目录
索引
index,是存储引擎用于快速找到数据的一种数据结构。
MySQL默认使用InnoDB存储引擎,该存储引擎是最重要,使用最广泛的,除非有非常特别的原因需要使用其他存储引擎,否则优先考虑InnoDB。
索引优点:
- 减少服务器需要扫描的数据量
- 帮助服务器避免排序和临时表
- 索引可以将随机I/O变为顺序I/O,提高查询性能
缺点:
- 从空间角度考虑,建立索引需要占用物理空间
- 从时间角度考虑,创建和维护索引都需要花费时间,例如对数据进行增删改时就需要维护索引。
因此在不需要频繁的增删改但需要频繁查的表中创建索引是更好的选择。
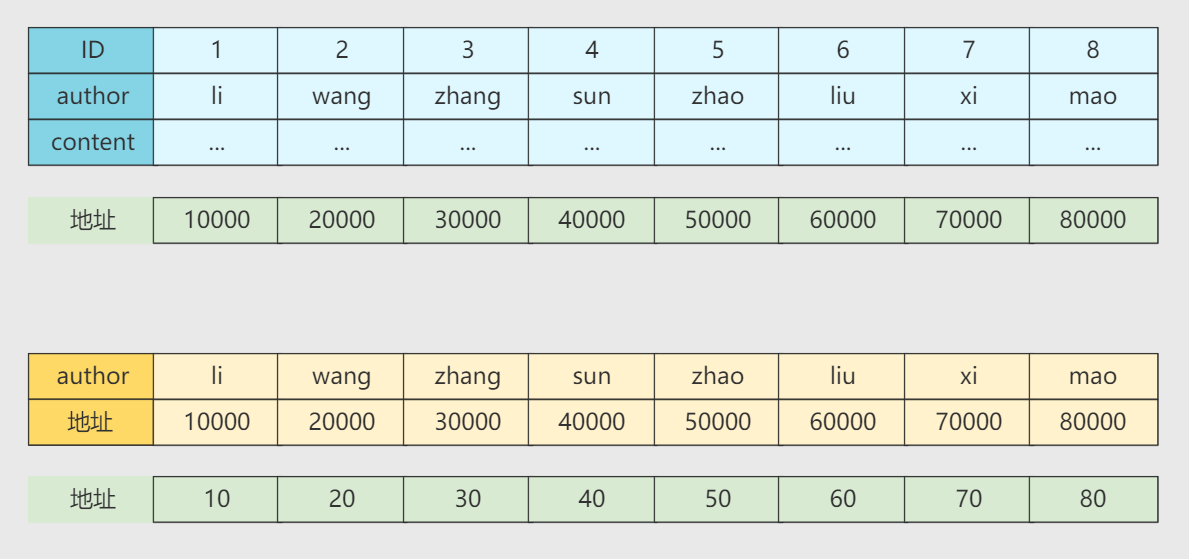
我们建立索引就类似于建议一个图中黄色的一个索引表,通过author字段快速定位,然后找到需要的数据,这只是一个例子方便我们理解,不是真正的索引运行。
常见索引类型
- 哈希索引:基于哈希表实现,查找非常快。但不支持范围查找和排序操作,也不支持部分索引列的查找,只支持等值比较的查询。如果哈希冲突很多的话,索引的维护代价会很高。因此,哈希索引只适用于某些特定场合。在InnoDB中,支持的哈希索引是自适应的,不能人为创建。
哈希索引不支持范围查找的原因:哈希索引只包含哈希值和行指针,通过找哈希值通过行指针来找到要查找的数据,存储时输入的数据通过哈希函数映射出一个哈希值,但是哈希值是无序的,就像1,2映射出的哈希值就可能是5678和1234,因此哈希索引每查询一个就要全盘扫描来寻找下一个要查询的哈希值,因此哈希索引不支持范围查询。
哈希索引不支持排序操作的原因:与不支持范围查找的原因相同,因为每行数据的哈希值不含有任何顺序特性,即使原始字段值是按照某种顺序排列的,经过哈希函数处理后,这些值在哈希索引的存储顺序也是完全被打乱的。所以在对某一列进行排序时哈希索引不能提供任何帮助,因为它的结构中没有保留字段值的顺序信息。
- 全文索引:用于全文搜索的索引类型(倒排索引),可以执行关键字搜索。全文索引有很多限制,例如当数据量很大,内存无法装载全部索引时,搜索速度会非常慢。同时全文索引的维护成本也很大。MyISAM支持全文索引,InnoDB从1.2版本(MySQL5.6)开始支持全文索引。
- B+树索引:B+树索引就是传统意义上的索引,时目前关系型数据库中查找最为常见和最为有效的索引。B+树索引能够加快访问数据的速度,因为存储引擎不再需要进行全表扫描来获取需要的数据。B+树索引是顺序组织存储的,所以很适合查找范围数据,查到范围中的首个数据后就可以一直查找到范围中最后一个数据,不需要全表扫描。B+树索引分为聚簇索引(主键索引)和非聚簇索引(二级索引)。
B+树
主要阐述一下常见的搜寻方法和B+树怎么发展出来的
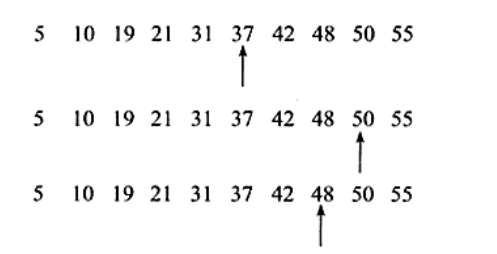
二分查找法
从5,10,19,21,31,37,42,48,50,55中查找48,使用二分查找法只需3次。如果顺序查找需要8次。
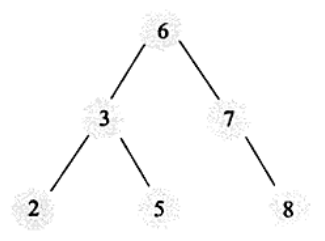
二叉搜索树和平衡二叉树
二叉搜索树,左子节点小于父节点的值,右子节点大于父节点的值。如果我们需要查找8,需要3次,而顺序查找需要6次。
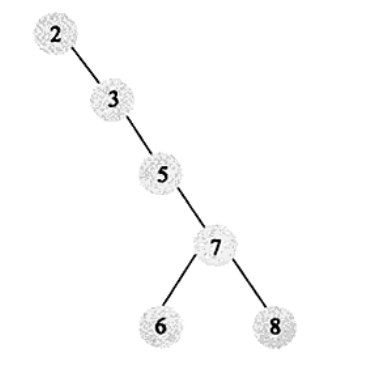
同样是二叉搜索树,下图的情况查找效率会很低,从而引出平衡二叉树(AVL树),平衡二叉树要求任何节点的子树高度最大差为1。平衡性确保查找的数独可以很快,避免了下图二叉搜索树的极端情况,即树退化成链表
B树和B+树
平衡二叉树随着节点的增加,树的高度会越来越高,会增加磁盘的I/O次数,影响查询效率,从而引出了B树,B树不限制一个节点只能由2个子节点,从而降低树的高度。
B树可以将节点的大小优化为磁盘块的大小,每次读取可以有效加载多个节点,B树常用于数据库等需要高效访问磁盘的场景。
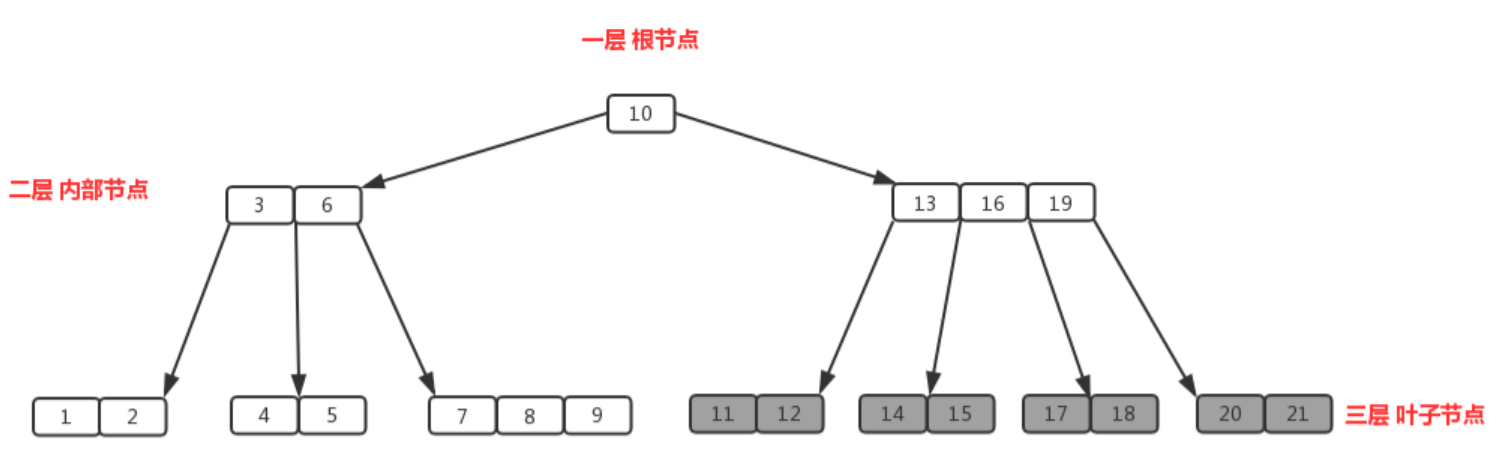
B+树是对B树的升级,B+树只有叶子节点存数据,非叶子节点只存索引。叶子节点包含所有索引,叶子节点构成一个有序链表,范围查找更快。由于非叶子节点只存索引,B+树比B树的非叶子节点可以存更多索引,高度更低,磁盘I/O次数更少。
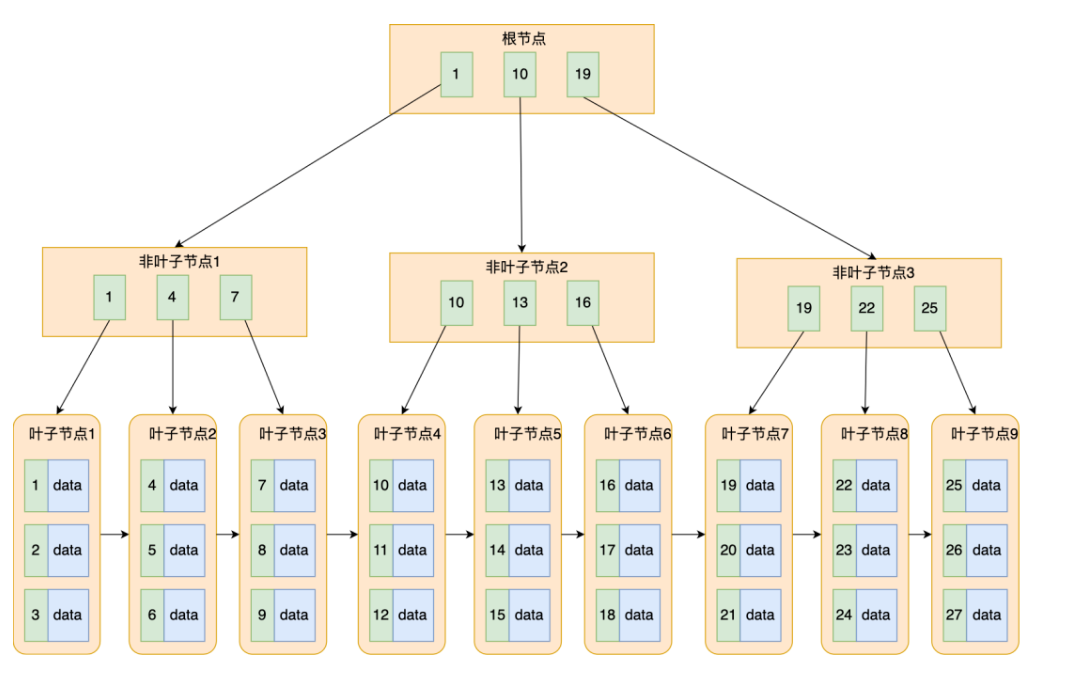
B+树范围搜索更快的原因:
由两张图我们可以看出B+树的叶子节点构成了一个有序链表,而B树则没有组成一个有序链表,如果要查1---10条数据,B+树找到第1条数据之后就可以沿着链表一直找到第10条,但B树找到第1条数据后可以找到第2条但是第3条记录就需要重新扫描去找,因此B+树的范围索引更快。