参考openGauss官方文档介绍:
查看 Wdr报告 | openGauss文档 | openGauss社区
在Oralce数据库中,遇到性能问题,我们通常会查看有无对应时间段的快照,生成awr报告并进一步分析(AWR是Automatic Workload Repository的简称,中文叫着自动工作量资料档案库。是Oracle数据库用于收集、管理和维护数据库整个运行期间和性能相关统计数据的存储仓库,是Oracle数据库性能调整和优化的基础。awr收集到的数据会被定期保存到磁盘,可以从数据字典查询以及生成性能报告。)。AWR报告整个数据库在运行期间的现状或者说真实状态只有在被完整记录下来,才是可查,可知,可比较,可推测或者说为未来性能优化调整提供支撑建议的基础。
在opengauss数据库中,也有着这样的"awr",它叫做------wdr。WDR是(Workload Diagnosis Report)负载诊断报告,是openGauss的工作负载诊断报告,常用于判断openGauss长期性能问题。
前提:
生成WDR报告的前提条件是,打开参数enable_wdr_snapshot。确认当前已按照的openGauss数据库是否打开WDR报告的参数,需要通过下图登录数据库进行查询。enable_wdr_snapshot的值为on表示打开,off表示关闭
打开WDR报告功能:
#gs_guc reload -N all -I all -c "enable_wdr_snapshot = on"
#select name,setting from pg_settings where name like '%wdr%';

以下介绍WDR报告的参数:
enable_wdr_snapshot
参数说明: 是否开启数据库监控快照功能。
该参数属于 SIGHUP 类型参数,请参考表GUC 参数分类中对应设置方法进行设置。
取值范围: 布尔型
on: 打开数据库监控快照功能。
off: 关闭数据库监控快照功能。
默认值: off
wdr_snapshot_retention_days
参数说明: 系统中数据库监控快照数据的保留天数,超过设置的值之后,系统每隔 wdr_snapshot_interval 时间间隔,清理 snapshot_id 最小的快照数据。
该参数属于 SIGHUP 类型参数,请参考表GUC 参数分类中对应设置方法进行设置。
取值范围:整型,1 ~ 8。
默认值: 8
wdr_snapshot_query_timeout
参数说明: 系统执行数据库监控快照操作时,设置快照操作相关的 sql 语句的执行超时时间。如果语句超过设置的时间没有执行完并返回结果,则本次快照操作失败。
该参数属于 SIGHUP 类型参数,请参考表GUC 参数分类中对应设置方法进行设置。
取值范围:整型,100 ~ INT_MAX(秒)。
默认值: 100s
wdr_snapshot_interval
参数说明: 后台线程 Snapshot 自动对数据库监控数据执行快照操作的时间间隔。
该参数属于 SIGHUP 类型参数,请参考表GUC 参数分类中对应设置方法进行设置。
取值范围:整型,10 ~ 60(分钟)。
默认值: 1h
快照表:
snapshot.snapshot:记录当前系统中存储的 WDR 快照信息
snapshot_id:WDR快照序列号
start_ts:WDR快照的开始时间
end_ts:WDR快照的结束时间

snapshot.tables_snap_timestamp:记录所有表的 WDR 快照信息
snapshot_id:WDR快照序列号
db_name:WDR snapshot对应的database
tablename:WDR snasphot对应的table
start_ts:WDR快照的开始时间
end_ts:WDR快照的结束时间

WDR 数据表:
说明:WDR 的数据表保存在 snapshot 这个 schema 下以 snap_开头的表,其数据来源于 dbe_perf 这个 schema 内的视图
postgres=# select relname from pg_class where relname like '%snap_%';
----------------------------------------------------------------------------------------------------------------
snapshot.tables_snap_timestamp -- 记录所有存储的WDR快照中数据库、表对象、数据采集的开始、结束时间
snapshot.snapshot -- 记录当前系统中存储的WDR快照数据的索引信息、开始、结束时间
snapshot.snapshot_pkey -- snapshot.snapshot表的primary key
snapshot.snap_seq -- 序列
snapshot.snap_global_os_runtime -- 操作系统运行状态信息
snapshot.snap_global_os_threads -- 线程状态信息
snapshot.snap_global_instance_time -- 各种时间消耗信息(时间类型见instance_time视图)
snapshot.snap_summary_workload_sql_count -- 各数据库主节点的workload上的SQL数量分布
snapshot.snap_summary_workload_sql_elapse_time -- 数据库主节点上workload(业务)负载的SQL耗时信息
snapshot.snap_global_workload_transaction -- 各节点上的workload的负载信息
snapshot.snap_summary_workload_transaction -- 汇总的负载事务信息
snapshot.snap_global_thread_wait_status -- 工作线程以及辅助线程的阻塞等待情况
snapshot.snap_global_memory_node_detail -- 节点的内存使用情况
snapshot.snap_global_shared_memory_detail -- 共享内存上下文的使用情况
snapshot.snap_global_stat_db_cu -- 数据库的CU命中情况,可以通过gs_stat_reset()进行清零
snapshot.snap_global_stat_database -- 数据库的统计信息
snapshot.snap_summary_stat_database -- 汇总的数据库统计信息
snapshot.snap_global_stat_database_conflicts -- 数据库冲突状态的统计信息
snapshot.snap_summary_stat_database_conflicts -- 汇总的数据库冲突状态的统计信息
snapshot.snap_global_stat_bad_block -- 表、索引等文件的读取失败信息
snapshot.snap_summary_stat_bad_block -- 汇总的表、索引等文件的读取失败信息
snapshot.snap_global_file_redo_iostat -- Redo(WAL)相关统计信息
snapshot.snap_summary_file_redo_iostat -- 汇总的Redo(WAL)相关统计信息
snapshot.snap_global_rel_iostat -- 数据对象IO统计信息
snapshot.snap_summary_rel_iostat -- 汇总的数据对象IO统计信息
snapshot.snap_global_file_iostat -- 数据文件IO统计信息
snapshot.snap_summary_file_iostat -- 汇总的数据文件IO统计信息
snapshot.snap_global_replication_slots -- 复制节点的信息
snapshot.snap_global_bgwriter_stat -- 后端写进程活动的统计信息
snapshot.snap_global_replication_stat -- 日志同步状态信息
snapshot.snap_global_transactions_running_xacts -- 各节点运行事务的信息
snapshot.snap_summary_transactions_running_xacts -- 汇总各节点运行事务的信息
snapshot.snap_global_transactions_prepared_xacts -- 当前准备好进行两阶段提交的事务的信息
snapshot.snap_summary_transactions_prepared_xacts -- 汇总的当前准备好进行两阶段提交的事务的信息
snapshot.snap_summary_statement -- SQL语句的全量信息
snapshot.snap_global_statement_count -- 当前时刻执行的DML/DDL/DQL/DCL语句统计信息
snapshot.snap_summary_statement_count -- 汇总的当前时刻执行的DML/DDL/DQL/DCL语句统计信息
snapshot.snap_global_config_settings -- 数据库运行时参数信息
snapshot.snap_global_wait_events -- event等待相关统计信息
snapshot.snap_summary_user_login -- 用户登录和退出次数的相关信息
snapshot.snap_global_ckpt_status -- 实例的检查点信息和各类日志刷页情况
snapshot.snap_global_double_write_status -- 实例的双写文件的情况
snapshot.snap_global_pagewriter_status -- 实例的刷页信息和检查点信息
snapshot.snap_global_redo_status -- 实例的日志回放情况
snapshot.snap_global_rto_status -- 极致RTO状态信息
snapshot.snap_global_recovery_status -- 主机和备机的日志流控信息
snapshot.snap_global_threadpool_status -- 节点上的线程池中工作线程及会话的状态信息
snapshot.snap_statement_responsetime_percentile -- SQL响应时间P80、P95分布信息
snapshot.snap_global_statio_all_indexes -- 数据库中的每个索引行、显示特定索引的I/O的统计
snapshot.snap_summary_statio_all_indexes -- 汇总的数据库中的每个索引行、显示特定索引的I/O的统计
snapshot.snap_global_statio_all_sequences -- 数据库中每个序列的每一行、显示特定序列关于I/O的统计
snapshot.snap_summary_statio_all_sequences -- 汇总的数据库中每个序列的每一行、显示特定序列关于I/O的统计
snapshot.snap_global_statio_all_tables -- 数据库中每个表(包括TOAST表)的I/O的统计
snapshot.snap_summary_statio_all_tables -- 汇总的数据库中每个表(包括TOAST表)的I/O的统计
snapshot.snap_global_stat_all_indexes -- 数据库中的每个索引行,显示访问特定索引的统计
snapshot.snap_summary_stat_all_indexes -- 汇总的数据库中的每个索引行,显示访问特定索引的统计
snapshot.snap_summary_stat_user_functions -- 汇总的数据库节点用户自定义函数的相关统计信息
snapshot.snap_global_stat_user_functions -- 用户所创建的函数的状态的统计信息
snapshot.snap_global_stat_all_tables -- 每个表的一行(包括TOAST表)的统计信息
snapshot.snap_summary_stat_all_tables -- 汇总的每个表的一行(包括TOAST表)的统计信息
snapshot.snap_class_vital_info -- 校验相同的表或者索引的Oid是否一致
snapshot.snap_global_record_reset_time -- 重置(重启,主备倒换,数据库删除)openGauss统计信息时间
snapshot.snap_summary_statio_indexes_name -- 表snap_summary_statio_all_indexes的索引
snapshot.snap_summary_statio_tables_name -- 表snap_summary_statio_all_tables的索引
snapshot.snap_summary_stat_indexes_name -- 表snap_summary_stat_all_indexes的索引
snapshot.snap_class_info_name -- 表snap_class_vital_info的索引生成WDR报告一般操作步骤:
1.执行以下SQL命令,查询已经生成的快照信息。
#select * from snapshot.snapshot;

2.手工生成快照:
#select create_wdr_snapshot();


3.生成WDR报告:
1)指定生成一份 WDR 报告文件:
\a \t \o wdr20240201.html
上述命令涉及参数说明如下:
\a: 切换非对齐模式。
\t: 切换输出的字段名的信息和行计数脚注。
\o: 把所有的查询结果发送至服务器文件里。
服务器文件路径:生成性能报告文件存放路径。用户需要拥有此路径的读写权限。


2)指定快照ID生成WDR报告内容
#select generate_wdr_report(begin_snap_id bigint, end_snap_id bigint, report_type cstring, report_scope cstring, node_name cstring);
参数说明:
begin_snap_id:查询时间段开始的 snapshot 的 id(表 snapshot.snaoshot 中的 snapshot_id)。
end_snap_id:查询时间段结束 snapshot 的 id。默认 end_snap_id 大于 begin_snap_id(表 snapshot.snaoshot 中的 snapshot_id)。
report_type 指定生成 report 的类型。例如,summary/detail/all。summary: 汇总数据;detail: 明细数据;all: 包含 summary 和 detail。
report_scope:指定生成 report 的范围,可以为 cluster 或者 node。cluster: 数据库级别的信息;node:节点级别的信息。
node_name:在 report_scope 指定为 node 时,需要把该参数指定为对应节点的名称。(节点名称可以执行 select * from pg_node_env;查询);在 report_scope 为 cluster 时,该值可以指定为省略、空或者为 NULL。
例如:
select generate_wdr_report(31, 32, 'all', 'cluster',null);
select generate_wdr_report(31, 32, 'all', 'node','dn_6001');
3)关闭WDR报告文件
#\a \t \o

完整的例子:

打开生成的WDR报告:
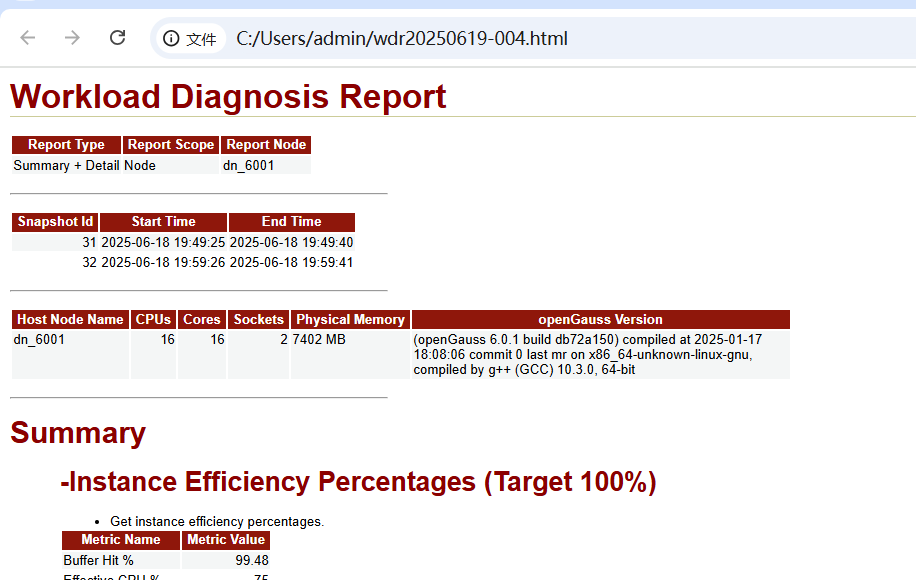
解读WDR报告:
WDR 报告的概况信息
从这一部分我们能得到如下信息:

这一部分是 WDR 报告的概况信息,从这一部分我们能得到如下信息:
| 信息分类 | 信息描述 |
|---|---|
| 报告采集类型 | Summary + Detail,即汇总数据+明细数据 |
| Snapshot 信息 | 使用 snapshot_id 为 31 和 32的快照采集 2025-06-18(19:49 ~ 19:59)的运行信息 |
| 硬件配置 | 16*16 7G内存 |
| 节点名 | dn_6001 |
| openGauss 版本 | openGauss 6 |
相关代码:
第一部分,Report Type/Report Scope/Report Node内容来源于执行generate_wdr_report函数时输入的参数,详见源码"GenReport::ShowReportType(report_params* params)"
第二部分查询SQL:(变量ld-->snapshot_id)
select snapshot_id as "Snapshot Id",
to_char(start_ts, 'YYYY-MM-DD HH24:MI:SS') as "Start Time",
to_char(end_ts, 'YYYY-MM-DD HH24:MI:SS') as "End Time"
from snapshot.snapshot
where snapshot_id = %ld or snapshot_id = %ld;
第三部分查询SQL:(变量ld-->snapshot_id)
select 'CPUS', x.snap_value
from (select * from pg_node_env) t,
(select * from snapshot.snap_global_os_runtime) x
where x.snap_node_name = t.node_name
and x.snapshot_id = %ld
and (x.snap_name = 'NUM_CPUS');
select 'CPU Cores', x.snap_value
from (select * from pg_node_env) t,
(select * from snapshot.snap_global_os_runtime) x
where x.snap_node_name = t.node_name
and x.snapshot_id = %ld
and x.snap_name = 'NUM_CPU_CORES';
select 'CPU Sockets', x.snap_value
from (select * from pg_node_env) t,
(select * from snapshot.snap_global_os_runtime) x
where x.snap_node_name = t.node_name
and x.snapshot_id = %ld
and x.snap_name = 'NUM_CPU_SOCKETS';
select 'Physical Memory', pg_size_pretty(x.snap_value)
from (select * from pg_node_env) t,
(select * from snapshot.snap_global_os_runtime) x
where x.snap_node_name = t.node_name
and x.snapshot_id = %ld
and x.snap_name = 'PHYSICAL_MEMORY_BYTES';
select node_name as "Host Node Name" from pg_node_env;
select version() as "openGauss Version";Database Stat
- 数据库维度性能统计信息:事务,读写,行活动,写冲突,死锁等。
- 数据库范围报表,仅cluster模式下可查看此报表。

Database Stat报表主要内容
| 列名称 | 描述 |
|---|---|
| DB Name | 数据库名称。 |
| Backends | 连接到该数据库的后端数。 |
| Xact Commit | 此数据库中已经提交的事务数。 |
| Xact Rollback | 此数据库中已经回滚的事务数。 |
| Blks Read | 在这个数据库中读取的磁盘块的数量。 |
| Blks Hit | 高速缓存中已经发现的磁盘块的次数。 |
| Tuple Returned | 顺序扫描的行数。 |
| Tuple Fetched | 随机扫描的行数。 |
| Tuple Inserted | 通过数据库查询插入的行数。 |
| Tuple Updated | 通过数据库查询更新的行数。 |
| Tup Deleted | 通过数据库查询删除的行数。 |
| Conflicts | 由于数据库恢复冲突取消的查询数量。 |
| Temp Files | 通过数据库查询创建的临时文件数量。 |
| Temp Bytes | 通过数据库查询写入临时文件的数据总量。 |
| Deadlocks | 在该数据库中检索的死锁数。 |
| Blk Read Time | 通过数据库后端读取数据文件块花费的时间,以毫秒计算。 |
| Blk Write Time | 通过数据库后端写入数据文件块花费的时间,以毫秒计算。 |
| Stats Reset | 重置当前状态统计的时间。 |
这一部分描述的是后台写操作的统计信息,数据来源于 snapshot.snap_global_bgwriter_stat 表。
具体内容如下:
| 列名 | 数据获取相关函数 | 说明 |
|---|---|---|
| Checkpoints Timed | pg_stat_get_bgwriter_timed_checkpoints() | 执行的定期检查点数 |
| Checkpoints Require | pg_stat_get_bgwriter_requested_checkpoints() | 执行的需求检查点数 |
| Checkpoint Write Time(ms) | pg_stat_get_checkpoint_write_time() | 检查点操作中,文件写入到磁盘消耗的时间(单位:毫秒) |
| Checkpoint Sync Time(ms) | pg_stat_get_checkpoint_sync_time() | 检查点操作中,文件同步到磁盘消耗的时间(单位:毫秒) |
| Buffers Checkpoint | pg_stat_get_bgwriter_buf_written_checkpoints() | 检查点写缓冲区数量 |
| Buffers Clean | pg_stat_get_bgwriter_buf_written_clean() | 后端写线程写缓冲区数量 |
| Maxwritten Clean | pg_stat_get_bgwriter_maxwritten_clean() | 后端写线程停止清理 Buffer 的次数 |
| Buffers Backend | pg_stat_get_buf_written_backend() | 通过后端直接写缓冲区数 |
| Buffers Backend | Fsync pg_stat_get_buf_fsync_backend() | 后端不得不执行自己的 fsync 调用的时间数(通常后端写进程处理这些即使后端确实自己写) |
| Buffers Alloc | pg_stat_get_buf_alloc() 分配的缓冲区数量 | |
| Stats Reset | pg_stat_get_bgwriter_stat_reset_time() | 这些统计被重置的时间 |
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id
select (snap_2.snap_checkpoints_timed - coalesce(snap_1.snap_checkpoints_timed, 0)) AS "Checkpoints Timed",
(snap_2.snap_checkpoints_req - coalesce(snap_1.snap_checkpoints_req, 0)) AS "Checkpoints Require",
(snap_2.snap_checkpoint_write_time - coalesce(snap_1.snap_checkpoint_write_time, 0)) AS "Checkpoint Write Time(ms)",
(snap_2.snap_checkpoint_sync_time - coalesce(snap_1.snap_checkpoint_sync_time, 0)) AS "Checkpoint Sync Time(ms)",
(snap_2.snap_buffers_checkpoint - coalesce(snap_1.snap_buffers_checkpoint, 0)) AS "Buffers Checkpoint",
(snap_2.snap_buffers_clean - coalesce(snap_1.snap_buffers_clean, 0)) AS "Buffers Clean",
(snap_2.snap_maxwritten_clean - coalesce(snap_1.snap_maxwritten_clean, 0)) AS "Maxwritten Clean",
(snap_2.snap_buffers_backend - coalesce(snap_1.snap_buffers_backend, 0)) AS "Buffers Backend",
(snap_2.snap_buffers_backend_fsync - coalesce(snap_1.snap_buffers_backend_fsync, 0)) AS "Buffers Backend Fsync",
(snap_2.snap_buffers_alloc - coalesce(snap_1.snap_buffers_alloc, 0)) AS "Buffers Alloc",
to_char(snap_2.snap_stats_reset, 'YYYY-MM-DD HH24:MI:SS') AS "Stats Reset"
from
(select * from snapshot.snap_global_bgwriter_stat
where snapshot_id = %ld
and snap_node_name = '%s') snap_2
LEFT JOIN
(select * from snapshot.snap_global_bgwriter_stat
where snapshot_id = %ld
and snap_node_name = '%s') snap_1
on snap_2.snapshot_id = snap_1.snapshot_id --错误点:snap_2.snapshot_id = snap_1.snapshot_id ? 这其实还是同一个snapshot
and snap_2.snap_node_name = snap_1.snap_node_name
and snap_2.snap_stats_reset = snap_1.snap_stats_reset
limit 200;
-- 统计信息应该是2次snapshot之间的数据,而以上SQL并不能正确输出相关数据。个人觉得可以删除LEFT JOIN连接。
-- 建议修改如下:
select (snap_2.snap_checkpoints_timed - coalesce(snap_1.snap_checkpoints_timed, 0)) AS "Checkpoints Timed",
(snap_2.snap_checkpoints_req - coalesce(snap_1.snap_checkpoints_req, 0)) AS "Checkpoints Require",
(snap_2.snap_checkpoint_write_time - coalesce(snap_1.snap_checkpoint_write_time, 0)) AS "Checkpoint Write Time(ms)",
(snap_2.snap_checkpoint_sync_time - coalesce(snap_1.snap_checkpoint_sync_time, 0)) AS "Checkpoint Sync Time(ms)",
(snap_2.snap_buffers_checkpoint - coalesce(snap_1.snap_buffers_checkpoint, 0)) AS "Buffers Checkpoint",
(snap_2.snap_buffers_clean - coalesce(snap_1.snap_buffers_clean, 0)) AS "Buffers Clean",
(snap_2.snap_maxwritten_clean - coalesce(snap_1.snap_maxwritten_clean, 0)) AS "Maxwritten Clean",
(snap_2.snap_buffers_backend - coalesce(snap_1.snap_buffers_backend, 0)) AS "Buffers Backend",
(snap_2.snap_buffers_backend_fsync - coalesce(snap_1.snap_buffers_backend_fsync, 0)) AS "Buffers Backend Fsync",
(snap_2.snap_buffers_alloc - coalesce(snap_1.snap_buffers_alloc, 0)) AS "Buffers Alloc",
to_char(snap_2.snap_stats_reset, 'YYYY-MM-DD HH24:MI:SS') AS "Stats Reset"
from
(select * from snapshot.snap_global_bgwriter_stat
where snapshot_id = %ld
and snap_node_name = '%s') snap_2,
(select * from snapshot.snap_global_bgwriter_stat
where snapshot_id = %ld
and snap_node_name = '%s') snap_1
limit 200;Load Profile
- 数据库维度的性能统计信息:CPU时间,DB时间,逻辑读/物理读,IO性能,登入登出,负载强度,负载性能表现等。
- 数据库范围报表,仅cluster模式下可查看此报表。

Load Profile报表主要内容
| 指标名称 | 描述 |
|---|---|
| DB Time(us) | 作业运行的elapse time总和。 |
| CPU Time(us) | 作业运行的CPU时间总和。 |
| Redo size(blocks) | 产生的WAL的大小(块数)。 |
| Logical read (blocks) | 表或者索引文件的逻辑读(块数)。 从数据库的 内存缓冲区(Buffer Cache) 中读取数据块(Block) 数据已经在内存中,无需访问磁盘,速度极快。 如果请求的数据不在内存中,则会触发物理读。 可以增大 Buffer Cache提高逻辑读。 |
| Physical read (blocks) | 表或者索引的物理读(块数)。 从 磁盘(数据文件) 中读取数据块到内存缓冲区。 需要磁盘 I/O 操作,速度比逻辑读慢得多。 物理读过多通常意味着缓存命中率低,可能需优化内存或 SQL。 |
| Physical write (blocks) | 表或者索引的物理写(块数)。 |
| Read IO requests | 表或者索引的读次数。 |
| Write IO requests | 表或者索引的写次数。 |
| Read IO (MB) | 表或者索引的读大小(MB)。 |
| Write IO (MB) | 表或者索引的写大小(MB)。 |
| Logons | 登录次数。 |
| Executes (SQL) | SQL执行次数。 |
| Rollbacks | 回滚事务数。 |
| Transactions | 事务数。 |
| SQL response time P95(us) | 95%的SQL的响应时间。 |
| SQL response time P80(us) | 80%的SQL的响应时间。 |
Instance Efficiency Percentages
- 数据库级或者节点缓冲命中率。
- 数据库、节点范围报表,cluster模式和node模式下均可查看此报表。

Instance Efficiency Percentages报表主要内容
| 指标名称 | 描述 |
|---|---|
| Buffer Hit % | Buffer Pool命中率。 |
| Effective CPU % | CPU time占DB time的比例。 |
| WalWrite NoWait % | 访问WAL Buffer的event次数占总wait event的比例。 |
| Soft Parse % | 软解析的次数占总的解析次数的比例。 |
| Non-Parse CPU % | 非parse的时间占执行总时间的比例。 |
目标值是 100%,即越接近 100%,数据库运行越健康
Buffer Hit: 即数据库请求的数据在 buffer 中命中的比例,该指标越高代表 openGauss 在 buffer 中查询到目标数据的概率越高,数据读取性能越好。
Effective CPU: 即有效的 CPU 使用比例,该指标偏小则说明 CPU 的有效使用偏低,处于等待状态的比例可能较高。
WalWrite NoWait: 即 WAL 日志写入时不等待的比例,该指标接近 100%,说明 buffer 容量充足,可以满足 WAL 写操作的需求,若指标值偏小则可能需要调大 buffer 容量。
Soft Parse: 即 SQL 软解析的比例,该指标接近 100%,说明当前执行的 SQL 基本都可以在 Buffer 中找到,若指标值偏小则说明存在大量硬解析,需要分析原因,对 DML 语句进行适度优化。
**Non-Parse CPU:**即非解析占用的 CPU 比例,该指标接近 100%,说明 SQL 解析并没有占用较多的 CPU 时间。
相关代码:
-- 变量:ld指的是snapshot_id,手动执行以下SQL语句时请自行替换对应的snapshot_id
select
unnest(array['Buffer Hit %%', 'Effective CPU %%', 'WalWrite NoWait %%', 'Soft Parse %%', 'Non-Parse CPU %%']) as "Metric Name",
unnest(array[case when s1.all_reads = 0 then 1 else round(s1.blks_hit * 100 / s1.all_reads) end, s2.cpu_to_elapsd, s3.walwrite_nowait, s4.soft_parse, s5.non_parse]) as "Metric Value"
from
(select (snap_2.all_reads - coalesce(snap_1.all_reads, 0)) as all_reads,
(snap_2.blks_hit - coalesce(snap_1.blks_hit, 0)) as blks_hit
from
(select sum(coalesce(snap_blks_read, 0) + coalesce(snap_blks_hit, 0)) as all_reads,
coalesce(sum(snap_blks_hit), 0) as blks_hit
from snapshot.snap_summary_stat_database
where snapshot_id = %ld) snap_1,
(select sum(coalesce(snap_blks_read, 0) + coalesce(snap_blks_hit, 0)) as all_reads,
coalesce(sum(snap_blks_hit), 0) as blks_hit
from snapshot.snap_summary_stat_database
where snapshot_id = %ld) snap_2
) s1,
(select round(cpu_time.snap_value * 100 / greatest(db_time.snap_value, 1)) as cpu_to_elapsd
from
(select coalesce(snap_2.snap_value, 0) - coalesce(snap_1.snap_value, 0) as snap_value
from
(select snap_stat_name, snap_value from snapshot.snap_global_instance_time
where snapshot_id = %ld and snap_stat_name = 'CPU_TIME') snap_1,
(select snap_stat_name, snap_value from snapshot.snap_global_instance_time
where snapshot_id = %ld and snap_stat_name = 'CPU_TIME') snap_2) cpu_time,
(select coalesce(snap_2.snap_value, 0) - coalesce(snap_1.snap_value, 0) as snap_value
from
(select snap_stat_name, snap_value from snapshot.snap_global_instance_time
where snapshot_id = %ld and snap_stat_name = 'DB_TIME') snap_1,
(select snap_stat_name, snap_value from snapshot.snap_global_instance_time
where snapshot_id = %ld and snap_stat_name = 'DB_TIME') snap_2) db_time
) s2,
(select (bufferAccess.snap_wait - bufferFull.snap_wait) * 100 / greatest(bufferAccess.snap_wait, 1) as walwrite_nowait
from
(select coalesce(snap_2.snap_wait) - coalesce(snap_1.snap_wait, 0) as snap_wait
from
(select snap_wait from snapshot.snap_global_wait_events
where snapshot_id = %ld and snap_event = 'WALBufferFull') snap_1,
(select snap_wait from snapshot.snap_global_wait_events
where snapshot_id = %ld and snap_event = 'WALBufferFull') snap_2) bufferFull,
(select coalesce(snap_2.snap_wait) - coalesce(snap_1.snap_wait, 0) as snap_wait
from
(select snap_wait from snapshot.snap_global_wait_events
where snapshot_id = %ld and snap_event = 'WALBufferAccess') snap_1,
(select snap_wait from snapshot.snap_global_wait_events
where snapshot_id = %ld and snap_event = 'WALBufferAccess') snap_2) bufferAccess
) s3,
(select round((snap_2.soft_parse - snap_1.soft_parse) * 100 / greatest((snap_2.hard_parse + snap_2.soft_parse)-(snap_1.hard_parse + snap_1.soft_parse), 1)) as soft_parse
from
(select sum(snap_n_soft_parse) as soft_parse, sum(snap_n_hard_parse) as hard_parse from snapshot.snap_summary_statement
where snapshot_id = %ld ) snap_1,
(select sum(snap_n_soft_parse) as soft_parse, sum(snap_n_hard_parse) as hard_parse from snapshot.snap_summary_statement
where snapshot_id = %ld ) snap_2
) s4,
(select round((snap_2.elapse_time - snap_1.elapse_time) * 100 /greatest((snap_2.elapse_time + snap_2.parse_time)-(snap_1.elapse_time + snap_1.parse_time), 1)) as non_parse
from
(select sum(snap_total_elapse_time) as elapse_time, sum(snap_parse_time) as parse_time from snapshot.snap_summary_statement
where snapshot_id = %ld ) snap_1,
(select sum(snap_total_elapse_time) as elapse_time, sum(snap_parse_time) as parse_time from snapshot.snap_summary_statement
where snapshot_id = %ld ) snap_2
) s5;TOP 10 Events by Total Wait Time
数据库 Top 10 的等待事件、等待次数、总等待时间、平均等待时间、等待事件类型
- 最消耗时间的事件。
- 节点范围报表,仅node模式下可查看此报表。

Top 10 Events by Total Wait Time报表主要内容
| 列名称 | 描述 |
|---|---|
| Event | Wait Event名称。 |
| Waits | wait次数。 |
| Total Wait Time(us) | 总wait时间(微秒)。 |
| Avg Wait Time(us) | 平均wait时间(微秒)。 |
| Type | Wait Event类别。 |
等待事件主要分为等待状态、等待轻量级锁、等待 IO、等待事务锁这 4 类,详见下表所示:
等待状态列表
当 wait_status 为 acquire lwlock、acquire lock 或者 wait io 时,表示有等待事件。
正在等待获取 wait_event 列对应类型的轻量级锁、事务锁,或者正在进行 IO。
- 轻量级锁等待事件列表
当 wait_status 值为 acquire lwlock(轻量级锁)时对应的 wait_event 等待事件类型即为轻量级锁等待。
wait_event 为 extension 时,表示此时的轻量级锁是动态分配的锁,未被监控。
| wait_event类型 | 类型描述 |
|---|---|
| ShmemIndexLock | 用于保护共享内存中的主索引哈希表。 |
| OidGenLock | 用于避免不同线程产生相同的OID。 |
| XidGenLock | 用于避免两个事务获得相同的xid。 |
| ProcArrayLock | 用于避免并发访问或修改ProcArray共享数组。 |
| SInvalReadLock | 用于避免与清理失效消息并发执行。 |
| SInvalWriteLock | 用于避免与其它写失效消息、清理失效消息并发执行。 |
| WALInsertLock | 用于避免与其它WAL插入操作并发执行。 |
| WALWriteLock | 用于避免并发WAL写盘。 |
| ControlFileLock | 用于避免pg_control文件的读写并发、写写并发。 |
| CheckpointLock | 用于避免多个checkpoint并发执行。 |
| CLogControlLock | 用于避免并发访问或者修改Clog控制数据结构。 |
| SubtransControlLock | 用于避免并发访问或者修改子事务控制数据结构。 |
| MultiXactGenLock | 用于串行分配唯一MultiXact id。 |
| MultiXactOffsetControlLock | 用于避免对pg_multixact/offset的写写并发和读写并发。 |
| MultiXactMemberControlLock | 用于避免对pg_multixact/members的写写并发和读写并发。 |
| RelCacheInitLock | 用于失效消息场景对init文件进行操作时加锁。 |
| CheckpointerCommLock | 用于向checkpointer发起文件刷盘请求场景,需要串行的向请求队列插入请求结构。 |
| TwoPhaseStateLock | 用于避免并发访问或者修改两阶段信息共享数组。 |
| TablespaceCreateLock | 用于确定tablespace是否已经存在。 |
| BtreeVacuumLock | 用于防止vacuum清理B-tree中还在使用的页面。 |
| AutovacuumLock | 用于串行化访问autovacuum worker数组。 |
| AutovacuumScheduleLock | 用于串行化分配需要vacuum的table。 |
| AutoanalyzeLock | 用于获取和释放允许执行Autoanalyze的任务资源。 |
| SyncScanLock | 用于确定heap扫描时某个relfilenode的起始位置。 |
| NodeTableLock | 用于保护存放数据库节点信息的共享结构。 |
| PoolerLock | 用于保证两个线程不会同时从连接池里取到相同的连接。 |
| RelationMappingLock | 用于等待更新系统表到存储位置之间映射的文件。 |
| AsyncCtlLock | 用于避免并发访问或者修改共享通知状态。 |
| AsyncQueueLock | 用于避免并发访问或者修改共享通知信息队列。 |
| SerializableXactHashLock | 用于避免对于可串行事务共享结构的写写并发和读写并发。 |
| SerializableFinishedListLock | 用于避免对于已完成可串行事务共享链表的写写并发和读写并发。 |
| SerializablePredicateLockListLock | 用于保护对于可串行事务持有的锁链表。 |
| OldSerXidLock | 用于保护记录冲突可串行事务的结构。 |
| FileStatLock | 用于保护存储统计文件信息的数据结构。 |
| SyncRepLock | 用于在主备复制时保护xlog同步信息。 |
| DataSyncRepLock | 用于在主备复制时保护数据页同步信息。 |
| CStoreColspaceCacheLock | 用于保护列存表的CU空间分配。 |
| CStoreCUCacheSweepLock | 用于列存CU Cache循环淘汰。 |
| MetaCacheSweepLock | 用于元数据循环淘汰。 |
| ExtensionConnectorLibLock | 用于初始化ODBC连接场景,在加载与卸载特定动态库时进行加锁。 |
| SearchServerLibLock | 用于GPU加速场景初始化加载特定动态库时,对读文件操作进行加锁。 |
| LsnXlogChkFileLock | 用于串行更新特定结构中记录的主备机的xlog flush位置点。 |
| ReplicationSlotAllocationLock | 用于主备复制时保护主机端的流复制槽的分配。 |
| ReplicationSlotControlLock | 用于主备复制时避免并发更新流复制槽状态。 |
| ResourcePoolHashLock | 用于避免并发访问或者修改资源池哈希表。 |
| WorkloadStatHashLock | 用于避免并发访问或者修改包含数据库主节点的SQL请求构成的哈希表。 |
| WorkloadIoStatHashLock | 用于避免并发访问或者修改用于统计当前数据库节点的IO信息的哈希表。 |
| WorkloadCGroupHashLock | 用于避免并发访问或者修改Cgroup信息构成的哈希表。 |
| OBSGetPathLock | 用于避免对obs路径的写写并发和读写并发。 |
| WorkloadUserInfoLock | 用于避免并发访问或修改负载管理的用户信息哈希表。 |
| WorkloadRecordLock | 用于避免并发访问或修改在内存自适应管理时对数据库主节点收到请求构成的哈希表。 |
| WorkloadIOUtilLock | 用于保护记录iostat,CPU等负载信息的结构。 |
| WorkloadNodeGroupLock | 用于避免并发访问或者修改内存中的nodegroup信息构成的哈希表。 |
| JobShmemLock | 用于定时任务功能中保护定时读取的全局变量。 |
| OBSRuntimeLock | 用于获取环境变量,如GASSHOME。 |
| LLVMDumpIRLock | 用于导出动态生成函数所对应的汇编语言。 |
| LLVMParseIRLock | 用于在查询开始处从IR文件中编译并解析已写好的IR函数。 |
| CriticalCacheBuildLock | 用于从共享或者本地缓存初始化文件中加载cache的场景。 |
| WaitCountHashLock | 用于保护用户语句计数功能场景中的共享结构。 |
| BufMappingLock | 用于保护对共享缓冲映射表的操作。 |
| LockMgrLock | 用于保护常规锁结构信息。 |
| PredicateLockMgrLock | 用于保护可串行事务锁结构信息。 |
| OperatorRealTLock | 用于避免并发访问或者修改记录算子级实时数据的全局结构。 |
| OperatorHistLock | 用于避免并发访问或者修改记录算子级历史数据的全局结构。 |
| SessionRealTLock | 用于避免并发访问或者修改记录query级实时数据的全局结构。 |
| SessionHistLock | 用于避免并发访问或者修改记录query级历史数据的全局结构。 |
| CacheSlotMappingLock | 用于保护CU Cache全局信息。 |
| BarrierLock | 用于保证当前只有一个线程在创建Barrier。 |
| dummyServerInfoCacheLock | 用于保护缓存加速openGauss连接信息的全局哈希表。 |
| RPNumberLock | 用于加速openGauss的数据库节点对正在执行计划的任务线程的计数。 |
| ClusterRPLock | 用于加速openGauss的CCN中维护的openGauss负载数据的并发存取控制。 |
| CBMParseXlogLock | Cbm 解析xlog时的保护锁 |
| RelfilenodeReuseLock | 避免错误地取消已重用的列属性文件的链接。 |
| RcvWriteLock | 防止并发调用WalDataRcvWrite。 |
| PercentileLock | 用于保护全局PercentileBuffer |
| CSNBufMappingLock | 保护csn页面 |
| UniqueSQLMappingLock | 用于保护uniquesql hash table |
| DelayDDLLock | 防止并发ddl。 |
| CLOG Ctl | 用于避免并发访问或者修改Clog控制数据结构 |
| Async Ctl | 保护Async buffer |
| MultiXactOffset Ctl | 保护MultiXact offet的slru buffer |
| MultiXactMember Ctl | 保护MultiXact member的slrubuffer |
| OldSerXid SLRU Ctl | 保护old xids的slru buffer |
| ReplicationSlotLock | 用于保护ReplicationSlot |
| PGPROCLock | 用于保护pgproc |
| MetaCacheLock | 用于保护MetaCache |
| DataCacheLock | 用于保护datacache |
| InstrUserLock | 用于保护InstrUserHTAB。 |
| BadBlockStatHashLock | 用于保护global_bad_block_stat hash表。 |
| BufFreelistLock | 用于保证共享缓冲区空闲列表操作的原子性。 |
| CUSlotListLock | 用于控制列存缓冲区槽位的并发操作。 |
| AddinShmemInitLock | 保护共享内存对象的初始化。 |
| AlterPortLock | 保护协调节点更改注册端口号的操作。 |
| FdwPartitionCaheLock | HDFS分区表缓冲区的管理锁。 |
| DfsConnectorCacheLock | DFSConnector缓冲区的管理锁。 |
| DfsSpaceCacheLock | HDFS表空间管理缓冲区的管理锁。 |
| FullBuildXlogCopyStartPtrLock | 用于保护全量Build中Xlog拷贝的操作。 |
| DfsUserLoginLock | 用于HDFS用户登录以及认证。 |
| LogicalReplicationSlotPersistentDataLock | 用于保护逻辑复制过程中复制槽位的数据。 |
| WorkloadSessionInfoLock | 保护负载管理session info内存hash表访问。 |
| InstrWorkloadLock | 保护负载管理统计信息的内存hash表访问。 |
| PgfdwLock | 用于管理实例向Foreign server建立连接。 |
| InstanceTimeLock | 用于获取实例中会话的时间信息。 |
| XlogRemoveSegLock | 保护Xlog段文件的回收操作。 |
| DnUsedSpaceHashLock | 用于更新会话对应的空间使用信息。 |
| CsnMinLock | 用于计算CSNmin。 |
| GPCCommitLock | 用于保护全局Plan Cache hash表的添加操作。 |
| GPCClearLock | 用于保护全局Plan Cache hash表的清除操作。 |
| GPCTimelineLock | 用于保护全局Plan Cache hash表检查Timeline的操作。 |
| TsTagsCacheLock | 用于时序tag缓存管理。 |
| InstanceRealTLock | 用于保护共享实例统计信息hash表的更新操作。 |
| CLogBufMappingLock | 用于提交日志缓存管理。 |
| GPCMappingLock | 用于全局Plan Cache缓存管理。 |
| GPCPrepareMappingLock | 用于全局Plan Cache缓存管理。 |
| BufferIOLock | 保护共享缓冲区页面的IO操作。 |
| BufferContentLock | 保护共享缓冲区页面内容的读取、修改。 |
| CSNLOG Ctl | 用于CSN日志管理。 |
| DoubleWriteLock | 用于双写的管理操作。 |
| RowPageReplicationLock | 用于管理行存储的数据页复制。 |
| extension | 其他轻量锁。 |
- IO 等待事件列表
当 wait_status 值为 wait io 时对应的 wait_event 等待事件类型即为 IO 等待事件。
| wait_event类型 | 类型描述 |
|---|---|
| BufFileRead | 从临时文件中读取数据到指定buffer。 |
| BufFileWrite | 向临时文件中写入指定buffer中的内容。 |
| ControlFileRead | 读取pg_control文件。主要在数据库启动、执行checkpoint和主备校验过程中发生。 |
| ControlFileSync | 将pg_control文件持久化到磁盘。数据库初始化时发生。 |
| ControlFileSyncUpdate | 将pg_control文件持久化到磁盘。主要在数据库启动、执行checkpoint和主备校验过程中发生。 |
| ControlFileWrite | 写入pg_control文件。数据库初始化时发生。 |
| ControlFileWriteUpdate | 更新pg_control文件。主要在数据库启动、执行checkpoint和主备校验过程中发生。 |
| CopyFileRead | copy文件时读取文件内容。 |
| CopyFileWrite | copy文件时写入文件内容。 |
| DataFileExtend | 扩展文件时向文件写入内容。 |
| DataFileFlush | 将表数据文件持久化到磁盘 |
| DataFileImmediateSync | 将表数据文件立即持久化到磁盘。 |
| DataFilePrefetch | 异步读取表数据文件。 |
| DataFileRead | 同步读取表数据文件。 |
| DataFileSync | 将表数据文件的修改持久化到磁盘。 |
| DataFileTruncate | 表数据文件truncate。 |
| DataFileWrite | 向表数据文件写入内容。 |
| LockFileAddToDataDirRead | 读取"postmaster.pid"文件。 |
| LockFileAddToDataDirSync | 将"postmaster.pid"内容持久化到磁盘。 |
| LockFileAddToDataDirWrite | 将pid信息写到"postmaster.pid"文件。 |
| LockFileCreateRead | 读取LockFile文件"%s.lock"。 |
| LockFileCreateSync | 将LockFile文件"%s.lock"内容持久化到磁盘。 |
| LockFileCreateWRITE | 将pid信息写到LockFile文件"%s.lock"。 |
| RelationMapRead | 读取系统表到存储位置之间的映射文件 |
| RelationMapSync | 将系统表到存储位置之间的映射文件持久化到磁盘。 |
| RelationMapWrite | 写入系统表到存储位置之间的映射文件。 |
| ReplicationSlotRead | 读取流复制槽文件。重新启动时发生。 |
| ReplicationSlotRestoreSync | 将流复制槽文件持久化到磁盘。重新启动时发生。 |
| ReplicationSlotSync | checkpoint时将流复制槽临时文件持久化到磁盘。 |
| ReplicationSlotWrite | checkpoint时写流复制槽临时文件。 |
| SLRUFlushSync | 将pg_clog、pg_subtrans和pg_multixact文件持久化到磁盘。主要在执行checkpoint和数据库停机时发生。 |
| SLRURead | 读取pg_clog、pg_subtrans和pg_multixact文件。 |
| SLRUSync | 将脏页写入文件pg_clog、pg_subtrans和pg_multixact并持久化到磁盘。主要在执行checkpoint和数据库停机时发生。 |
| SLRUWrite | 写入pg_clog、pg_subtrans和pg_multixact文件。 |
| TimelineHistoryRead | 读取timeline history文件。在数据库启动时发生。 |
| TimelineHistorySync | 将timeline history文件持久化到磁盘。在数据库启动时发生。 |
| TimelineHistoryWrite | 写入timeline history文件。在数据库启动时发生。 |
| TwophaseFileRead | 读取pg_twophase文件。在两阶段事务提交、两阶段事务恢复时发生。 |
| TwophaseFileSync | 将pg_twophase文件持久化到磁盘。在两阶段事务提交、两阶段事务恢复时发生。 |
| TwophaseFileWrite | 写入pg_twophase文件。在两阶段事务提交、两阶段事务恢复时发生。 |
| WALBootstrapSync | 将初始化的WAL文件持久化到磁盘。在数据库初始化发生。 |
| WALBootstrapWrite | 写入初始化的WAL文件。在数据库初始化发生。 |
| WALCopyRead | 读取已存在的WAL文件并进行复制时产生的读操作。在执行归档恢复完后发生。 |
| WALCopySync | 将复制的WAL文件持久化到磁盘。在执行归档恢复完后发生。 |
| WALCopyWrite | 读取已存在WAL文件并进行复制时产生的写操作。在执行归档恢复完后发生。 |
| WALInitSync | 将新初始化的WAL文件持久化磁盘。在日志回收或写日志时发生。 |
| WALInitWrite | 将新创建的WAL文件初始化为0。在日志回收或写日志时发生。 |
| WALRead | 从xlog日志读取数据。两阶段文件redo相关的操作产生。 |
| WALSyncMethodAssign | 将当前打开的所有WAL文件持久化到磁盘。 |
| WALWrite | 写入WAL文件。 |
| WALBufferAccess | WAL Buffer访问(出于性能考虑,内核代码里只统计访问次数,未统计其访问耗时)。 |
| WALBufferFull | WAL Buffer满时,写wal文件相关的处理。 |
| DoubleWriteFileRead | 双写 文件读取。 |
| DoubleWriteFileSync | 双写 文件强制刷盘。 |
| DoubleWriteFileWrite | 双写 文件写入。 |
| PredoProcessPending | 并行日志回放中当前记录回放等待其它记录回放完成。 |
| PredoApply | 并行日志回放中等待当前工作线程等待其他线程回放至本线程LSN。 |
| DisableConnectFileRead | HA锁分片逻辑文件读取。 |
| DisableConnectFileSync | HA锁分片逻辑文件强制刷盘。 |
| DisableConnectFileWrite | HA锁分片逻辑文件写入。 |
- 事务锁等待事件列表
当 wait_status 值为 acquire lock(事务锁)时对应的 wait_event 等待事件类型为事务锁等待事件。
| wait_event 类型 | 类型描述 |
|---|---|
| relation | 对表加锁 |
| extend | 对表扩展空间时加锁 |
| partition | 对分区表加锁 |
| partition_seq | 对分区表的分区加锁 |
| page | 对表页面加锁 |
| tuple | 对页面上的 tuple 加锁 |
| transactionid | 对事务 ID 加锁 |
| virtualxid | 对虚拟事务 ID 加锁 |
| object | 加对象锁 |
| cstore_freespace | 对列存空闲空间加锁 |
| userlock | 加用户锁 |
| advisory | 加 advisory 锁 |
相关代码:
-- 说明:变量ld-->snapshot_id, 变量s-->node_name
select snap_event as "Event",
snap_wait as "Waits",
snap_total_wait_time as "Total Wait Times(us)",
round(snap_total_wait_time/snap_wait) as "Wait Avg(us)",
snap_type as "Wait Class"
from (
select snap_2.snap_event as snap_event,
snap_2.snap_type as snap_type,
snap_2.snap_wait - snap_1.snap_wait as snap_wait,
snap_2.total_time - snap_1.total_time as snap_total_wait_time
from
(select snap_event,
snap_wait,
snap_total_wait_time as total_time,
snap_type
from snapshot.snap_global_wait_events
where snapshot_id = %ld
and snap_event != 'none'
and snap_event != 'wait cmd'
and snap_event != 'unknown_lwlock_event'
and snap_nodename = '%s') snap_1,
(select snap_event,
snap_wait,
snap_total_wait_time as total_time,
snap_type
from snapshot.snap_global_wait_events
where snapshot_id = %ld
and snap_event != 'none'
and snap_event != 'wait cmd'
and snap_event != 'unknown_lwlock_event'
and snap_nodename = '%s') snap_2
where snap_2.snap_event = snap_1.snap_event
order by snap_total_wait_time desc limit 10)
where snap_wait != 0;Wait Classes by Total Wait Time
按照等待类型(STATUS、IO_EVENT、LWLOCK_EVENT、LOCK_EVENT),分类统计等待次数、总等待时间、平均等待时间。
- 最消耗时间的等待时间分类。
- 节点范围报表,仅node模式下可查看此报表。

Wait Classes by Total Wait Time报表主要内容
| 列名称 | 描述 |
|---|---|
| Type | Wait Event类别名称: * STATUS。 * LWLOCK_EVENT。 * LOCK_EVENT。 * IO_EVENT。 |
| Waits | Wait次数。 |
| Total Wait Time(us) | 总Wait时间(微秒)。 |
| Avg Wait Time(us) | 平均Wait时间(微秒)。 |
相关代码
-- 说明: 变量ld-->snapshot_id, 变量s-->node_name
select
snap_2.type as "Wait Class",
(snap_2.wait - snap_1.wait) as "Waits",
(snap_2.total_wait_time - snap_1.total_wait_time) as "Total Wait Time(us)",
round((snap_2.total_wait_time - snap_1.total_wait_time) / greatest((snap_2.wait - snap_1.wait), 1)) as "Wait Avg(us)"
from
(select
snap_type as type,
sum(snap_total_wait_time) as total_wait_time,
sum(snap_wait) as wait from snapshot.snap_global_wait_events
where snapshot_id = %ld
and snap_nodename = '%s'
and snap_event != 'unknown_lwlock_event'
and snap_event != 'none'
group by snap_type) snap_2
left join
(select
snap_type as type,
sum(snap_total_wait_time) as total_wait_time,
sum(snap_wait) as wait
from snapshot.snap_global_wait_events
where snapshot_id = %ld
and snap_nodename = '%s'
and snap_event != 'unknown_lwlock_event' and snap_event != 'none'
group by snap_type) snap_1
on snap_2.type = snap_1.type
order by "Total Wait Time(us)" desc;分别从等待时长、等待次数这两个维度对等待事件进行统计。
表格中列的含义即就是列的英文翻译,这里就不再复述了。
具体的等待事件的介绍详见前文:"Top 10 Events by Total Wait Time"部分的内容,这里也不再复述。
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id,无论从哪个维度统计,基本的SQL语句差异不大,这里仅列举"by wait time"的SQL示例
select t2.snap_type as "Type",
t2.snap_event as "Event",
(t2.snap_total_wait_time - coalesce(t1.snap_total_wait_time, 0)) as "Total Wait Time (us)",
(t2.snap_wait - coalesce(t1.snap_wait, 0)) as "Waits",
(t2.snap_failed_wait - coalesce(t1.snap_failed_wait, 0)) as "Failed Waits",
(case "Waits"
when 0 then 0
else round("Total Wait Time (us)" / "Waits", 2)
end) as "Avg Wait Time (us)",
t2.snap_max_wait_time as "Max Wait Time (us)"
from
(select * from snapshot.snap_global_wait_events
where snapshot_id = %ld
and snap_nodename = '%s'
and snap_event != 'unknown_lwlock_event'
and snap_event != 'none') t1
right join
(select * from snapshot.snap_global_wait_events
where snapshot_id = %ld
and snap_nodename = '%s'
and snap_event != 'unknown_lwlock_event'
and snap_event != 'none') t2
on t1.snap_event = t2.snap_event
order by "Total Wait Time (us)"
desc limit 200;Host CPU
- 主机CPU消耗。
- 节点范围报表,仅node模式下可查看此报表。

Host CPU报表主要内容
| 列名称 | 描述 |
|---|---|
| Cpus | CPU数量。 |
| Cores | CPU核数。 |
| Sockets | CPU Sockets数量。 |
| Load Average Begin | 开始snapshot的Load Average值。 |
| Load Average End | 结束snapshot的Load Average值。 |
| %User | 用户态在CPU时间上的占比。 |
| %System | 内核态在CPU时间上的占比。 |
| %WIO | Wait IO在CPU时间上的占比。 |
| %Idle | 空闲时间在CPU时间上的占比。 |
主机 CPU 的负载情况:
CPU 的平均负载、用户使用占比、系统使用占比、IO 等待占比、空闲占比
相关代码
select
snap_2.cpus as "Cpus",
snap_2.cores as "Cores",
snap_2.sockets as "Sockets",
snap_1.load as "Load Average Begin",
snap_2.load as "Load Average End",
round(coalesce((snap_2.user_time - snap_1.user_time), 0) / greatest(coalesce((snap_2.total_time - snap_1.total_time), 0), 1) * 100, 2) as "%User",
round(coalesce((snap_2.sys_time - snap_1.sys_time), 0) / greatest(coalesce((snap_2.total_time - snap_1.total_time), 0), 1) * 100, 2) as "%System",
round(coalesce((snap_2.iowait_time - snap_1.iowait_time), 0) / greatest(coalesce((snap_2.total_time - snap_1.total_time), 0), 1) * 100, 2) as "%WIO",
round(coalesce((snap_2.idle_time - snap_1.idle_time), 0) / greatest(coalesce((snap_2.total_time - snap_1.total_time), 0), 1) * 100, 2) as "%Idle"
from
(select H.cpus, H.cores, H.sockets, H.idle_time, H.user_time, H.sys_time, H.iowait_time,
(H.idle_time + H.user_time + H.sys_time + H.iowait_time) AS total_time, H.load from
(select C.cpus, E.cores, T.sockets, I.idle_time, U.user_time, S.sys_time, W.iowait_time, L.load from
(select snap_value as cpus from snapshot.snap_global_os_runtime
where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'NUM_CPUS')) AS C,
(select snap_value as cores from snapshot.snap_global_os_runtime
where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'NUM_CPU_CORES')) AS E,
(select snap_value as sockets from snapshot.snap_global_os_runtime
where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'NUM_CPU_SOCKETS')) AS T,
(select snap_value as idle_time from snapshot.snap_global_os_runtime
where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'IDLE_TIME')) AS I,
(select snap_value as user_time from snapshot.snap_global_os_runtime
where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'USER_TIME')) AS U,
(select snap_value as sys_time from snapshot.snap_global_os_runtime
where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'SYS_TIME')) AS S,
(select snap_value as iowait_time from snapshot.snap_global_os_runtime
where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'IOWAIT_TIME')) AS W,
(select snap_value as load from snapshot.snap_global_os_runtime
where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'LOAD')) AS L ) as H ) as snap_2,
(select H.cpus, H.cores, H.sockets, H.idle_time, H.user_time, H.sys_time, H.iowait_time,
(H.idle_time + H.user_time + H.sys_time + H.iowait_time) AS total_time, H.load from
(select C.cpus, E.cores, T.sockets, I.idle_time, U.user_time, S.sys_time, W.iowait_time, L.load from
(select snap_value as cpus from snapshot.snap_global_os_runtime
where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'NUM_CPUS')) AS C,
(select snap_value as cores from snapshot.snap_global_os_runtime
where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'NUM_CPU_CORES')) AS E,
(select snap_value as sockets from snapshot.snap_global_os_runtime
where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'NUM_CPU_SOCKETS')) AS T,
(select snap_value as idle_time from snapshot.snap_global_os_runtime
where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'IDLE_TIME')) AS I,
(select snap_value as user_time from snapshot.snap_global_os_runtime
where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'USER_TIME')) AS U,
(select snap_value as sys_time from snapshot.snap_global_os_runtime
where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'SYS_TIME')) AS S,
(select snap_value as iowait_time from snapshot.snap_global_os_runtime
where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'IOWAIT_TIME')) AS W,
(select snap_value as load from snapshot.snap_global_os_runtime
where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'LOAD')) AS L ) as H ) as snap_1 ;Memory Statistics
- 内核内存使用分布。
- 节点范围报表,仅node模式下可查看此报表。

Memory Statistics报表主要内容
| 指标名称 | 描述 |
|---|---|
| shared_used_memory | 已经使用共享内存大小(MB)。 |
| max_shared_memory | 最大共享内存(MB)。 |
| process_used_memory | 进程已经使用内存(MB)。 |
| max_process_memory | 最大进程内存(MB)。 |
节点内存的变化信息
通过这些变化信息,我们可以了解到在两次快照期间,数据库的内存变化情况,作为数据库性能分析或异常分析的参考。数据来源于 snapshot.snap_global_memory_node_detail。
这部分分别描述了: 内存的类型 以及 对应的起始大小和终止大小。
这里没有采集到数据的原因: 测试环境内存太小,导致启动时将 memory protect 关闭了,从而导致无法查询 dbe_perf.global_memory_node_detail 视图。 而 WDR 的内存统计数据(snapshot.snap_global_memory_node_detail)则来源于该视图。
另外,请确保 disable_memory_protect=off。
关于这部分 Memory Type 常见类型如下:
| Memory 类型 | 说明 |
|---|---|
| max_process_memory | openGauss 实例所占用的内存大小 |
| process_used_memory | 进程所使用的内存大小 |
| max_dynamic_memory | 最大动态内存 |
| dynamic_used_memory | 已使用的动态内存 |
| dynamic_peak_memory | 内存的动态峰值 |
| dynamic_used_shrctx | 最大动态共享内存上下文 |
| dynamic_peak_shrctx | 共享内存上下文的动态峰值 |
| max_shared_memory | 最大共享内存 |
| shared_used_memory | 已使用的共享内存 |
| max_cstore_memory | 列存所允许使用的最大内存 |
| cstore_used_memory | 列存已使用的内存大小 |
| max_sctpcomm_memory | sctp 通信所允许使用的最大内存 |
| sctpcomm_used_memory | sctp 通信已使用的内存大小 |
| sctpcomm_peak_memory | sctp 通信的内存峰值 |
| other_used_memory | 其他已使用的内存大小 |
| gpu_max_dynamic_memory | GPU 最大动态内存 |
| gpu_dynamic_used_memory | GPU 已使用的动态内存 |
| gpu_dynamic_peak_memory | GPU 内存的动态峰值 |
| pooler_conn_memory | 链接池申请内存计数 |
| pooler_freeconn_memory | 链接池空闲连接的内存计数 |
| storage_compress_memory | 存储模块压缩使用的内存大小 |
| udf_reserved_memory | UDF 预留的内存大小 |
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id
select
snap_2.snap_memorytype as "Memory Type",
snap_1.snap_memorymbytes as "Begin(MB)",
snap_2.snap_memorymbytes as "End(MB)"
from
(select snap_memorytype, snap_memorymbytes
from
snapshot.snap_global_memory_node_detail
where (snapshot_id = %ld and snap_nodename = '%s')
and
(snap_memorytype = 'max_process_memory'
or snap_memorytype = 'process_used_memory'
or snap_memorytype = 'max_shared_memory'
or snap_memorytype = 'shared_used_memory'))
as snap_2
left join
(select snap_memorytype, snap_memorymbytes
from
snapshot.snap_global_memory_node_detail
where (snapshot_id = %ld and snap_nodename = '%s')
and (snap_memorytype = 'max_process_memory'
or snap_memorytype = 'process_used_memory'
or snap_memorytype = 'max_shared_memory'
or snap_memorytype = 'shared_used_memory'))
as snap_1
on snap_2.snap_memorytype = snap_1.snap_memorytype;Time Mode
数据库各种状态所消耗的时间
- 节点范围的语句的时间分布信息。
- 节点范围报表,仅node模式下可查看此报表。

Time Model报表主要内容
| 名称 | 描述 |
|---|---|
| DB_TIME | 所有线程端到端的墙上时间(WALL TIME)消耗总和(单位:微秒)。 |
| EXECUTION_TIME | 消耗在执行器上的时间总和(单位:微秒)。 |
| PL_EXECUTION_TIME | 消耗在PL/SQL执行上的时间总和(单位:微秒)。 |
| CPU_TIME | 所有线程CPU时间消耗总和(单位:微秒)。 |
| PLAN_TIME | 消耗在执行计划生成上的时间总和(单位:微秒)。 |
| REWRITE_TIME | 消耗在查询重写上的时间总和(单位:微秒)。 |
| PL_COMPILATION_TIME | 消耗在SQL编译上的时间总和(单位:微秒)。 |
| PARSE_TIME | 消耗在SQL解析上的时间总和(单位:微秒)。 |
| NET_SEND_TIME | 消耗在网络发送上的时间总和(单位:微秒)。 |
| DATA_IO_TIME | 消耗在数据读写上的时间总和(单位:微秒)。 |
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id
select t2.snap_node_name as "Node Name",
t2.snap_stat_name as "Stat Name",
(t2.snap_value - coalesce(t1.snap_value, 0)) as "Value(us)"
from
(select * from snapshot.snap_global_instance_time
where snapshot_id = %ld
and snap_node_name = '%s') t1
right join
(select * from snapshot.snap_global_instance_time
where snapshot_id = %ld
and snap_node_name = '%s') t2
on t1.snap_stat_name = t2.snap_stat_name
order by "Value(us)"
desc limit 200;Wait Events
- 节点级别的等待事件的统计信息。
- 节点范围报表,仅node模式下可查看此报表。

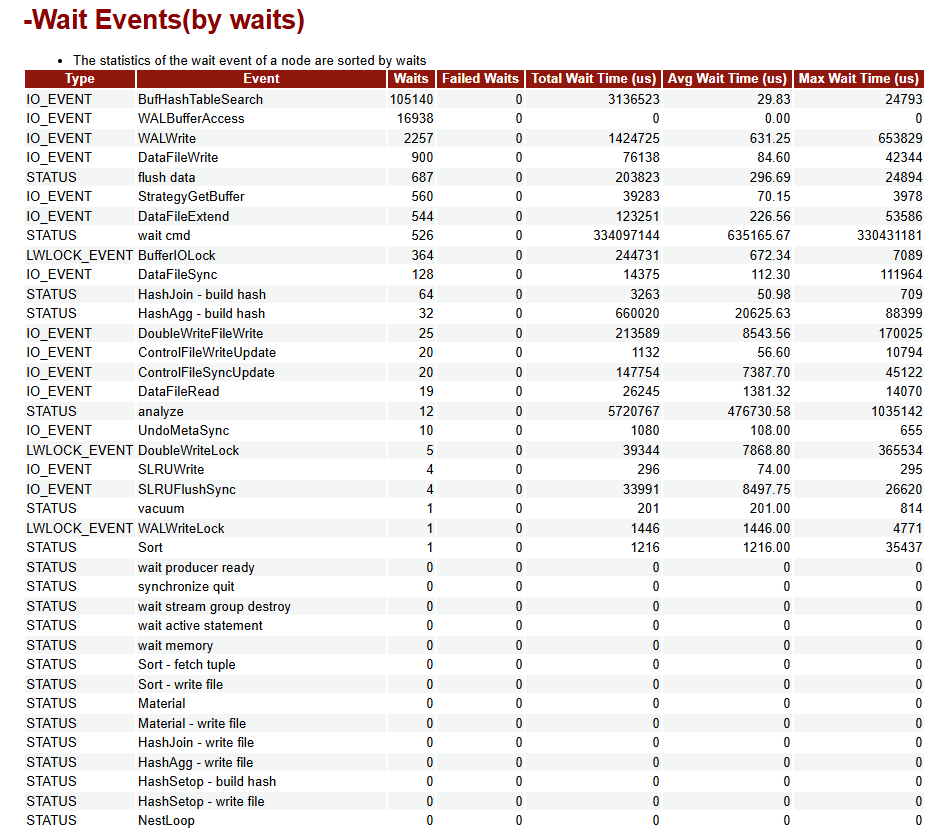
Wait Events报表主要内容
| 列名称 | 描述 |
|---|---|
| Type | Wait Event类别名称: * STATUS。 * LWLOCK_EVENT。 * LOCK_EVENT。 * IO_EVENT。 |
| Event | Wait Event名称。 |
| Total Wait Time (us) | 总Wait时间(us)。 |
| Waits | 总Wait次数。 |
| Failed Waits | Wait失败次数。 |
| Avg Wait Time (us) | 平均Wait时间(us)。 |
| Max Wait Time (us) | 最大Wait时间(us)。 |
IO Profile
- 数据库或者节点维度的IO的使用情况,即IO负载情况。
- 数据库、节点范围报表,cluster模式和node模式下均可查看此报表。

IO Profile指标表主要内容
| 指标名称 | 描述 |
|---|---|
| Database requests | Database IO次数。 |
| Database (MB) | Database IO数据量。 |
| Database (blocks) | Database IO数据块。 |
| Redo requests | Redo IO次数。 |
| Redo (MB) | Redo IO量。 |
Database requests: 即每秒 IO 请求次数,包括请求次数总和、读请求次数、写请求次数.
Database(blocks): 即每秒 block 请求数量,包含请求的 block 总和数量、读 block 的数量和写 block 的数量.
Database(MB): 即将 block 换算成容量(MB)如:blocks \* 8/1024,增加数据的可读性。
Redo requests 和 Redo(MB) 分别表示每秒 redo 的写请求次数和 redo 写的数据量。
相关代码:
-- 由于源码中相关SQL融合了C++程序语法,像我这种不做开发的DBA读起来有些难以理解【如:(phyblkwrt * %d) >> 20 这个段没有很好理解】。
-- 但是依旧不影响我们对这些数据采集方法的理解,相关SQL如下:
-- 两个snapshot_id(24和25)期间,数据块的IO统计信息(数值除以3600即换算成以秒为单位的WDR数据)
postgres=# select
(snap_2.phytotal - snap_1.phytotal) as phytotal,
(snap_2.phyblktotal - snap_1.phyblktotal) as phyblktotal,
(snap_2.phyrds - snap_1.phyrds) as phyrds,
(snap_2.phyblkrd - snap_1.phyblkrd) as phyblkrd,
(snap_2.phywrts - snap_1.phywrts) as phywrts,
(snap_2.phyblkwrt - snap_1.phyblkwrt) as phyblkwrt
from
(select (snap_phyrds + snap_phywrts) as phytotal,
(snap_phyblkwrt + snap_phyblkrd) as phyblktotal,
snap_phyrds as phyrds, snap_phyblkrd as phyblkrd,
snap_phywrts as phywrts, snap_phyblkwrt as phyblkwrt
from snapshot.snap_global_rel_iostat
where snapshot_id = 24 and snap_node_name = 'dn_6001') snap_1,
(select (snap_phyrds + snap_phywrts) as phytotal,
(snap_phyblkwrt + snap_phyblkrd) as phyblktotal,
snap_phyrds as phyrds, snap_phyblkrd as phyblkrd,
snap_phywrts as phywrts, snap_phyblkwrt as phyblkwrt
from snapshot.snap_global_rel_iostat
where snapshot_id = 25 and snap_node_name = 'dn_6001') snap_2;
phytotal | phyblktotal | phyrds | phyblkrd | phywrts | phyblkwrt
----------+-------------+---------+----------+---------+-----------
4626892 | 4626892 | 2955639 | 2955639 | 1671253 | 1671253
-- 两个snapshot_id(24和25)期间,redo的统计信息(数值除以3600即换算成以秒为单位的WDR数据)
postgres=# select
(snap_2.phywrts - snap_1.phywrts) as phywrts,
(snap_2.phyblkwrt - snap_1.phyblkwrt) as phyblkwrt
from
(select sum(snap_phywrts) as phywrts, sum(snap_phyblkwrt) as phyblkwrt
from snapshot.snap_global_file_redo_iostat
where snapshot_id = 24 and snap_node_name = 'dn_6001') snap_1,
(select sum(snap_phywrts) as phywrts, sum(snap_phyblkwrt) as phyblkwrt
from snapshot.snap_global_file_redo_iostat
where snapshot_id = 25 and snap_node_name = 'dn_6001') snap_2;
phywrts | phyblkwrt
---------+-----------
132721 | 509414Report Details
报告明细信息,包含:SQL统计信息,缓存IO状态,对象状态,SQL明细,可以点击连接查看每个细节

SQL Statistics
SQL 执行情况进行统计信息,从 SQL 执行时间、SQL 消耗 CPU 的时间、SQL 返回的行数、SQL 扫描的行数、SQL 执行的次数、SQL 物理读的次数、SQL 逻辑读的次数等多维度对两次快照期间的 SQL 执行情况进行统计
- SQL语句各个维度性能统计,按以下维度排序展示:总时间、平均时间、CPU耗时、返回的行数、扫描的行数、执行次数、逻辑读、物理读。
- 数据库、节点范围报表,cluster模式和node模式下均可查看此报表。

在Node下是SQL ordered by Tuples Read,在Cluster下是SQL ordered by Row Read
SQL Statistics报表主要内容
| 列名称 | 描述 |
|---|---|
| Unique SQL Id | 归一化的SQL ID。 |
| Node Name | 节点名称。 |
| User Name | 用户名称。 |
| Tuples Read | 访问的元组数量。 |
| Calls | 调用次数。 |
| Min Elapse Time(us) | 最小执行时间(us)。 |
| Max Elapse Time(us) | 最大执行时间(us)。 |
| Total Elapse Time(us) | 总执行时间(us)。 |
| Avg Elapse Time(us) | 平均执行时间(us)。 |
| Returned Rows | SELECT返回行数。 |
| Tuples Affected | Insert/Update/Delete行数。 |
| Logical Read | Buffer逻辑读次数。 |
| Physical Read | Buffer物理读次数。 |
| CPU Time(us) | CPU时间(us)。 |
| Data IO Time(us) | IO上的时间花费(us)。 |
| Sort Count | 排序执行的次数。 |
| Sort Time(us) | 排序执行的时间(us)。 |
| Sort Mem Used(KB) | 排序过程中使用的work memory大小(KB)。 |
| Sort Spill Count | 排序过程中,若发生落盘,写文件的次数。 |
| Sort Spill Size(KB) | 排序过程中,若发生落盘,使用的文件大小(KB)。 |
| Hash Count | hash执行的次数。 |
| Hash Time(us) | hash执行的时间(us)。 |
| Hash Mem Used(KB) | hash过程中使用的work memory大小(KB)。 |
| Hash Spill Count | hash过程中,若发生落盘,写文件的次数。 |
| Hash Spill Size(KB) | hash过程中,若发生落盘,使用的文件大小(KB)。 |
| SQL Text | 归一化SQL字符串。 |







Tips:Top200 显得有些冗余,多余的 SQL 信息并没有太大用处,反而降低了可读性,希望将来能优化到 Top20。
相关代码:
-- 由于多个SQL统计信息的SQL语句类似,这里仅列举SQL执行时间的统计SQL,其他的类似。
-- 说明:%s代表node_name,%ld代表snapshot_id
select t2.snap_unique_sql_id as "Unique SQL Id",
t2.snap_user_name as "User Name",
(t2.snap_total_elapse_time - coalesce(t1.snap_total_elapse_time, 0)) as "Total Elapse Time(us)",
(t2.snap_n_calls - coalesce(t1.snap_n_calls, 0)) as "Calls",
round("Total Elapse Time(us)"/greatest("Calls", 1), 0) as "Avg Elapse Time(us)",
t2.snap_min_elapse_time as "Min Elapse Time(us)",
t2.snap_max_elapse_time as "Max Elapse Time(us)",
(t2.snap_n_returned_rows - coalesce(t1.snap_n_returned_rows, 0)) as "Returned Rows",
((t2.snap_n_tuples_fetched - coalesce(t1.snap_n_tuples_fetched, 0)) +
(t2.snap_n_tuples_returned - coalesce(t1.snap_n_tuples_returned, 0))) as "Tuples Read",
((t2.snap_n_tuples_inserted - coalesce(t1.snap_n_tuples_inserted, 0)) +
(t2.snap_n_tuples_updated - coalesce(t1.snap_n_tuples_updated, 0)) +
(t2.snap_n_tuples_deleted - coalesce(t1.snap_n_tuples_deleted, 0))) as "Tuples Affected",
(t2.snap_n_blocks_fetched - coalesce(t1.snap_n_blocks_fetched, 0)) as "Logical Read",
((t2.snap_n_blocks_fetched - coalesce(t1.snap_n_blocks_fetched, 0)) -
(t2.snap_n_blocks_hit - coalesce(t1.snap_n_blocks_hit, 0))) as "Physical Read",
(t2.snap_cpu_time - coalesce(t1.snap_cpu_time, 0)) as "CPU Time(us)",
(t2.snap_data_io_time - coalesce(t1.snap_data_io_time, 0)) as "Data IO Time(us)",
(t2.snap_sort_count - coalesce(t1.snap_sort_count, 0)) as "Sort Count",
(t2.snap_sort_time - coalesce(t1.snap_sort_time, 0)) as "Sort Time(us)",
(t2.snap_sort_mem_used - coalesce(t1.snap_sort_mem_used, 0)) as "Sort Mem Used(KB)",
(t2.snap_sort_spill_count - coalesce(t1.snap_sort_spill_count, 0)) as "Sort Spill Count",
(t2.snap_sort_spill_size - coalesce(t1.snap_sort_spill_size, 0)) as "Sort Spill Size(KB)",
(t2.snap_hash_count - coalesce(t1.snap_hash_count, 0)) as "Hash Count",
(t2.snap_hash_time - coalesce(t1.snap_hash_time, 0)) as "Hash Time(us)",
(t2.snap_hash_mem_used - coalesce(t1.snap_hash_mem_used, 0)) as "Hash Mem Used(KB)",
(t2.snap_hash_spill_count - coalesce(t1.snap_hash_spill_count, 0)) as "Hash Spill Count",
(t2.snap_hash_spill_size - coalesce(t1.snap_hash_spill_size, 0)) as "Hash Spill Size(KB)",
LEFT(t2.snap_query, 25) as "SQL Text"
from
(select * from snapshot.snap_summary_statement where snapshot_id = %ld and snap_node_name = '%s') t1
right join
(select * from snapshot.snap_summary_statement where snapshot_id = %ld and snap_node_name = '%s') t2
on t1.snap_unique_sql_id = t2.snap_unique_sql_id
and t1.snap_user_id = t2.snap_user_id
order by "Total Elapse Time(us)"
desc limit 200;Cache IO Stats
- 用户的表、索引的IO的统计信息。
- 数据库、节点范围报表,cluster模式和node模式下均可查看此报表。




Cache IO Stats包含User table和User index两张表,列名称及描述如下所示。
User table IO activity ordered by heap blks hit ratio
表 1 User table IO activity ordered by heap blks hit ratio报表主要内容
| 列名称 | 描述 |
|---|---|
| DB Name | Database名称。 |
| Schema Name | Schema名称。 |
| Table Name | Table名称。 |
| %Heap Blks Hit Ratio | 此表的Buffer Pool命中率。 |
| Heap Blks Read | 该表中读取的磁盘块数。 |
| Heap Blks Hit | 此表缓存命中数。 |
| Idx Blks Read | 表中所有索引读取的磁盘块数。 |
| Idx Blks Hit | 表中所有索引命中缓存数。 |
| Toast Blks Read | 此表的TOAST表读取的磁盘块数(如果存在)。 |
| Toast Blks Hit | 此表的TOAST表命中缓冲区数(如果存在)。 |
| Tidx Blks Read | 此表的TOAST表索引读取的磁盘块数(如果存在)。 |
| Tidx Blks Hit | 此表的TOAST表索引命中缓冲区数(如果存在)。 |
这一部分根据 Heap block 的命中率排序统计用户表的 IO 活动状态。
数据来源于 snapshot.snap_global_statio_all_indexes 表和 snapshot.snap_global_statio_all_tables 表。
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id
SELECT table_io.db_name as "DB Name",
table_io.snap_schemaname as "Schema Name",
table_io.snap_relname as "Table Name",
table_io.heap_blks_hit_ratio as "%Heap Blks Hit Ratio",
table_io.heap_blks_read as "Heap Blks Read",
table_io.heap_blks_hit as "Heap Blks Hit",
idx_io.idx_blks_read as "Idx Blks Read",
idx_io.idx_blks_hit as "Idx Blks Hit",
table_io.toast_blks_read as "Toast Blks Read",
table_io.toast_blks_hit as "Toast Blks Hit",
table_io.tidx_blks_read as "Tidx Blks Read",
table_io.tidx_blks_hit as "Tidx Blks Hit"
FROM
(select t2.db_name, t2.snap_schemaname , t2.snap_relname ,
(case
when ((t2.snap_heap_blks_read - coalesce(t1.snap_heap_blks_read, 0)) + (t2.snap_heap_blks_hit - coalesce(t1.snap_heap_blks_hit, 0))) = 0
then 0
else round((t2.snap_heap_blks_hit - coalesce(t1.snap_heap_blks_hit, 0))/
((t2.snap_heap_blks_read - coalesce(t1.snap_heap_blks_read, 0)) + (t2.snap_heap_blks_hit - coalesce(t1.snap_heap_blks_hit, 0))) * 100, 2)
end ) as heap_blks_hit_ratio,
(t2.snap_heap_blks_read - coalesce(t1.snap_heap_blks_read, 0)) as heap_blks_read,
(t2.snap_heap_blks_hit - coalesce(t1.snap_heap_blks_hit, 0)) as heap_blks_hit,
(t2.snap_idx_blks_read - coalesce(t1.snap_idx_blks_read, 0)) as idx_blks_read,
(t2.snap_idx_blks_hit - coalesce(t1.snap_idx_blks_hit, 0)) as idx_blks_hit,
(t2.snap_toast_blks_read - coalesce(t1.snap_toast_blks_read, 0)) as toast_blks_read,
(t2.snap_toast_blks_hit - coalesce(t1.snap_toast_blks_hit, 0)) as toast_blks_hit,
(t2.snap_tidx_blks_read - coalesce(t1.snap_tidx_blks_read, 0)) as tidx_blks_read,
(t2.snap_tidx_blks_hit - coalesce(t1.snap_tidx_blks_hit, 0)) as tidx_blks_hit from
(select * from snapshot.snap_global_statio_all_tables
where snapshot_id = %ld and snap_node_name = '%s'
and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot')
and snap_schemaname !~ '^pg_toast') t1
right join
(select * from snapshot.snap_global_statio_all_tables
where snapshot_id = %ld
and snap_node_name = '%s'
and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot')
and snap_schemaname !~ '^pg_toast') t2
on t1.snap_relid = t2.snap_relid
and t2.db_name = t1.db_name
and t2.snap_schemaname = t1.snap_schemaname ) as table_io
LEFT JOIN
(select t2.db_name , t2.snap_schemaname , t2.snap_relname,
(t2.snap_idx_blks_read - coalesce(t1.snap_idx_blks_read, 0)) as idx_blks_read,
(t2.snap_idx_blks_hit - coalesce(t1.snap_idx_blks_hit, 0)) as idx_blks_hit
from
(select * from snapshot.snap_global_statio_all_indexes
where snapshot_id = %ld
and snap_node_name = '%s'
and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot')
and snap_schemaname !~ '^pg_toast') t1
right join
(select * from snapshot.snap_global_statio_all_indexes
where snapshot_id = %ld
and snap_node_name = '%s'
and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot')
AND snap_schemaname !~ '^pg_toast') t2
on t1.snap_relid = t2.snap_relid
and t2.snap_indexrelid = t1.snap_indexrelid
and t2.db_name = t1.db_name and t2.snap_schemaname = t1.snap_schemaname) as idx_io
on table_io.db_name = idx_io.db_name
and table_io.snap_schemaname = idx_io.snap_schemaname
and table_io.snap_relname = idx_io.snap_relname
order by "%%Heap Blks Hit Ratio"
asc limit 200;User index IO activity ordered by idx blks hit ratio
表 2 User index IO activity ordered by idx blks hit ratio报表主要内容
| 列名称 | 描述 |
|---|---|
| DB Name | Database名称。 |
| Schema Name | Schema名称。 |
| Table Name | Table名称。 |
| Index Name | Index名称。 |
| %Idx Blks Hit Ratio | Index的命中率。 |
| Idx Blks Read | 所有索引读取的磁盘块数。 |
| Idx Blks Hit | 所有索引命中缓存数。 |
根据索引缓存命中率,统计用户索引 IO 活动信息
数据来源于 snapshot.snap_global_statio_all_indexes 表。
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id
select t2.db_name as "DB Name",
t2.snap_schemaname as "Schema Name",
t2.snap_relname as "Table Name",
t2.snap_indexrelname as "Index Name",
(case
when ((t2.snap_idx_blks_read - coalesce(t1.snap_idx_blks_read, 0)) + (t2.snap_idx_blks_hit - coalesce(t1.snap_idx_blks_hit, 0))) = 0 then 0
else
round((t2.snap_idx_blks_hit - coalesce(t1.snap_idx_blks_hit, 0))/((t2.snap_idx_blks_hit - coalesce(t1.snap_idx_blks_hit, 0)) +
(t2.snap_idx_blks_read - coalesce(t1.snap_idx_blks_read, 0))) * 100, 2)
end) as "%Idx Blks Hit Ratio",
(t2.snap_idx_blks_read - coalesce(t1.snap_idx_blks_read, 0)) as "Idx Blks Read",
(t2.snap_idx_blks_hit - coalesce(t1.snap_idx_blks_hit, 0)) as "Idx Blks Hit"
from
(select * from snapshot.snap_global_statio_all_indexes
where snapshot_id = %ld
and snap_node_name = '%s'
and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot')
and snap_schemaname !~ '^pg_toast') t1
right join
(select * from snapshot.snap_global_statio_all_indexes
where snapshot_id = %ld
and snap_node_name = '%s'
and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot')
and snap_schemaname !~ '^pg_toast') t2
on t1.snap_relid = t2.snap_relid
and t2.snap_indexrelid = t1.snap_indexrelid
and t2.db_name = t1.db_name
and t2.snap_schemaname = t1.snap_schemaname
order by "%Idx Blks Hit Ratio"
asc limit 200;Object Stats
- 表、索引维度的性能统计信息。
- 数据库、节点范围报表,cluster模式和node模式下均可查看此报表。
Object stats包含User Tables stats、User index stats和Bad lock stats三张表,列名称及描述如下所示。
User Tables Stats
表 1 User Tables stats报表主要内容
| 列名称 | 描述 |
|---|---|
| DB Name | Database名称。 |
| Schema | Schema名称。 |
| Relname | Relation名称。 |
| Seq Scan | 此表发起的顺序扫描数。 |
| Seq Tup Read | 顺序扫描抓取的活跃行数。 |
| Index Scan | 此表发起的索引扫描数。 |
| Index Tup Fetch | 索引扫描抓取的活跃行数。 |
| Tuple Insert | 插入行数。 |
| Tuple Update | 更新行数。 |
| Tuple Delete | 删除行数。 |
| Tuple Hot Update | HOT更新行数(即没有更新所需的单独索引)。 |
| Live Tuple | 估计活跃行数。 |
| Dead Tuple | 估计死行数。 |
| Last Vacuum | 最后一次此表是手动清理的(不计算VACUUM FULL)时间。 |
| Last Autovacuum | 上次被autovacuum守护进程清理的时间。 |
| Last Analyze | 上次手动分析这个表的时间。 |
| Last Autoanalyze | 上次被autovacuum守护进程分析的时间。 |
| Vacuum Count | 这个表被手动清理的次数(不计算VACUUM FULL)。 |
| Autovacuum Count | 这个表被autovacuum清理的次数。 |
| Analyze Count | 这个表被手动分析的次数。 |
| Autoanalyze Count | 这个表被autovacuum守护进程分析的次数。 |
描述用户表状态的统计信息
数据源于 snapshot.snap_global_stat_all_tables 表。
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id
SELECT snap_2.db_name as "DB Name",
snap_2.snap_schemaname as "Schema",
snap_2.snap_relname as "Relname",
(snap_2.snap_seq_scan - coalesce(snap_1.snap_seq_scan, 0)) as "Seq Scan",
(snap_2.snap_seq_tup_read - coalesce(snap_1.snap_seq_tup_read, 0)) as "Seq Tup Read",
(snap_2.snap_idx_scan - coalesce(snap_1.snap_idx_scan, 0)) as "Index Scan",
(snap_2.snap_idx_tup_fetch - coalesce(snap_1.snap_idx_tup_fetch, 0)) as "Index Tup Fetch",
(snap_2.snap_n_tup_ins - coalesce(snap_1.snap_n_tup_ins, 0)) as "Tuple Insert",
(snap_2.snap_n_tup_upd - coalesce(snap_1.snap_n_tup_upd, 0)) as "Tuple Update",
(snap_2.snap_n_tup_del - coalesce(snap_1.snap_n_tup_del, 0)) as "Tuple Delete",
(snap_2.snap_n_tup_hot_upd - coalesce(snap_1.snap_n_tup_hot_upd, 0)) as "Tuple Hot Update",
snap_2.snap_n_live_tup as "Live Tuple",
snap_2.snap_n_dead_tup as "Dead Tuple",
to_char(snap_2.snap_last_vacuum, 'YYYY-MM-DD HH24:MI:SS') as "Last Vacuum",
to_char(snap_2.snap_last_autovacuum, 'YYYY-MM-DD HH24:MI:SS') as "Last Autovacuum",
to_char(snap_2.snap_last_analyze, 'YYYY-MM-DD HH24:MI:SS') as "Last Analyze",
to_char(snap_2.snap_last_autoanalyze, 'YYYY-MM-DD HH24:MI:SS') as "Last Autoanalyze",
(snap_2.snap_vacuum_count - coalesce(snap_1.snap_vacuum_count, 0)) as "Vacuum Count",
(snap_2.snap_autovacuum_count - coalesce(snap_1.snap_autovacuum_count, 0)) as "Autovacuum Count",
(snap_2.snap_analyze_count - coalesce(snap_1.snap_analyze_count, 0)) as "Analyze Count",
(snap_2.snap_autoanalyze_count - coalesce(snap_1.snap_autoanalyze_count, 0)) as "Autoanalyze Count"
FROM
(SELECT * FROM snapshot.snap_global_stat_all_tables
WHERE snapshot_id = %ld
and snap_node_name = '%s'
and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot')
AND snap_schemaname !~ '^pg_toast') snap_2
LEFT JOIN
(SELECT * FROM snapshot.snap_global_stat_all_tables
WHERE snapshot_id = %ld
and snap_node_name = '%s'
and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot')
AND snap_schemaname !~ '^pg_toast') snap_1
ON snap_2.snap_relid = snap_1.snap_relid
AND snap_2.snap_schemaname = snap_1.snap_schemaname
AND snap_2.snap_relname = snap_1.snap_relname
AND snap_2.db_name = snap_1.db_name
order by snap_2.db_name, snap_2.snap_schemaname
limit 200;User index stats
表 2 User index stats报表主要内容
| 列名称 | 描述 |
|---|---|
| DB Name | Database名称。 |
| Schema | Schema名称。 |
| Relname | Relation名称。 |
| Index Relname | Index名称。 |
| Index Scan | 索引上开始的索引扫描数。 |
| Index Tuple Read | 通过索引上扫描返回的索引项数。 |
| Index Tuple Fetch | 通过使用索引的简单索引扫描抓取的表行数。 |
用户索引状态的统计信息
数据源于 snapshot.snap_global_stat_all_indexes 表。
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id
SELECT snap_2.db_name as "DB Name",
snap_2.snap_schemaname as "Schema",
snap_2.snap_relname as "Relname",
snap_2.snap_indexrelname as "Index Relname",
(snap_2.snap_idx_scan - coalesce(snap_1.snap_idx_scan, 0)) as "Index Scan",
(snap_2.snap_idx_tup_read - coalesce(snap_1.snap_idx_tup_read, 0)) as "Index Tuple Read",
(snap_2.snap_idx_tup_fetch - coalesce(snap_1.snap_idx_tup_fetch, 0)) as "Index Tuple Fetch"
FROM
(SELECT * FROM snapshot.snap_global_stat_all_indexes
WHERE snapshot_id = %ld
and snap_node_name = '%s'
and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot')
and snap_schemaname !~ '^pg_toast') snap_2
LEFT JOIN
(SELECT * FROM snapshot.snap_global_stat_all_indexes
WHERE snapshot_id = %ld
and snap_node_name = '%s'
and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot')
and snap_schemaname !~ '^pg_toast') snap_1
ON snap_2.snap_relid = snap_1.snap_relid
and snap_2.snap_indexrelid = snap_1.snap_indexrelid
and snap_2.snap_schemaname = snap_1.snap_schemaname
and snap_2.snap_relname = snap_1.snap_relname
and snap_2.snap_indexrelname = snap_1.snap_indexrelname
and snap_2.db_name = snap_1.db_name
order by snap_2.db_name, snap_2.snap_schemaname
limit 200;Bad lock stats
表 3 Bad lock stats报表主要内容
| 列名称 | 描述 |
|---|---|
| DB Id | 数据库的OID。 |
| Tablespace Id | 表空间的OID。 |
| Relfilenode | 文件对象ID。 |
| Fork Number | 文件类型。 |
| Error Count | 失败计数。 |
| First Time | 第一次发生时间。 |
| Last Time | 最近一次发生时间。 |
描述坏块的统计信息
数据源于 snapshot.snap_global_stat_bad_block 表。
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id
SELECT snap_2.snap_databaseid AS "DB Id",
snap_2.snap_tablespaceid AS "Tablespace Id",
snap_2.snap_relfilenode AS "Relfilenode",
snap_2.snap_forknum AS "Fork Number",
(snap_2.snap_error_count - coalesce(snap_1.snap_error_count, 0)) AS "Error Count",
snap_2.snap_first_time AS "First Time",
snap_2.snap_last_time AS "Last Time"
FROM
(SELECT * FROM snapshot.snap_global_stat_bad_block
WHERE snapshot_id = %ld
and snap_node_name = '%s') snap_2
LEFT JOIN
(SELECT * FROM snapshot.snap_global_stat_bad_block
WHERE snapshot_id = %ld
and snap_node_name = '%s') snap_1
ON snap_2.snap_databaseid = snap_1.snap_databaseid
and snap_2.snap_tablespaceid = snap_1.snap_tablespaceid
and snap_2.snap_relfilenode = snap_1.snap_relfilenode
limit 200;


Utility status
- 复制槽和后台checkpoint的状态信息。
- 节点范围报表,仅node模式下可查看此报表。

Utility status包含Replication slot和Replication stat两张表,列名称及描述如下所示。
Replication slot
表 1 Replication slot报表主要内容
| 列名称 | 描述 |
|---|---|
| Slot Name | 复制节点名。 |
| Slot Type | 复制节点类型。 |
| DB Name | 复制节点数据库名称。 |
| Active | 复制节点状态。 |
| Xmin | 复制节点事务标识。 |
| Restart Lsn | 复制节点的Xlog文件信息。 |
| Dummy Standby | 复制节点假备。 |
描述的是复制槽的相关信息
解读: 本次实验环境是单机,没有复制槽数据
这一部分描述的是复制槽的相关信息。数据来源于:snapshot.snap_global_replication_slots 表。
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id
SELECT snap_slot_name as "Slot Name",
snap_slot_type as "Slot Type",
snap_database as "DB Name",
snap_active as "Active",
snap_x_min as "Xmin",
snap_restart_lsn as "Restart Lsn",
snap_dummy_standby as "Dummy Standby"
FROM snapshot.snap_global_replication_slots
WHERE snapshot_id = %ld
and snap_node_name = '%s'
limit 200;Replication stat
表 2 Replication stat报表主要内容
| 列名称 | 描述 |
|---|---|
| Thread Id | 线程的PID。 |
| Usesys Id | 用户系统ID。 |
| Usename | 用户名称。 |
| Application Name | 应用程序。 |
| Client Addr | 客户端地址。 |
| Client Hostname | 客户端主机名。 |
| Client Port | 客户端端口。 |
| Backend Start | 程序起始时间。 |
| State | 日志复制状态。 |
| Sender Sent Location | 发送端发送日志位置。 |
| Receiver Write Location | 接收端write日志位置。 |
| Receiver Flush Location | 接收端flush日志位置。 |
| Receiver Replay Location | 接收端replay日志位置。 |
| Sync Priority | 同步优先级。 |
| Sync State | 同步状态。 |
描述事务槽详细的状态信息
解读: 本次实验环境是单机,没有复制槽数据
这一部分描述事务槽详细的状态信息,数据源于 snapshot.snap_global_replication_stat 表。
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id
SELECT snap_pid as "Thread Id",
snap_usesysid as "Usesys Id",
snap_usename as "Usename",
snap_application_name as "Application Name",
snap_client_addr as "Client Addr",
snap_client_hostname as "Client Hostname",
snap_client_port as "Client Port",
snap_backend_start as "Backend Start",
snap_state as "State",
snap_sender_sent_location as "Sender Sent Location",
snap_receiver_write_location as "Receiver Write Location",
snap_receiver_flush_location as "Receiver Flush Location",
snap_receiver_replay_location as "Receiver Replay Location",
snap_sync_priority as "Sync Priority",
snap_sync_state as "Sync State"
FROM snapshot.snap_global_replication_stat
WHERE snapshot_id = %ld
and snap_node_name = '%s' limit 200;SQL Detail
- SQL语句文本详情。
- 数据库、节点范围报表,cluster模式和node模式下均可查看此报表。

SQL Detail报表主要内容
| 列名称 | 描述 |
|---|---|
| Unique SQL Id | 归一化SQL ID。 |
| User Name | 用户名称。 |
| Node Name | 节点名称。Node模式下不显示该字段。 |
| SQL Text | 归一化SQL文本。即 SQL 的具体内容 |
数据来源于 snapshot.snap_summary_statement 表。
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id
select (t2.snap_unique_sql_id) as "Unique SQL Id",
(t2.snap_query) as "SQL Text"
from
snapshot.snap_summary_statement t2
where snapshot_id = %ld
and snap_node_name = '%s';Configuration settings
- 节点配置。
- 节点范围报表,仅node模式下可查看此报表。

Configuration settings报表主要内容
| 列名称 | 描述 |
|---|---|
| Name | GUC名称。 |
| Abstract | GUC描述。 |
| Type | 数据类型。 |
| Curent Value | 当前值。 |
| Min Value | 合法最小值。 |
| Max Value | 合法最大值。 |
| Category | GUC类别。 |
| Enum Values | 如果是枚举值,列举所有枚举值。 |
| Default Value | 数据库启动时参数默认值。 |
| Reset Value | 数据库重置时参数默认值。 |
数据源于 snapshot.snap_global_config_settings 表。
信息内容如下所示:
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id
select snap_name as "Name",
snap_short_desc as "Abstract",
snap_vartype as "Type",
snap_setting as "Curent Value",
snap_min_val as "Min Value",
snap_max_val as "Max Value",
snap_category as "Category",
snap_enumvals as "Enum Values",
snap_boot_val as "Default Value",
snap_reset_val as "Reset Value"
FROM
snapshot.snap_global_config_settings
WHERE snapshot_id = %ld
and snap_node_name = '%s';注意:
用于生成报告的两个快照应满足以下条件:
- 两次快照之间不能有节点重启。
- 两次快照之间不能有主备倒换。
- 两次快照之间不能对性能指标进行reset操作。
- 两次快照之间不能有drop database操作。
- 生成的WDR中如果存在负数时,说明该指标不能反映数据库的表现。
- 生成报告的时间与性能快照中的性能数据量有关系,一般在分钟级可以完成。如果超过5分钟没有完成,请尝试收集snapshot schema下的表(首先考虑snap_global_statio_all_tables,snap_global_statio_all_indexes)的统计信息ANALYZE | ANALYSE,然后再次运行报告生成。或者设置会话级语句超时时间set statement_timeout=*,主动终止报告生成。
- 生成报告时,尽量设置客户端的字符集与GaussDB数据库的字符集保持一致(可以通过set client_encoding to *去设置客户端字符集)。
参考: