问题:从网上下载的视频文件,是由很多个各种不同的场景视频片段合并而成。现在要求精确的把各个视频片段从大视频里分割出来。
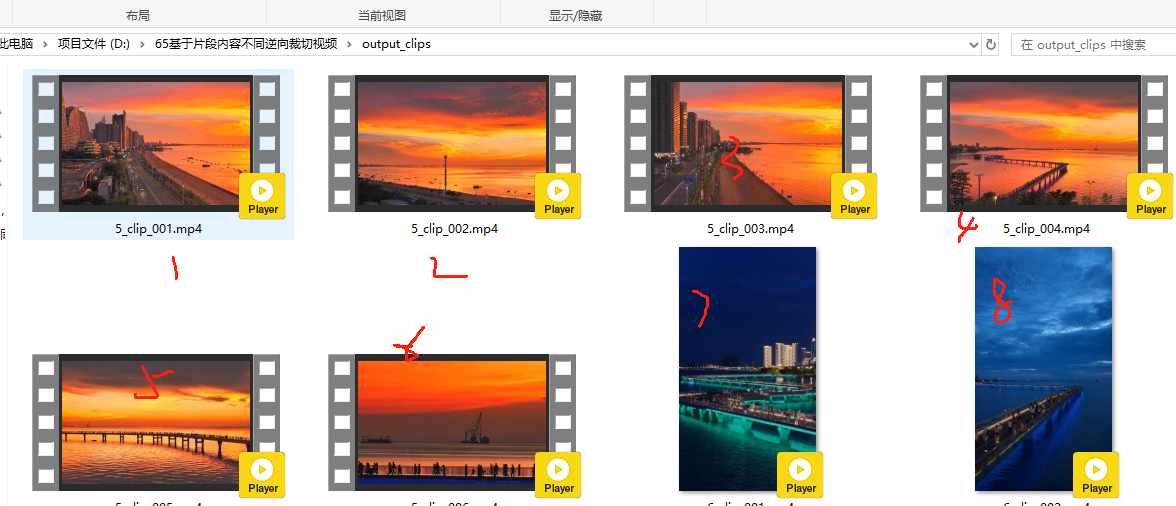
效果如图:已分割出来的小片段
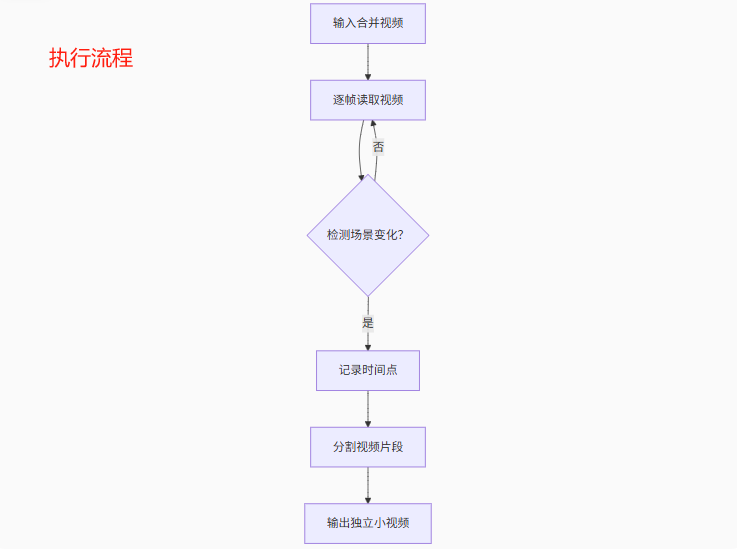
思考过程 难点在于检测场景变化。为什么呢?因为不同的视频情况各异,并没有一定的规律,需要通过机械检测,也需要通过AI模型进行判断。需要通对对画面,音频,语义等多方面进行综合检测。
首先分析问题:
-
核心目标是:识别视频中不同场景的分界点,然后将这些段落精确分离成独立的小视频文件。
-
方法有:
-
使用AI图像分类模型(如 MobileNet)识别每段内容主题,如"焊接/水管"等;
-
使用预训练模型(如 ResNet, EfficientNet)
-
语音识别(如 whisper)转文字,然后进行判断,🏆语音识别 + NLP特别适合讲解类视频。
-

-
使用语音检测,对停顿有规律的节凑进行判断;
-
自定义规则 判断"逻辑片段"边界:如停顿 > 1.5 秒,或语义变化
-
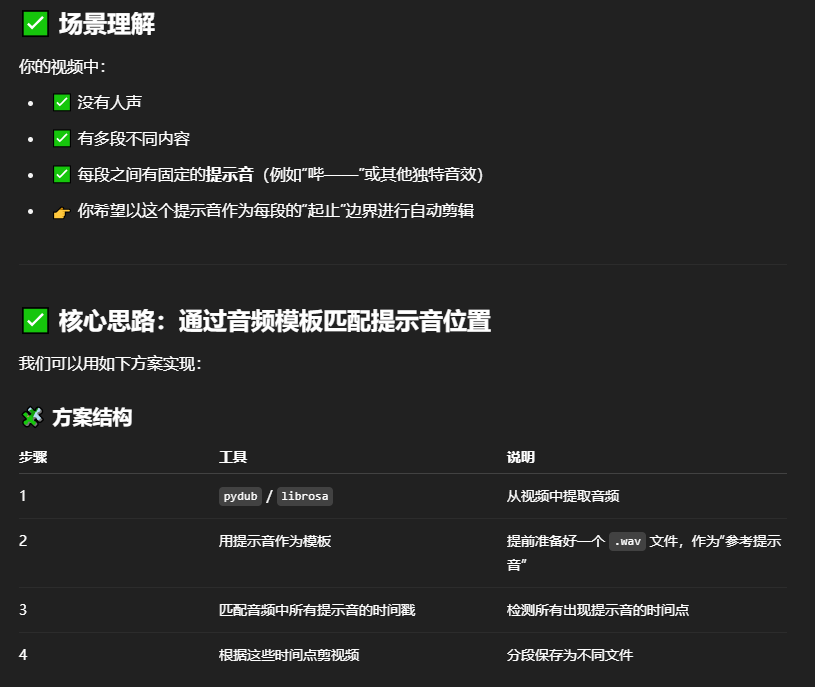
根据视频中音频特点,如视频内有某种特定的提示音,也可以通过检测该指定的提示音进行分割,更为精准。
-

-
根据视频画面特点,如视频内有某种特定的图像符号,也可以通过检测该指定的图像符号进行分割,更为精准。
-
或者训练一个 图像分类模型 对帧图片判断场景类型(高阶)
在分割时可能出现的问题:
| 问题 | 原因 |
|---|---|
| 同一场景内讲解多个内容 | 画面没变,但内容变了,无法检测 |
| 同一个主题但切了视角 | 被误判为新场景 |
| 非真实镜头切换(如过渡动画) | 被误判为新场景 |
| 模糊、晃动、亮度变化 | 可能导致误检或漏检 |
步骤
a提取视频的视觉特征(图像帧)
b通过算法识别"场景切换点"
c根据切换点将视频裁剪成多个片段
d导出为单独视频文件
| 功能 | 工具 | 说明 |
|---|---|---|
| 视频解析 | opencv, moviepy |
加载视频、读取帧 |
| 场景检测 | PySceneDetect ✅推荐 |
自动识别场景切换 |
| 视频裁剪 | ffmpeg 或 moviepy |
将视频按时间段切分保存 |
✅ 推荐做法(用 PySceneDetect 实现)
pip install scenedetectopencv moviepy
import os
from scenedetect import VideoManager, SceneManager
from scenedetect.detectors import ContentDetector
from moviepy.editor import VideoFileClip
def detect_scenes(video_path, threshold=30.0):
"""检测视频中的场景切换,返回每个片段的起止时间(单位:秒)"""
video_manager = VideoManager([video_path])
scene_manager = SceneManager()
scene_manager.add_detector(ContentDetector(threshold=threshold)) # 越小越敏感
video_manager.set_downscale_factor()
video_manager.start()
scene_manager.detect_scenes(frame_source=video_manager)
scene_list = scene_manager.get_scene_list()
scene_times = [(start.get_seconds(), end.get_seconds()) for start, end in scene_list]
print(f"[INFO] 共检测到 {len(scene_times)} 个场景片段。")
return scene_times
def split_video(video_path, scene_times, output_dir):
"""根据给定起止时间列表裁剪视频并保存为小片段"""
if not os.path.exists(output_dir):
os.makedirs(output_dir)
base_name = os.path.splitext(os.path.basename(video_path))[0]
for i, (start, end) in enumerate(scene_times):
clip = VideoFileClip(video_path).subclip(start, end)
out_path = os.path.join(output_dir, f"{base_name}_clip_{i+1:03d}.mp4")
print(f"[INFO] 正在导出:{out_path},时长:{end - start:.2f} 秒")
clip.write_videofile(out_path, codec='libx264', audio_codec='aac')
def main():
# ==== 配置项 ====
video_path = '6.mp4' # 原始视频路径(替换成你自己的)
output_dir = './output_clips' # 输出目录
threshold = 30.0 # 场景变化阈值(小 = 更敏感)
'''threshold = 15.0 # 非常敏感(小场景变动都会分)
threshold = 30.0 # 默认值,适合多数视频
threshold = 45.0 # 稍微严格,只检测"重大"场景变化
'''
print("[INFO] 正在检测视频场景...")
scene_times = detect_scenes(video_path, threshold=threshold)
print("[INFO] 正在裁剪并保存片段...")
split_video(video_path, scene_times, output_dir)
print("[DONE] 全部处理完成。")
if __name__ == '__main__':
main()优化建议
对于更精确的场景识别,可以使用预训练的深度学习模型(如 ResNet、YOLO 等)来分析视频内容
考虑音频特征的更复杂分析,如声音的频率特征、音调变化等
调整threshold和min_scene_length参数以适应不同视频的特性
对于较长的视频,可以考虑多线程处理以提高效率