概述
官方文档:https://www.elastic.co/docs/manage-data/data-store/index-basics
索引是Elasticsearch中的基本存储单元,类似于MySql数据库中的表,包含一堆有相似结构的文档数据,在Elasticsearch可以创建多个索引。
tips:
每个索引默认有5个主分片,1个副本分片,其中的主分片和副本分片的作用,我们下面讲解。
添加至索引中的数据,会被近实时(1秒内)的被搜索(这里不是立即可以被检索)
近实时被搜索如何理解?下面我们会仔细讲解,参考文档:https://www.elastic.co/docs/manage-data/data-store/near-real-time-search
索引的组成
逻辑层面
从逻辑层面来看,索引是由下面几个部分组成:
- 分片
- 索引的逻辑拆分单元,每个分片是一个独立的 Lucene 索引
- 主分片(Primary Shards)负责数据写入和读取,副本分片(Replica Shards)用于容错和负载均衡
- 分片数量在索引创建时指定,默认 5 个主分片,1个副本分片,可通过设置调整
设置分片示例
PUT /my_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}- 映射(Mapping)
- 定义索引中字段,字段的类型、分词器、存储方式等元数据
- 支持动态映射(自动推断字段类型)和手动映射(精确控制字段行为)
映射示例:
{
"mappings": {
"properties": {
"title": { "type": "text", "analyzer": "ik_max_word" },
"tags": { "type": "keyword" },
"create_time": { "type": "date" }
}
}
}- 文档(Document)
- 索引中真实的数据记录,类似mysql表中的行数据
- 索引的最小数据单元,以 JSON 格式存储,包含多个字段(Fields)
- 每个文档有唯一标识符(ID),可自动生成或手动指定
示例文档记录
{
"_index": "my-first-elasticsearch-index",
"_id": "DyFpo5EBxE8fzbb95DOa",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"email": "john@smith.com",
"first_name": "John",
"last_name": "Smith",
"info": {
"bio": "Eco-warrior and defender of the weak",
"age": 25,
"interests": [
"dolphins",
"whales"
]
},
"join_date": "2024/05/01"
}
}物理层面
ES 索引的底层基于 Lucene,其物理存储由以下部分构成:
- Lucene 分段(Segments)
- 索引的物理存储单元,每个分段是一个独立的倒排索引
- 分段由 Refresh 操作生成,包含文档的索引数据和元数据
- 分段特性:
- 不可变(Immutable),生成后无法修改,保证搜索时的数据一致性
- 后台自动合并(Merge),减少分段数量,优化搜索性能
- 倒排索引(Inverted Index)
- Lucene 的核心数据结构,是 ES 快速检索的基础
- 倒排索引将 "文档 - 词语" 的正向关系转换为 "词语 - 文档列表" 的反向关系
结构示例:
词语(Term) | 文档ID列表(Postings List)
-----------|---------------------------
Elasticsearch | [1, 3, 5]
搜索引擎 | [1, 2, 4]
分布式 | [1, 3, 4]-
索引文件(Index Files)
- 每个 Lucene 分段包含多个索引文件,常见类型:
- *.nvd:存储文档字段值
- *.nvm:字段值的元数据
- *.tim:记录词语(Term)的字典和频率
- *.doc:文档偏移量索引
- *.pos:词语在文档中的位置信息(用于短语搜索)
- *.dim:分段元数据(如创建时间、版本等)
- 每个 Lucene 分段包含多个索引文件,常见类型:
-
事务日志(Translog)
- 记录所有未持久化的索引操作,确保数据不丢失
- 存储路径:
data/<cluster_name>/nodes/<node_id>/indices/<index_uuid>/translog - 作用:
- 保障 ES 重启后数据恢复
- 支持增量恢复(Incremental Recovery)
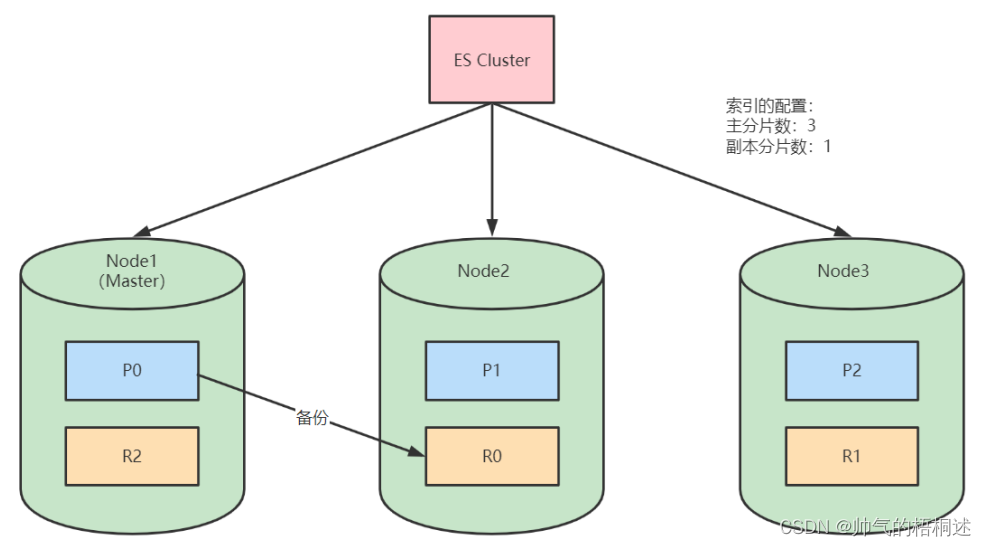
索引分片的作用
主分片
主分片是 Elasticsearch(ES)索引数据存储的基础单元。也是实现ES分布式高可用的基石,主分片在创建索引时通过number_of_shards指定,默认是5个主分片,主分片的数量可以根据主节点的数量来进行设置。
常规业务场景下(数据量中等,单分片≤50GB),每个节点的分片可以设置成1-2个,例如你的主节点有3个,在每个节点的资源规格都一样的情况下,那么你的主分片可以设置为3个或者6个
大数据量场景下(单分片 50GB100GB,总数据量≤600GB),每个节点的分片可以设置成34个,例如你的主节点有3个,在每个节点的资源规格都一样的情况下,那么你的主分片可以设置为9个或者12个
主分片经过设置之后是不可更改的,所以在设置主分片时需要经过慎重的考虑。
其主要作用有以下几点:
-
每个索引被拆分为多个主分片(默认 5 个),每个主分片是一个独立的 Lucene 索引,负责存储索引的部分文档数据,当执行搜索、更新、删除等操作时,请求会被分发到相关主分片上执行,确保数据操作的直接性和高效性。
-
主分片是数据写入的唯一入口:所有文档的创建、更新、删除操作都首先在主分片上完成,再同步到副本分片,主分片维护着文档的最新版本和元数据(如版本号、路由信息),确保集群内数据的一致性。
-
通过增加主分片数量(创建索引时指定),可以将数据分散到更多节点,提升集群的存储容量和并发处理能力。每个主分片可独立分配到不同节点,实现负载均衡(如通过 ES 的分片分配机制自动调整)。
副本分片
副本分片是主分片的镜像拷贝,主要为集群提供可靠性、可用性和性能优化能力。副本分片占用与主分片相同的存储空间,增加副本会提高内存和磁盘使用量,副本分片在创建索引时通过number_of_replicas指定,默认值是1。
副本分片设置之后是可以修改的,如下:
PUT /your_index/_settings
{
"number_of_replicas": 2 // 设置副本数为2
}副本分片的作用如下:
-
当某个节点故障或主分片所在节点不可用时,副本分片会被提升为新的主分片(通过 ES 的自动故障转移机制),确保服务不中断,每个副本分片与主分片分布在不同节点(默认策略),避免单点故障(如节点硬件故障、网络分区)导致数据丢失
-
副本分片可处理读请求(如搜索、获取文档),分担主分片的查询压力,尤其在高并发场景下显著提升集群吞吐量,同一索引的副本分片越多,可并行处理的读请求越多(如每个副本分片可独立响应查询)。
-
副本分片是数据的冗余存储,即使部分节点损坏,仍可通过其他节点的副本恢复完整数据(无需依赖外部备份),可通过调整副本数量(默认 1 个)平衡可用性和资源消耗(每个副本占用与主分片相同的存储空间)。
修改副本分片的注意事项
- 注意资源消耗
- 每个副本分片占用与主分片相同的存储空间,增加副本会提高内存和磁盘使用量。
- 例如5 主分片 ×2 副本 = 15 个分片,需预留相应存储和 JVM 堆内存。
- 注意性能影响
- 增加副本可提升读性能(更多分片可并行处理查询),但修改期间会产生网络流量(复制数据),可能短暂影响集群性能。
- 建议在低峰期执行大规模副本调整。
- 故障转移能力
- 至少保留 1 个副本以保证高可用(允许 1 个节点故障)。
- 若需容忍 N 个节点故障,副本数应≥N。
- 集群状态监控
- 修改过程中通过GET /_cluster/health监控集群状态,确保status为green或yellow(red表示有未分配的主分片)
副本分片和主分片的数量对应关系
当主分片设置成3,副本分片设置成1时,那么一共会有6个分片存在集群中,副本分片的1是将对应的3个主分片分别copy一份在不同的节点中。
索引的近实时性
官方文档:https://www.elastic.co/docs/manage-data/data-store/near-real-time-search
近实时性是指当数据写入至ES的索引中,需要一定时间(官方描述的是1秒内)才能被检索到,这个可以通过下面的参数设置
# 索引创建时设置refresh_interval为500ms
PUT /my_index
{
"settings": {
"refresh_interval": "500ms" # 默认1000ms,也就是1秒
}
}refresh_interval参数并不是设置的越小越好,当值为0时,会禁用自动 Refresh,仍需手动触发 Refresh 才能让文档可搜索,这会引入人为延迟(人为操作,延迟可能更大)。
Refesh机制
Refresh 机制是控制近实时性的关键
- 默认 Refresh 间隔:ES 默认每 1 秒执行一次 Refresh 操作,这就是 "1 秒近实时" 的来源
- 手动触发 Refresh:可通过 API 强制刷新,实现更低延迟(如POST /index/_refresh)
- 性能与实时性的权衡:缩短 Refresh 间隔会提高实时性,但会增加 IO 开销;延长间隔则反之
为什么ES不是 "完全实时"的?
- Refresh 间隔的存在:即使将refresh_interval设为 0(禁用自动 Refresh),仍需手动触发 Refresh 才能让文档可搜索,这会引入人为延迟。
- 写入流程的固有延迟:文档从写入到生成分段需要经历内存缓冲区处理,无法做到完全实时(如数据库的实时查询)。
- 设计权衡:ES 牺牲极小的实时性(1 秒)换取高性能和分布式架构的稳定性,这是分布式搜索系统的典型设计。
索引的管理
ES的索引类似类似数据库中的表,管理ES的索引需要通过ES的API来进行管理。索引的API主要有以下
创建索引
API
PUT /{index}
{
"aliases": { ... }, # 指定索引别名
"settings": { ... }, # 指定索引的设置
"mappings": { ... } # 指定映射
}参数说明:
index:索引的名称,需要遵循以下规则:
- 仅限小写字母
- 不能包含\、/、 *、?、"、<、>、|、#以及空格符等特殊符号
- 从7.0版本开始不再包含冒号
- 不能以-、_或+开头
- 不能超过255个字节(注意它是字节,因此多字节字符将计入255个限制)
aliases:索引别名(Aliases) 是指向一个或多个索引的逻辑名称,可用于简化查询、实现读写分离或索引滚动等场景
settings:索引的配置参数,如分片数、副本数、刷新间隔等。常用的配置参数为:
- number_of_shards:指定索引分片
- number_of_replicas:指定副本数
- refresh_interval:指定刷新时间,单位秒
- auto_expand_replicas:自动调整副本数(根据节点数)
- indices.memory.index_buffer_size:索引缓冲区占堆内存的比例(默认10%)
- index.translog.durability:异步刷新事务日志(默认sync)
- index.translog.flush_threshold_size:事务日志刷新阈值
- index.queries.cache.enabled:启用查询结果缓存(默认true)
- indices.queries.cache.size:缓存占堆内存比例
- indices.fielddata.cache.size:字段数据缓存大小
- index.priority:控制索引在恢复和分片分配时的优先级
- index.routing.allocation.include.tag:强制分片分配到特定节点,包含特定标签的节点
- index.routing.allocation.exclude._name:强制分片分配到特定节点,排除特定节点
- index.blocks.write:true设置索引只读
- index.hidden:true设置索引隐藏,不显示在_cat/indices
- index.max_result_window:调整深度分页限制,默认10000,慎用!推荐用scroll或search_after
mappings:定义索引字段的数据类型和索引方式。后续会单独讲解mappings
实战:创建第一个索引
可以进入kibana进行创建:
示例:
# 创建请求
PUT index_test01
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"refresh_interval": "1s"
}
}
# 预期返回
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "index_test01"
}查看索引
查看所有的索引
示例:
# 请求接口
GET /_cat/indices?v&s=index
# 预期返回
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .apm-agent-configuration KC2krPV1Q6On8zLG-2Ap6g 1 1 0 0 454b 227b
green open .apm-custom-link fW3LcrktTOGTDKvglhgODQ 1 1 0 0 454b 227b
green open .kibana_7.17.26_001 Bv6ZMZL6STaho_Phwbrv1w 1 1 691 16 5.3mb 2.8mb
green open .kibana_task_manager_7.17.26_001 0wrV35RzTWahe5vAUJKVow 1 1 17 25815 5.8mb 2.8mb
green open index_test01 TRTmGpiNRuC1wZY49Wt_aA 3 1 0 0 1.3kb 681b返回字段说明:
- health:索引的健康程度,green表示所有主分片和副本分片都正常运行,red表示至少有一个主分片未分配(数据可能丢失),yellow表示主分片正常,但至少有一个副本分片未分配
- status:open表示索引可正常读写,close表示索引已关闭,不可访问
- index:索引名称,以 . 开头的通常是系统索引,如 Kibana、APM 等组件创建的索引
- uuid:索引的唯一标识符(用于内部识别,不可修改)
- pri:主分片数量(创建索引时指定,不可动态修改)
- rep:主分片的副本数量(可动态调整)
- docs.count:索引中的文档总数
- docs.deleted:已标记删除但尚未物理删除的文档数(段合并后会清理)
- store.size:索引的总存储大小(包括主分片和所有副本)
- pri.store.size:主分片的存储大小(不包括副本)
查看指定的索引
api:GET /{index-name}
示例:
# 请求
GET /index_test01
# 预期返回
{
"index_test01" : {
"aliases" : { },
"mappings" : { },
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"refresh_interval" : "1s", # 刷新时间
"number_of_shards" : "3", # 主分片数量
"provided_name" : "index_test01", # 索引名称
"creation_date" : "1750482108424", # 创建时间
"number_of_replicas" : "1", # 副本数量
"uuid" : "TRTmGpiNRuC1wZY49Wt_aA", # uuid,唯一标识符
"version" : {
"created" : "7172699"
}
}
}
}
}其它查询的api
| API 路径 | 功能描述 | 示例 |
|---|---|---|
GET /{index}/_settings |
获取索引设置 | GET /products/_settings |
GET /{index}/_mapping |
获取索引映射 | GET /products/_mapping |
GET /{index}/_alias |
获取索引别名 | GET /products/_alias |
GET /{index}/_stats |
获取索引统计信息 | GET /products/_stats |
GET /{index}/_shards |
获取分片状态 | GET /products/_shards |
GET /_cluster/health |
集群健康状态 | GET /_cluster/health |
GET /_cluster/health/{index} |
特定索引健康状态 | GET /_cluster/health/products |
GET /{index}/_recovery |
恢复进度 | GET /products/_recovery |
GET /{index}/_segments |
段信息 | GET /products/_segments |
GET /{index}/_field_usage_stats |
字段使用统计 | GET /products/_field_usage_stats |
修改索引
在 Elasticsearch 中,修改索引设置的 API 允许动态调整索引的配置参数(如副本数、刷新间隔等)
动态修改索引设置(运行时生效)
修改单个或多个设置
示例:
PUT /{index}/_settings
{
"settings": {
"setting_name_1": "value_1",
"setting_name_2": "value_2",
...
}
}修改副本数
# 请求
PUT /index_test01/_settings
{
"settings": {
"number_of_replicas": 2
}
}
# 预期返回
{
"acknowledged" : true
}
# 查看一下
GET /index_test01/_settings
{
"index_test01" : {
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"refresh_interval" : "1s",
"number_of_shards" : "3",
"provided_name" : "index_test01",
"creation_date" : "1750482108424",
"number_of_replicas" : "2",
"uuid" : "TRTmGpiNRuC1wZY49Wt_aA",
"version" : {
"created" : "7172699"
}
}
}
}
}支持动态修改的参数
| 设置名称 | 说明 | 示例值 |
|---|---|---|
| number_of_replicas | 副本数 | 2 |
| refresh_interval | 刷新间隔(控制新文档可见性) | 30s, -1(禁用自动刷新) |
| index.search.slowlog.threshold.query.warn | 查询慢日志阈值(警告级别) | 10s |
| index.max_result_window | 分页最大结果数(深度分页风险) | 100000 |
| index.blocks.write | 禁止写入(只读模式) | true |
| index.routing.allocation.exclude._name | 排除特定节点 | node1,node2 |
| index.priority | 恢复优先级 | 10 |
静态设置参数(需关闭索引后修改)
某些设置(如主分片数)必须在索引关闭后才能修改:
# 关闭索引
POST /{index}/_close
# 修改静态设置
PUT /{index}/_settings
{
"settings": {
"number_of_shards": 10 # 仅示例,生产环境谨慎修改
}
}删除索引(谨慎操作,可以使用关闭索引替代)
在 Elasticsearch 中,删除索引是一个不可逆操作,会永久移除索引及其所有数据
删除单个索引
api:DELETE /{index}
示例:
# 请求
DELETE /index_test01
# 预期返回
{
"acknowledged" : true
}
# 验证索引是否存在
HEAD /index_test01
# 预期返回,404表示已经删除
{"statusCode":404,"error":"Not Found","message":"404 - Not Found"}删除多个索引
使用逗号分隔多个索引名,或通配符匹配:
示例:
DELETE /{index1},{index2},...
# 通配符,删除所有以logs-开头的索引
DELETE /logs-*删除所有索引(谨慎操作)
警告:此操作会删除集群中所有索引,生产环境中禁用!
安全措施:部分集群配置了action.destructive_requires_name为true,禁止通过通配符删除所有索引。
DELETE /_all
DELETE /*索引的其它操作
- 关闭索引:
POST /{index}/_close,关闭索引,使其不能进行读写操作,以节省资源。 - 打开索引:
POST /{index}/_open,打开已关闭的索引,恢复其读写功能。 - 收缩索引:
POST /{index}/_shrink/{target_index},将索引收缩为指定的目标索引,可减少分片数量。 - 拆分索引:
POST /{index}/_split/{target_index},将索引拆分为多个新的索引。 - 克隆索引:
POST /{index}/_clone/{target_index},克隆一个现有的索引到新的索引。 - 索引滚动:
POST /{alias}/_rollover,用于将数据从一个索引滚动到另一个索引,常用于按时间滚动的索引场景。 - 冻结索引:
POST /{index}/_freeze,冻结索引,使其数据不可变,以节省内存和提高查询性能。 - 解冻索引:
POST /{index}/_unfreeze,解冻已冻结的索引,恢复其可写状态。 - 解析索引:
GET /_resolve_index/{index},解析索引的名称,返回其真实的索引名称和相关信息。 - 检查索引是否存在:
HEAD /{index},通过请求的响应状态码判断索引是否存在,200 表示存在,404 表示不存在。