近日,快手推荐模型团队提出了一个端到端生成式推荐系统 OneRec,该系统采用 Encoder-Decoder 架构,引入了基于奖励机制的偏好对齐方法,借助强化学习增强模型效果,可在奖励模型引导下直接生成契合用户偏好的视频内容。通过极致的性能优化,OneRec 在推荐模型 FLOPs 提升 10 倍的同时,大幅削减了通信和存储等运营成本近 90%。目前,OneRec 已在快手/快手极速版双端承接 25%的线上流量,带动 APP 停留时长分别提升 0.54%和 1.24%。

当生成式架构重塑 AI 技术栈时,推荐系统却仍受困于模块化设计的"算力泥潭"------传统级联架构导致的算力碎片化、优化不一致等问题,限制了这一核心基础设施的创新步伐。为此,快手技术团队提出了端到端生成式推荐新范式「OneRec」。
【主要贡献】
-
单阶段编码器-解码器生成框架:该框架巧妙利用 Encoder 对用户全生命周期行为序列进行压缩处理,以此实现精准的兴趣建模,同时基于 MoE 架构的 Decoder 具备超大规模参数扩展能力,有力保障了短视频推荐的端到端精准生成。
-
引入了基于奖励机制的偏好对齐方法:通过奖励反馈机制,并借助强化学习增强模型效果,模型能够敏锐捕捉到更为细粒度的用户偏好信息。为此,OneRec 精心设计并搭建了一套多维度奖励系统,涵盖偏好奖励、格式奖励、工业场景奖励,全方位助力模型理解用户偏好。
-
首个工业级端到端生成式推荐落地方案:本系统在快手主站/极速版双端短视频推荐主场景完成验证。为期一周、覆盖 5% 流量 的 A/B 测试表明,纯生成式模型 (OneRec ) 仅通过强化学习对齐用户偏好,即达到与原复杂级联系统相当的效果。叠加奖励模型选择策略 (OneRec with RM Selection) 后,更实现了用户停留时长显著提升 (主站 +0.54%,极速版 +1.24%),以及 7 日用户生命周期 (LT7) 增长(主站+0.05%,极速版+0.08%)的业务突破。
下图(左)展示了快手 / 快手极速版中 OneRec 与级联推荐架构的 Online 性能比较,图(中)展示了 OneRec 与 Linear、DLRM、SIM 的 FLOPs 比较,图(右)展示了 OneRec 与级联推荐架构的 OPEX 对比,以及和链路中计算复杂度最高的精排模型 SIM 的 MFU 对比。

一、传统推荐系统框架的局限性
推荐系统是一种基于用户历史行为、物品属性以及上下文信息,通过模型算法来预测用户偏好并主动推送个性化信息的信息过滤技术。在个性化新闻推送、音乐推荐、视频推荐以及商品推荐等众多场景中,推荐系统都发挥着至关重要的作用。
传统推荐系统通常采用召回->粗排->精排的多层级联架构模式,以平衡系统时延和效果,然而在实际应用中,却面临着三大核心瓶颈:
**其一:算力效率低下:**以快手为例的分析显示,即使是在推荐系统中计算复杂度最高的精排模型(SIM),在旗舰版 GPU 上进行训练和推理时,其 MFU 分别仅为 4.6%和 11.2%。与之形成鲜明对比的是,大语言模型在 H100 上的 MFU 能够达到 40%-50%的水平。
其二:目标函数相互冲突。平台需要同时优化用户、创作者和生态系统的数百个目标,这些目标在不同阶段相互掣肘,导致系统整体的一致性和效率持续恶化。
更严峻的是,技术代差逐渐拉大。随着 AI 技术的飞速发展,Scaling Law、强化学习等前沿技术不断涌现,并在众多领域取得了显著成效。然而,现有架构却难以将这些最新的 AI 技术成果有效吸纳。同时,由于架构的限制,推荐系统也难以充分利用先进计算硬件的能力。这使得推荐系统与主流 AI 技术的发展步伐逐渐脱节,技术代差日益拉大。
二、快手端到端生成式推荐系统 OneRec
面对这些挑战,快手团队提出端到端生成式推荐系统 OneRec,其核心在于利用 Encoder 压缩用户全生命周期行为序列实现兴趣建模,同时基于 MoE 架构的 Decoder 实现超大规模参数扩展,确保短视频推荐的端到端精准生成。同时配合定制化强化学习框架和极致的训练/推理优化,使模型实现效果和效率的双赢。目前,新系统在以下几个方面的效果显著:
-
可以用远低于线上系统的成本,采用更大的模型,取得更好的推荐效果;
-
在一定范围内,找到了推荐场景的 scaling law;
-
过去很难影响和优化推荐结果的 RL 技术在这个架构上体现出了非常高的潜力;
-
目前该系统从训练到 serving 架构以及 MFU 水平都和 LLM 社区接近,LLM 社区的很多技术可以很好地在这个系统上落地。

2.1 OneRec 模型框架
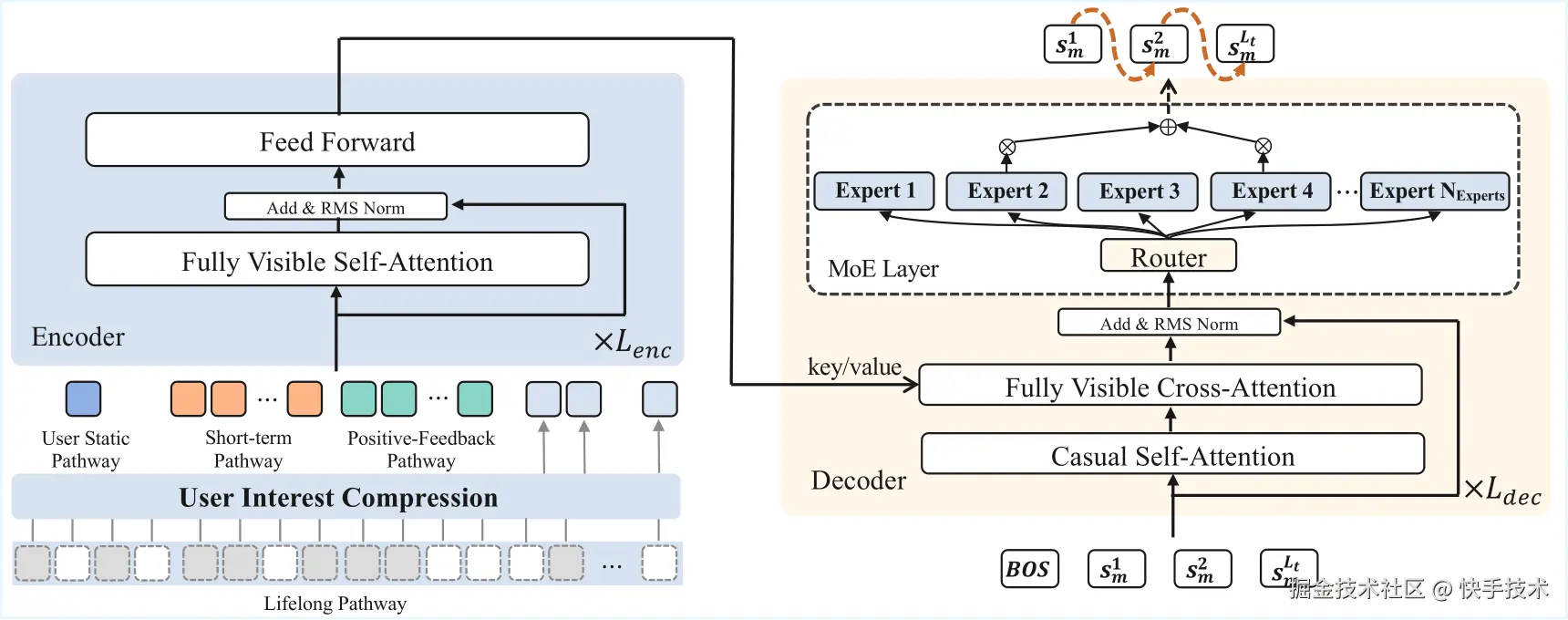
OneRec 采用编码器-解码器架构(如下图),将推荐问题转化为序列生成任务,在训练过程中使用 NTP (Next Token Prediction) 损失函数优化。
2.1.1 语义分词器
面对快手平台上亿级别的视频内容,如何让模型"理解"每个视频成为关键挑战。OneRec 首创了协同感知的多模态分词方案:
● 多模态融合:同时处理视频的标题、标签、语音转文字、图像识别等多维信息;
● 协同信号集成:不仅关注内容特征,更融入用户行为信息建模;
● **分层语义编码:**采用 RQ-Kmeans 技术,将每个视频转化为 3 层粗到细的语义 ID。
2.1.2 编码器-解码器
在训练阶段,OneRec 通过编码器-解码器架构执行下一个 token 预测,进而实现对目标物品的更高效预测。该架构在不同阶段起到的作用分别如下:
● 多尺度用户建模:编码阶段同时考虑用户静态特征、短期行为序列、有效观看序列和终身行为序列;
● 专家混合解码器:解码阶段采用逐点生成策略,通过 Mixture of Experts(MoE)架构提升模型容量和效率。
2.1.3 推荐系统中的 Scaling Laws
参数规模实验是 OneRec 研究中的另一亮点,它试图回答一个 fundamental 的问题:**推荐系统是否同样遵循大语言模型领域已被证实的 Scaling Law?**实验结果清晰地表明,随着模型参数量从 0.015B 到 2.633B 的递增,训练损失呈现出明显的下降趋势。

技术报告中还介绍了包含 Feature Scaling 、Codebook Scaling 和 Infer Scaling 等,极大地利用算力来提升推荐的精度。
2.2 RL 偏好对齐
预训练模型虽然可以通过下一个 token 预测来拟合曝光物品的空间分布,但这些曝光物品来源于过去的传统推荐系统,这导致模型无法突破传统推荐系统的性能天花板。
传统推荐系统通常定义多个目标,如点击量、点赞数、评论数和观看时长,然后通过加权融合每个目标的预测值(xtr)将其组合成一个分数。然而,手动调整这些融合权重既缺乏准确性,又缺乏个性化,并且常常导致目标之间的优化冲突。
为了解决这一挑战,OneRec 引入了基于奖励机制的偏好对齐方法,利用强化学习增强模型效果。通过奖励反馈机制,模型得以感知更为细粒度的用户偏好信息。为此,OneRec 构建了一套综合性的奖励系统,包括如下:
-
偏好奖励(Preference Reward)用于对齐用户偏好
-
格式奖励(Format Reward)确保生成的 token 均为有效格式
-
工业场景奖励(Industrial Reward)以满足各类业务场景的需求

首先,什么样的视频应该被奖励呢?面对这一问题,OneRec 提出采用偏好奖励模型,能基于用户特征,输出对不同目标预测值进行**「个性化融合」**后的偏好分数。过程中,利用该分数「P-Score」作为强化学习的奖励 r_i,并通过 GRPO 的改进版 ECPO(Early-Clipped GRPO)进行优化。结果显示,相较于 GRPO,ECPO 对负优势(A<0)样本进行更严格的策略梯度截断,保留样本的同时防止梯度爆炸使训练更加稳定。

OneRec 在快手两个场景进行了强化学习的消融实验,线上结果显示:在不损失视频曝光量的情况下显著提升 APP 使用时长。

其次,在 OneRec 中,词表空间远大于全部视频数量,这会导致在推理阶段生成的语义 ID 序列可能无法映射回真实视频 ID,即非法生成。OneRec 指出强化学习虽然能提升效果,但由于**「挤压效应」**会导致模型输出的合法性显著下降,不仅推理成本变大且不利于推荐的多样性。
挤压效应:负向优势的梯度会将大部分的概率质量挤压到当前模型的最优输出 o*,大部分合法输出的概率被抹平。

针对这个问题,OneRec 提出「以暴制暴」,用强化学习的方法解决强化学习的问题,引入格式奖励(Format Reward)鼓励合法的输出以缓解挤压效应。OneRec 对两种合法样本的挑选方法进行了实验,并观察到非常有趣的结论:
-
从生成样本中挑选概率最大的 k 个:生成样本的总体合法性先上升后衰减,所挑选样本的合法性很快收敛到 100%
-
从生成样本中随机挑选 k 个:生成样本的总体合法性和所挑选样本的合法性同时上升,未出现衰减。

这些现象表明,如果用概率最大的 k 个样本训练,模型会很快捕捉到奖励的内在机制,从而引发**「Rward Hacking」**现象。该实验不仅验证了格式奖励的有效性,而且表明奖励的准确定义十分重要。
除了以上提到的用户偏好奖励和格式奖励,OneRec 还引入了工业场景奖励,以满足特殊工业需求,如营销号的打压、冷启视频和长尾视频的分发等。
2.3 性能优化
从衡量算力效率的核心指标 MFU(模型浮点运算利用率)来说,传统推荐排序模型长期深陷**"个位数魔咒"**,主要有两方面的原因:
-
一是业务迭代积累的历史包袱,如快手精排模型算子数量高达 15000+个,复杂结构导致无法像 LLM 那样进行深度优化;
-
二是成本与延迟约束下的规模瓶颈,致使单个算子计算密度低下,显存带宽成为性能天花板,GPU 算力利用率长期低于 10%。
而 OneRec 的生成式架构带来破局性变革:通过采用类 LLM 的 encoder-decoder 架构精简组件,将关键算子数量压缩 92%至 1,200 个,配合更大模型规模提升计算密度;同时通过重构推荐链路释放延迟压力,使训练/推理 MFU 分别飙升至 23.7%和 28.6%,较传统方案实现 3-5 倍提升,首次让推荐系统达到与主流 AI 模型比肩的算力效能水平。
除了模型结构的天然优势,团队还针对 OneRec 特性在训练和推理框架层面进行了深度定制优化。
2.3.1 系统深度优化
除了模型结构的天然优势,我们还针对 OneRec 特性在训练和推理框架层面进行了深度定制优化。
训练优化
-
计算压缩:针对同一请求下的多条曝光样本(如一次下发 6 个视频,平均 5 条曝光),这些样本共享用户和 context 特征。我们按请求 ID 分组,避免在 context 序列上重复执行 ffn 计算。同时,利用变长 flash attention,有效避免重复的 kv 访存操作,进一步提升 attention 的计算密度。
-
Embedding 加速优化:针对单样本需训练 1000 万以上 Embedding 参数的挑战,我们自研了 SKAI 系统,实现了 Embedding 训练全流程在 GPU 上完成,避免 GPU/CPU 同步中断;通过统一 GPU 内存管理(UGMMU)大幅减少 kernel 数量;采用时间加权 LFU 智能缓存算法充分利用数据的时间局部性,并通过 Embedding 预取流水线将参数传输与模型计算重叠,有效隐藏传输延迟,整体大幅提升了 Embedding 训练效率。
-
高效并行训练:采用数据并行 + ZERO1 + 梯度累计的训练策略。选择 ZERO1 是因为模型 Dense 参数较小,单 GPU 可容纳完整模型参数和梯度,在 interleaving 多个 macro batch 时能够减少数据并行组的同步开销。
-
混合精度与编译优化:绝大部分 op 使用 BFloat16 进行运算,对全图进行编译优化,通过计算图优化和 kernel fusion 减少计算开销。
推理优化
OneRec 在推理阶段采用大 beam size(通常为 512)来提升生成式推荐的多样性和覆盖率。面对如此大规模的并行生成需求,我们从计算复用、算子优化、系统调度等多个维度进行了深度优化:
-
计算复用优化: OneRec 针对大规模并行生成需求,通过多种计算复用手段大幅提升效率:首先,同一用户请求下 encoder 侧特征在所有 beam 上完全一致,因此 encoder 只需前向计算一次,避免了重复计算;其次,decoder 生成过程中 cross attention 的 key/value 在所有 beam 间共享,显著降低显存占用和算力消耗;同时,decoder 内部采用 KV cache 机制,缓存历史步骤的 key/value,进一步减少重复计算。
-
算子级优化: OneRec 推理阶段全面采用 Float16 混合精度计算,显著提升了计算速度并降低了显存占用。同时,针对 MoE、Attention、BeamSearch 等核心算子,进行了深度 kernel 融合和手工优化,有效减少了 GPU kernel 启动和内存访问次数,全面提升了算子计算效率和整体吞吐能力。
-
系统调度优化: OneRec 通过动态 Batching 策略,根据当前系统负载和请求延迟实时调整 batch 的大小,尽可能提升每个 batch 的并发度。这种方式能够有效减少单次请求的平均访存带宽消耗,进一步提升整体计算效率和系统吞吐。
通过以上系统性的优化策略,OneRec 在性能方面取得了显著提升。在算力利用率方面,训练和推理的 MFU 分别达到了 23.7% 和 28.8% ,相比传统推荐模型的 4.6% 和 11.2% 有了大幅改善。运营成本降低至传统方案的 10.6%,实现了接近 90% 的成本节约。
2.4 Online 实验效果
OneRec 在快手主站/极速双端 app 的短视频推荐主场景上均进行了严格实验。通过为期一周 5%流量的 AB 测试,纯生成式模型(OneRec)仅凭 RL 对齐用户偏好即达到原有复杂推荐系统同等效果,而叠加奖励模型选择策略(OneRec with RM Selection)后更实现停留时长提升 0.54%/1.24% 、7 日用户生命周期(LT7)增长 **0.05%/0.08%**的显著突破------须知在快手体系中,0.1%停留时长或 0.01% LT7 提升即具统计显著性。
更值得关注的是,模型在点赞、关注、评论等所有交互指标上均取得正向收益(如下表),证明其能规避多任务系统的"跷跷板效应"实现全局最优。该系统目前已经在短视频推荐主场景承担 25%的 QPS。

除了短视频推荐的消费场景之外,OneRec 在快手本地生活服务场景同样表现惊艳:AB 对比实验表明该方案推动 GMV 暴涨 21.01%、订单量提升 17.89%、购买用户数增长 18.58%,其中新客获取效率更实现 23.02%的显著提升。
目前,该业务线已实现 100%流量全量切换。值得注意的是,全量上线后的指标增长幅度较实验阶段进一步扩大,充分验证了 OneRec 在不同业务场景的泛化能力。
三、总结和展望
OneRec 通过创新的生成式架构重构推荐系统的技术范式。与此同时经过极致的工程优化,在效果与效率双重维度上实现全面超越。当然,新系统还有很多地方未完善,报告中仍指出了三个待突破的方向:
-
推理能力:Infer 阶段 step 的 scaling up 能力尚不明显,这预示着 OneRec 还不具备很强的推理能力;
-
多模态桥接:构建用户行为模态与 LLM/VLM 的原生融合架构,借鉴 VLM 中的跨模态对齐技术,实现用户行为序列、视频内容与语义空间的统一学习,成为一个原生全模态的模型;
-
完备的 Reward System:目前 Reward System 的设计还比较初级。在 OneRec 端到端的架构下,Reward System 既能影响在线结果也能影响离线训练,我们期望利用该能力引导模型更好地理解用户偏好和业务需求,提供更优的推荐体验。
可以预见,随着 AI 能力的持续融入,OneRec 将释放出更强大的能力,在更广泛的推荐应用场景中创造更大的业务价值。