#作者:朱雷
文章目录
- 一、说明
- 二、WAL和Snapshot存储方式对比
- 三、存储方式详细对比
-
- [3.1 优点](#3.1 优点)
-
- [3.1.1. 独享式](#3.1.1. 独享式)
- [3.1.2. 共享式](#3.1.2. 共享式)
- [3.2 缺点](#3.2 缺点)
-
- [3.2.1. 独享式](#3.2.1. 独享式)
- [3.2.2. 共享式](#3.2.2. 共享式)
- 四、适用场景建议
- 五、总结建议
一、说明
WAL(预写日志) :负责实时记录所有数据变更操作,通过顺序写入保证事务原子性。在 etcd 中,所有数据的修改在提交前,都要先写入到WAL中。
Snapshot(快照):则通过定期生成完整数据镜像可以在etcd故障时实现快速恢复。etcd 防止WAL文件过多而设置的快照。
两者在存储特性上存在显著差异:
WAL特性 :高频、小数据量、顺序写入
快照特性:低频、大数据量、随机写入
Etcd 集群对磁盘 I/O的延时非常敏感,因为 Etcd 必须持久化它的日志,当其他 I/O 密集型的进程也在占用磁盘 I/O 的带宽时,就会导致 fsync 时延非常高。这将导致 Etcd 丢失心跳包、请求超时或暂时性的 Leader 丢失。
官方说明:
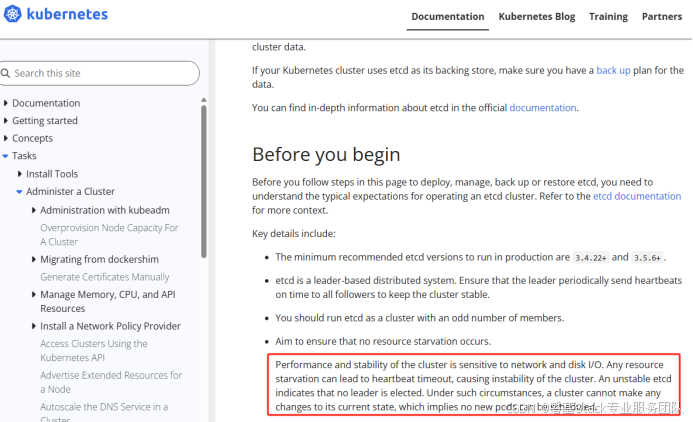
二、WAL和Snapshot存储方式对比
| 存储方式 | 优点 | 缺点 |
|---|---|---|
| 共享式(同一块设备) | 配置维护复杂度低 硬件成本低 | 产生IO争抢增加延迟 数据单点故障风险高 资源利用不合理 |
| 独享式(不同块设备) | 避免IO争抢降低延迟 数据单点故障风险低 资源利用更合理 支持更灵活的备份策略 | 配置维护复杂度高 硬件成本高 |
三、存储方式详细对比
3.1 优点
3.1.1. 独享式
3.1.1.1. 降低读写延迟
IO隔离:
分离后可避免WAL的顺序写入与快照的随机写入产生IO争抢,降低整体延迟。
资源争抢的连锁反应:
- CPU饥饿:高磁盘延迟导致IOWait上升,etcd协程无法及时调度,进一步加剧消息处理延迟。
- 网络缓冲区溢出:若持久化延迟导致消息积压,网络层sendBuffer可能溢出,触发重传机制,形成恶性循环。
SSD适配:
WAL存储设备可选择高顺序写入性能的SSD(如QLC颗粒)
快照存储设备可选用高随机读写能力的SSD(如TLC/MLC颗粒)
3.1.1.2. 故障隔离性提升
单点故障风险降低:若某一SSD发生物理损坏,另一存储路径的数据仍保持独立完整性。
恢复效率保障:WAL与快照分离后,可独立执行数据修复或回滚操作。
3.1.1.3. 资源利用更合理
寿命管理:WAL的频繁写入会加速SSD磨损,分离后可针对性部署高耐久度设备(如企业级SSD)。
容量规划:快照占用空间较大,可单独扩展大容量SSD而不影响WAL存储性能。
3.1.1.4. 运维灵活性增强
备份策略:可对WAL和快照分别制定差异化的备份周期与压缩策略。
监控维度:独立监控两个存储路径的IOPS、延迟、磁盘健康状态。
3.1.2. 共享式
3.1.2.1 配置复杂度低
集群相对配置简单可维护性较高
3.1.2.2 硬件成本低
不需采购两类不同性能规格的SSD,硬件投入比独享存储方案低
3.2 缺点
3.2.1. 独享式
3.2.1.1. 配置维护复杂度高
路径依赖:需严格保证etcd配置文件中WAL与快照路径的准确性,否则可能导致数据丢失。
监控覆盖:需对多个设备分别实施健康检测与性能调优。
扩容限制:存储容量扩展时需同时考虑两个路径的平衡性,避免资源倾斜。
3.2.1.2. 硬件成本高
设备采购:需额外购置SSD并分配独立IO通道,增加硬件投入。
3.2.2. 共享式
3.2.2.1. 产生IO争抢增加延迟
WAL以高频顺序写入为主,快照涉及低频大容量随机读写,分离存储可避免两类操作争抢同一SSD的IO资源,降低整体延迟
3.2.2.2. 数据单点故障风险高
存储损坏时,数据完全丢失风险高
3.2.2.3. 资源利用不合理
WAL以高频顺序写入为主,快照涉及低频大容量随机读写,使用同一种资源无法兼顾这两种情况。
四、适用场景建议
独享模式推荐场景:
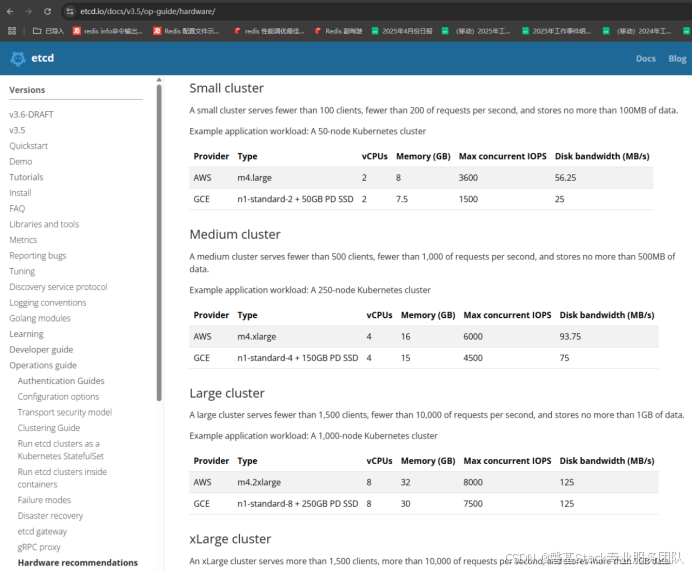
大规模Kubernetes集群(节点数>250)
高并发IO负载写入场景(数据量>=500MB,qps>=1K)
共享模式推荐场景:
中小规模或测试环境Kubernetes集群(节点数<250硬件成本收益比低)
低IO负载场景(分离带来的性能提升有限)
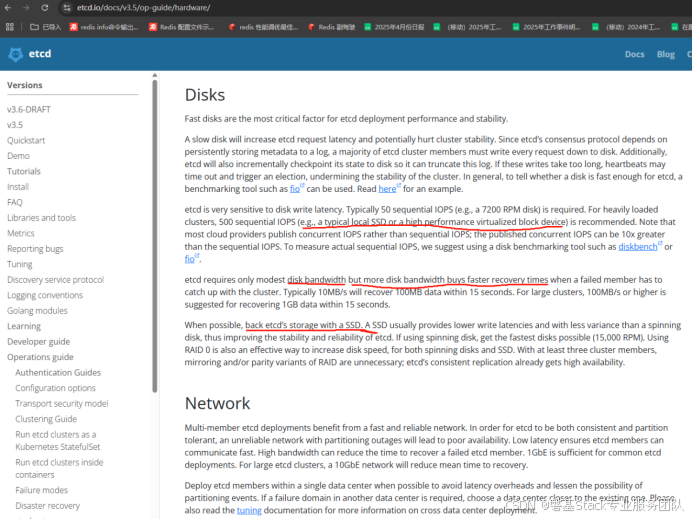
官方集群硬件配置参考:
五、总结建议
- 根据以上对比分析,etcd持久化存储在使用共享存储或分离存储时,在etcd压力高或故障时对业务侧会产生一定的影响。
- 官方建议:尽量使用 SSD 支持 etcd 的存储。SSD 通常比机械硬盘提供更低的写入延迟和更小的波动性,从而提高 etcd 的稳定性和可靠性。如果使用机械硬盘,请尽可能选择速度最快的硬盘(15,000 RPM)。使用 RAID 0 也是提高磁盘速度的有效方法,无论机械硬盘还是 SSD 都适用。如果集群成员至少有三个,则无需使用 RAID 的镜像和/或奇偶校验变体;etcd 的一致性复制已经具备高可用性。
- 对于控制面的稳定性、性能有很高要求时推荐使用分离存储模式。
- 对于中小规模K8S集群推荐使用共享存储模式,增加性能量化监控指标项:
如:
etcd_wal_fsync_duration_seconds_bucket(p99 延迟时间< 10 ms)
etcd_snapshot_save_total_duration_seconds_bucket
etcd_disk_backend_commit_duration_seconds_bucket (p99 延迟时间< 25 ms)等
磁盘操作延迟过高(wal_fsync_duration_seconds或backend_commit_duration_seconds)通常表示磁盘存在问题。这可能会导致请求延迟过高或集群不稳定。
在磁盘操作延迟分布高的情况下考虑独享分离存储模式或升级使用企业级高性能的SSD存储设备。
-
大规模k8s集群推荐使用独享分离存储模式,同时增加性能量化监控指标项:
如:
etcd_wal_fsync_duration_seconds_bucket(p99 延迟时间< 10 ms)
etcd_snapshot_save_total_duration_seconds_bucket
etcd_disk_backend_commit_duration_seconds_bucket (p99 延迟时间< 25 ms)等
在磁盘操作延迟分布高的情况下考虑将数据分片存储。
-
对于已在实际生产中运行的K8S集群,增加性能量化监控指标项:
如:
etcd_wal_fsync_duration_seconds_bucket(p99 延迟时间< 10 ms)
etcd_snapshot_save_total_duration_seconds_bucket
etcd_disk_backend_commit_duration_seconds_bucket (p99 延迟时间< 25 ms)等
并保留一段时间(建议至少三个月)的监控数据,根据历史监控数据分析磁盘操作延迟分布趋势,如果磁盘操作延迟分布趋势:
- 一直线性增加
- 多次某时间段内有明显突发增高且延迟较大
考虑分离存储模式或升级使用企业级高性能的SSD存储设备。
- 建议在新环境中首次设置 etcd 集群时运行基准测试,以确保集群达到足够的性能;集群延迟和吞吐量对微小的环境差异很敏感。
注:
1、扩展 etcd 集群可以通过牺牲性能来提高可用性。扩展不会提升集群性能或容量。一般规则是不要对 etcd 集群进行扩展或缩减。不要为 etcd 集群配置任何自动伸缩组。强烈建议在任何官方支持的规模下,始终为生产 Kubernetes 集群运行一个包含五成员的静态 etcd 集群。
2、当需要更高的可靠性时,合理的扩展方法是将三成员集群升级到五成员集群。