Perceive Anything: Recognize, Explain, Caption, and Segment Anything in Images and Videos

https://arxiv.org/pdf/2506.05302v1
Figure 1: Perceive Anything Model (PAM): PAM accepts various visual prompts (such as clicks, boxes, and masks) to produce region-specific information for images and videos, including masks, category, label definition, contextual function, and detailed captions. The model also handles demanding region-level streaming video captioning.

Abstract
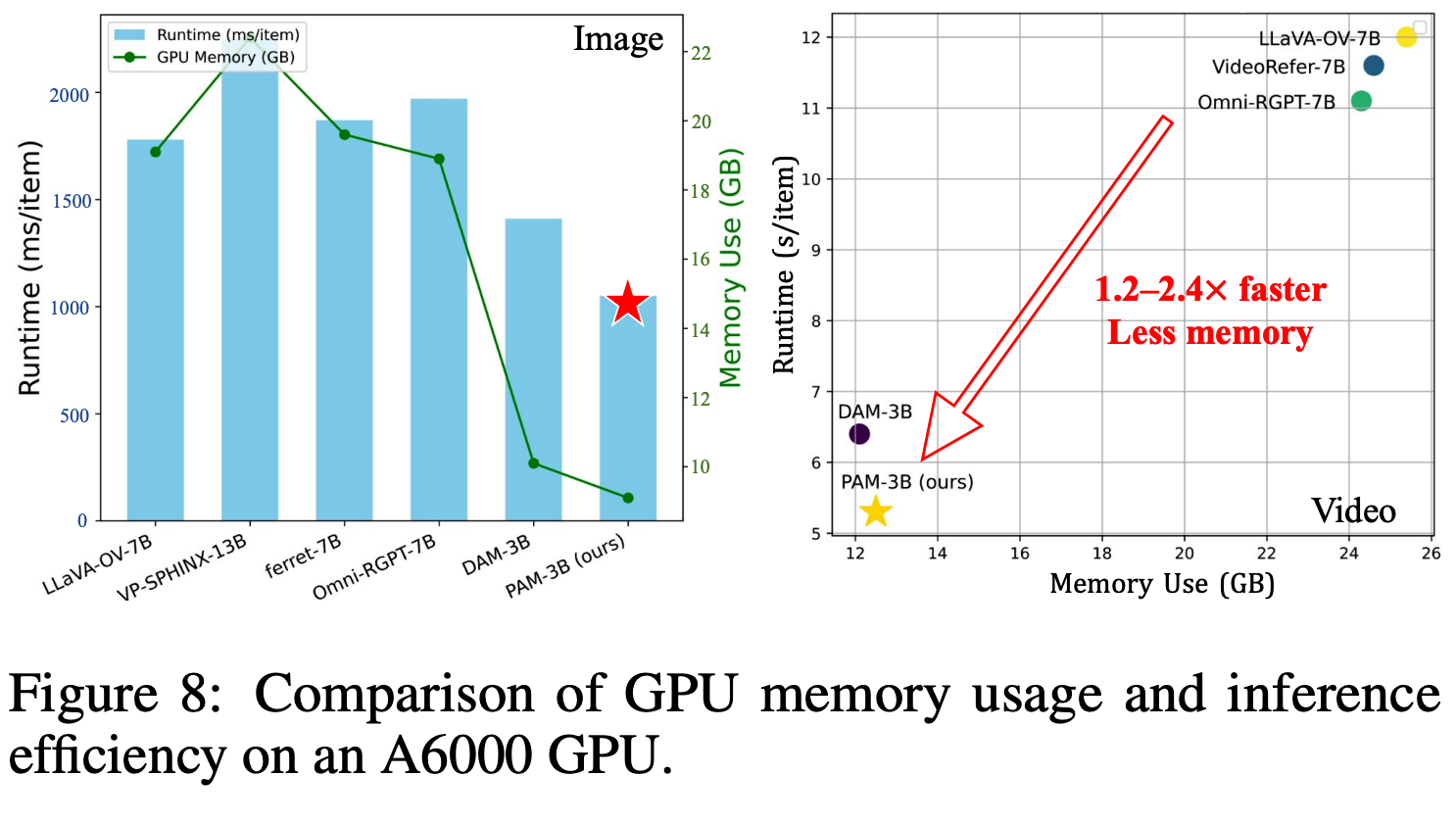
We present Perceive Anything Model (PAM) , a conceptually straightforward and efficient framework for comprehensive region-level visual understanding in images and videos. Our approach extends the powerful segmentation model SAM 2 by integrating Large Language Models (LLMs) , enabling simultaneous object segmentation with the generation of diverse, region-specific semantic outputs, including categories, label definition, functional explanations, and detailed captions. A key component, Semantic Perceiver , is introduced to efficiently transform SAM 2's rich visual features, which inherently carry general vision, localization, and semantic priors into multi-modal tokens for LLM comprehension. To support robust multi-granularity understanding, we also develop a dedicated data refinement and augmentation pipeline, yielding a high-quality dataset of 1.5M image and 0.6M video region-semantic annotations , including novel region-level streaming video caption data . PAM is designed for lightweightness and efficiency , while also demonstrates strong performance across a diverse range of region understanding tasks. It runs 1.2−2.4× faster and consumes less GPU memory than prior approaches, offering a practical solution for real-world applications . We believe that our effective approach will serve as a strong baseline for future research in region-level visual understanding.
本文提出了感知万物模型(Perceive Anything Model, PAM) ,这是一个概念上简洁高效、用于图像和视频全面区域级视觉理解 的框架。本文的方法通过集成大语言模型(Large Language Models, LLMs) 扩展了强大的分割模型SAM 2 ,使其能够同时进行目标分割 并生成多样化、区域特定的语义输出 ,包括类别、标签定义、功能解释和详细描述。本文引入了一个关键组件------语义感知器(Semantic Perceiver) ,它能高效地将 SAM 2 丰富的视觉特征(这些特征本身蕴含通用的视觉、定位和语义先验知识)转化为多模态 token ,以供 LLM 理解。为了支持鲁棒的多粒度理解 ,本文还开发了专用的数据精炼与增强流程 ,构建了一个包含150万张图像和60万段视频的区域-语义标注 的高质量数据集,其中包括新颖的区域级流式视频描述数据 。PAM 设计追求轻量化和高效率 ,同时在广泛的区域理解任务 上展现出强大的性能。与现有方法相比,其运行速度快 1.2−2.4 倍 ,消耗的 GPU 内存更少 ,为实际应用提供了实用的解决方案 。本文相信,这种高效的方法 将为未来区域级视觉理解的研究奠定坚实的基础(strong baseline)。
Code, model and data are available at: Perceive Anything: Recognize, Explain, Caption, and Segment Anything in Images and Videos
Introduction
视觉社区见证了视觉基础模型的飞速发展,例如 SAM 34 和 SAM 2 52 ,它们极大地提升了图像和视频中交互式目标分割 的性能。这些模型能够基于各种视觉提示(visual prompts) 以惊人的精度定位任意目标。然而,它们通常缺乏对分割区域的深层语义理解,阐明这些区域的含义或其上下文功能仍然是一个具有挑战性的问题。
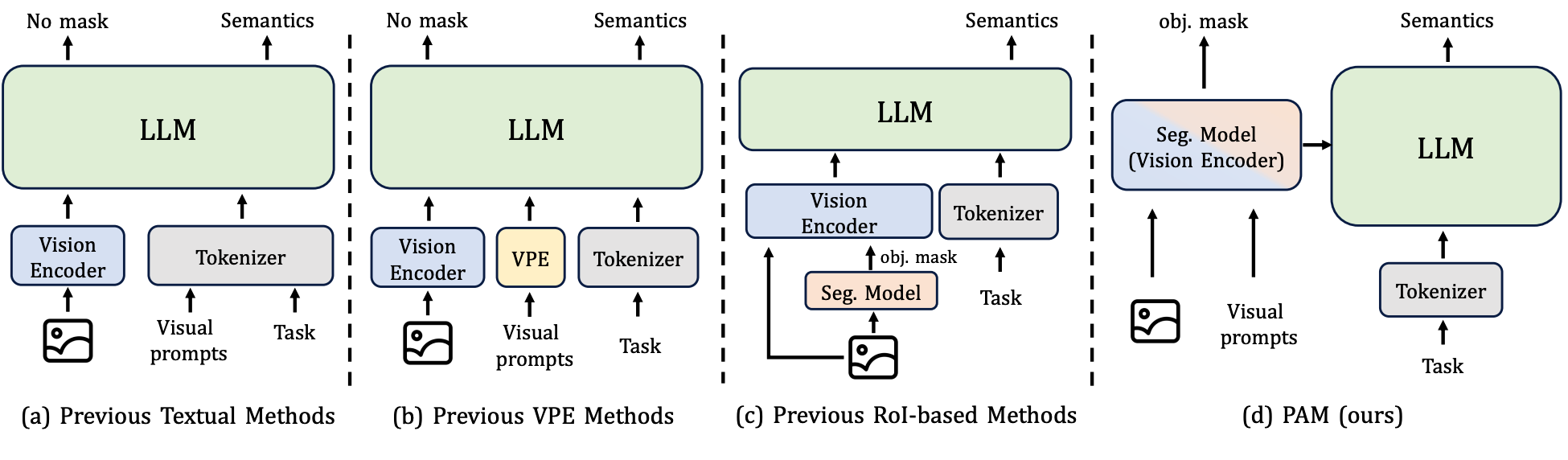
最近的研究试图通过视觉提示赋予视觉-语言模型(Vision--Language Models, VLMs)区域级理解能力 。如图 2 所示,当前的方法可分为三种范式:(1) 文本编码(textual encoding)63, 78, 86, 44 :将 2D 边界框坐标编码为提示词中的自然语言字符串,因此不提供显式的区域先验 ;(2) 视觉提示编码(visual prompt encoding, VPE)41, 51 :引入额外模块 来嵌入区域图像特征和位置特征;(3) 基于感兴趣区域/分割的编码(RoI/segmentation-based encoding)38, 77, 83, 80, 29 :利用外部掩码生成器 来拼接图像嵌入和掩码嵌入。尽管这些方法展现出潜力,但它们通常存在一些局限性:(i) 它们通常仅生成有限的语义输出 ------通常只是类别标签或简短描述 26, 88, 69, 67;(ii) 它们的设计是模态特定的 ,专注于单一视觉模态(图像或视频),泛化性有限 63, 78, 77, 80, 81;(iii) 它们依赖外部分割模型 来提供掩码,这种串行设计增加了计算开销 ,并使整体性能对掩码质量敏感 80, 81, 38。
Figure 2: Previous Paradigms vs. Our Paradigm (PAM). (a & b) Textual/VPE methods provide region understanding using positional embeddings but typically lack simultaneous object masks. (c) RoI/Segmentation-based methods use external segmenter for object masks, subsequently fusing image and mask embeddings. (d) In contrast to previous paradigms, our method directly treats the Seg. model as vision encoder. It effectively leverages the rich visual embeddings from the robust segmentation model and features a parallel design for its mask and semantic decoders.
为了应对这些挑战,本文提出了感知万物模型(Perceive Anything Model, PAM) ,这是一个端到端的区域级视觉-语言模型 ,旨在实现快速且全面的细粒度视觉理解 ,适用于图像和视频,其能力包括预测类别、解释识别出的区域元素的定义和上下文功能,以及生成特定区域的详细描述。本文的方法并非从头开始重新设计模型架构,而是高效地扩展 SAM 2 框架 ,结合大语言模型(Large Language Models, LLMs) 来支持语义理解。具体来说,本文引入了一个语义感知器(Semantic Perceiver) 作为关键桥梁,它有效利用 SAM 2 骨干网络丰富的中间视觉特征 ,将通用的视觉、定位和语义先验知识 整合到视觉 token 中。这些 token 随后由 LLM 处理 ,以生成多样化的语义输出 。此外,PAM 采用了并行设计 用于其掩码解码器 和语义解码器 ,能够同时生成区域掩码和语义内容 ,从而提高计算效率。
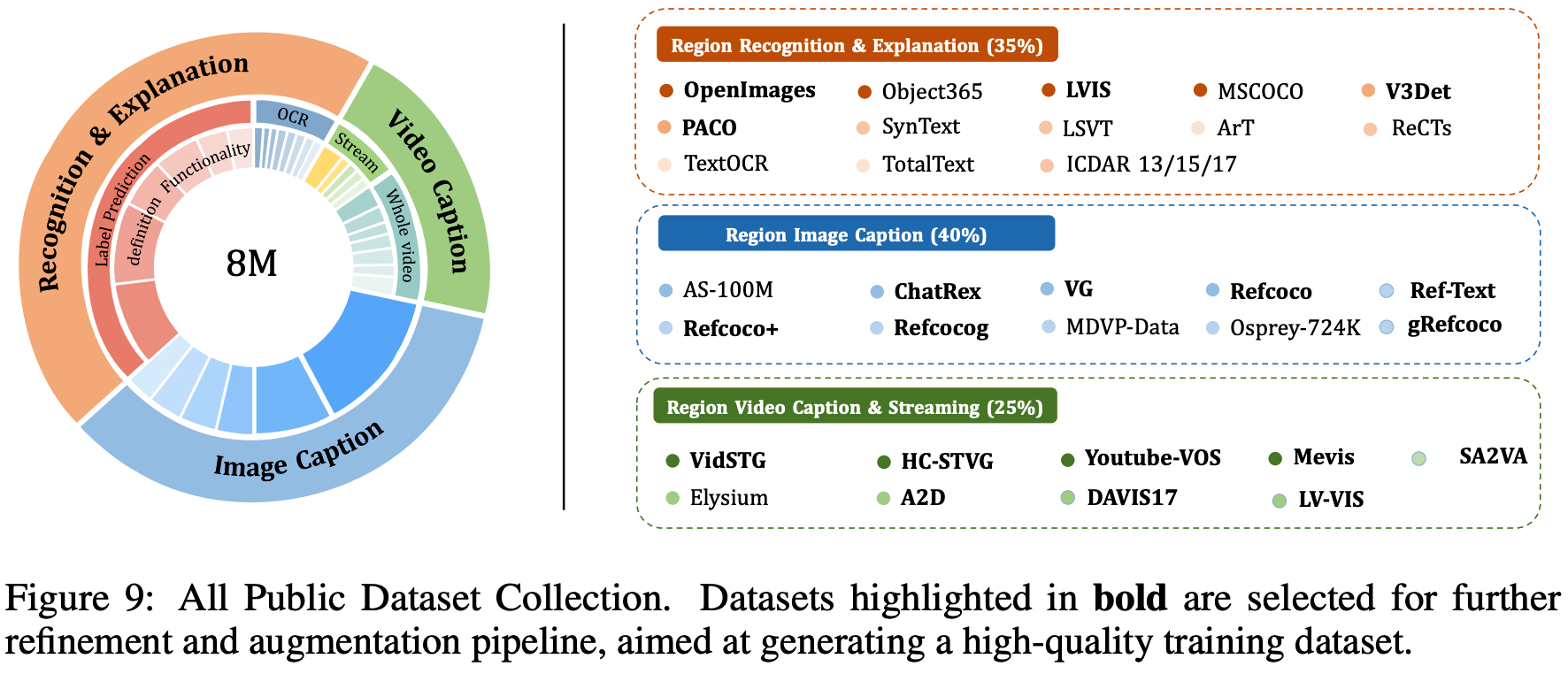
为确保 PAM 在理解区域级多维语义粒度方面的鲁棒性,高质量的 训练数据至关重要。虽然多个现有数据集 6, 32, 36, 43, 29, 68 提供了区域语义标注,但作者注意到它们通常 过于粗糙**,限制了其用于细粒度理解任务的效用。因此,为构建高质量的训练数据,本文开发了一个先进的** 数据精炼与增强流程**。该流程利用领先的** 视觉语言模型(VLMs,例如 GPT-4o 27)和人类专家验证来精炼和增强现有的区域级标注数据集。
-
对于图像 :为每个特定区域生成多个不同语义粒度 的标注:一个细粒度的类别标签 、一个阐明该区域在场景中角色或功能的上下文感知定义 ,以及详细的描述。
-
对于视频 :将参考视频检测与分割数据集 64, 58, 18, 71, 17 中原始的粗粒度标注精炼为详细的、具有时序感知的区域级描述 。此外,本文首创开发了基于事件的区域级流式视频描述数据 。据作者所知,这是首个构建此类数据集的工作,使模型能够支持流式视频区域描述。
-
值得注意的是,还为每个数据标注生成了双语(英文和中文)版本 ,以赋予模型多语言响应能力。
此过程最终产生了一个高质量数据集,包含 150 万(1.5M)个图像-区域-语义三元组和 60 万(0.6M)个视频-区域-语义三元组。
本文的实验结果表明,PAM 在多种图像和视频区域理解任务中均表现出 鲁棒的性能**,同时与先前模型相比,** 运行速度快 1.2−2.4 倍且 GPU 内存占用更低**。作者相信,提出的模型、数据集和见解将** 显著推动该领域的研究**,并为视觉语言社区带来广泛价值。**
Perceive Anything Model (PAM)
给定视觉提示(如点、框或掩码)以指定感兴趣区域,感知万物模型(PAM) 能够同时 完成以下任务:
(1) 分割(Segment) :在图像中或整个视频中为指定区域生成精确的分割掩码 。
(2) 识别(Recognize) :识别 指定区域或对象的类别 。
(3) 解释(Explain) :提供清晰解释 ,说明该区域或对象在其给定上下文中的定义、属性和功能 。
(4) 描述(Caption) :为图像、视频和视频流中的区域生成简洁或详细的描述。
模型架构
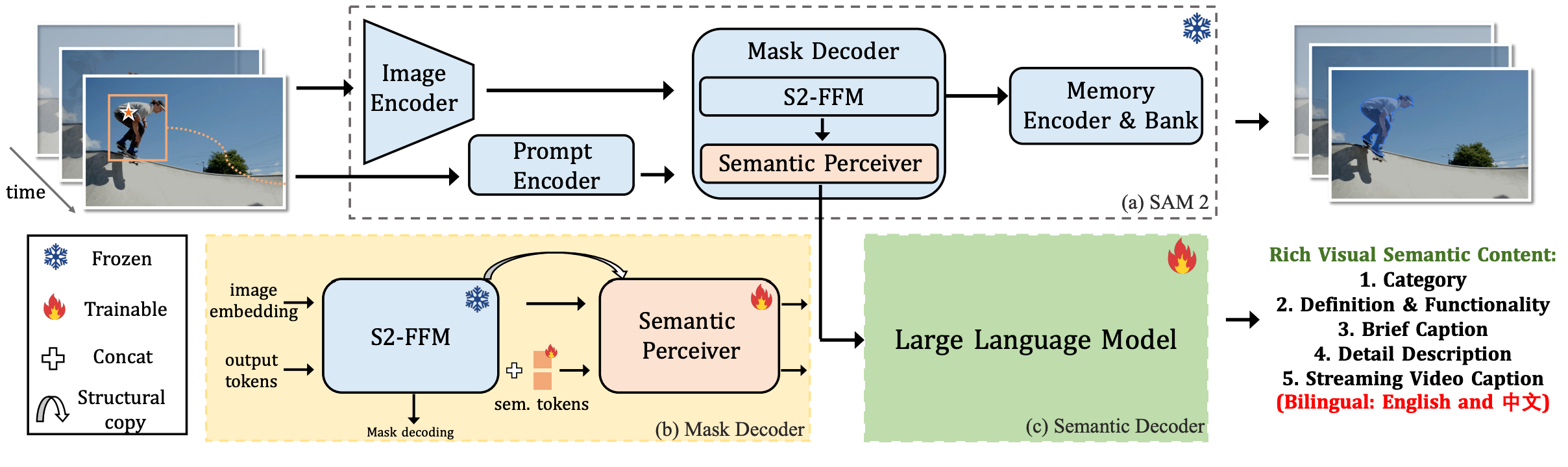
如图 3 所示,提出的 PAM 可分为两部分。第一部分是 SAM 2 框架 ,它包含一个图像编码器(image encoder) 、一个提示编码器(prompt encoder) 、记忆模块(memory modules) 和一个掩码解码器(mask decoder) 。该框架提供了强大的时空视觉特征提取和分割能力 。第二部分是一个语义解码器(semantic decoder) ,它基于一个大语言模型(Large Language Model, LLM) 。关键 在于,本文提出的语义感知器(Semantic Perceiver) 充当了桥梁 ,它有效利用 SAM 2 骨干网络的中间视觉特征 ,并生成视觉 token(visual tokens) 。这些 token 随后由 LLM 处理 ,以生成多样化的语义输出 。在解码方面,PAM 采用了并行设计 用于其掩码解码器 和语义解码器 ,从而能够同时分割对象 并生成其多样化的语义输出。各组件的设计和训练过程详述如下。
Figure 3: Overall Architecture of PAM.
语义感知器(Semantic Perceiver)
如图 3(b) 和图 4 所示,语义感知器的架构 镜像了 SAM 2 特征融合模块(SAM 2 Feature Fusing module, S2-FFM) ,采用了一个轻量级的两层 Transformer ,包含自注意力(self-attention) 、交叉注意力(cross-attention) 和一个逐点 MLP(point-wise MLP)。具体来说,它接收两个主要输入:
- 来自 S2-FFM 的增强掩码 token(enhanced mask tokens) :这些 token 融合了 IoU 和提示 token 的信息 ,并作为精确生成掩码的唯一标识符。
- S2-FFM 之后更新的图像嵌入(updated image embeddings) :这些嵌入捕捉了通用的视觉上下文 以及通过与掩码 token 交互而丰富的隐式特征 。
接下来,遵循 26, 28 的方法,本文将 Ns 个可学习的语义 token(learnable semantic tokens) 与增强的掩码 token 进行拼接(concatenate) 。最后,通过语义感知器内部进一步的注意力机制 ,本文可以获取富含通用视觉信息和对象级定位信息的视觉 token 。给定 N 帧输入(对于单张图像 N=1),语义感知器输出两组 256 维向量 :642 × N 个视觉 token 和 Ns × N 个语义 token (Ns 默认为 16)。
投影器(Projector)
位于 LLM 之前 的投影器 包含两层:一个像素重排操作(pixel shuffle operation) 和一个 MLP 投影器(MLP projector)。
- 对于图像输入 ,本文对相邻的 2×2 特征块(feature patches) 应用像素重排操作 ,以下采样视觉 token 的数量。
- 对于视频输入 ,被提示的帧(prompted frame) 的处理方式与单张图像类似,而视频片段中的剩余帧(remaining frames) 则经过更激进的 4×4 像素重排操作 ,以显著减少视觉 token ,并进一步提高语义解码器的处理效率 。
随后,本文使用两个独立的 MLP 45 来分别投影视觉 token 和语义 token。
Figure 4: Detailed illustration of our PAM workflow. Semantic Perceiver first receives enhanced image embeddings and mask tokens from the S2-FFM and outputs enriched visual tokens and semantic tokens. These are subsequently fed into the semantic decoder for decoding.
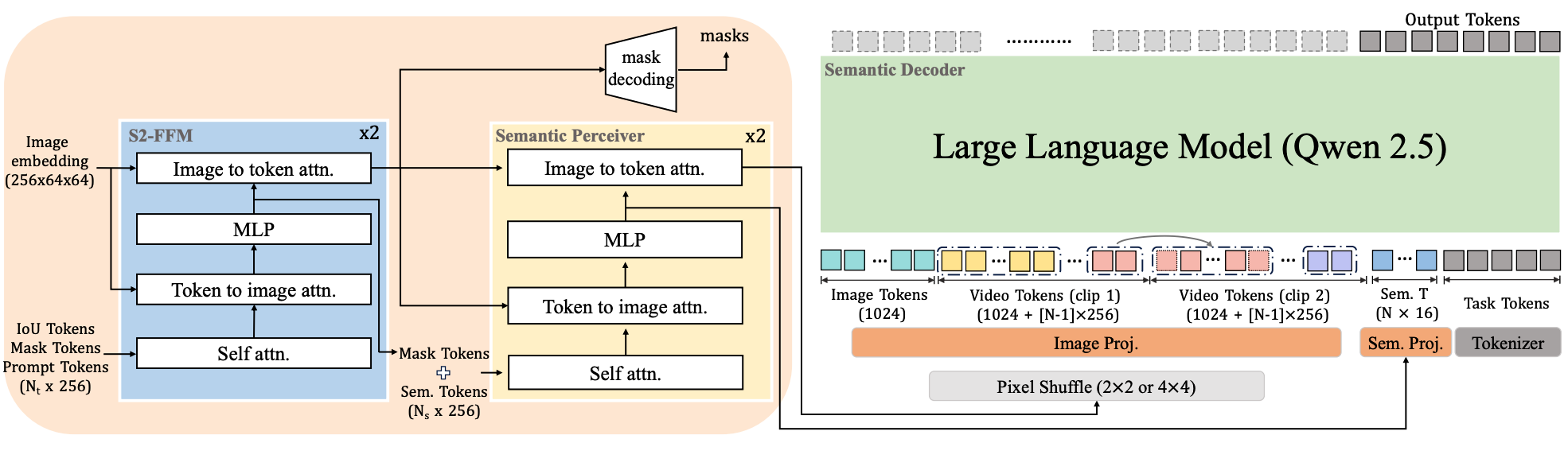
语义解码器(Semantic Decoder)
本文采用预训练的 Qwen2.5 LLM 72 作为本文的语义解码器,利用其强大的语言处理能力。该解码器负责解释处理后的视觉 token 和语义 token ,并结合任务指令 ,以生成所需的语义输出。
流式视频编码与解码(Streaming Video Encode and Decode)
基于 SAM 2 中通过记忆模块(memory modules)逐帧渐进引入历史信息 的基础,本文提出了一种简单直接的策略 来实现区域级流式视频描述(region-level streaming video captioning) ,而无需添加复杂组件。具体来说,对每个视频片段的最后一帧 应用一个额外的 2×2 像素重排操作(pixel shuffle operation) 。这导致了更高密度的视觉 token ,从而改善了历史视觉信息的保留 。这些 token 随后作为下一个视频片段的初始帧 ,并与该片段的剩余帧 一起由 LLM 处理 。这种方法确保每个片段得到一致的处理 ,并有效地将关键的历史信息 从上一个片段传递到下一个视频片段。此外,本文将先前的文本描述 纳入提示词(prompt) 中,以进一步增强上下文历史信息 ,从而提升模型对持续事件的理解和描述准确性 。在实践中,本文的框架允许用户灵活指定解码时间戳 。当达到指定时间戳时,模型会描述当前时间戳与上一个时间戳之间时间段内的指定区域。
训练策略(Training Strategies)
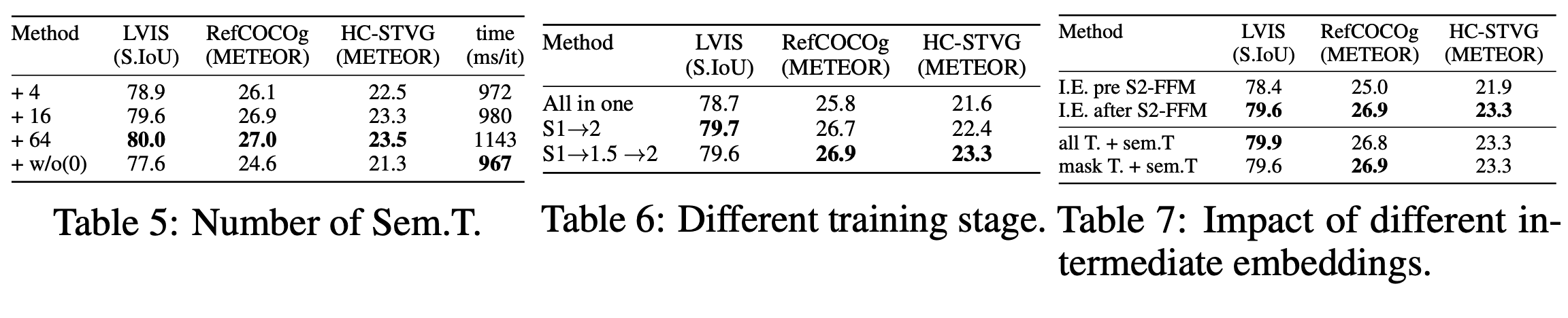
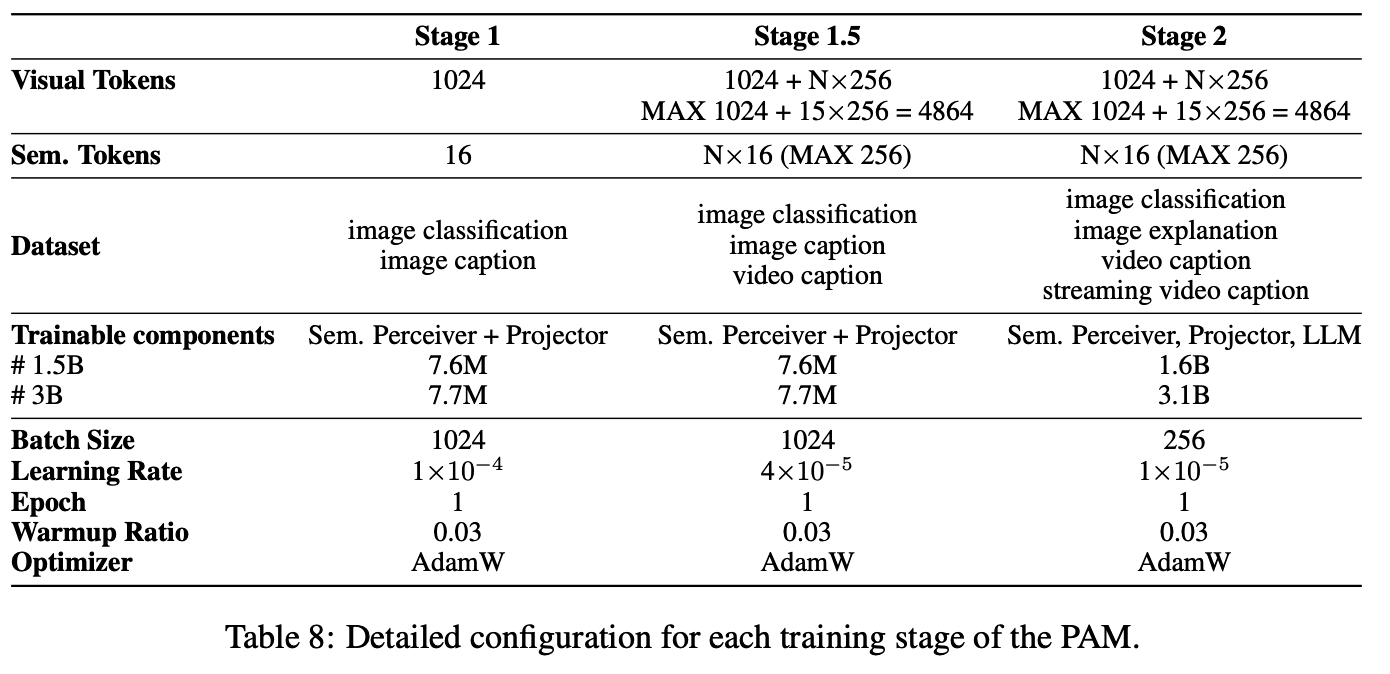
本文采用三阶段课程学习(three-stage curriculum learning) 方法来构建训练过程,逐步增强 PAM 的区域级视觉理解能力 ,从图像扩展到视频 。在所有训练阶段 ,SAM 2 的参数均被冻结(frozen)。每个训练阶段的超参数总结在附录 A 中。
-
阶段 1:图像预训练与对齐(Image Pretraining and Alignment) 。初始训练阶段侧重于在视觉 token 、语义 token 和语言模型的嵌入空间(embedding space) 之间建立鲁棒的对齐(robust alignment) 。主要目标是使模型能够有效理解区域级图像内容 。为此,本文利用一个包含区域级图像分类和描述(region-level image classification and captioning) 的大规模数据集。在此阶段,仅训练语义感知器(semantic perceiver)和投影器(projector)。
-
阶段 1.5:视频增强预训练与对齐(Video-Enhanced Pretraining and Alignment) 。在此阶段,本文通过加入区域级视频描述(region-level video captions) 来扩展基于图像的初始训练。这种加入使模型能够通过整合时空视觉信息(spatio-temporal visual information) 来理解动态场景(comprehend dynamic scenes) 。可训练模块与阶段 1 相同。
-
阶段 2:多模态微调(Multimodal Fine-Tuning) 。最后阶段采用监督微调(Supervised Fine-Tuning, SFT) ,使模型能够执行多样化任务(perform diverse tasks) 并生成期望的响应(generate desired responses) 。此阶段利用一个高质量数据集 ,该数据集已通过本文的流程(第 4 节)进行了精炼和增强(refined and augmented) 。此阶段的训练联合涉及语义感知器、投影器和语义解码器(semantic decoder)。
Data
为了增强 PAM 的全面视觉感知能力(comprehensive visual perception capabilities) ,本文开发了一个鲁棒的数据精炼与增强流程(robust data refinement and augmentation pipeline) ,以策划(curate) 一个高质量的训练数据集 。该数据集具有三个关键特征:
(1) 广泛的语义粒度(Broad-ranging Semantic Granularities) :它提供多样化的视觉语义标注(diverse visual semantic annotations) ,涵盖从粗粒度(coarse-level) (类别、定义、上下文功能)到细粒度(fine-grained) (详细描述)的范围(第 4.1 节)。
(2) 区域流式描述标注(Regional Streaming Caption Annotations) :这是首个专门为流式视频区域描述(streaming video region captioning)策划标注 的数据集(第 4.2 节)。
(3) 双语标注(Bilingual Annotations) ,支持英语和中文 (附录 B.2)。
该流程详述如下,更多信息可在附录 B 中找到。
Image Dataset
区域识别、解释与描述(Regional Recognition, Explanation, and Caption)
对于区域识别 ,本文利用了多个实例检测与分割数据集 55, 35, 40, 23, 50, 66,以及场景文本识别数据集 56, 31, 30, 19, 24, 14, 76, 57, 4。在此上下文中,边界框(bounding box)或掩码(mask) 作为视觉提示输入 ,而标签(label) 被视为输出。
为了实现超越简单分类的深层、细粒度视觉理解 ,本文提出了一个增强流程(enhanced pipeline) ,为每个特定区域生成:清晰的概念解释(clear conceptual explanations) 、上下文功能角色(contextual functional roles) 和详细描述(detailed descriptions) 。这种多维信息(multi-dimensional information) 旨在显著提升用户理解 ,特别是对于不常见术语或陌生主题 。为实现这一点,本文利用最新的 VLMs ,借助其广泛的世界知识和强大的视觉理解能力 来辅助精炼。具体来说,本文应用掩码集合方法(Set of Mask, SoM)75 来识别感兴趣区域 ,并使用原始标注作为上下文 来引导模型生成期望的响应 ,这些响应随后经过人工质量保证(manual quality assurance)。图 5(左)展示了一个说明性示例。更多细节见附录 B.1。

视频数据集(Video Dataset)
区域级视频描述(Region-level Video Caption)
为了将模型的区域描述能力扩展到视频 ,本文收集并分析了几个现有的视频数据集,包括参考检测与分割数据集(referring detection and segmentation datasets) 71, 47, 18, 62, 58, 17, 85, 64,以及近期为 SAV 53 数据集 添加的 Sa2VA 79 标注 。这些数据集旨在基于文本描述检测、分割和描述视频中的特定对象,但其描述往往过于粗糙、简单、不准确或主要是静态的 ,忽略了关键的时间细节 ,例如物体运动、交互以及整个视频中的状态变化。
为了应对现有局限性,本文提出了故事板驱动的描述扩展方法(storyboard-driven caption expansion method) 。该过程包含几个关键阶段:
(1) 关键帧采样(Keyframe Sampling) :从每个视频中均匀提取六个关键帧 。
(2) 故事板合成(Storyboard Synthesis) :将这些提取的关键帧组合 成一张高分辨率合成图像 ,以故事板格式(storyboard format) 呈现(如图 5 所示)。
(3) 以对象为中心的高亮(Object-Centric Highlighting) :在此合成图像中,每个单独的帧 使用彩色边界框或掩码 (通过 SoM 实现 )专门突出显示目标对象 。
(4) LLM 驱动的精炼(LLM-Powered Elaboration) :然后,以原始标注作为条件 ,本文提示 GPT-4o 生成既精炼、详细又具有时间感知(temporally aware) 的描述。这种多帧整合(multiframe consolidation) 至关重要,因为它增强了 GPT-4o 的上下文理解能力 ,相比单帧分析能产生更优的描述。
区域级流式视频描述(Region-level Streaming Video Caption)
除了描述整个视频,本文的目标是将模型的能力扩展到流式方式 。为实现这一点,本文对精炼后的区域级视频描述数据进行了额外的增强(additional augmentation)。具体来说:
- 本文首先采用 TRACE-Uni 模型 22 将输入视频分割成多个不同的事件(distinct events) ,每个事件由其时间边界(temporal boundaries) 界定。
- 随后,对于每个分割出的视频片段,本文应用相同的 '故事板驱动'处理方法。
- 为了生成精确且连续的事件描述 ,本文重新设计了 GPT-4o 的输入提示(input prompt) ,使其迭代地纳入前一个视频片段的描述 作为处理当前片段的上下文信息 。
整个工作流程如图 5(右)所示。
Experiments
Figure 6: PAM provides various semantic granularities informantion and support bilingual outputs.


Appendix
A. Configuration for Each Training Stage
B. Dataset