为了更好的去理解预料信息,我们需要去进行文本的数据分析。
一.标签数量分布
python
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('fivethirtyeight')
train_data = pd.read_csv("cn_data/train.tsv",sep='\t')
test_data = pd.read_csv("cn_data/dev.tsv",sep='\t')
sns.countplot(x='label',data=train_data)
plt.title('Distribution of Sentiments in Training Data')
plt.show()
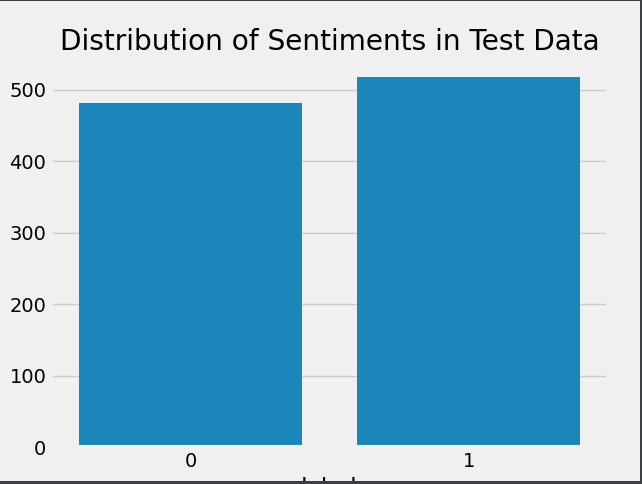
sns.countplot(x='label',data=test_data)
plt.title('Distribution of Sentiments in Test Data')
plt.show()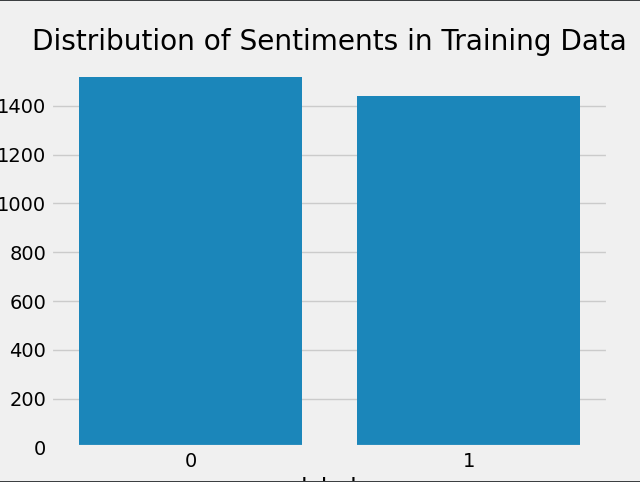
二.句子长度分析
往往会通过分析句子的长度构成,来选择句子截断/补齐的长度
python
#增加一列,记录该文本的长度
train_data["sentence_length"] = list(map(lambda x: len(x),train_data["sentence"]))
sns.countplot(x='sentence_length',data=train_data)
plt.title('Distribution of Sentence Lengths in Training Data')
plt.xticks([])
plt.show()
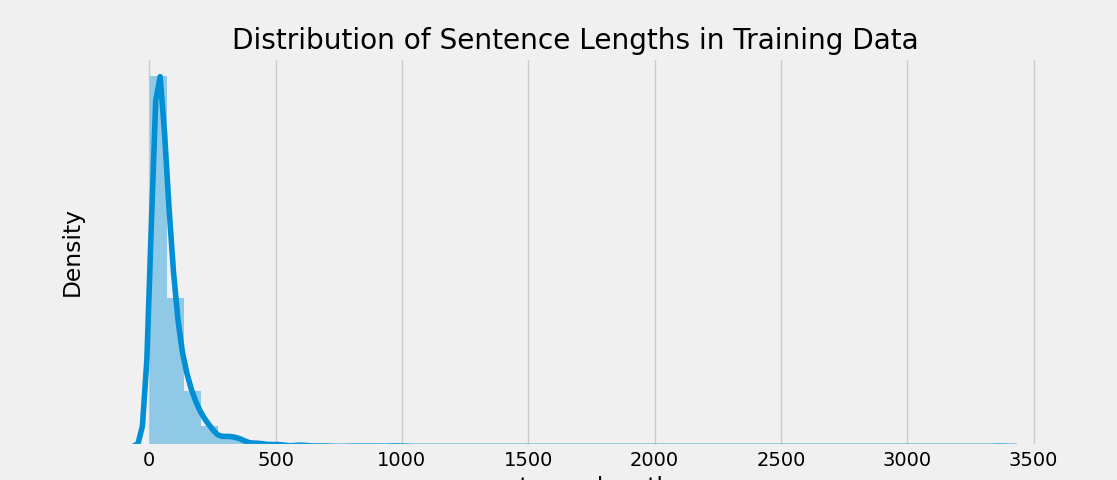
sns.distplot(train_data["sentence_length"])
plt.yticks([])
plt.title('Distribution of Sentence Lengths in Training Data')
plt.show()
test_data["sentence_length"] = list(map(lambda x: len(x),test_data["sentence"]))
sns.countplot(x='sentence_length',data=test_data)
plt.title('Distribution of Sentence Lengths in Test Data')
plt.xticks([])
plt.show()
sns.distplot(test_data["sentence_length"])
plt.yticks([])
plt.title('Distribution of Sentence Lengths in Test Data')
plt.show()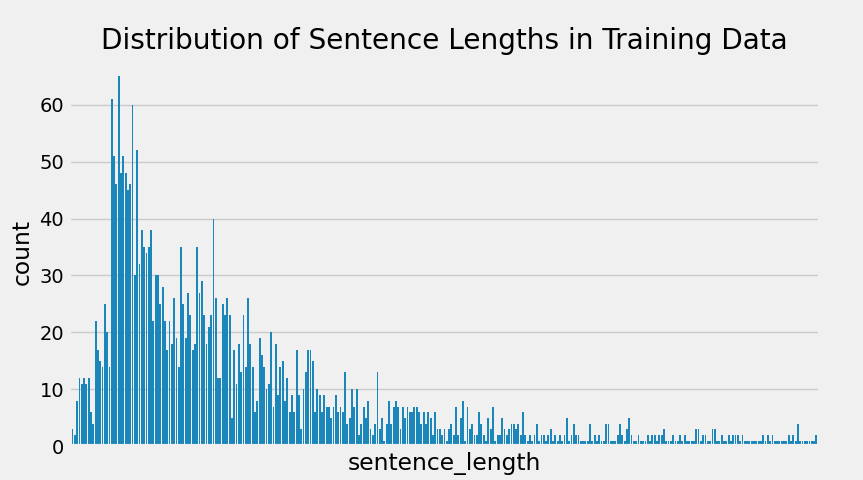
三. 正负样本的散点分布
python
#绘制散点图
sns.stripplot(y='sentence_length',x='label',data=train_data)
plt.show()
sns.stripplot(y='sentence_length',x='label',data=test_data)
plt.show()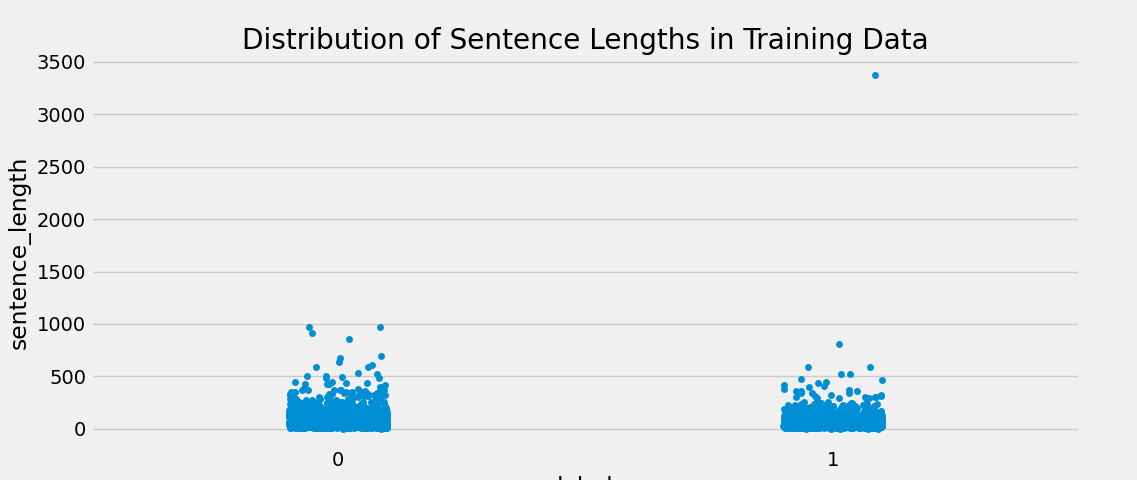
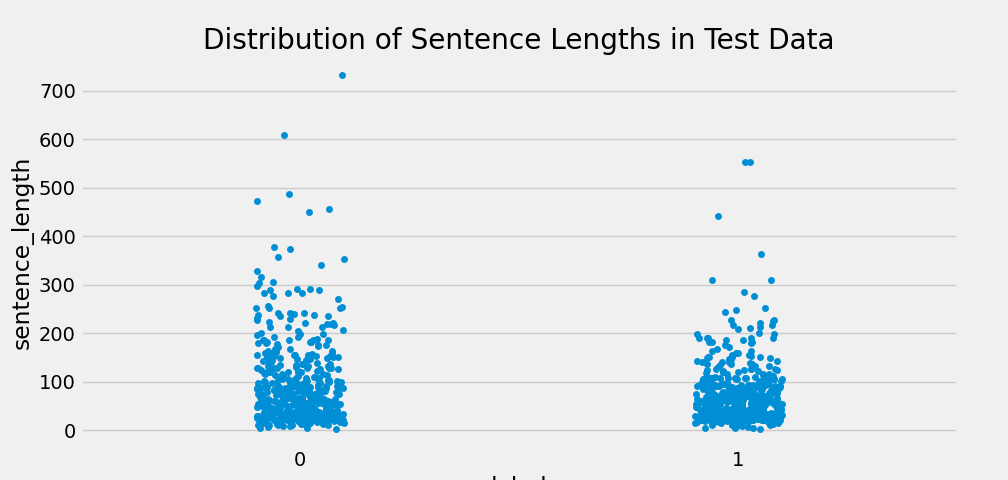
通过查看散点图,发现异常点的存在,进一步人工进行审查。
四.不同词汇统计
python
#获取训练集和验证机不同词汇总数统计
import jieba
from itertools import chain
#rain_vocab = set(chain(*map(lambda x: jieba.lcut(x),train_data["sentence"])))
token_lists = map(lambda x: jieba.lcut(x), train_data["sentence"]) #分词
flat_tokens = chain(*token_lists) #展平为1维数组
train_vocab = set(flat_tokens) #去掉重复词
print("训练集不同词汇总数:",len(train_vocab))
valid_vocab = set(chain(*map(lambda x: jieba.lcut(x),test_data["sentence"])))
print("验证集不同词汇总数:",len(valid_vocab))
五.高频词汇词云
高频形容词词云
对于情感分析,我们往往会提取形容词,来评估语料集的质量。
python
import jieba.posseg as pseg
from wordcloud import WordCloud
# 词性统计
def get_a_list(text):
r = []
for g in pseg.lcut(text):
if g.flag == 'a': #a就是形容词
r.append(g.word) #把词存入列表
return r
def get_word_cloud(keyword_list):
wordcloud = WordCloud(background_color='white', font_path='C:\Windows\Fonts\STFANGSO.TTF', max_font_size=100, random_state=42)
keyword_string = " ".join(keyword_list) #这里参数必须传字符串类型
wordcloud.generate(keyword_string)
plt.figure()
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
#正样本
p_train_data = train_data[train_data['label']==1]["sentence"]
train_p_a_vocab = chain(*map(lambda x: get_a_list(x),p_train_data))
#负样本
n_train_data = train_data[train_data['label']==0]["sentence"]
train_n_a_vocab = chain(*map(lambda x: get_a_list(x),n_train_data))
get_word_cloud(train_p_a_vocab)
get_word_cloud(train_n_a_vocab)

正样本主要是褒义词,负样本主要是贬义词,基本符合要求,但是可以发现负样本中出现了"舒服","干净",可以进一步进行人工审查。