一、Transformer与transformers
结论:Transformer是模型架构,transfortmers是库。
问:为什么我们要知道Transformer与transformers呢?
答:千问大模型和DeepSeek都是Transformer架构的,transformers库就是为这个架构而生的,各位觉着我们不了解它俩能行么?
(以上结论笔者的说法可能不准确,但请不要急着给笔者科普,笔者搜一下能知道的比诸君喷的更准确,但是在这里为了让看文章的同学好理解,笔者就先这么说罢,想要更多了解Transfomer详细内容请自行找论文看,笔者自觉讲不明白,搬运一堆论文概念看不懂也没啥用,诸君以为呢?)
Transformer 模型(技术架构)由 Google 在 2017 年论文《Attention Is All You Need》中提出的一种深度学习架构 ,基于自注意力机制(Self-Attention),彻底摒弃了传统的循环神经网络(RNN)结构。
在Transformer模型中,原始文本 → 分词器(Tokenization)→ 编码器(Encoder)→ 解码器(Decoder)→ 输出(经分词器转换回文本):
-
分词器 (Tokenization)是整个流程的起点:分词器的作用是将输入文本分割成Token,这些Token可以是单词、字符、短语等。常见的分词策略包括按词切分(Word-based)、按字符切分(Character-based)和按子词切分(Subword)等方法,供编码器(Encoder)处理。
-
编码器(Encoder)**:**将输入编码处理为带有注意力信息的连续表示,可以将编码器堆叠N次使得每一层都有机会学习不同的注意力表示,从而提高Transformer的预测能力。
再好懂点就是将输入序列转换为上下文感知的语义表示,使模型能够理解每个 token 在全局语境中的含义。再直白点就是我们给模型一个汉字"白",模型输出"白""天"俩字,要比输出"白""大"两个完全不搭噶的字靠谱,就是干这个事儿。
-
解码器 (Decoder)是生成环节的核心:根据编码器的语义表示,逐词生成目标文本。
-
分词器 (Tokenization)也是输出的终点 :解码器生成的 token ID 需通过分词器的
decode()方法还原为人类可读的文本。
transformers 库(工具包)由 Hugging Face 团队开发的 Python 库,全称为transformers(小写),提供了对 Transformer 架构模型的预训练权重 、模型架构 和任务工具的统一接口。它的设计目标是简化 Transformer 模型的使用,让研究者和开发者能够快速应用最先进的 NLP 技术。
建议各位眼熟一下分词器(Tokenization)、 编码器(Encoder)、 解码器(Decoder)这几个单词,后面有用。
二、AutoModel与AutoModelForCausalLM
二者都是transformers库中的类,都是加载模型的类。
AutoModel 是一个通用模型类,设计用来加载和运行各种预训练模型。它不包含特定任务的头部(例如分类头),提供了预训练模型的基本架构,但没有针对特定任务进行优化。
AutoModelForCausalLM,基于AutoModelForCausalLM。用于因果语言建模(Causal Language Modeling)。因果语言建模是指给定之前的词或字符序列,模型预测文本序列中下一个词或字符的任务。这种模型广泛应用于生成式任务,如对话系统、文本续写、摘要生成等。
(这里看不懂就算,能知道是个加载模型的类就行,我们用AutoModelForCausalLM)
在实际应用中,选择哪种模型类取决于任务需求。如果任务是文本生成或因果语言建模,`AutoModelForCausalLM` 更合适;而其他类型的 NLP 任务,如文本分类或序列标注,选`AutoModel`可能更合适 。
三、 AutoTokenizer
AutoTokenizer 是 Hugging Face Transformers 库中的一个实用工具类 ,它提供了一种通用接口 来加载与预训练模型对应的分词器(Tokenizer)。AutoTokenizer可以根据预训练模型名称(如 "bert-base-uncased"),自动选择对应的分词器类(如 BertTokenizer)。建议搞不清状况的情况下就使用AutoTokenizer。
上文中我们知道了分词器是做什么的,我们以Bert模型为例,"窗前明月光"这句诗,在经过分词处理后就变成了床前明月光这几个汉字对应的字典编码。
四、pipeline
没错,如你所想,这就是管道。熟悉linux的同学如你所想~
Transformers Pipeline 是Hugging Face Transformers 库提供的一个高级 API,旨在简化自然语言处理(NLP)、计算机视觉(CV)和多模态任务的实现流程。其核心功能包括数据预处理、模型调用和结果后处理的三部分整合,用户只需输入数据即可直接获得最终结果。
五、从一段代码来看
这段代码中笔者以下载到本地的Bert模型为例,详细看一下我们上面降到transforms库的具体使用。
python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
# 设置具体包含 config.json(即模型配置文件) 的目录,路一直到模型配置文件的父级
model_dir = r"D:/XXX/XXX/XXXmodel/bert-base-chinese/models--bert-base-chinese/snapshots/c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f"
# 加载模型和分词器
model = AutoModelForCausalLM.from_pretrained(model_dir,is_decoder=True)
tokenizer = AutoTokenizer.from_pretrained(model_dir)
# 使用加载的模型和分词器创建生成文本的 pipeline
# 如果你想使用GPU环境,device参数配置为cuda
generator = pipeline("text-generation", model=model, tokenizer=tokenizer,device='cpu')
# 生成文本
output = generator("你好,我是一款语言模型,", max_length=50, num_return_sequences=1)
# output = generator("你好,我是一款语言模型,", max_length=50, num_return_sequences=1, truncation=True, clean_up_tokenization_spaces=False)
'''
output = generator(
"你好,我是一款语言模型,",#生成文本的输入种子文本(prompt)。模型会根据这个初始文本,生成后续的文本
max_length=50,#指定生成文本的最大长度。这里的 50 表示生成的文本最多包含 50 个标记(tokens)
num_return_sequences=2,#参数指定返回多少个独立生成的文本序列。值为 1 表示只生成并返回一段文本。
truncation=True,#该参数决定是否截断输入文本以适应模型的最大输入长度。如果 True,超出模型最大输入长度的部分将被截断;如果 False,模型可能无法处理过长的输入,可能会报错。
temperature=0.7,#该参数控制生成文本的随机性。值越低,生成的文本越保守(倾向于选择概率较高的词);值越高,生成的文本越多样(倾向于选择更多不同的词)。0.7 是一个较为常见的设置,既保留了部分随机性,又不至于太混乱。
top_k=50,#该参数限制模型在每一步生成时仅从概率最高的 k 个词中选择下一个词。这里 top_k=50 表示模型在生成每个词时只考虑概率最高的前 50 个候选词,从而减少生成不太可能的词的概率。
top_p=0.9,#该参数(又称为核采样)进一步限制模型生成时的词汇选择范围。它会选择一组累积概率达到 p 的词汇,模型只会从这个概率集合中采样。top_p=0.9 意味着模型会在可能性最强的 90% 的词中选择下一个词,进一步增加生成的质量。
clean_up_tokenization_spaces=True#该参数控制生成的文本中是否清理分词时引入的空格。如果设置为 True,生成的文本会清除多余的空格;如果为 False,则保留原样。默认值即将改变为 False,因为它能更好地保留原始文本的格式。
)
'''
print(output)输出结果如下:

大家可以猜一猜为什么后面有这么多点?那是因为我们说了生成长度为50。
六、一起看看bert模型文件
读到这里大家肯定很好奇笔者在上面代码中下载到本地的模型到底长什么样子,模型里面都有什么文件,接下里以bert模型为例,我们来看一下模型里面都有哪些文件。
上图是笔者在本地加载的模型文件,有用的文件都在snapshots文件夹下。其中:
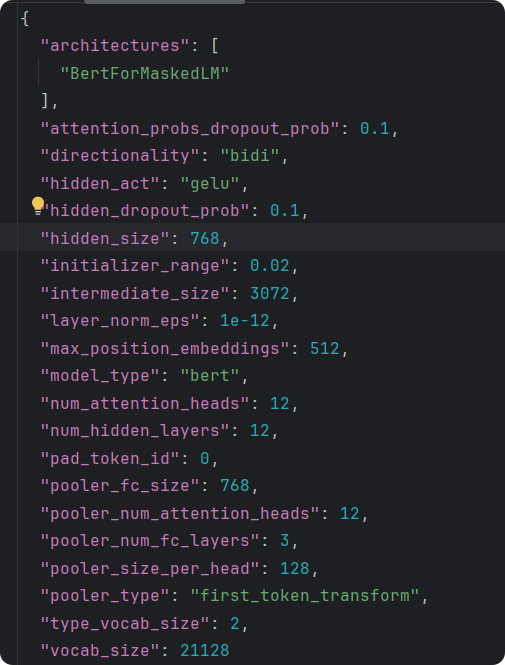
config.json是模型的配置文件,对模型做了简单说明,说明了模型的头、模型的结构、模型的参数。其中vocab_size说明模型最多能识别21128个字符。
special_tokens文件中包含的特殊字符,UNK就是未识别的字符串,即超出2128个字符外的识别不了的。
tokenizer_config是分词器的配置文件。
vocab.txt是字典文件,存储模型能识别出的字符。一句话在分词器处理之后,编码器先转码成字典中的数字即位置编码大模型会把每次字转换为字典的索引(注意这里还不是向量化)。(中文分词和英文不一样,英文分词是一个单词一分,中文是一个汉字一分)
七、你还需要知道的概念
这里的每一个名次都适合拿出来水一篇文章啊,笔者还是太懒了。~
7.1、HuggingFace
一个下载模型的社区。。。。
HuggingFace 最初成立于 2016 年,最初以聊天机器人开发起步,后来逐渐转型为专注于开源机器学习框架和模型的平台。如今,它已成为全球 AI 开发者社区的核心枢纽之一,致力于降低 AI 技术的使用门槛,推动技术民主化。transformers库、Datastes库都是他家出的。
Model Hub 收录了数万种预训练模型,覆盖 NLP、计算机视觉、语音处理等多个领域。开发者可直接下载、微调或部署模型,无需重复训练,大幅节省时间和计算资源。
7.2、CUDA
CUDA(Compute Unified Device Architecture)是由 NVIDIA 开发的并行计算平台和编程模型,旨在利用 NVIDIA 图形处理器(GPU)的强大算力加速计算任务。它打破了 GPU 传统上仅用于图形渲染的局限,让开发者能够通过编写特定代码,将 GPU 作为高效的并行计算处理器使用。
CUDA 是 NVIDIA GPU 算力释放的关键技术,它将 GPU 从图形处理器拓展为通用计算平台,通过 CUDA开发者能够以相对低的成本实现高性能计算,加速复杂任务的落地,其生态(如支持的框架、库和工具)也在持续扩展,成为现代计算基础设施的重要组成部分。
7.3、Annaconda
笔者用它来管理python环境,在实际开发中不同的项目一般用不同的python环境。
Anaconda 是一个开源的Python/R 数据分析和科学计算平台,由 Continuum Analytics 开发(现属 Anaconda, Inc.)。它本质上是一个集成环境,内置了数百个常用的数据科学、机器学习库,并通过包管理工具(如 conda)和环境管理功能,解决了开发者在配置开发环境时面临的依赖冲突、版本兼容等痛点。
7.4、pytroch
PyTorch 是一个开源的深度学习框架,基于 Python 语言构建,由 Facebook AI Research(FAIR)团队开发并维护。它提供了灵活的张量计算(Tensor Computation)和动态计算图(Dynamic Computational Graph)功能,广泛应用于自然语言处理(NLP)、计算机视觉(CV)、语音识别等领域。
Transformers 库本身是一个框架无关的库,它支持多种深度学习后端(如 PyTorch、TensorFlow、JAX)。但在实际使用中,PyTorch 常被作为默认后端。