技术背景
在MindSpore的ops下实现了一个tensor_scatter_add算子。这个算子的作用为,例如给定一个shape为(1,2,3,4)的原始tensor,因为这个tensor有4个维度,所以我们每次去提取一个tensor元素的时候,就需要4个索引。那么假如说我们要提取这个tensor中的5个元素,那么需要用到的索引tensor的shape应该为(5,4)。这样一来就可以提取得到5个元素,然后做一个add的操作,给定一个目标的tensor,它的shape为(5,),我们就可以把这个目标tensor按照索引tensor,加到原始的tensor里面去,这就是tensor_scatter_add算子的作用。但是在PyTorch中没有这个算子的实现,只有scatter_add和index_add,但是这三个算子的作用是完全不一样的,接下来用代码示例演示一下。
代码实现
首先看一个mindspore的tensor_scatter_add算子,其官方文档的介绍是这样的:

以下是一个代码实现的示例:
python
In [1]: import mindspore as ms
In [2]: arr=ms.numpy.zeros((1,2,3,4),dtype=ms.float32)
In [3]: idx=ms.numpy.zeros((5,4),dtype=ms.int64)
In [4]: src=ms.numpy.ones((5,),dtype=ms.float32)
In [5]: res=ms.ops.tensor_scatter_add(arr,idx,src)
In [6]: res.sum()
Out[6]: Tensor(shape=[], dtype=Float32, value= 5)
In [7]: res
Out[7]:
Tensor(shape=[1, 2, 3, 4], dtype=Float32, value=
[[[[ 5.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]],
[[ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]]]])在MindSpore中该算子支持的是挺好的,因为在索引里面其实存在重复索引,并行计算的话可能存在race condition的问题,而MindSpore中还是可以做到正确的加和。在PyTorch中有一个scatter_add算子,但是跟MindSpore里面的tensor_scatter_add完全是两个不一样的算子,以下是一个示例:
python
In [1]: import torch as tc
In [2]: arr=tc.zeros((1,2,3,4),dtype=tc.float32)
In [3]: idx=tc.zeros((5,4),dtype=tc.int64)
In [4]: src=tc.ones((5,),dtype=tc.float32)
In [6]: res=tc.scatter_add(arr,0,idx,src)
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[6], line 1
----> 1 res=tc.scatter_add(arr,0,idx,src)
RuntimeError: Index tensor must have the same number of dimensions as self tensor他这个scatter_add算子就不是为了这种场景而设计的。
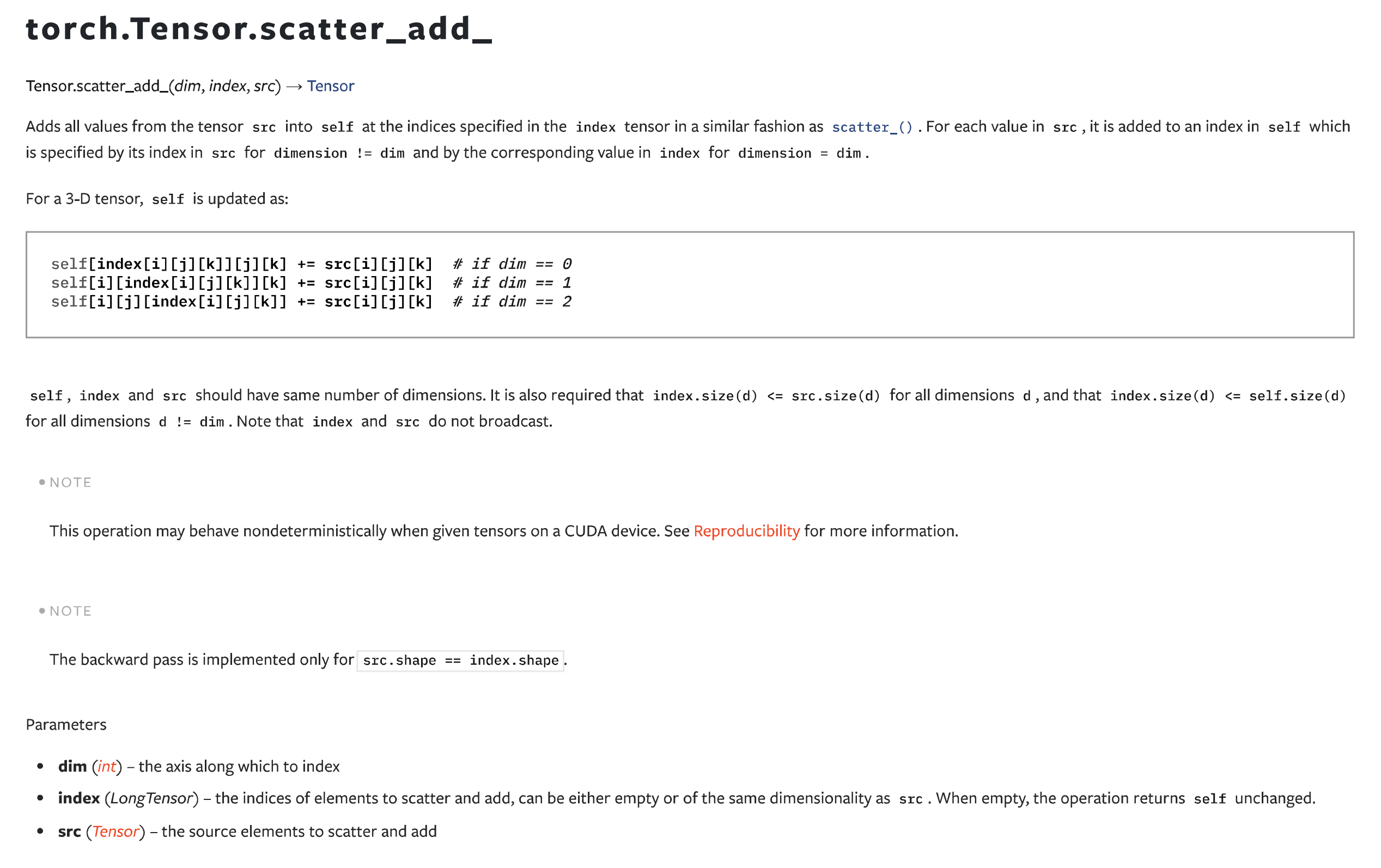
还有另外一个index_add,但是用法也不太相似:
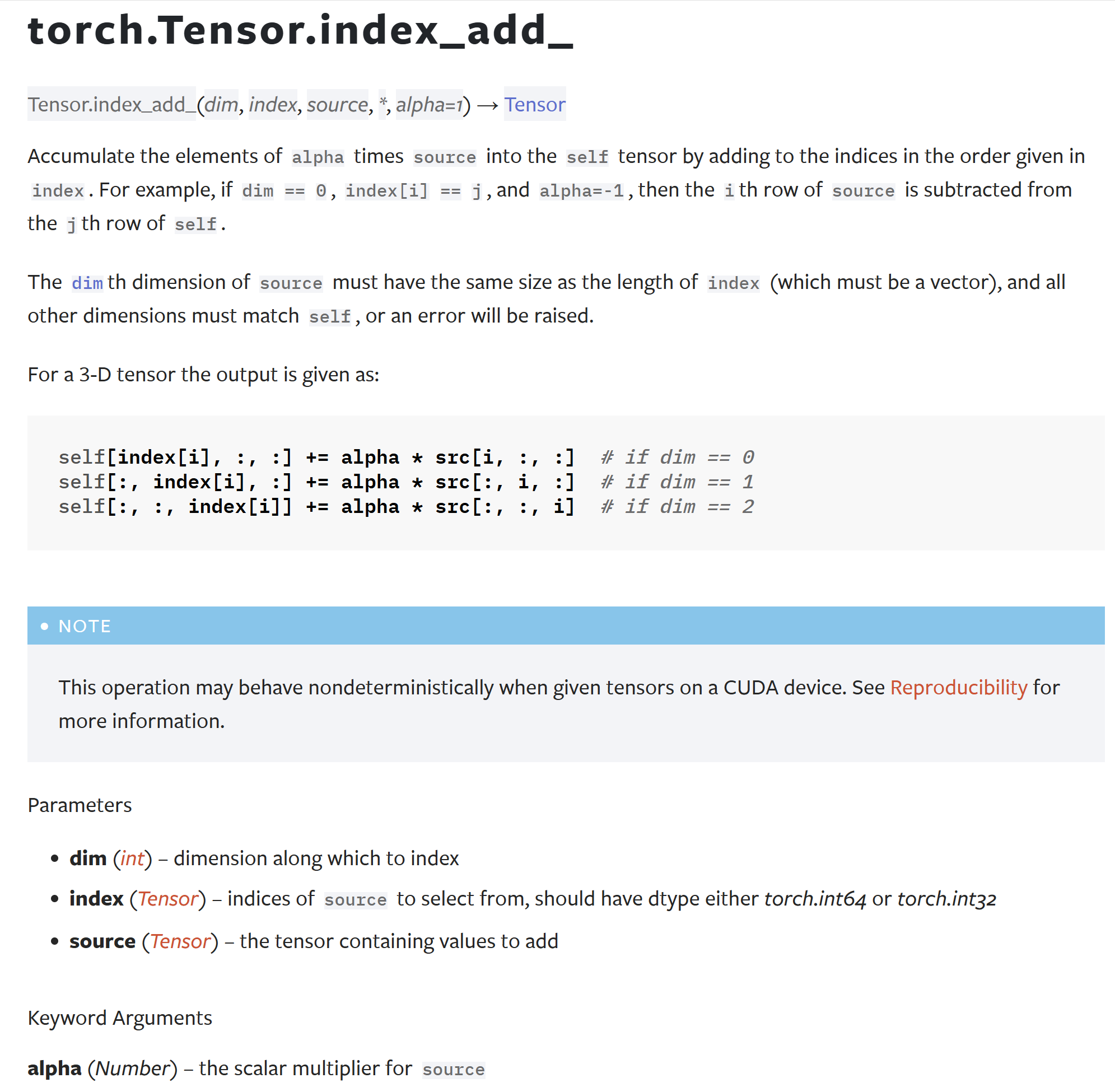
不过如果想要用PyTorch实现这个功能的话,也不是没有办法。还是以这个例子来说,因为原始tensor有4个维度,所以索引到每一个元素需要4个索引编号。在PyTorch中可以直接这样操作(不建议!不建议!不建议!):
python
In [8]: arr[idx[:,0],idx[:,1],idx[:,2],idx[:,3]]+=src
In [9]: arr.sum()
Out[9]: tensor(1.)
In [10]: arr
Out[10]:
tensor([[[[1., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]]])这个例子就可以看出来,直接使用索引进行加和的话,结果是不对的。存在相同索引的情况下,不同的操作之间有可能相互覆盖。所以,非常的不建议这么操作,除非能够确保索引tensor都是唯一的。
总结概要
本文介绍了MindSpore中的tensor_scatter_add算子的用法,可以对一个多维的tensor在指定的index上面进行加和操作。在PyTorch中虽然也有一个叫scatter_add的算子,但是本质上来说两者是完全不一样的操作。
版权声明
本文首发链接为:https://www.cnblogs.com/dechinphy/p/tensor-scatter-add.html
作者ID:DechinPhy
更多原著文章:https://www.cnblogs.com/dechinphy/
请博主喝咖啡:https://www.cnblogs.com/dechinphy/gallery/image/379634.html