一:背景
1. 讲故事
前段时间有位朋友微信上找到我,说他们docker中的采集程序出现了CPU爆高的情况,让我帮忙看下怎么回事,自己抓了个dump,感觉这位朋友动手能力还是比较强的,可能调试这块知识不熟悉,不知道如何分析,既然找到我,那就给他分析下吧。
二:CPU爆高分析
1. 为什么会爆高
在动手观察CPU是否爆高之前,我一般都会先看一下这个cpu的能力怎么样,在 windows 上相信大家都知道用 !cpuid 轻松观察,但在 linux 上相对来说麻烦点,但也有两种方式。
- 观察 heap 个数
由于是网站类型,默认是 servergc,而servergc有一个特性就是堆个数与逻辑核保持一致,所以观察heap的个数可以间接得到,使用 !eeversion 或 !eeheap -gc 命令,输出如下:
C#
0:000> !eeversion
4.700.20.51601 (3.x runtime)
4.700.20.51601 @Commit: d989459717cbce34262060c4b8b949185033e379
Server mode with 2 gc heaps
SOS Version: 8.0.10.10501 retail build
0:000> !eeheap -gc
========================================
Number of GC Heaps: 2
----------------------------------------
Heap 0 (0000000000cd4aa0)
generation 0 starts at 7f509cc107d8
generation 1 starts at 7f509cb84f80
generation 2 starts at 7f509bfff000
ephemeral segment allocation context: none
Small object heap
segment begin allocated committed allocated size committed size
7f509bffe000 7f509bfff000 7f509ccccfa8 7f509cec0000 0xccdfa8 (13426600) 0xec2000 (15474688)
Large object heap starts at 7f529bfff000
segment begin allocated committed allocated size committed size
7f529bffe000 7f529bfff000 7f529c30c268 7f529c30d000 0x30d268 (3199592) 0x30f000 (3207168)
------------------------------
Heap 1 (0000000000d30950)
generation 0 starts at 7f519cf7fcb0
generation 1 starts at 7f519cf10788
generation 2 starts at 7f519bfff000
ephemeral segment allocation context: none
Small object heap
segment begin allocated committed allocated size committed size
7f519bffe000 7f519bfff000 7f519d018728 7f519d1fe000 0x1019728 (16881448) 0x1200000 (18874368)
Large object heap starts at 7f52abfff000
segment begin allocated committed allocated size committed size
7f52abffe000 7f52abfff000 7f52ac45bb10 7f52ac45c000 0x45cb10 (4573968) 0x45e000 (4579328)
------------------------------
GC Allocated Heap Size: Size: 0x2451448 (38081608) bytes.
GC Committed Heap Size: Size: 0x282f000 (42135552) bytes.从卦中可以看到,当前heap=2,尼玛。。。这 docker 只有两个核呀。。。。这跑啥不都得cpu爆高嘛。。。
有一些基础的朋友可能会立即反驳,heapcount 是可以通过外部手段改的,言外之意就是你看到的可能是幻象。。。那到底是不是幻象呢?这就需要用第二种办法了。。。
- 观察 coreclr 源码
在 coreclr 中其实有大量的全局变量,只要你读过相应的源码,相信很快就能找到一个全局变量 g_num_processors ,参考如下:
C#
0:000> x libcoreclr!*process*
00007f53`45b6e928 libcoreclr!g_num_processors = 2从卦中可以看到,确实当前逻辑核=2,这个是无法修改的。。。
2. 朋友的质疑
当知道cpucore=2的事实之后,我就不想分析了, 跑一个线程就能把cpu干一半,这让我分析个啥。。。告知完朋友之后,让他加逻辑核来解决,但朋友提出了自己的质疑,说他的程序之前CPU不高,为什么现在就高了?希望我能找到问题代码。。。
既然要找原因,那就到各个线程看看有没有特别明显的爆高代码,使用 ~*e !clrstack 命令,仔细观察了下,也没有特别明显的,只有一些Socket,Octopus,SqlServer 等,输出如下:
C#
0:000> ~*e !clrstack
...
OS Thread Id: 0x1b (19)
Child SP IP Call Site
00007F5069FF8CE0 00007f534654f3c7 [InlinedCallFrame: 00007f5069ff8ce0] Interop+Sys.ReceiveMessage(System.Runtime.InteropServices.SafeHandle, MessageHeader*, System.Net.Sockets.SocketFlags, Int64*)
00007F5069FF8CE0 00007f52d082d7db [InlinedCallFrame: 00007f5069ff8ce0] Interop+Sys.ReceiveMessage(System.Runtime.InteropServices.SafeHandle, MessageHeader*, System.Net.Sockets.SocketFlags, Int64*)
00007F5069FF8CD0 00007f52d082d7db ILStubClass.IL_STUB_PInvoke(System.Runtime.InteropServices.SafeHandle, MessageHeader*, System.Net.Sockets.SocketFlags, Int64*)
...
00007F5069FF9D80 00007f52d19d736d Octopus.xxxx.TaskService.GetTemplateTask(System.String)
...
OS Thread Id: 0x23 (27)
Child SP IP Call Site
00007F50617F96B0 00007f534614f7ef [InlinedCallFrame: 00007f50617f96b0] Interop+Sys.WaitForSocketEvents(IntPtr, SocketEvent*, Int32*)
00007F50617F96B0 00007f52d082a7bb [InlinedCallFrame: 00007f50617f96b0] Interop+Sys.WaitForSocketEvents(IntPtr, SocketEvent*, Int32*)
00007F50617F96A0 00007f52d082a7bb ILStubClass.IL_STUB_PInvoke(IntPtr, SocketEvent*, Int32*)
00007F50617F9730 00007f52d0add25c System.Net.Sockets.SocketAsyncEngine.EventLoop() [/_/src/System.Net.Sockets/src/System/Net/Sockets/SocketAsyncEngine.Unix.cs @ 311]
00007F50617F9780 00007f52d0add219 System.Net.Sockets.SocketAsyncEngine+c.<.ctor>b__23_0(System.Object) [/_/src/System.Net.Sockets/src/System/Net/Sockets/SocketAsyncEngine.Unix.cs @ 285]
00007F50617F9790 00007f52cbd74d83 System.Threading.Tasks.Task.InnerInvoke() [/_/src/System.Private.CoreLib/shared/System/Threading/Tasks/Task.cs @ 2445]
00007F50617F97B0 00007f52cbd74b91 System.Threading.Tasks.Task.ExecuteWithThreadLocal(System.Threading.Tasks.Task ByRef, System.Threading.Thread) [/_/src/System.Private.CoreLib/shared/System/Threading/Tasks/Task.cs @ 2378]
00007F50617F9830 00007f52cbd749e8 System.Threading.Tasks.Task.ExecuteEntryUnsafe(System.Threading.Thread) [/_/src/System.Private.CoreLib/shared/System/Threading/Tasks/Task.cs @ 2321]
00007F50617F9850 00007f52cbd8196b System.Threading.Tasks.ThreadPoolTaskScheduler+c.<.cctor>b__10_0(System.Object) [/_/src/System.Private.CoreLib/shared/System/Threading/Tasks/ThreadPoolTaskScheduler.cs @ 36]
00007F50617F9860 00007f52cbd5593a System.Threading.ThreadHelper.ThreadStart(System.Object) [/_/src/System.Private.CoreLib/src/System/Threading/Thread.CoreCLR.cs @ 81]
00007F50617F9BD0 00007f534565d49f [GCFrame: 00007f50617f9bd0]
00007F50617F9CA0 00007f534565d49f [DebuggerU2MCatchHandlerFrame: 00007f50617f9ca0]
...
OS Thread Id: 0x17 (15)
Child SP IP Call Site
00007F506BFFE5F0 00007f534654b35b [InlinedCallFrame: 00007f506bffe5f0] Confluent.Kafka.Impl.NativeMethods.NativeMethods_Debian9.rd_kafka_poll(IntPtr, IntPtr)
00007F506BFFE5F0 00007f52d080fc73 [InlinedCallFrame: 00007f506bffe5f0] Confluent.Kafka.Impl.NativeMethods.NativeMethods_Debian9.rd_kafka_poll(IntPtr, IntPtr)
00007F506BFFE5E0 00007f52d080fc73 ILStubClass.IL_STUB_PInvoke(IntPtr, IntPtr)
00007F506BFFE670 00007f52d080f964 Confluent.Kafka.Producer`2+c__DisplayClass24_0[[System.__Canon, System.Private.CoreLib],[System.__Canon, System.Private.CoreLib]].b__0()只有两个逻辑核,却跑了若干个线程,cpu高也能说的过去,看起来不像是bug代码导致的,而是正常的新陈代谢,总不能让马儿跑,又不让马儿吃草吧。。。 为了进一步确认,让朋友上一下 dotnet-trace。
3. dotnet-trace 跟踪
在Windows之外的系统里,可以使用 dotnet-trace 跟踪,虽然有点弱鸡,但也没有办法,让朋友在 cpu 高的时候开启,很快 trace.nettrace 也抓到了,抓到之后,我们拖到 DotTrace 中看一下,因为他有非常强的可视化视图,这是我比较喜欢他的一个重要原因,也是众多 jetbrains 产品中的唯一一个,截图如下:
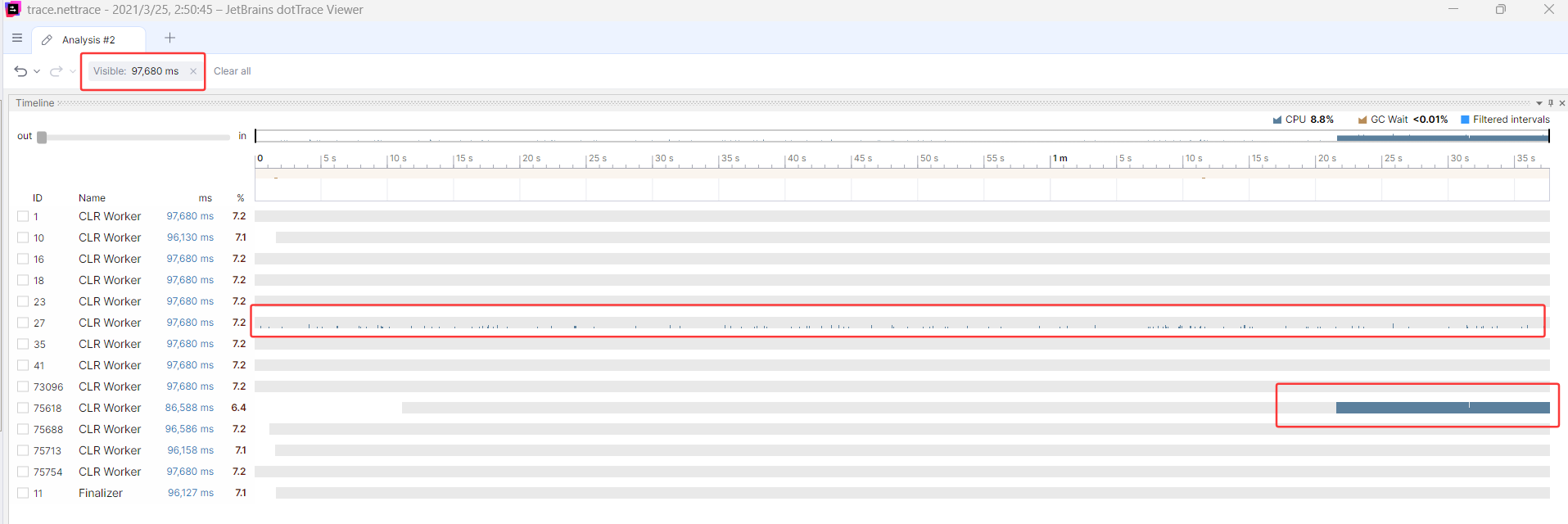
从上面的 timeline 时间轴来看,主要是 tid=27 和 tid=75618 在跑,毕竟只有两个核,coreclr具有线程亲和性绑定。
由于是有关CPU的消耗情况,将 dottrace 的 Thread State 面板中设置为 Running,然后依次观察两个线程,截图如下:
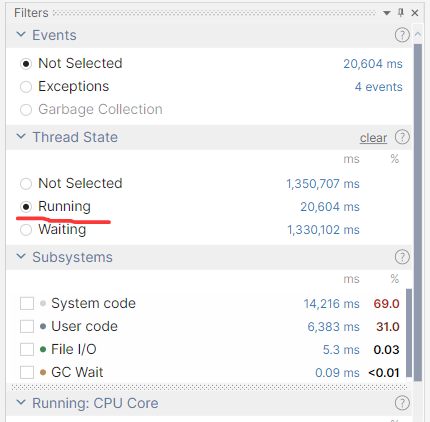
- tid=75618
观察了两个 6s 左右的线程活动区域,都和 HttpMetrics 检测有关,看起来这里面的逻辑不少,截图如下:
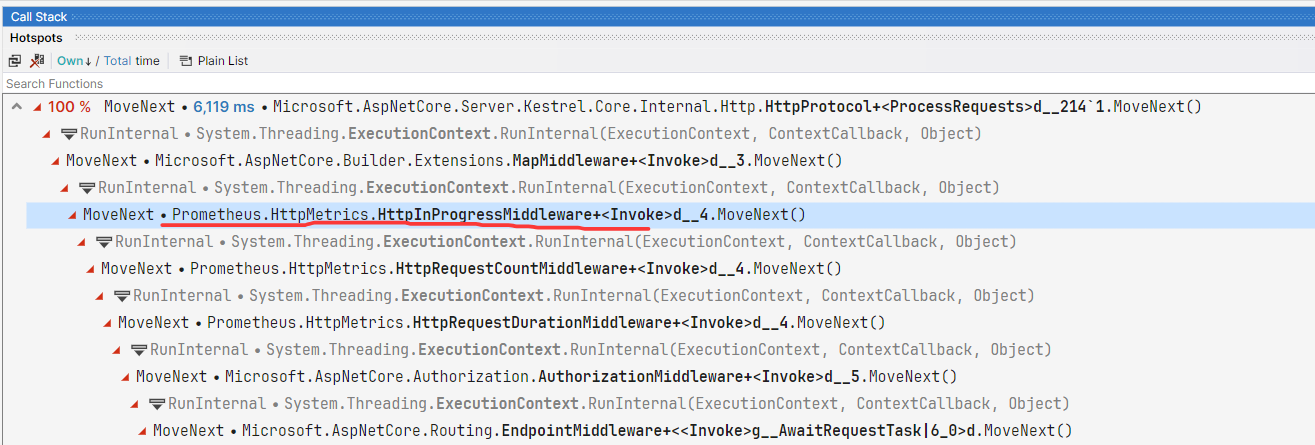
- tid=27
在这个线程中有非常多的点状cpu消耗,也在不断的耗费cpu的时钟周期数,抽了一些点状,发现都和 Kafka 消息订阅有关,截图如下:
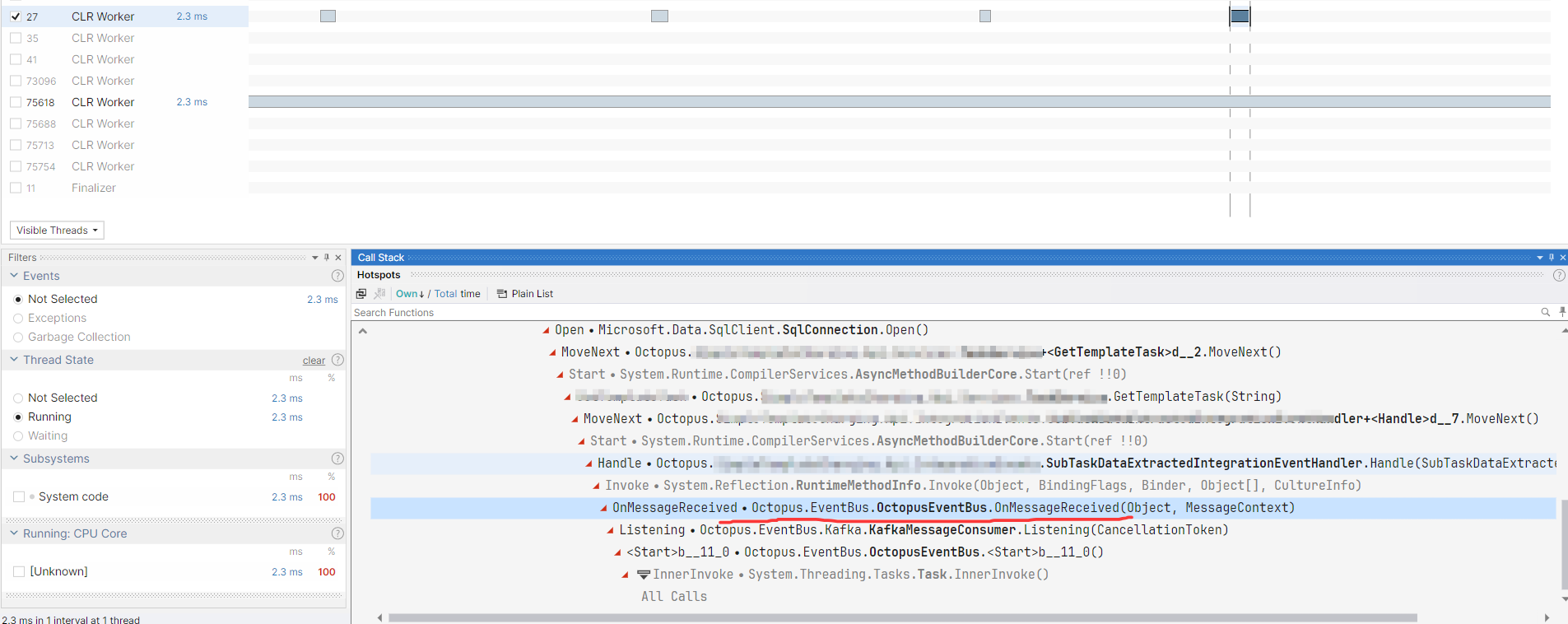
分析到这里,我也只能这么解释了,突然爆高的原因有两个:
- HttpMetrics 检测模块有很大诱因,可以去掉观察。
- Kafka 的消息处理频繁了,可以适当的缓一下。
这也算是比较无奈和无语之下给的建议吧,个人感觉这些逻辑看起来都没有明显的问题,更多的还是要加 cpu 的逻辑核。。。
三:总结
这次cpu爆高事故我个人觉得还是挺无语的,越是极客的程序员越喜欢把资源压榨到极致,不断的研究着如何不让马吃草又让马儿跑,而我是个偏向佛系的人。。。
最后做个推荐,作为JetBrains社区内容合作者,大家有购买jetbrains的产品,可以用我的折扣码
HUANGXINCHENG,有25%的内部优惠哦。
