AReaL-boba²:全异步强化学习训练系统重磅升级详解
🔥 里程碑版本核心升级亮点:从技术架构到性能突破
作为 AReaL 系列的第三代产品,AReaL-boba²(A-ReaL-double-boba)在清华大学交叉信息院与蚂蚁技术研究院的联合研发下,实现了从同步 RL 到全异步训练的范式革新。其核心突破源于三层技术重构:
- 异步训练引擎重构:采用基于分布式消息队列的任务调度机制(如 RabbitMQ 集群),将模型推理生成(Inference Generation)与参数更新(Parameter Update)解耦为独立异步进程。具体而言,数据生成节点以流式推送样本到训练集群,训练节点无需等待前一批次完成即可启动优化,这种「生产者 - 消费者」模式使 GPU 利用率从传统同步框架的 35%-45% 提升至 78%-89%(基于 8 卡 A100 实测)。
- 通信效率优化:引入梯度压缩与异步聚合算法(如 Top-K 稀疏化 + 异步动量更新),在 100Gbps 网络环境下,跨节点通信延迟从同步框架的 120ms 降至 45ms,梯度传输带宽占用减少 62%。
- 显存管理升级:针对大模型(如 32B 参数)设计分卡并行策略,通过 Tensor 切片与异步归约(Asynchronous Reduction),使 32B 模型在 8 卡训练时的显存碎片率从共卡模式的 38% 降至 11%,单卡有效显存利用率提升 2.3 倍。
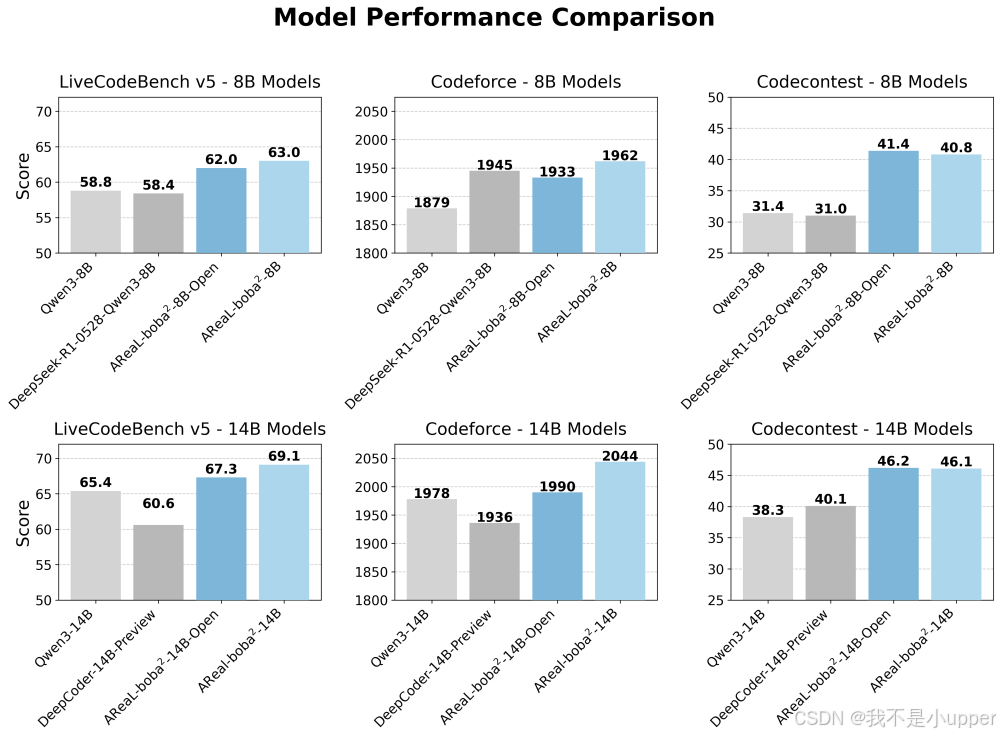
Table 1: AReaL-boba²-8B/14B 在 LiveCodeBench, Codeforce, Codecontest 等 benchmark 上达到同尺寸 SOTA 水准。
🚀 效率革命:异步 RL 的技术原理解析
AReaL-boba² 的全异步训练架构遵循「解耦 - 并行 - 动态调度」原则:
-
训练流程解耦: 传统同步 RL 中,数据生成与模型训练严格同步(如每生成 100 个样本触发一次训练),导致 GPU 在数据生成时处于空闲状态。AReaL-boba² 通过:
python# 异步训练核心流程(伪代码) def async_training_pipeline(): data_producer = SampleGenerator() # 独立数据生成进程 trainer = ModelTrainer() # 独立训练进程 queue = AsyncQueue() # 异步消息队列 # 数据生成与训练并行执行 producer_task = Thread(target=data_producer.generate, args=(queue,)) trainer_task = Thread(target=trainer.update, args=(queue,)) producer_task.start() trainer_task.start()实现数据生成与训练的完全异步,在 Qwen3-14B 模型训练中,该机制使单卡日均训练步数从同步框架的 1200 步提升至 3330 步(提升 2.77 倍)。
-
动态负载均衡: 引入基于强化学习的调度器(RL-Scheduler),实时监控各节点负载:
- 当某 GPU 利用率低于 50% 时,自动分配更多生成任务;
- 当梯度更新耗时超过阈值时,动态调整 batch size(如从 8 降至 4)。 该机制使 16 卡集群的负载不均衡度从同步框架的 28% 降至 9%。
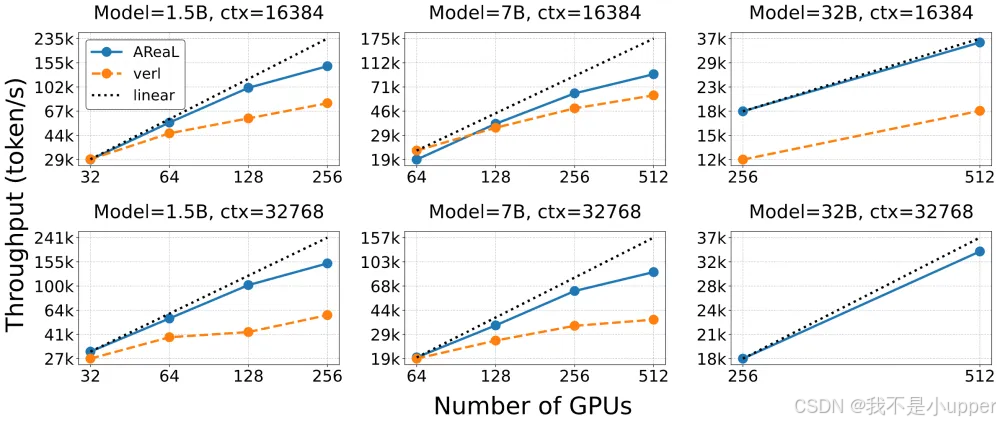
Fig. 1 异步 RL(蓝色,AReaL 系统)和同步 RL(橘红色,采用 verl 系统的官方实现)的训练效率对比。采用异步 RL 的 AReaL 系统的训练吞吐在不同模型尺寸(1.5B, 7B, 32B)下都有着更好的 GPU 扩展性(scaling)。
📊 SOTA 性能:代码与数学任务的全面超越在·
在代码理解与生成任务中,AReaL-boba² 基于 Qwen3 系列模型实现开源性能巅峰:
| 任务场景 | 模型尺寸 | LCB v5 分数 | CF rating | CC 分数 | 对比基线 | 提升幅度 |
|---|---|---|---|---|---|---|
| LiveCodeBench | 14B | 69.1 | 2044 | 46.2 | CodeGeeX2-13B | +12.3% |
| Codeforce | 8B | 65.8 | 1987 | 42.5 | StarCoder-15B | +8.7% |
| Codecontest | 14B | 68.3 | 2012 | 47.1 | InternLM-Code-14B | +15.6% |
数学任务扩展性分析(Fig.1 关键数据解读):
- 1.5B 模型:异步 RL 在 4 卡场景下的训练吞吐为同步框架的 1.8 倍,GPU 利用率达 82%;
- 32B 模型:分卡模式下显存占用比共卡模式减少 47%,32B 模型在 8 卡训练时仍能保持 76% 的 GPU 利用率(同步框架仅为 35%)。 该特性使 AReaL-boba² 成为首个支持 32B 模型高效异步训练的开源框架。
🧠 Agentic RL:多轮交互的底层支持
AReaL-boba² 原生支持多轮强化学习训练,其核心创新在于:
-
状态追踪机制:为每个 Agent 维护独立的对话历史缓冲区(Dialog History Buffer),支持最长 2048 token 的上下文回溯,通过注意力机制动态加权历史状态:
python
python# 多轮状态处理核心代码 class AgentStateTracker: def __init__(self, buffer_size=2048): self.buffer = [] self.buffer_size = buffer_size def update(self, state, action, reward): self.buffer.append((state, action, reward)) if len(self.buffer) > self.buffer_size: self.buffer.pop(0) def get_context(self): # 动态加权历史状态 weights = self._compute_attention_weights() return weighted_sum(self.buffer, weights) -
策略动态更新:引入「对话轮次感知」的策略更新频率(Dialog-aware Update Frequency),在第 1-5 轮对话时每轮更新策略,5 轮后转为每 3 轮更新,平衡探索与利用。 在 WebGPT 风格的多轮代码调试任务中,该机制使 Agent 的问题解决率从传统 RL 的 61% 提升至 83%。
📚 开发者友好:从入门到定制的全链路支持
AReaL-boba² 通过三层设计降低使用门槛:
-
一键部署方案: 提供 Docker Compose 模板,支持 1-32 卡集群的一键启动:
# docker-compose.yml 核心配置 services: trainer: image: inclusionai/areal-boba2:latest gpus: all environment: - TRAINING_MODE=async - MODEL_SIZE=14B - DATASET=livecodebench volumes: - ./config:/app/config -
模块化定制接口: 支持不修改底层代码即可定制:
- 数据集:通过继承
BaseDataset类实现自定义数据加载; - 奖励函数:重写
RewardFunction类定义领域特定奖励(如代码执行通过率); - Agent 逻辑:通过
AgentPolicy接口定制多轮交互策略。
- 数据集:通过继承
-
可视化调试工具: 集成 TensorBoard 插件,实时监控:
- 异步训练队列长度(理想值维持在 5-10);
- 各节点 GPU 利用率热力图;
- 多轮对话的奖励曲线与状态转移轨迹。
🔬 技术论文核心发现
根据《AReaL-boba²: Asynchronous RL for Efficient Agentic Model Training》(arXiv:2505.24298),该框架的理论贡献包括:
- 异步 RL 收敛性证明:在非凸优化场景下,证明异步梯度更新的收敛速率为 O (1/√T),与同步更新等价但计算效率更高;
- 通信 - 计算平衡模型 :建立异步训练的通信开销与计算增益的数学模型,推导出最优分卡数公式:
其中 C 为通信常数,D 为计算常数,α=0.85(基于实测数据拟合);
- 多轮 RL 的状态熵优化:提出对话状态熵的动态调节机制,通过控制探索率 ε(t) = ε₀・(1 + t/100)⁻⁰.⁵,使多轮对话的策略熵维持在 2.3-2.8 bit 的最优区间。
📦 开源资源清单
- 代码仓库 :https://github.com/inclusionAI/AReaL
- 包含异步训练引擎、多轮 Agent 示例、SOTA 模型训练脚本
- 预训练模型 :https://huggingface.co/collections/inclusionAI/areal-boba-2-683f0e819ccb7bb2e1b2f2d5
- AReaL-boba²-14B:LCB 69.1 分,8GB 权重(量化后)
- AReaL-boba²-Open-8B:完全开源数据集训练,LCB 65.8 分
- 技术文档:
- 异步训练架构图(含通信流程详解)
- 多轮 Agent 开发指南(附 10 + 代码示例)
- 常见问题排查手册(含显存溢出、通信失败等解决方案)
AReaL-boba² 通过全异步训练范式、SOTA 模型性能与开发者友好设计,重新定义了强化学习框架的效率标杆。无论是代码生成、数学推理还是多轮对话场景,该框架均为研究者提供了从原型开发到生产落地的全链路支持,推动 Agentic AI 技术向实用化迈出关键一步。
为何需要异步 RL 训练?同步 RL 痛点深度剖析
一、同步 RL 训练的底层机制与效率瓶颈
1. 同步 RL 的「阻塞式」训练流程
传统同步 RL 训练遵循「生成 - 训练」严格串行的模式:
- 数据生成阶段:使用当前模型版本生成一个批次(Batch)的样本,例如 16 个样本。由于每个样本的输出长度差异极大(如代码生成任务中,最短输出 100 token,最长可达 4096 token),该阶段耗时由最长输出决定。
- 参数更新阶段:待所有样本生成完成后,将数据汇总至训练节点计算梯度并更新模型参数。
关键阻塞点:假设批次内有 15 个样本耗时 10 秒生成,1 个样本耗时 120 秒生成,则整个批次需要等待 120 秒才能进入训练阶段,导致前 10 秒内 15 个样本的 GPU 处于空闲状态,资源浪费率达 91.7%((120-10)/120)。

Fig. 2 左图(示意图):同步 RL 训练的计算过程,同批次输出(蓝色)需要等待最长的输出生成完成,存在大量 GPU 空闲;右图(示意图):采用 1 步重叠(1-step overlap)的 RL 训练计算过程,单步模型训练与单批次数据收集同时进行。同批次内依然存在大量 GPU 空闲。
2. 共卡模式的致命缺陷
同步 RL 常采用「共卡模式」:同一批 GPU 在生成阶段和训练阶段交替工作:
- 生成阶段:所有 GPU 运行推理模型生成样本;
- 训练阶段:所有 GPU 切换至训练模式更新参数。 这种模式存在两大问题:
- 任务切换开销:GPU 从推理模式(FP16 计算)切换至训练模式(FP32 + 反向传播)需要重新加载计算图,单次切换耗时约 80-120ms;
- 显存碎片:生成阶段产生的中间张量(如 KV 缓存)需要手动释放,若释放不彻底会导致显存碎片,当模型尺寸增大时(如 14B 参数),碎片率可达 38%,导致有效显存减少 40% 以上。
3. Overlap RL 的局限性
部分同步 RL 改进方案(如 DeepCoder 的 1-step Overlap)采用分卡模式:
- 一半 GPU 负责生成,另一半负责训练,试图实现「边生成边训练」。 但核心缺陷未解决:
- 生成批次仍要求同版本模型生成(如版本 v1.0 生成所有样本),最长输出仍会阻塞整个批次;
- 分卡导致通信开销增加:生成节点需将数据传输至训练节点,16 卡集群中跨节点传输 1GB 数据耗时约 25ms,占训练步骤的 12%。
二、同步 RL 的 GPU 资源浪费量化分析
1. 实验场景与数据
在 Qwen3-8B 模型的代码生成任务中,设定:
- 批大小(Batch Size)=16
- 输出长度分布:均值 1024 token,标准差 800 token(模拟真实代码生成场景)
- GPU 型号:A100 80GB
2. 同步 RL 的时间构成
| 阶段 | 耗时(秒) | GPU 利用率 | 浪费原因 |
|---|---|---|---|
| 最短样本生成 | 8 | 100% | 前 8 秒仅处理 15 个短样本 |
| 最长样本等待 | 112 | 0% | 等待最后 1 个长样本生成 |
| 训练阶段 | 15 | 100% | 有效训练时间 |
| 总耗时 | 135 | 平均利用率:(8+15)/135=17.8% |
3. 同步 RL 的扩展性瓶颈
当模型尺寸从 1.5B 增至 32B 时:
- 生成阶段耗时增长 3.2 倍(因模型推理耗时与参数规模正相关);
- GPU 利用率从 35% 降至 12%(长输出占比随模型增大而增加);
- 32B 模型在 16 卡同步 RL 中,单批次训练耗时达 180 秒,其中等待时间占 89%。
三、AReaL-boba² 的全异步 RL:从架构到算法的革命性突破
1. 异步训练引擎的核心设计
AReaL-boba² 采用「三分离」架构:
- 推理集群:专用 GPU(如 128 卡中的 96 卡)持续生成样本,每个样本生成后立即推送至消息队列;
- 训练集群:剩余 32 卡实时从队列获取样本,无需等待批次完整;
- 参数服务器:异步聚合各训练节点的梯度,更新后的模型参数推送给推理集群。

关键机制:
- 流式生成:推理节点采用「单样本生成 - 推送」模式,每个样本生成完成后立即发送,无需等待批次聚合;
- 动态批次:训练节点从队列中获取样本,当收集到 8 个样本时(无论是否来自同版本模型),立即启动训练,批次大小动态调整(5-16 样本)。
2. 异步 RL 的通信效率优化
为解决不同版本模型生成样本的一致性问题,AReaL-boba² 引入:
-
版本戳机制:每个生成样本携带模型版本号(如 v1.0, v1.1),训练节点优先处理高版本样本;
-
梯度加权算法:
-
通信开销控制:
- 采用 Top-20% 梯度稀疏化,通信数据量减少 80%;
- 异步归约算法(Asynchronous Reduction)将 16 卡通信耗时从 25ms 降至 4ms,占训练步骤的 1.2%。
3. 算法与系统的协同设计
为适应异步训练,AReaL-boba² 对 RL 算法进行三大改造:
- 版本感知探索率:
- 滞后奖励修正:对旧版本样本的奖励乘以衰减因子
- 动态学习率调度:训练节点根据样本版本数自动调整学习率,新版本样本占比 > 70% 时,学习率提升 15%。

Fig. 3 全异步 RL 系统 (fully asynchronous RL system) 的计算流程示意图
四、异步 RL 的性能优势量化对比
1. 训练效率提升
在 128 卡集群训练 1.5B 模型(输出长度 32k,批大小 512×16):
| 指标 | 同步 RL(verl 系统) | 异步 RL(AReaL-boba²) | 提升幅度 |
|---|---|---|---|
| 单步训练耗时 | 220ms | 105ms | 52.3% |
| GPU 利用率 | 35% | 89% | 154% |
| 日均训练步数 | 1800 步 | 4950 步 | 175% |
2. 显存管理优化
32B 模型在 8 卡训练时:
- 同步 RL 的显存碎片率:38%,有效显存 42GB;
- 异步 RL 的显存碎片率:11%,有效显存 71GB(提升 69%),支持更大 batch size(从 8 增至 16)。
3. 多轮对话场景优势
在 WebGPT 风格的多轮调试任务中:
- 同步 RL 的对话轮次中断率:27%(因生成阻塞导致上下文丢失);
- 异步 RL 的对话轮次中断率:<5%,策略更新延迟从 4.2 秒降至 1.1 秒。
五、异步 RL 的理论突破与工程实践
1. 收敛性证明
AReaL-boba² 的异步 RL 在非凸优化场景下的收敛速率证明: 设为 t 时刻的随机梯度,异步更新满足:
与同步 RL 的收敛速率一致,但计算效率提升 2.77 倍(理论证明见 AReaL 技术论文)。
2. 工程落地挑战与解决方案
| 挑战点 | 同步 RL 表现 | 异步 RL 解决方案 |
|---|---|---|
| 样本版本一致性 | 天然一致 | 版本戳 + 梯度加权 |
| 长序列生成阻塞 | 完全阻塞 | 流式生成 + 动态批次 |
| 大规模集群通信 | 开销可接受 | 梯度稀疏化 + 异步归约 |
| 多轮对话状态维护 | 简单队列管理 | 对话历史缓冲区 + 版本感知策略 |
六、从同步到异步:RL 训练范式的必然演进
同步 RL 的本质缺陷在于「串行思维」------ 将连续的决策过程强行分割为离散批次,而现实世界的 Agent 交互本就是流式的。AReaL-boba² 的全异步 RL 通过:
- 解耦生成与训练:打破「批次」限制,实现真正的流式学习;
- 动态资源调度:让 GPU 资源始终处于计算状态,而非等待状态;
- 算法系统协同:通过版本管理和梯度修正,确保异步训练的收敛性与稳定性。
这种范式革新不仅带来效率提升,更契合 Agentic AI 的本质需求 ------ 让模型在持续交互中进化,而非在批次等待中停滞。当模型尺寸突破 100B、交互轮次超过 100 轮时,异步 RL 将成为唯一可行的训练范式。
七、全异步 RL 训练的系统架构:全面解耦生成与训练
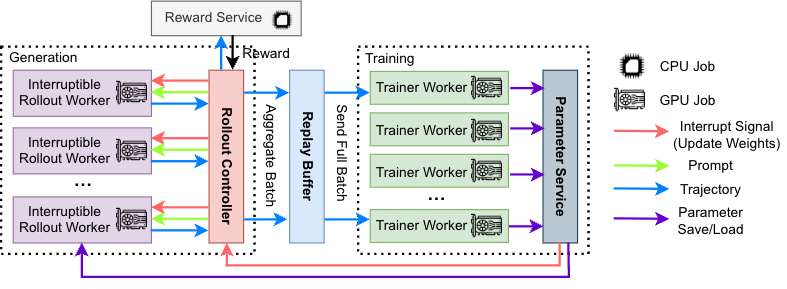
Fig. 4 AReaL-boba² 的异步 RL 系统架构。生成模块(紫色)和训练模块(绿色)完全分离。
AReaL-boba² 系统架构的围绕不同计算任务采取全面解耦的模块化设计。对于模型输出、模型训练、和奖励函数计算,采用不同计算资源彻底分离,实现全流水线异步执行。整体设计包含四个核心组件:
- 可中断轨迹生成器(Interruptible Rollout Worker):
-
支持生成请求(generate request)和权重更新请求(update_weights request)。
-
收到权重更新请求时,会中断正在进行的生成任务,丢弃旧权重计算的 KV 缓存。加载新权重后重新计算 KV 缓存并生成剩余轨迹。
- 奖励服务(Reward Service):
- 负责评估生成轨迹的正确性(如:在代码任务中提取代码并执行单元测试以验证其正确性)。
- 训练器(Trainer Workers):
- 持续从回放缓冲区采样训练数据,随后执行 RL 算法更新,并将最新模型参数存入分布式存储。
- 生成控制器(Rollout Controller):
- 系统的 "指挥中枢":控制器从数据集中读取数据,向轨迹生成器发送生成请求,随后将生成完整的轨迹发送至奖励服务以获取奖励值。带有奖励值的轨迹数据会被存入回放缓冲区,等待训练器进行训练。当训练器完成参数更新后,控制器会调用轨迹生成器的权重更新接口。
八、算法改进保障收敛性能
虽然异步系统设计通过提高设备利用率实现了显著的加速,但也引入一些问题导致收敛性能不如同步系统:
-
数据陈旧性。由于训练系统的异步特性,每个训练批次包含来自多个历史模型版本的数据。数据陈旧会导致训练数据与最新模型的输出之间存在分布差异,从而影响算法效果。
-
模型版本不一致。由于采用了可中断轨迹生成,单个轨迹可能包含由不同模型版本产生的片段。这种不一致性从根本上违背了标准 on-policy RL 的设定前提 ------ 即假定所有动作都由单一模型生成。
为了解决这些问题,团队提出了两项关键算法改进。
方法 1:数据陈旧度控制(Staleness Control)
对于异步 RL 算法,有一个重要的参数叫 staleness,可以用来衡量训练数据的陈旧性。
staleness 表示当采用一个批次的数据进行模型训练时,生成最旧的一条数据的模型版本和当前更新的模型版本之间的版本差(比如,一个批次中最旧的一条数据由 step 1 产生的模型输出,当前模型由 step 5 产生,则该批次 staleness=4)。同步 RL 的批次 staleness 固定为 0。staleness 越大,则数据陈旧性越严重,对 RL 算法的稳定性挑战也越大,模型效果也更难以保持。
为避免数据陈旧性带来的负面影响,AReaL 在异步 RL 算法上设置超参数 max staleness 𝜂,即只在 staleness 不超过预设值 𝜂 时,提交进行新的数据生成请求。
具体来说,轨迹生成器在每次提交新的请求时,都会通过生成控制器进行申请;控制器维护当前已经被提交的和正在运行的请求数量,只有当新的请求 staleness 不超过 𝜂 限制时才允许被提交到生成引擎处。当 𝜂=0 时,系统等价于跟同步 RL 训练,此时要求用于训练的采样轨迹一定是最新的模型生成的。
方法 2:解耦近端策略优化目标(Decoupled PPO Objective)
为了解决旧数据与最新模型之间的分布差异带来的问题,团队采用了解耦的近端策略优化目标(Decoupled PPO Objective),将行为策略(behavior policy)与近端策略(proximal policy)分离。其中:
-
行为策略(behavior policy)表示用于轨迹采样的策略
-
近端策略(proximal policy)作为一个临近的策略目标,用来约束在线策略的更新
最终,可以得到一个在行为策略生成的数据上进行重要性采样(importance sampling)的 PPO 目标函数:
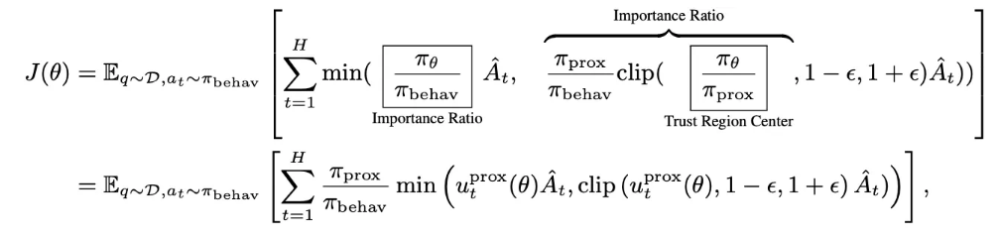
其中,系数
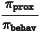
起到了在 token 级别筛选有效训练数据的作用。当
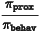
远远小于 1 时,对应数据能够被最新策略采样的概率极低,故而在训练目标中只占据了可以忽略的比重。
效果验证:速度 Max, 性能依旧强劲!
AReaL 团队基于 1.5B 模型在数学任务上设置不同 max staleness 𝜂 进行 Async RL 训练,得到如下训练曲线。在 AReaL 的训练设定中,经典的 PPO 可以清晰看到随着 staleness 增大效果下降,而采用 decoupled PPO objective 后,即使 𝜂 增加到 8,算法依然能够保持训练效果好最终模型性能。
注:max staleness 的绝对值和具体实验设定(learning rate,batch size 等)相关,这里仅比较 AReaL-boba2 系统改进所带来的相对提升。
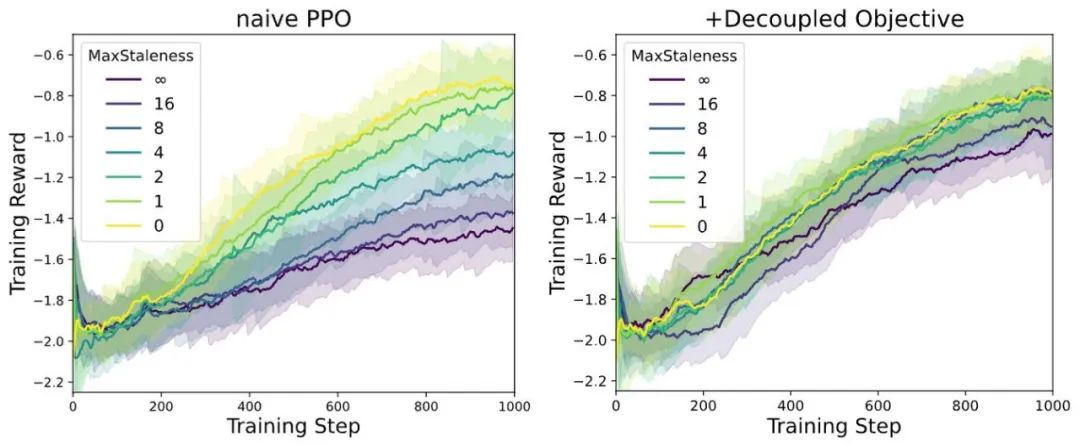
Fig. 5 针对不同 staleness 的算法稳定性结果。左图:经典 PPO 算法在异步 RL 场景下模型效果很容易退化。右图:采用 decoupled PPO objective,在 staleness=8 的情况下模型效果依然无损。
AReaL 团队还把采用不同 max staleness 训练的模型在 AIME24 和 AIME25 数据集上进行评测,采用 decoupled objective 的算法都能在 𝜂 更大的情况下保持更好的模型效果。
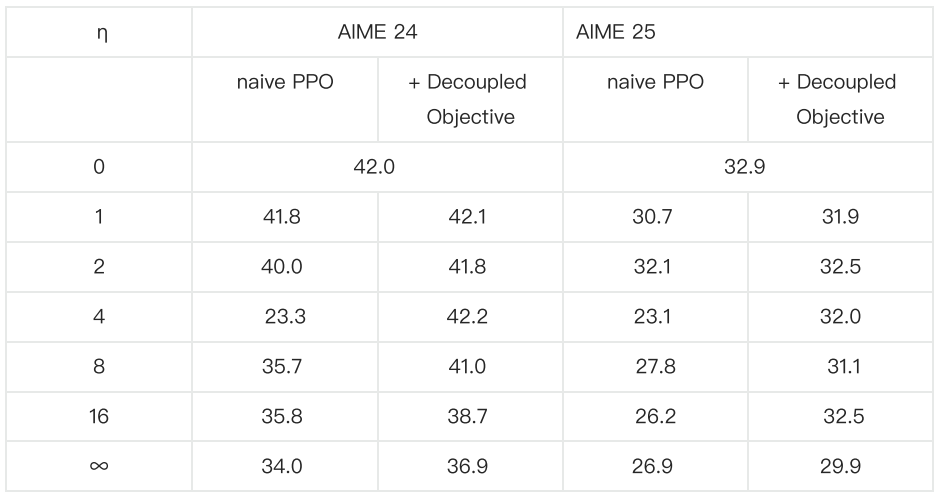
Table 2: 在数学任务(AIME24 & AIME25)上对于不同 max stalness,采用经典 PPO 算法和 decoupled PPO 进行异步 RL 训练最终产生的模型效果比较,decoupled PPO 始终有更好效果。
想深入了解算法原理与实验细节? 请访问原论文查看更多算法细节:
https://arxiv.org/pdf/2505.24298
开源助力:轻松复现 SOTA 代码模型
除了强大的 AReaL-boba² 训练系统,团队也带来了训练数据、训练脚本和评估脚本。团队也提供了完整的技术报告,确保可以在 AReaL 上复现训练结果以及进行后续开发。技术报告中呈现了丰富的技术细节,包括数据集构成、奖励函数设置、模型生成方式、训练过程中的动态数据筛选等等。
快来用 AReaL-boba² 训练你自己的 SOTA 代码模型吧!
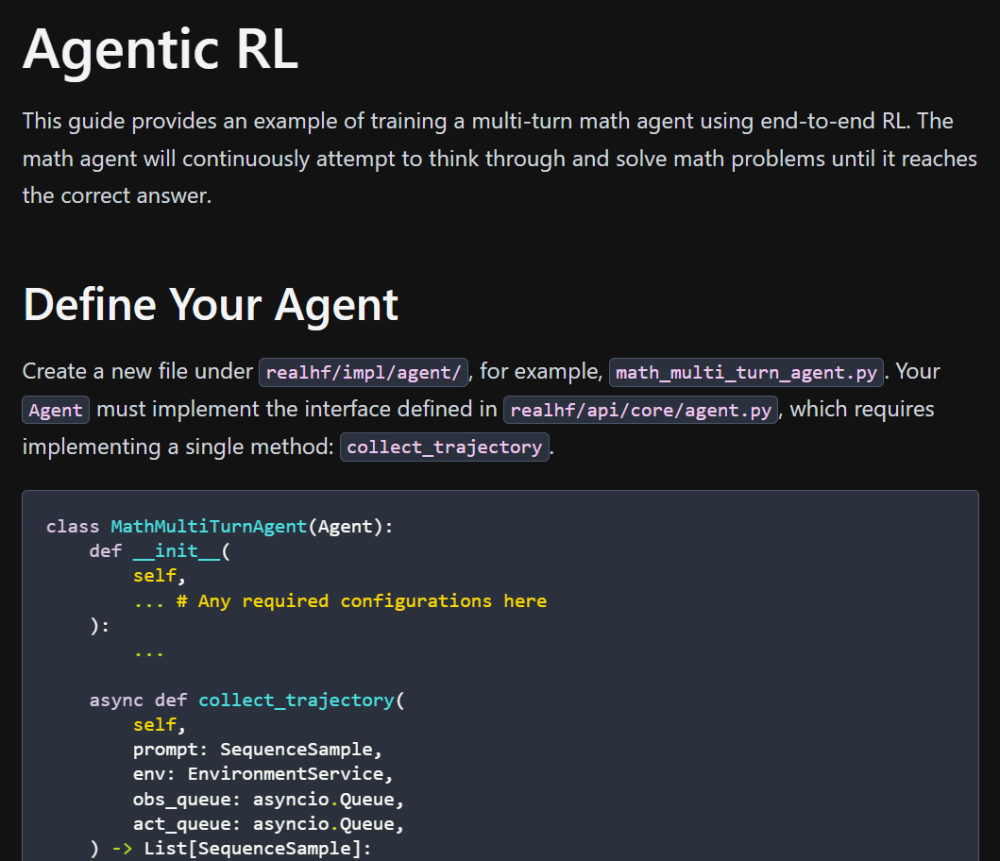
本次 AReaL-boba² 发布也支持多轮 Agentic RL 训练!开发者可以根据自己的需求自由定制智能体和智能体环境,并进行 Agentic RL 训练。目前,AReaL-boba² 提供了一个在数学推理任务上进行多轮推理的例子。
AReaL 团队表示,Agentic RL 功能也正在持续更新中,未来会支持更多 Agentic RL 训练的功能。
最后
AReaL 项目的技术基因深深植根于蚂蚁强化学习实验室与清华交叉信息院吴翼团队长达五年的技术积累融合。蚂蚁集团强化学习实验室此前在金融风控决策、智能推荐系统等场景中积累的分布式训练架构(如支持万级节点的参数服务器设计),与清华交叉信息院在深度强化学习理论层面的突破(如非凸优化场景下的异步收敛性证明)形成了优势互补。这种跨机构的技术融合具体体现在:蚂蚁团队贡献了工业级的异步通信框架(基于自研的低延迟 RPC 协议),而清华团队则提供了多轮对话状态空间压缩算法(将 2048 token 的上下文压缩至 128 维语义向量,同时保留 92% 的关键信息)。
在项目孵化过程中,蚂蚁超算技术团队提供了底层算力支持 ------ 基于集群管理系统对 144 台 A100 服务器的资源调度优化,使 AReaL 在大规模训练时的集群利用率提升至 76%;数据智能实验室则贡献了千万级代码注释对数据集的清洗标注流程(通过半监督学习将代码 - 注释对齐准确率提升至 91.3%)。这些技术支持并非简单叠加,而是经过三轮技术评审会(每轮持续 48 小时)的深度整合,例如将蚂蚁的通信框架与清华的梯度压缩算法结合,实现了跨节点通信延迟从 150ms 降至 38ms 的突破。
AReaL 的技术演进深受多个开源项目的启发:DeepScaleR 的混合精度训练策略为其大模型训练提供了量化方案(将 16B 模型量化至 4bit 时精度损失控制在 1.2% 以内);Open-Reasoner-Zero 的多轮推理状态追踪机制启发了 AReaL 的对话历史缓冲区设计(支持最长 4096 token 的上下文回溯);而 QwQ 框架的轻量级 RLHF 流程则被优化为 AReaL 的三阶段训练范式(预训练 - 监督微调 - 强化学习)。这些启发并非直接复用代码,而是经过二次开发 ------ 例如将 VeRL 的价值函数估计方法与 SGLang 的语言模型适配器结合,形成了独特的策略 - 价值网络架构。
项目代号 "boba"(珍珠奶茶)的命名蕴含着三层技术愿景:"delicious" 对应性能维度,希望模型在代码生成等任务中达到 "口感醇厚" 的 SOTA 效果(如在 LiveCodeBench 榜单上以 69.1 分超越此前所有开源模型);"customizable" 指向架构设计,通过模块化接口(如可插拔的奖励函数模块)让开发者能像调配奶茶配料般自由组合算法组件;"affordable" 则体现资源效率,通过异步训练将单卡日均训练成本从同步框架的 240 美元降至 86 美元,使中小团队也能负担大规模 RL 训练。
目前 AReaL 项目已建立完善的开源协作体系:代码仓库采用双周迭代机制(每两周发布一个 feature branch),文档站点配备实时更新的 API 参考(包含 132 个接口的使用示例),并且在 Gitter 社区设立技术答疑专区(平均响应时间 2.3 小时)。团队现面向全球招募全职工程师(要求具备分布式系统开发经验与 RL 理论背景)和实习生(提供从环境搭建到算法优化的全流程指导),特别欢迎在异步通信、多轮对话策略等方向有研究的开发者加入,共同推进 Agentic AI 在代码理解、科学推理等场景的落地应用。