华为云Flexus+DeepSeek征文|体验华为云ModelArts快速搭建Dify-LLM应用开发平台并搭建查询数据库的大模型工作流
什么是华为云ModelArts
- 华为云ModelArts ModelArts是华为云提供的全流程AI开发平台,覆盖从数据准备到模型部署的全生命周期管理,帮助企业和开发者高效构建、训练、部署AI模型,实现智能化升级。
开始接触华为云ModelArts Studio大模型即服务平台
- 访问官方地址
https://www.huaweicloud.com/product/modelarts/studio.html

快速搭建Dify-LLM应用开发平台
什么是Dify-LLM应用开发平台
-
Dify-LLM 应用开发平台是一个基于大型语言模型(LLM)的低代码/无代码开发平台,旨在帮助开发者快速构建、部署和管理基于 AI 的应用程序。它提供了可视化的操作界面和丰富的工具,简化了从模型调用到应用上线的全流程,适合不同技术背景的用户使用。
-
华为云提供了一键部署快速搭建Dify平台的功能,使开发者可以快速搭建生产级的生成式AI应用
-
快速搭建的方案架构如下

-
通过VPC与安全组构建安全网络,用户经ELB接入CCE部署的Dify服务集群,结合Embedding与reranker增强AI能力,并依托Redis、PostgreSQL、CSS与OBS实现多样化数据存储与处理,具备高可用、可扩展特性
开始搭建Dify-LLM应用开发平台
-
先进入官网
https://www.huaweicloud.com/solution/implementations/building-a-dify-llm-application-development-platform.html

-
选择一键部署(云服务器单机部署)

-
这里不做操作直接下一步

-
把密码设置好下一步

-
继续下一步

-
点击创建执行计划

-
可以查看费用,然后点击部署

-
可以看到正在按顺序部署

-
等待服务部署完毕,访问Dify-LLM应用开发平台

-
部署完毕,访问Dify-LLM应用开发平台

-
登录Dify-LLM应用开发平台

-
至此搭建Dify-LLM应用开发平台大功告成,不得不说,华为云一键部署Dify平台真是太方便了,全程不需要怎么操作,全是一键搞定
开始搭建大模型工作流
什么是大模型工作流
- 大模型工作流(Large Model Workflow)是指利用大规模预训练语言模型(如GPT、BERT等)完成复杂任务时,所采用的一系列系统化、结构化的处理步骤和方法。它通过将大模型能力与特定任务需求相结合,实现更高效、更可靠的AI应用
开始搭建
- 这次准备做一个大模型工作流,然后然后可以查询数据库数据输出,


-
然后我们需要调用华为云的DeepSeek-V3-32K模型作为基底大模型
-
安装dify中的大模型插件,OpenAI-API-compatible

-
等待安装完成

-
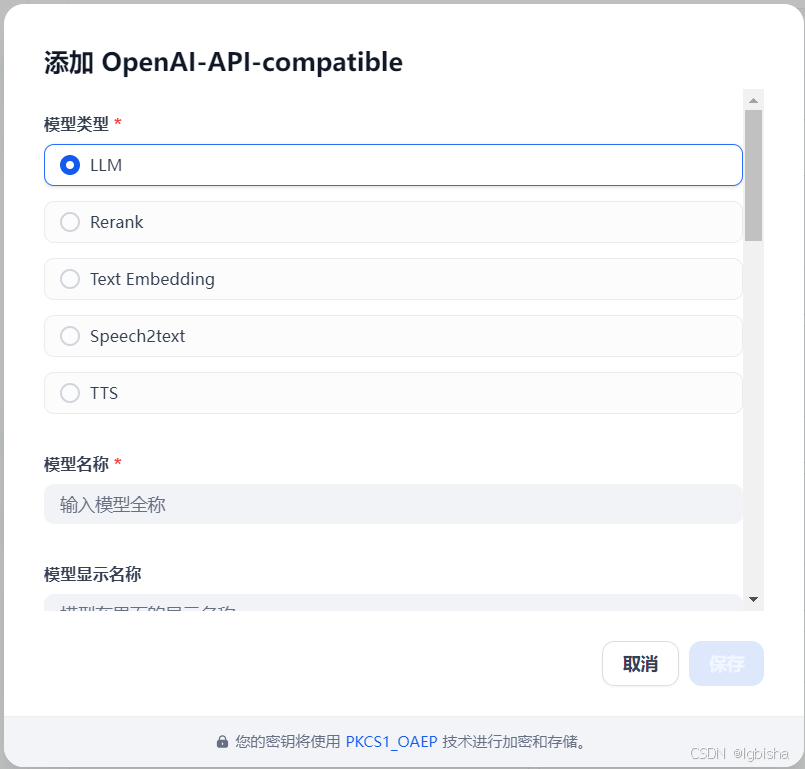
设置大模型
-
密钥从华为云中获取

-
进入api-key管理,创建自己的key,用于调用大模型

-
回来继续配置key,注意接口地址是
https://api.modelarts-maas.com/v1

-
这样大模型就配置完毕了
-
然后安装插件,点击右上角工具列表,搜索
rookie_text2data

-
开始安装
-
这里我们准备的mysql数据库,新建一个test的库

-
然后准备一个用户表与一个部门表
CREATE TABLE
test.user(
idint NOT NULL AUTO_INCREMENT COMMENT '主键id',
namevarchar(30) NULL COMMENT '用户名称',
ageint NULL COMMENT '年龄',
department_idint NULL COMMENT '部门id',
gendervarchar(255) NULL COMMENT '性别(男/女)',
PRIMARY KEY (id)
) COMMENT = '用户表';CREATE TABLE
test.department(
idint NOT NULL AUTO_INCREMENT COMMENT '主键id',
namevarchar(255) NULL COMMENT '部门名称',
PRIMARY KEY (id)
) COMMENT = '部门表'; -
然后插入一些数据
INSERT INTO
department(name) VALUES
('人力资源部'),
('财务部'),
('技术研发部'),
('市场营销部'),
('客户服务部');INSERT INTO
user(name,age,department_id,gender) VALUES
-- 人力资源部 (部门ID 1)
('张伟', 32, 1, '男'),
('李娜', 28, 1, '女'),
('王芳', 35, 1, '女'),-- 财务部 (部门ID 2)
('赵明', 45, 2, '男'),
('钱静', 30, 2, '女'),
('孙丽', 29, 2, '女'),-- 技术研发部 (部门ID 3)
('周强', 27, 3, '男'),
('吴昊', 31, 3, '男'),
('郑雪', 26, 3, '女'),
('王磊', 33, 3, '男'),-- 市场营销部 (部门ID 4)
('冯敏', 29, 4, '女'),
('陈阳', 34, 4, '男'),
('褚小云', 25, 4, '女'),-- 客户服务部 (部门ID 5)
('卫华', 28, 5, '女'),
('蒋涛', 31, 5, '男'),
('沈月', 24, 5, '女');


- 然后去工作流添加节点


-
配置输入参数与接受参数

-
新增节点模板转换,用于json转换字符串

-
然后添加LLM节点,进行sql检测

你是一位精通mysql的数据库专家,你需要检查sql语句是否存在错误,如果有错就改正,没错就输出结果
回答要求:- 不能包含多余信息
- 必须是可执行的sql语句
- 删除掉Sql中的\n,用空格替换。
json数据: /output
-
然后添加执行sql节点

-
然后跟上面一样把json输出为字符串

-
然后对结果进行分析总结
你是数据分析专家,处理JSON格式SQL查询结果时需要遵守以下核心规则:
- 严格依赖现有数据,直接使用提供的JSON数据进行分析,不质疑数据准确性或完整性
- 禁止数据编造,当数据字段为[]、空或None时,必须回复"没有查询到相关数据"
不得自行推断或补充不存在的数据 - 高效分析原则,无需重复验证数据条件/时间范围/类别(默认数据已符合用户查询条件)
避免不必要的重复筛选操作 - 格式要求,输入数据为JSON结构
输出保持简洁,但需完整包含上述所有关键点
数据:/output
问题:/test
Sql语句:/text
回答要求:
1.以表格方式列出数据。
2.提供分析和建议。
3.提供查询的Sql语句。

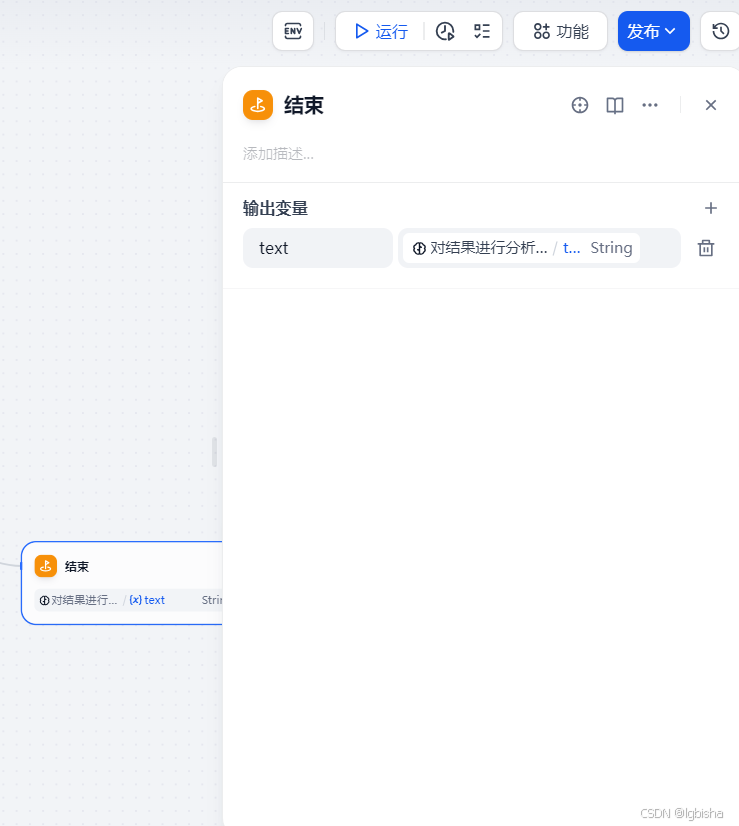
- 添加结束节点并发布

-
然后点击运行进行简单测试

-
至此查询数据库的大模型工作流就见好了
欢迎大家一起加入华为云
