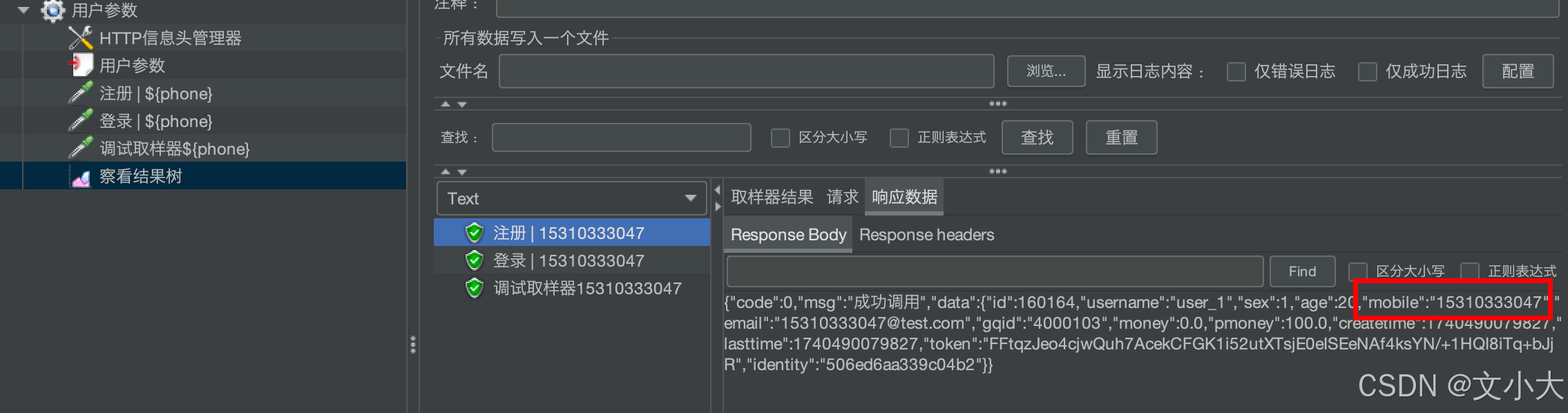
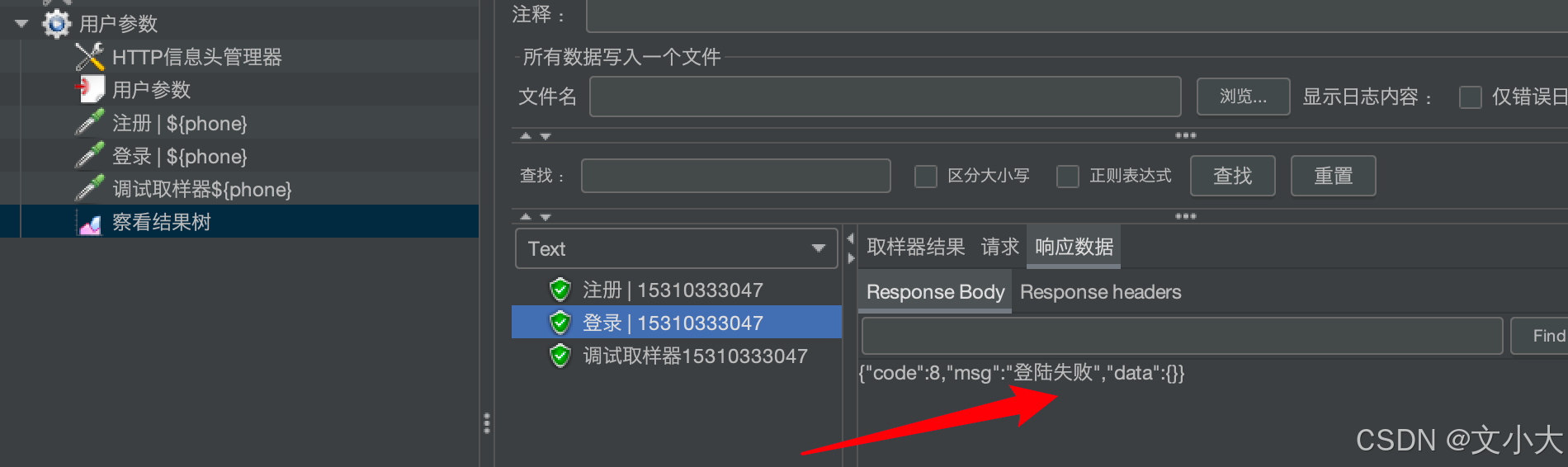
2、如果放在某个接口下面,作用域就是这个接口,只有这个接口执行前会调用,其他接口执行之前不会调用执行这个前置;
因为前置处理器在注册之前会调用,生成值保存在变量里;登录没有这个用户参数,就不会调用生成新数据,可以直接调用之前存的变量的值
1.2.3、用户参数的勾选框 - 每次迭代更新一次
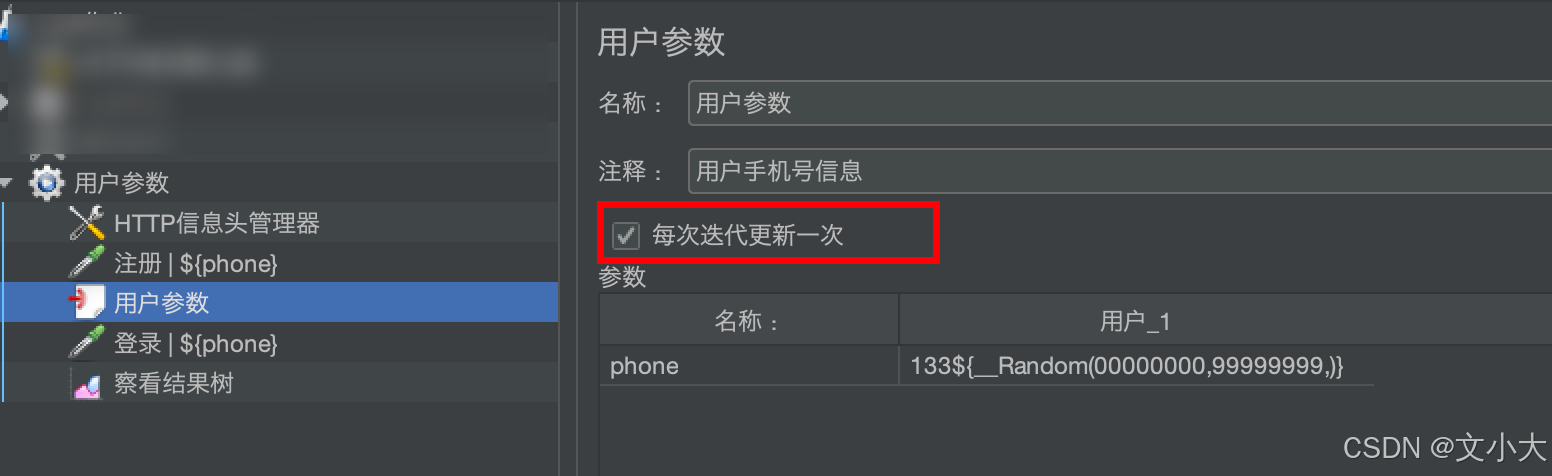
迭代:线程组下所有的取样器执行一次,算一次迭代完成。
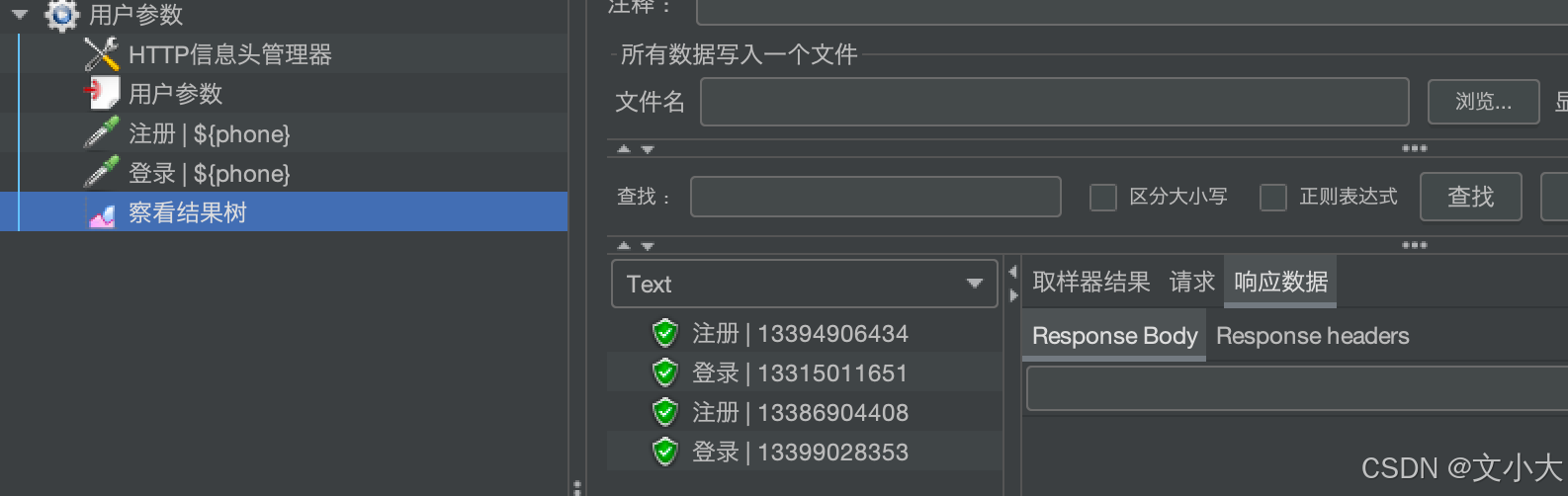
默认:为不勾选,每个请求都会执行一次用户参数。(如:下边4次请求,执行了四次用户参数)
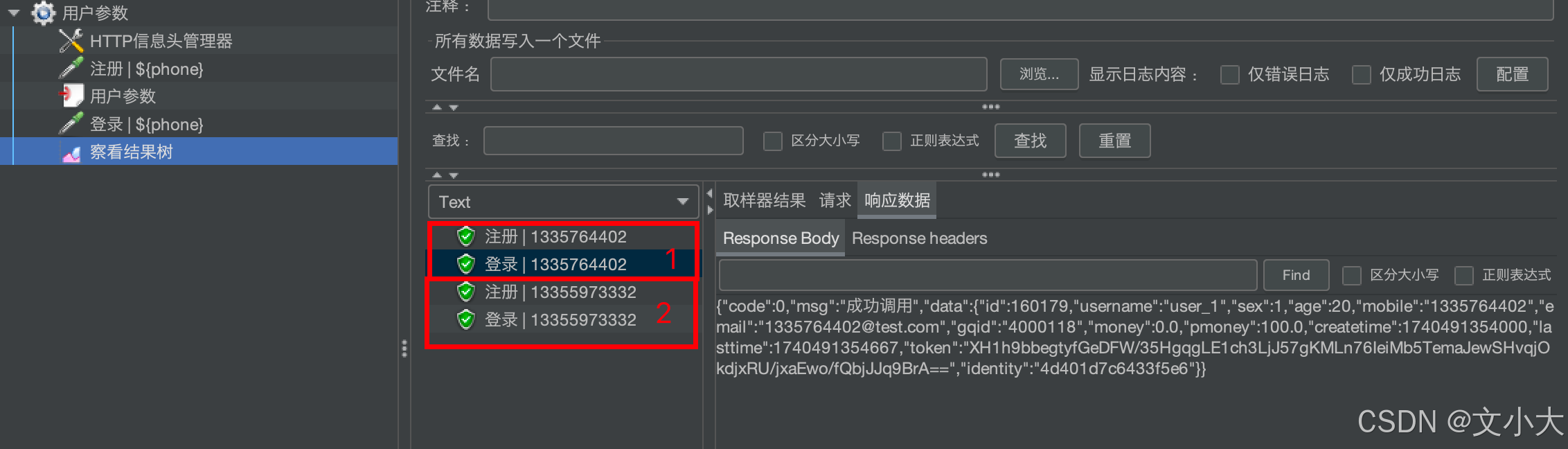
勾选:一次迭代只执行一次用户参数,下次迭代时再执行第二次。(如下两次迭代)
总结用户定义的变量、用户参数
1、用户定义的变量:可以跨线程组被引用;用户参数不能夸线程组、只能作用于当前线程组
2、用户定义的变量,在每次启动运行的时候会获取一次值,在运行过程中值永远不会变。【循环和用户并发都不会变】;用户参数在每次运行时,都会动态获取值,每次调用的时候就会改变值;如果希望不要变化,就勾选每次迭代更新一次;或者放在第一个取样器下面就会调用一次。
3、重点掌握用户参数的时候用 因为性能里用户定义变量用很少。
4、用到的大部分的变量 - 后置处理器等都是用户参数类型变量不能跨线程使用。-- 后面通过属性实现
1.3 csv数据文件参数化
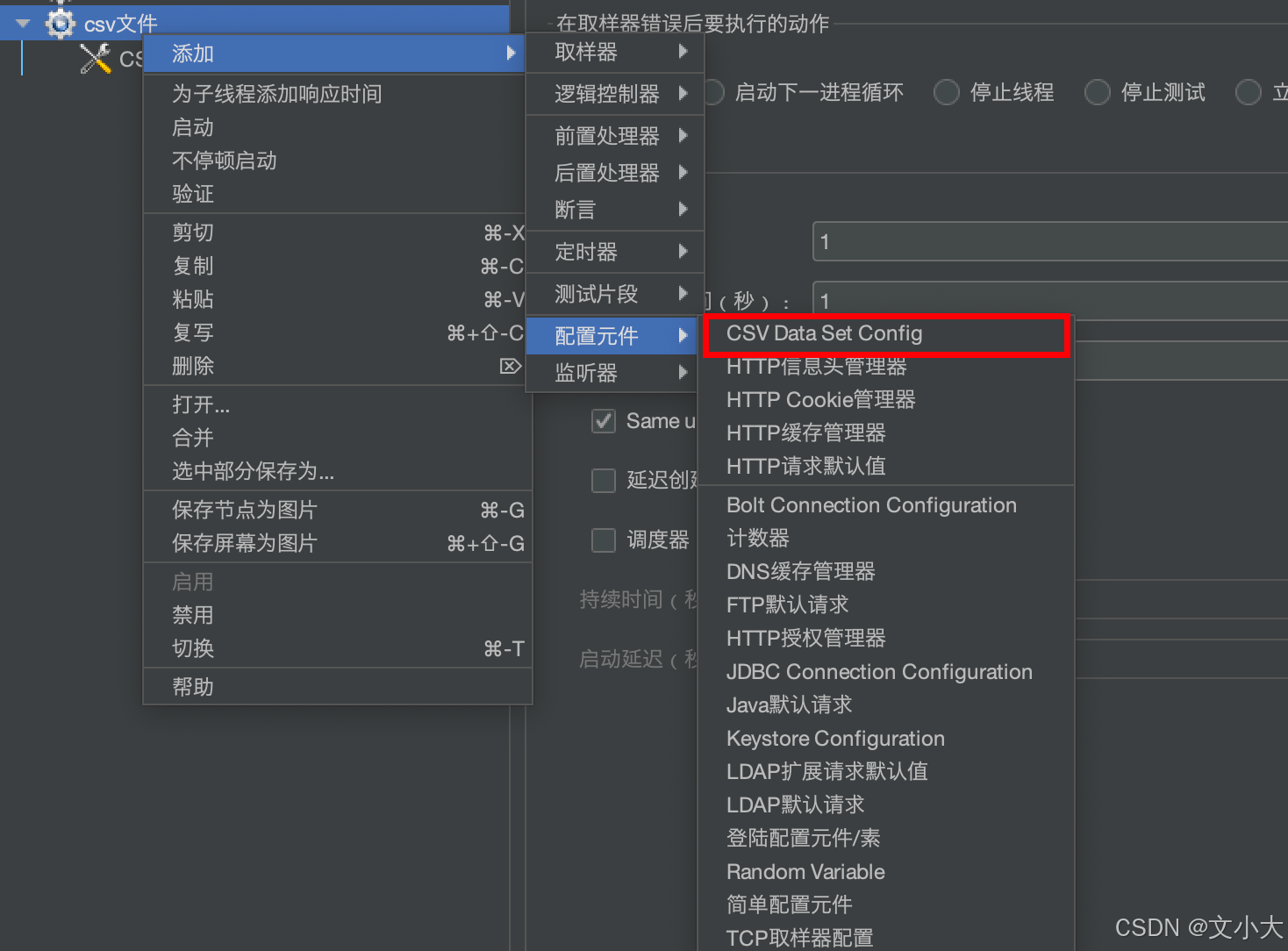
注:配置元件中添加,配置元件执行优先级最高,如果出错了后边不会运行,可能看不到查看结果数的结果(可以在工具日志里看到报错信息)
1.3.1 基础概念
使用场景:批量执行并需要构造真实数据的时候,可以从数据库里导出数据到CSV文件中,接口通过CSV文件批量进行操作。
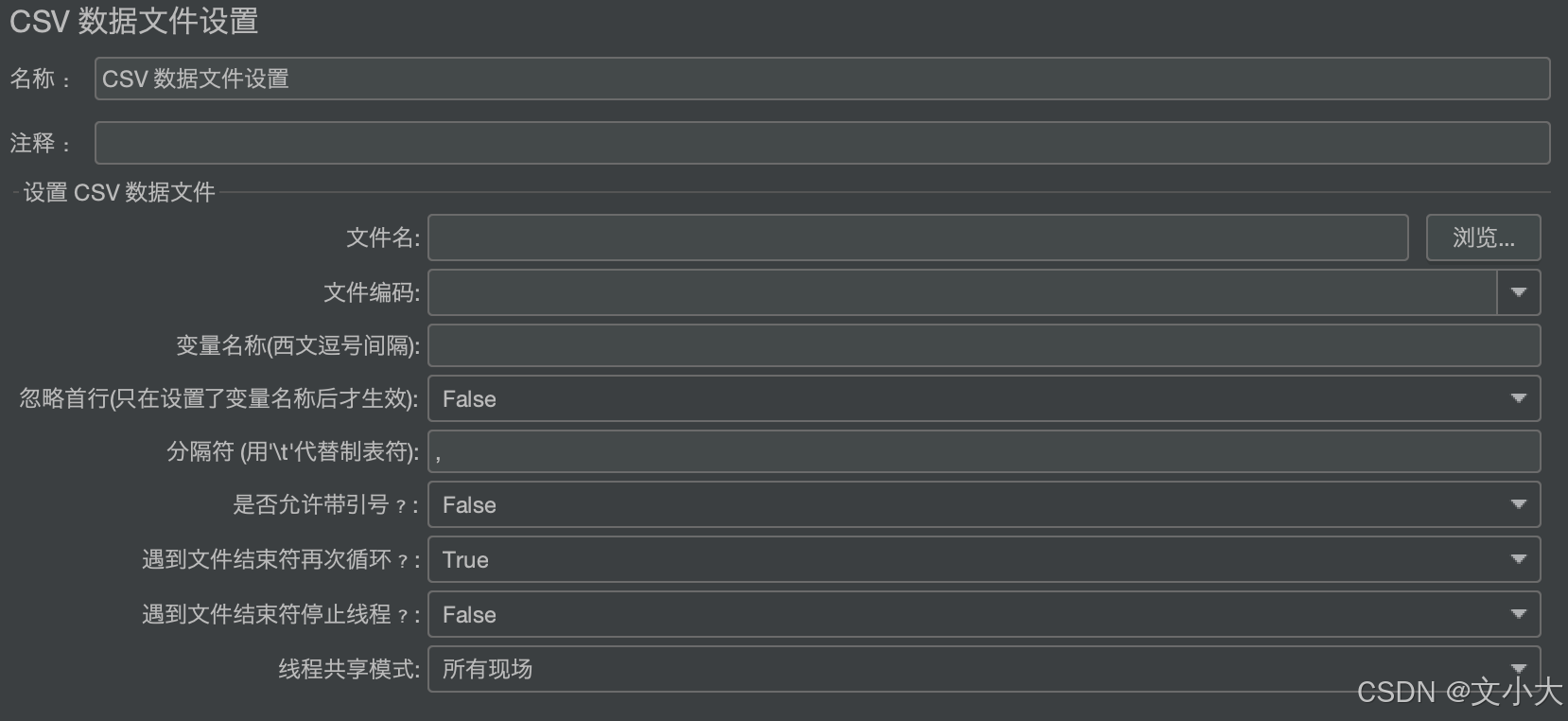
元件的每个配置解释:
文件名:可以写绝对路径(浏览选择文件),也可以写相对路径(相对的起始点是jmx文件的位置)
1、相对路径: 相对的起始点是jmx脚本的位置 | 或者jmeter的bin文件目录两个都可以,所以写的文件名会默认去这两个目录下找这个csv文件;
2、推荐使用相对路径
3、如果写绝对路径,会自动适配/ 和\路径盘符,因为适配各个平台【win和mac】路径 【但是换台机器容易找不到文件】-- D:/apache-jmeter-5.2.1/bin/testdata.txt
4、文件是支持多种格式: txt 、csv 等
文件编码:由选择的文件自身编码来选择
1、csv文件,字符集编码不一定是utf8。如果csv文件自身不是utf8编码的,而jmeter中csv选的字符集选择了utf8,可能出现中文字符集不同而导致乱码;
2、如果我们用数据的文件是 csv,数据又有中文,Jmeter获取数据的时候已经出现乱码了,用notepad++把csv文件打开,切换字符编码为utf8或者重新保存的时候选择编码为utf8。
3、使用csv文件容易产生乱码现象。所以我们一般建议文件选择用 txt;默认就是utf8编码
变量名称:自己定义变量名,多个时候用英语的逗号隔开,这个逗号是固定的,与文件种的列分隔符没有关系
1、如果第一个变量接受第一列,第二个变量接受第三列,中间写逗号 + 空格【name, ,pid 】
2、这个变量名就可以被后续的接口调用 ${name} ,拿到 csv 文件里对应列的值。
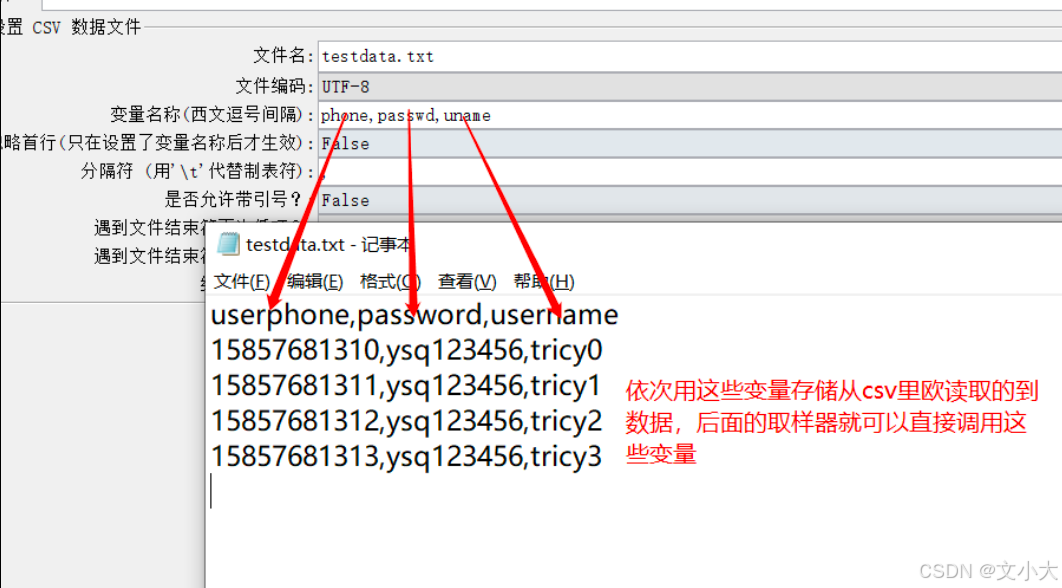
忽略首行:True不要第一行,False要第一行(表头去掉的时候选True)
分隔符:就要看你读取的文件的列与列的分隔符号(tab就是制表符\t;空格,默认csv文件是英文逗号)
是否允许带引号:这个只能是txt文本操作,csv文件不会生效
1、False: 不允许带引号, 如果有引号就会当做数据的整体组成部分 "1344555555"
2、True :允许带引号 , 如果有引号就会自动去掉引号。
遇到文件结束符再次循环吗?
1、True: 是的,继续循环,继续循环取文件中值。当文件内容从头到尾,全部都取了1次值之后,再从头开始取值。
2、False: 不,不再循环取值,如果还要用值,就是一个空值。 如果遇到数据是EOF数据 要检查这个地方配置 + 数据库行数 +检查文本之后是否有空行。
遇到文件结束符停止线程吗?
1、True: 是,停止线程,jmeter就会 停止运行。
2、False :不,继续运行, jmeter 还会继续跑
3、如果上面的两个配置冲突了 以上面的配置为准。后面配置失效。
以下是默认配置

线程共享模式:
所有现场(所有线程):所有线程共享,不管jmeter有多个线程组,总共有多少个线程,所有的线程都共用一份文件
1、所有的线程,在使用这个文件的时候, 排队使用文件中的数据。【第一个线程使用第一行,依次排列取值】
2、当2个线程组共享这个CSV文件: csv放测试计划下共享,否则不能跨线程组。
3、两个线程组执行: 几乎同时执行
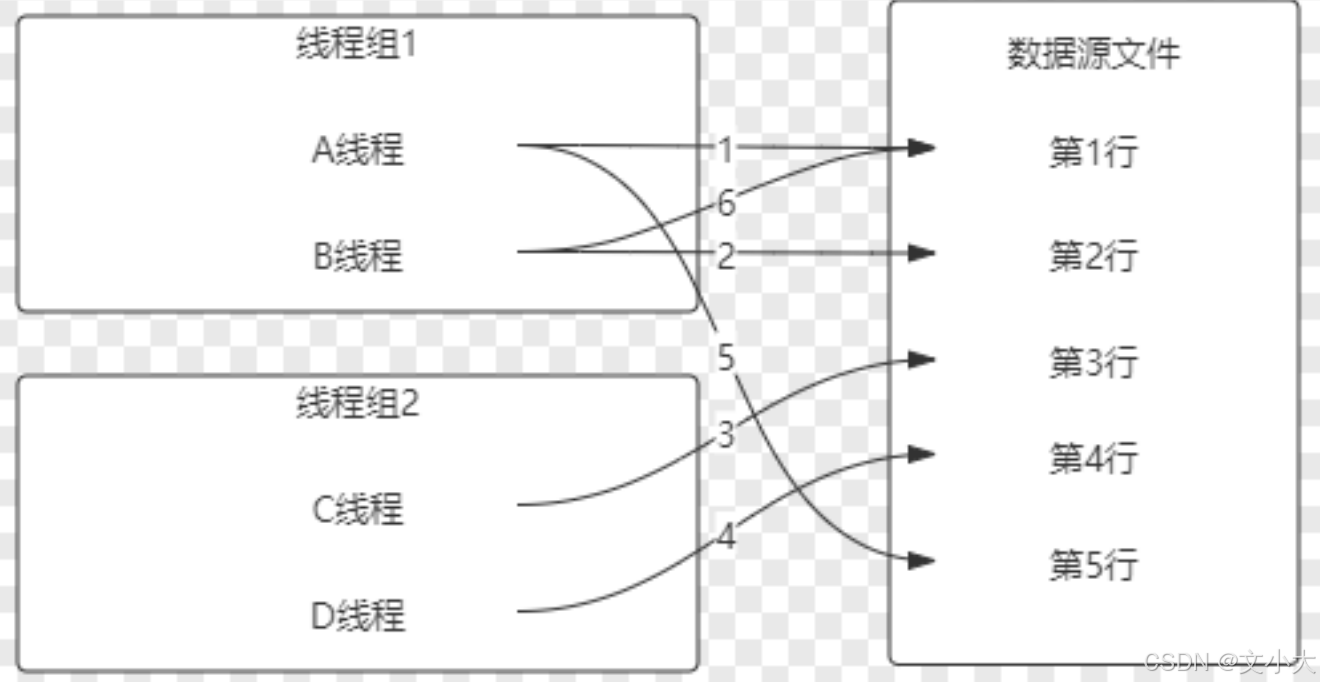
当前线程组:这个线程组的所有线程,共用一份数据。有多个线程时,有n个线程组那么内存中就有n份相同的数据。
单独线程组里单独读取自己内存的数据。不会混用。每个线程组都从头开始取。
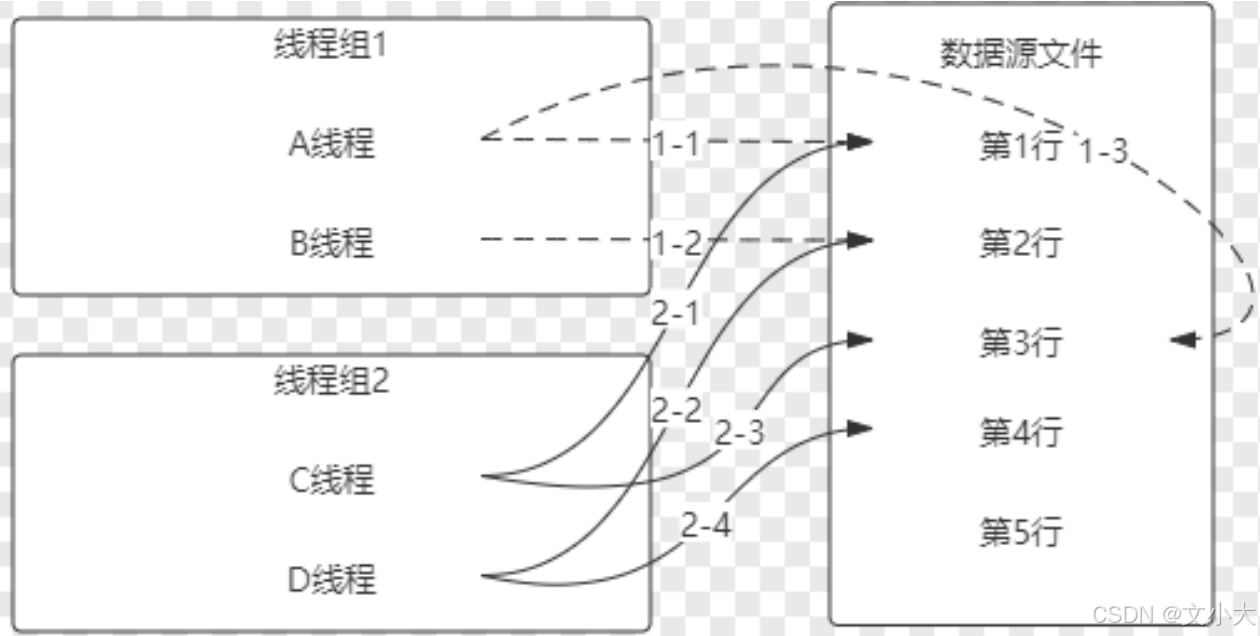
当前线程:每个线程(用户)私有一份,有n个线程,在内存中就有n份数据,运行中取值时都取自己的那一份,都是从头开始的。
如果设置循环,那么单个线程就会取第二行的值
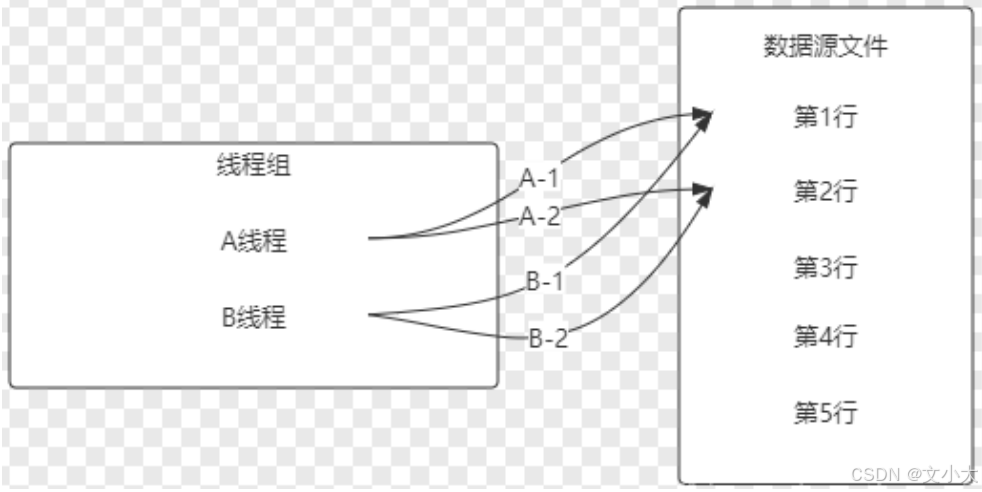
注:以上三种情况,最后一个【当前线程】选项占用内存最多。所以比较少用。