本章侧重于Microsoft MASM汇编程序的基本组成部分。读者将会了解到如何定义常数和变量,数字和字符常量的标准格式,以及怎样汇编并运行你的第一个程序。本章特别强调了Visual Studio 调试器,它是理解程序如何工作的优秀工具。本章最重要的是,一次前进一步,在进入到下一步之前,要掌握每一个细节。夯实基础对后续章节来说是非常有帮助的。
3.1 基本语言元素
3.1.1第一个汇编语言程
序汇编语言以隐晦难懂而著名,但是本书从另一个角度来看它--它是一种几乎提供了全部信息的语言。程序员可以看到正在发生的所有事情,甚至包括CPU中的寄存器和标志!但是,在拥有这种能力的同时,程序员必须负责处理数据表示的细节和指令的格式。程序员工作在一个具有大量详细信息的层次。现在以一个简单的汇编语言程序为例,来了解其工作过程。程序执行两个数相加,并将结果保存在寄存器中。程序名称为AddTwo:
main PROC
mov eax,5 :将数字5送入eax寄存器
add eax,6 ;eax寄存器加6
INVOKE ExitProcess, 0 ;程序结束
main ENDP虽然在每行代码前插入行号有助于讨论,但是在编写汇编程序时,并不需要实际键入行号。此外,目前还不要试图输入并运行这个程序,因为它还缺少一些重要的声明,本章稍后将介绍相关内容。
现在按照一次一行代码的方法来仔细查看这段程序:第 1 行开始main 程序(主程序),即程序的人口;第 2 行将数字 5 送人 eax 寄存器;第 3 行把 6 加到 EAX 的值上,得到新值11;第 5 行调用 Windows 服务(也被称为函数)ExitProcess 停止程序,并将控制权交还给操作系统;第6行是主程序结束的标记。
读者可能已经注意到了程序中包含的注释,它总是用分号开头。程序的顶部省略了一些声明,稍后会予以说明,不过从本质上说,这是一个可以用的程序。它不会将全部信息显示在屏幕上,但是借助工具程序调试器的运行,程序员可以按一次一行代码的方式执行程序,并查看寄存器的值。本章的后面将展示如何实现这个过程。
添加一个变量
现在让这个程序变得有趣些,将加法运算的结果保存在变量sum中。要实现这一点,需要增加一些标记,或声明,用来标识程序的代码和数据区:
.data ;此为数据区
sum DWORD 0 ;定义名为sum的变量
.code ;此为代码区
main PROC
mov eax, 5 ;将数字5送入eax寄存器
add eax, 6 ;eax寄存器加6
mov sum, eax
INVOKE ExitProcess, 0 ;程序结束
main ENDP变量sum 在第2行进行了声明,其大小为 32 位,使用了关键字DWORD。汇编语言中有很多这样的大小关键字,其作用或多或少与数据类型一样。但是与程序员可能熟悉的类型相比它们没有那么具体,比如 int、double、float 等等。这些关键字只限制大小,并不检查变量中存放的内容。记住,程序员拥有完全控制权。
顺便说一下,那些被 .code 和.data 伪指令标记的代码和数据区,被称为段。即,程序有代码段和数据段。在本章后面的内容中,还要命名第三种段:堆栈(stack)。
接下来,将更深人地研究汇编语言的细节,展示如何声明常量(又称常数)、标识符、伪指令和指令。读者可能需要反复阅读本章来记住这些内容,但是这个时间绝对花得值得。另外,本章中每次提到汇编器使用的语法规则时,实际是指Microsoft MASM汇编器使用的语法规则。虽然其他汇编器使用的语法规则不同,但是,本章将忽略它们。每次提到汇编器时不再重复印刷MASM这个词,可能至少能节约下(世界上某个地方的)一棵树。
3.1.2整数常量
整数常量(integer literal)(又称为整型常量(integer constant))由一个可选前置符号、一个或多个数字,以及一个指明其基数的可选基数字符构成:
(+\|-)\] digits \[ radix
本书使用 Microsoft语法符号。方括号内的元素是可选的;大括号内的元素用|符号分隔,且必须要选择其中一个元素;斜体字标识的是有明确定义或说明的元素
由此,比如26就是一个有效的整数常量。它没有基数,所以假设其是十进制形式。果想要表示十六进制数 26,就将其写为26h。同样,数字1101可以被看做是十进制值,除非在其末尾添加"b",使其成为1101b(二进制)。下表列出了可能的基数值:
|-----|------|---|---------|
| h | 十六进制 | r | 编码实数 |
| q/o | 八进制 | t | 十进制(备用) |
| d | 十进制 | y | 二进制(备用) |
| b | 二进制 | | |
下面这些整数常量声明了各种基数。每行都有注释:
26 ;十进制
26d ;十进制
11010011b ;二进制
42q ;八进制
42o ;八进制
1Ah ;十六进制
0A3h ;十六进制
以字母开头的十六进制数必须加个前置0,以防汇编器将其解释为标识符
3.1.3整型常量表达式
整型常量表达式(constantintegerexpression)是一种算术表达式,它包含了整数常量和算术运算符。每个表达式的计算结果必须是一个整数,并可用32位(从0到FFFFFFFFh)来存放。表3-1列出了算术运算符,并按照从高(1)到低(4)的顺序给出了它们的优先级。对整型常量表达式而言很重要的是,要意识到它们只在汇编时计算。从现在开始,本书将它们简称为整数表达式。

运算符优先级(operator precedence)是指,当一个表达式包含两个或多个运算符时,这些操作的执行顺序,下面是一些表达式和它们的执行顺序:
4+5*2 ;乘法,加法
12 -1 MOD 5 ;取模,减法
-5 +2 ;一元减法,加法
(4+2)* 6 ;加法,乘法
下面给出了一些有效表达式和它们的值:
|---------------|-----|
| 表达式 | 值 |
| 16/5 | 3 |
| -(3+4)*(6-1) | -35 |
| -3+4*6-1 | 20 |
| 25 mod 3 | 1 |
建议:在表达式中使用圆括号来表明操作顺序,那么就不用去死记运算符优先级。
3.1.4 实数常量
实数常量(real number literal)(又称为浮点数常量(floating-point literal))用于表示十进制实数和编码(十六进制)实数。十进制实数包含一个可选符号,其后跟随一个整数,一个十进制小数点,一个可选的表示小数部分的整数,和一个可选的指数;
sign\]integer.\[integer\]\[exponent
符号和指数的格式如下:
sign +,-
exponent E{+,-}integer
下面是一些有效的十进制实数:
+3.0
-44.2E+05
26.E5
至少需要一个数字和一个十进制小数点。
编码实数(encodedreal)表示的是十六进制实数,用IEEE浮点数格式表示短实数(参见第 12 章)。比如,十进制数+1.0 用二进制表示为:
0011 1111 1000 0000 0000 0000 0000 0000
在汇编语言中,同样的值可以编码为短实数:
3F800000r
实数常量暂时还不会用到,因为大多数 x86 指令集是专门针对整数处理的。不过,第12 章将会说明怎样用实数,又称为浮点数,进行算术运算。这是非常有趣,又非常有技术性的。
3.1.5 字符常量
字符常量(character literal)是指,用单引号或双引号包含的一个字符。汇编器在内存中保存的是该字符二进制ASCII 码的数值。例如:
'A'
"d"
回想第 1章表明字符常量在内部保存为整数,使用的是 ASCII 编码序列。因此,当编写字符常量"A"时,它在内存中存放的形式为数字65(或41h)。本书封底内页有完整的ASCII 码表,读者需要经常查阅此表。
3.1.6 字符串常量
字符串常量(stringliteral)是用单引号或双引号包含的一个字符(含空格符)序列:
'ABC'
'X'
"Good night, Gracie"
'4096'
嵌套引号也是被允许的,使用方法如下例所示:
"This isn't a test"
'Say "Good night," Gracie'
和字符常量以整数形式存放一样,字符串常量在内存中的保存形式为整数字节数值序列。例如,字符串常量"ABCD"就包含四个字节41h、42h、43h、44h。
3.1.7 保留字
保留字(reservedwords)有特殊意义并且只能在其正确的上下文中使用。默认情况下,保留字是没有大小写之分的。比如,MOV与mov、Mov 是相同的。保留字有不同的类型:
●指令助记符,如MOV、ADD和MUL。
●寄存器名称。
●伪指令,告诉汇编器如何汇编程序。
●属性,提供变量和操作数的大小与使用信息。例如 BYTE 和WORD。
●运算符,在常量表达式中使用。
●预定义符号,比如 @data,它在汇编时返回常量的整数值。附录A是常用的保留字列表。
3.1.8 标识符
标识符(identifier)是由程序员选择的名称,它用于标识变量、常数、子程序和代码标签。标识符的形成有一些规则:
●可以包含1到247 个字符。
●不区分大小写。
●第一个字符必须为字母(A...Z, a...z)、下弄线(_)、@、?或$。其后的字符也可以是数字。
●标识符不能与汇编器保留字相同。
提示 可以在运行汇编器时,添加-Cp命令行切换项来使得所有关键字和标识符变成大小写敏感。
通常,在高级编程语言代码中,标识符使用描述性名称是一个好主意。尽管汇编语言指令短且隐晦,但没有理由使得标识符也要变得难以理解!下面是一些命名良好的名称:
lineCount firstValue index line_count
myFile xCoord main x_Coord
下面的名称合法,但是不可取;
_lineCount $first @myFile
一般情况下,应避免用符号@和下划线作为第一个字符,因为它们既用于汇编器,也用于高级语言编译器。
3.1.9 伪指令
伪指令(directive)是嵌入源代码中的命令,由汇编器识别和执行。伪指令不在运行时执行,但是它们可以定义变量、宏和子程序;为内存段分配名称,执行许多其他与汇编器相关的日常任务。默认情况下,伪指令不区分大小写。例如,.data,.DATA 和Data 是相同的。下面的例子有助于说明伪指令和指令的区别。DWORD伪指令告诉汇编器在程序中为一一个双字变量保留空间。另一方面,MOV指令在运行时执行,将myVar 的内容复制到 EAX寄存器中:
myVar DWORD 26
mov eax,myVar
尽管 Intel 处理器所有的汇编器使用相同的指令集,但是通常它们有着不同的伪指令。比如,Microsoft 汇编器的REPT 伪指令对其他一些汇编器就是无法识别的。
定义段汇编器伪指令的一个重要功能是定义程序区段,也称为段(segment)。程序中的段具有不同的作用。如下面的例子,一个段可以用于定义变量,并用.DATA 伪指令进行标识:
.data
.CODE伪指令标识的程序区段包含了可执行的指令:
.code
.STACK 伪指令标识的程序区段定义了运行时堆栈,并设置了其大小:
.stack 100h附录A给出了伪指令和运算符,是一个有用的参考。
3.1.10 指令
指令(instruction)是一种语句,它在程序汇编编译时变得可执行。汇编器将指令翻译为机器语言字节,并且在运行时由 CPU加载和执行。一条指令有四个组成部分:
●标号(可选)
●指令助记符(必需)
●操作数(通常是必需的)
●注释(可选)
不同部分的位置安排如下所示:
label:\] mnemonic \[operands\]\[comment
现在分别了解每个部分,先从标号字段开始。
1.标号
标号(label)是一种标识符,是指令和数据的位置标记。标号位于指令的前端,表示指令的地址。同样,标号也位于变量的前端,表示变量的地址。标号有两种类型:数据标号和代码标号。
数据标号标识变量的位置,它提供了一种方便的手段在代码中引用该变量。比如,下面定义了一个名为count 的变量:
count DWORD 100
汇编器为每个标号分配一个数字地址。可以在一个标号后面定义多个数据项。在下面的例子中,array定义了第一个数字(1024)的位置,其他数字在内存中的位置紧随其后:
array DWORD 1024, 2048
DWORD 4096, 8192变量将在3.4.2 节中解释,MOV 指令将在 4.1.4 节中解释。
程序代码区(指令所在区段)的标号必须用冒号(:)结束。代码标号用作跳转和循环指令的目标。例如,下面的JMP 指令创建一个循环,将程序控制传递给标号 target 标识的位置:
target:
mov ax,bx
...
jmp target代码标号可以与指令在同一行上,也可以自己独立一行:
L1: mov ax,bx
L2:标号命名规则与3.1.8节中说明的标识符命名规则一样。只要每个标号在其封闭子程序中是唯一的,那么就可以多次使用相同的标号。子程序将在第 5 章中讨论。
2.指令助记符
指令助记符(instruction mnemonic)是标记一条指令的短单词。在英语中,助记符是帮助记忆的方法。相似地,汇编语言指令助记符,如mov,add和sub,给出了指令执行操作类型的线索。下面是一些指令助记符的例子:
|-----|---------------|------|----------|
| 助记符 | 说明 | 助记符 | 说明 |
| MOV | 传送(分配)数值 | MUL | 两个数值相乘 |
| ADD | 两个数值相加 | JMP | 跳转到一个新位置 |
| SUB | 从一个数值中减去另一个数值 | CALL | 调用一个子程序 |
3.操作数
操作数是指令输入输出的数值。汇编语言指令操作数的个数范围是0~3个,每个操作数可以是寄存器、内存操作数、整数表达式和输人输出端口。寄存器命名在第2章讨论过整数表达式在3.1.2节讨论过。生成内存操作数有不同的方法--比如,使用变量名、带方括号的寄存器,详细内容将稍后讨论。变量名暗示了变量地址,并指示计算机使用给定地址的内存内容。下表列出了一些操作数示例:
|-----|-------|-------|-------|
| 示例 | 操作数类型 | 示例 | 操作数类型 |
| 96 | 整数常量 | eax | 寄存器 |
| 2+4 | 整数表达式 | Count | 内存 |
现在来考虑一些包含不同个数操作数的汇编语言指令示例。比如,STC指令没有操作数:
stc ;进位标志位置 1
INC指令有一个操作数:
inc eax ;EAX 加 1
MOV 指令有两个操作数:
mov count, ebx ;将EBX传送给变量count
操作数有固有顺序。当指令有多个操作数时,通常第一个操作数被称为目的操作数,第二个操作数被称为源操作数(source operand)。一般情况下,目的操作数的内容由指令修改。比如,在 MOV 指令中,数据就是从源操作数复制到目的操作数。
IMUL指令有三个操作数,第一个是目的操作数,第二个和第三个是进行乘法的源操作数:
imul eax, ebx, 5
在上例中,EBX 与5 相乘,结果存放在 EAX 寄存器中。
4.注释
注释是程序编写者与阅读者交流程序设计信息的重要途径。程序清单的开始部分通常包含如下信息:
●程序目标的说明
●程序创建者或修改者的名单
●程序创建和修改的日期
●程序实现技术的说明
注释有两种指定方法:
●单行注释,用分号(;)开始。汇编器将忽略在同一行上分号之后的所有字符。
●块注释,用 COMMENT伪指令和一个用户定义的符号开始。汇编器将忽略其后所有的文本行,直到相同的用户定义符号出现为止。示例如下:
COMMENT !
This line is a comment.
This line is also a comment.
!其他符号也可以使用,只要该符号不出现在注释行中:
COMMENT &
This line is a comment.
This line is also a comment.
&当然,程序员应该在整个程序中提供注释,尤其是代码意图不太明显的地方。
5.NOP(空操作)指令
最安全(也是最无用)的指令是NOP(空操作)。它在程序空间中占有一个字节,但是不做任何操作。它有时被编译器和汇编器用于将代码对齐到有效的地址边界。在下面的例子中,第一条指令MOV生成了3字节的机器代码。NOP指令就把第三条指令的地址对齐到双字边界(4 的偶数倍):
00000000 66 8B C3 mov ax,bx
00000003 90 nop ;对齐下条指令
00000004 8B D1 mov edx,ecx
x86 处理器被设计为从双字的偶数倍地址处加载代码和数据,这使得加载速度更快。
3.1.11 本节回顾
1.使用数值 -35,按照 MASM 语法,写出该数值的十进制、十六进制、八进制和二进制格式的整数常量。
答:-35d,负数取补码
十六进制:ddh, 八进制:335为, 二进制:11011101b。
2.(是/否):A5h是一个有效的十六进制常量吗?
答:否。0A5h才是有效的。
3.(是/否):整数表达式中,乘法运算符(*)是否比除法运算符(/)具有更高优先级?
答:否,两者是同级的。
4.编写一个整数表达式,要求用到3.1.2 节中的所有运算符。计算该表达式的值。
表达式:30 mod (3*4) +(3-1)/2 = 20
5.按照 MASM 语法,写出实数-6.2x10的实数常量。
答:-6.2E+04。
6.(是/否):字符串常量必须被包含在单引号中吗?
答:否,它们也可以被包含在双引号中。
7.保留字可以用作指令助记符、属性、运算符、预定义符号,和++伪指令++。
8.标识符的最大长度是多少?
答:247个字符。
3.2 示例:整数加减法
3.2.1 AddTwo程序
现在再查看一下本章开始给出的 AddTwo 程序,并添加必要的声明使其成为完全能运行的程序。请记住,行号不是程序的实际组成部分:
; AddTwo.asm - 两个32位整数相加
; 第3章示例
.386
.model flat, stdcall
.stack 4096
ExitProcess PROTO, dwExitCode:DWORD
.code
main PROC
mov eax, 5 ;数字5送入eax寄存器
add eax, 6 ;eax寄存器加6
INVOKE ExitProcess, 0
main ENDP
END main第 4 行是.386 伪指令,它表示这是一个32 位程序,能访问32 位寄存器和地址。第 5行选择了程序的内存模式(flat),并确定了子程序的调用规范(称为stdcall)。其原因是32位Windows服务要求使用stdcall规范。(第8章解释了stdcall是如何工作的。)第6行为运行时堆栈保留了 4096 字节的存储空间,每个程序都必须有。
第7 行声明了ExitProcess 函数的原型,它是一个标准的Windows服务。原型包含了函数名、PROTO 关键字、一个逗号,以及一个输入参数列表。ExitProcess的输入参数名称为dwExitCode。可以将其看作为给Windows 操作系统的返回值,返回值为零,则表示程序执行成功;而任何其他的整数值都表示了一个错误代码。因此,程序员可以将自己的汇编程序看作是被操作系统调用的子程序或过程。当程序准备结束时,它就调用 ExitProcess,并向操作系统返回一个整数以表示该程序运行良好。
更多信息: 读者可能会好奇,为什么操作系统想要知道程序是否成功完成。理由如下:与按序执行一些程序相比,系统管理员常常会创建脚本文件。在脚本文件中的每一个点上,系统管理员都需要知道刚执行的程序是否失败,这样就可以在必要时退出该脚本。脚本通常如下例所示,其中,ErrorLevell表示前一步的过程返回码大于或等于1:
call program_1
if ErrorLevel 1 goto FailedLabel
call program 2
if ErrorLevel 1 goto FailedLabel
:SuccessLabel
Echo Great,everything worked!
现在回到AddTwo程序清单。第16行用end伪指令来标记汇编的最后一行,同时它也标识了程序的人口(main)。标号main在第10行进行了声明,它标记了程序开始执行的地址。
提示 在显示汇编程序代码时,Visual Studio的语法高亮显示和关键字下的波浪线并不一致。通过如下步骤可以禁用它:从Tool菜单选择Options,继续选择 Text Editor选择 C/C++,选择Advanced,在Intellisense标题下,将Disable Squiggles 设置为 True。点击 OK关闭 Options 窗口。同样,记住 MASM 大小写不敏感,因此,程序员可以随意进行大小写组合。
汇编伪指令回顾
现在回顾一些在示例程序中使用过的最重要的汇编伪指令。
首先是.MODEL 伪指令,它告诉汇编程序用的是哪一种存储模式:
.model flat, stdcall
32 位程序总是使用平面(flat)存储模式,它与处理器的保护模式相关联。保护模式在第2章中已经讨论过了。关键字stdcall 在调用程序时告诉汇编器,怎样管理运行时堆栈。这是个复杂的问题,将在第 8 章中进行探讨。然后是 .STACK 伪指令,它告诉汇编器应该为程序运行时堆栈保留多少内存字节:
.stack 4096
数值 4096 可能比将要用的字节数多,但是对处理器的内存管理而言,它正好对应了一个内存页的大小。所有的现代程序在调用子程序时都会用到堆栈--首先,用来保存传递的参数;其次,用来保存调用函数的代码的地址。函数调用结束后,CPU 利用这个地址返回到函数被调用的程序点。此外,运行时堆栈还可以保存局部变量,也就是,在函数内定义的变量。
.CODE 伪指令标记一个程序代码区的起点,代码区包含了可执行指令。通常,.CODE的下一行声明程序的人口,按照惯例,一般会是一个名为main 的过程。程序的人口是指程序要执行的第一条指令的位置。用下面两行来传递这个信息:
.code
main PROC
ENDP 伪指令标记一个过程的结束。如果程序有名为 main 的过程,则 endp 就必须使用同样的名称:
main ENDP
最后,END 伪指令标记一个程序的结束,并要引用程序入口:
END main
如果在END伪指令后面还有更多代码行,它们都会被汇编程序忽略。程序员可以在这里放各种内容--程序注释,代码副本等等,都无关紧要。
3.2.2运行和调试AddTwo程序
使用 Visual Studio 可以很方便地编辑、构建和运行汇编语言程序。本书示例文件目录中的Project32文件夹包含了Visual Studio 2012Windows控制台项目,该文件夹已经按照 32位汇编语言编程进行了配置。(另一个Project64文件夹按照64位汇编进行了配置。)下面的步骤,按照Visual Studio 2012,说明了怎样打开示例项目,并创建AddTwo程序:
1)打开 Project32 文件夹,双击Project.sln文件。启动计算机上安装的最新版本的Visual Studio。
2)打开 Visual Studio 中Solution Explorer 窗口。它应该已经是可见的,但是程序员也可以在View 菜单中选择 Solution Explorer 使其可见。
3)在 Solution Explorer 窗口右键点击项目名称,在文本菜单中选择 Add,再在弹出菜单中选择 New Item。
4)在AddNewFile对话窗口中(见图3-1),将文件命名为AddTwo.asm,填写Location项为该文件选择一个合适的磁盘文件夹,
5)单击Add 按钮保存文件
6)键人程序源代码,如下所示。这里大写关键字不是必需的:

图3-1向Visual Studio项目添加一个新的源代码文件
7)在 Project 菜单中选择 Build Project,查看Visual Studio 工作区底部的错误消息。这被称为错误列表窗口。图 3-2 展示了打开并运行了示例程序的结果。注意,当没有错误时,窗口底部的状态栏会显示 "成功" (Build succeeded)。

图3-2 构建 Visual Studio 项目
1.调试演示
下面将展示 AddTwo 程序的一个示例调试会话。本书还未向读者展示直接在控制台窗口显示变量值,因此,我们将在调试会话中运行程序。演示使用的是 Visual Studio 2022,不过,自 2008 年起的任何版本的 Visual Studio 都可以使用。
运行调试程序的一个方法是在Debug菜单中选择StepOver。按照 Visual Studio 的配置F10功能键或Shift+F8组合键将执行StepOver命令。
开始调试会话的另一种方法是在程序语句上设置断点,方法是在代码窗口左侧灰色垂直条中直接单击。断点处由一个红色大圆点标识出来。然后就可以从Debug菜单中选择StartDebugging 开始运行程序。
提示如果试图在非执行代码行设置断点,那么在运行程序时,Visual Studio 会直接将断点前移到下一条可执行代码行。
图 3-3显示了调试会话开始时的程序。第11行,第一条MOV指令,设置了一个断点调试器已经暂停在该行,而该行还未执行。当调试器被激活时,Visual Studio窗口底部的状态栏变为橙色。当调试器停止并返回编辑模式时,状态栏变为蓝色。可视提示是有用的,因为在调试器运行时,程序员无法对程序进行编辑或保存。

图3-4显示的调试程序已经单步执行了11 行和 12 行,正暂停在 14行。将鼠标悬停在EAX 寄存器名称上,就可以查看其当前的内容(11)。结束程序运行的方法是在工具栏上单击 Continue按钮,或者是单击(工具栏右侧的)红色的 Stop Debugging按钮。
2.自定义调试接口
在调试时可以自定义调试接口。例如,如果想要显示CPU寄存器,实现方法是,在Debug菜单中选择 Windows,然后再选择Registers。图3-5显示了与刚才相同的调试会话其中Registers窗口可见,同时还关闭了一些不重要的窗口。EAX数值显示为0000000B,是十进制数 11 的十六进制表示。图中已经绘制了箭头指向该值。Registers 窗口中,EFL 寄存器包含了所有的状态标志位(零标志、进位标志、溢出标志等)。如果在 Registers 窗口中右键单击,并在弹出菜单中选择 Flags,则窗口将显示单个的标志位值。示例如图3-6 所示,标志位从左到右依次为:OV(溢出标志位)、UP(方向标志位)、EI(中断标志位)、PL(符号标志位)、ZR(零标志位)、AC(辅助进位标志位)PE(奇偶标志位)和 CY(进位标志位)。这些标志位准确的含义将在第4章进行说明。

图3-4调试器执行了11 行和 12 行之后

图3-5在调试会话中添加Registers窗口

图3-6 在Registers窗口中显示CPU状态标志
Registers 窗口的一个重要特点是,在单步执行程序时,任何寄存器,只要当前指令修改了它的数值,就会变为红色。尽管无法在打印页面(它只有黑白两色)上表示出来,这种红色高亮确实显示给程序员,使之了解其程序是怎样影响寄存器的。
提示 本书网站(asmirivine.com)有教程展示如何汇编和调试汇编语言程序。
在 Visual Studio中运行一个汇编语言程序时,它是在控制台窗口中启动的。这个窗口与从 Windows 的 Start菜单运行名为cmd.exe程序的窗口是相同的。或者,还可以打开项目Debug\Bin 文件夹中的命令提示符,直接从命令行运行应用程序。如果采用的是这个方法程序员就只能看见程序的输出,其中包括了写入控制台窗口的文本。查找具有相同名称的可执行文件作为 Visual Studio 项目。
;程序模板 (Template.asm)
.386
.model flat,stdcall
.stack 4096
ExitProcess PROTO, dwExitCode:DWORD
.data
;在这里声明变量
.code
main PROC
;在这里编写自己的代码
INVOKE ExitProcess,0
main ENDP
END main使用注释 在注释中包括程序说明、程序作者的名字、创建日期,以及后续修改信息,是一个非常好的主意。这种文档对任何阅读程序清单的人(包括程序员自己,几个月或几年之后)都是有帮助的。许多程序员已经发现了,程序编写几年后,他们必须先重新熟悉自己的代码才能进行修改。如果读者正在上编程课,那么老师可能会坚持要求使用这些附加信息。
3.2.4 本节回顾
1.在AddTwo程序中,ENDP伪指令的含义是什么?
答:ENDP伪指令标识了过程的结束。
2.在AddTwo程序中,.CODE伪指令标识了什么?
答:.code伪指令标识了代码段的开始。
3.AddTwo程序中两个段的名称是什么?
答:.code和.stack。
4.在AddTwo程序中,哪个寄存器保存了和数?
答:EAX。
5.在 AddTwo 程序中,哪条语句使程序停止?
答:INVOKE ExitProcess, 0。
3.3 汇编、链接和运行程序
用汇编语言编写的源程序不能直接在其目标计算机上执行,必须通过翻译或汇编将其转换为可执行代码。实际上,汇编器与编译器(compiler)很相似,编译器是一类程序,用于将C++或Java程序翻译为可执行代码。
汇编器生成包含机器语言的文件,称为目标文件(object file)。这个文件还没有准备好执行,它还需传递给一个被称为链接器(linker)的程序,从而生成可执行文件(executablefile)。这个文件就准备好在操作系统命令提示符下执行。
3.3.1汇编-链接-执行周期
图 3-7总结了编辑、汇编、链接和执行汇编语言程序的过程。下面详细说明每一个步骤。
步骤1:编程者用文本编辑器(texteditor)创建一个ASCII文本文件,称之为源文件。
步骤 2:汇编器读取源文件,并生成目标文件,即对程序的机器语言翻译。或者,它也会生成列表文件。只要出现任何错误,编程者就必须返回步骤 1,修改程序。
步骤 3:链接器读取并检查目标文件,以便发现该程序是否包含了任何对链接库中过程的调用。链接器从链接库中复制任何被请求的过程,将它们与目标文件组合,以生成可执行文件。
步骤4:操作系统加载程序将可执行文件读人内存,并使 CPU 分支到该程序起始地址,然后程序开始执行。
参见本书作者网站(www.asmirvine.com)的"Getting Started"标题,获取MicrosoftVisual Studio 对汇编语言程序进行汇编、链接和运行的详细指令。

3.3.2 列表文件
列表文件(listingfile)包括了程序源文件的副本,再加上行号、每条指令的数字地址、每条指令的机器代码字节(十六进制)以及符号表。符号表中包含了程序中所有标识符的名称、段和相关信息。高级程序员有时会利用列表文件来获得程序的详细信息。图3-8展示了AddTwo 程序的部分列表文件,现在进一步查看这个文件。1~7行没有可执行代码,因此它们原封不动地从源文件中直接复制过来。第9行表示代码段开始的地址为0000 0000(在32 位程序中,地址显示为8个十六进制数字)。这个地址是相对于程序内存占用起点而言的,但是,当程序加载到内存中时,这个地址就会转换为绝对内存地址。此时,该程序就会从这个地址开始,比如 0004 0000h。
; AddTwo.asm - adds two 32-bit integer
; Chapter 3 example
.386
.model flat, stdcall
ExitProcess PROTO, dwExitCode:DWORD
00000000 .code
00000000 main PROC
00000000 B8 00000005 mov eax, 5
00000005 83 C0 06 add eax, 6
INVOKE ExitProcess, 0
00000008 6A 00 push +00000000h
0000000A E8 00000000 E call ExitProcess
0000000F main ENDP
END main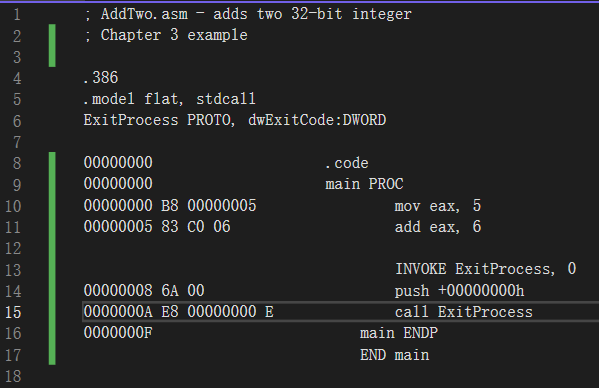
图3-8 AddTwo源列表文件摘录
第 10 行和第 11 行也显示了相同的开始地址 0000 0000,原因是:第一条可执行语句是MOV 指令,它在第 11 行。请注意第 11 行中,在地址和源代码之间出现了几个十六进制字节,这些字节(B8 0000 0005)代表的是机器代码指令(B8),而该指令分配给EAX的就是32位常数值(0000 0005)
11: 00000000 B8 0000 0005 mov eax5
数值 B8也被称为操作代码(或简称为操作码),因为它表示了特定的机器指令,将一个32 位整数送入 eax 寄存器。第 12 章将非常详细地介绍x86 机器指令架构。
第 12 行也是一条可执行指令,起始偏移量为 0000 0005。这个偏移量是指从程序起始地址开始5个字节的距离。也许,读者能猜出来这个偏移量是怎么算出来的。
第14行有invoke伪指令。注意第15行和16行是如何插人到这段代码中的,插人代码的原因是,INVOKE伪指今使得汇编器生成PUSH和CALL语句,它们就显示在第15行和16 行。第 5 章将讨论如何使用 PUSH 和 CALL。
图3-8中展示的示例列表文件说明了机器指令是怎样以整数值序列的形式加载到内存的,在这里用十六进制表示:B8、00000005、83、C0、06、6A、00、EB、00000000。每个数中包含的数字个数暗示了位的个数:2个数字就是8位,4个数字就是16位,8个数字就是 32位以此类推。所以,本例机器指令长正好是15个字节(2个4字节值和7个1字节值)。
当程序员想要确认汇编器是否按照自己的程序生成了正确的机器代码字节时,列表文件就是最好的资源。如果是刚开始学习机器代码指令是如何生成的,列表文件也是一个很好的教学工具。
提示 若想告诉 Visual Studio 生成列表文件,则在打开项目时按下述步骤操作:在Project菜单中选择Properties,在ConfigurationProperties下,选择Microsoft MacroAssembler。然后选择ListingFile。在对话框中,设置Generate Preprocessed SourceListing为Yes,设置ListAllAvailable Information为Yes。对话框如图 3-9 所示。

图3-9配置Visual Studio 以生成列表文件
列表文件的其他部分包含了结构和联合列表,以及过程、参数和局部变量。这里没有显示这些内容,但是后续章节将对它们进行讨论。
3.3.3 本节回顾
1.汇编器生成什么类型的文件?
答:目标(.OBJ)和列表(.LST)类型的文件。
2.(真/假):链接器从链接库中抽取已汇编程序,并将其插入到可执行程序中。
答:真
3.(真/假):程序源代码修改后,它必须再次进行汇编和链接才能按照修改内容执行。
答:真。
4.操作系统的哪一部分来读取和执行程序?
答:加载器
5.链接器生成什么类型的文件?
答:exe可执行类型的文件。
3.4定义数据
3.4.1 内部数据类型
汇编器识别一组基本的内部数据类型(intrinsic data type),按照数据大小(字节、字、双字等等)、是否有符号、是整数还是实数来描述其类型。这些类型有相当程度的重叠--例如,DWORD类型(32位,无符号整数)就可以和SDWORD类型(32位,有符号整数)相互交换。可能有人会说,程序员用 SDWORD 告诉读程序的人,这个值是有符号的,但是,对于汇编器来说这不是强制性的。汇编器只评估操作数的大小。因此,举例来说,程序员只能将32 位整数指定为 DWORD、SDWORD 或者REAL4 类型。表 3-2 给出了全部内部数据类型的列表,有些表项中的IEEE符号指的是IEEE计算机学会出版的标准实数格式。
3.4.2 数据定义语句
数据定义语句(data definition statement)在内存中为变量留出存储空间,并赋予一个可选的名字。数据定义语句根据内部数据类型(表3-2)定义变量。数据定义语法如下所示:
name directive initializer ,initializer...

下面是数据定义语句的一个例子:
count DWORD 12345
名字 分配给变量的可选名字必须遵守标识符规范(参见3.1.8节)。
伪指令 数据定义语句中的伪指令可以是BYTE、WORD、DWORD、SBTYE、SWORD,或其他在表 3-2 中列出的类型。此外,它还可以是传统数据定义伪指令,如表 3-3 所示。

初始值数据定义中至少要有一个初始值,即使该值为 0。其他初始值,如果有的话,用逗号分隔。对整数数据类型而言,初始值(initializer)是整数常量或是与变量类型,如BTYE或WORD相匹配的整数表达式。如果程序员希望不对变量进行初始化(随机分配数值),可以用符号?作为初始值。所有初始值,不论其格式,都由汇编器转换为二进制数据。初始值0011 0010b、32h 和50d 都具有相同的二进制数值。
3.4.3向AddTwo程序添加一个变量
本章开始时介绍了 AddTwo 程序,现在创建它的一个新版本,并称为AddTwoSum。这个版本引人了变量sum,它出现在完整的程序清单中:
;AddTwoSum.asm 第3章 示例
.386
.model flat, stdcall
.stack 4096
ExitProcess PROTO, dwExitCode:DWORD
.data
sum DWORD 0
.code
main PROC
mov eax, 5
add eax, 6
mov sum, eax
INVOKE ExitProcess, 0
main ENDP
END main可以在第 13 行设置断点,每次执行一行,在调试器中单步执行该程序。执行完第 15 行后,将鼠标悬停在变量sum 上,查看其值。或者打开一个 Watch 窗口,打开过程如下:在Debug菜单中选择Windows(在调试会话中),选择Watch,并在四个可用选项(Watch1,Watch2,Watch3或Watch4)中选择一个。然后,用鼠标高亮显示sum变量,将其拖拉到Watch 窗口中。图 3-10 展示了一个例子,其中用大箭头指出了执行第 15 行后,sum 的当前值。

图3-10在调试会话中使用Watch窗口
3.4.4定义BYTE和SBYTE数据
BYTE(定义字节)和SBYTE(定义有符号字节)为一个或多个无符号或有符号数值分配存储空间。每个初始值在存储时,都必须是8位的。例如:
value1 BYTE 'A' ;字符常量
value2 BYTE 0 ;最小无符号字节
value3 BYTE 255 ;最大无符号字节
value4 SBYTE -128 ;最小有符号字节
value5 SBYTE +127 ;最大有符号字节问号(?)初始值使得变量未初始化,这意味着在运行时分配数值到该变量:
value6 BYTE ?
可选名字是一个标号,标识从变量包含段的开始到该变量的偏移量。比如,如果 valuel在数据段偏移量为 0000 处,并在内存中占一个字节,则 value2 就自动处于偏移量为0001 处;
valuel BYTE 10h
value2 BYTE 20h
DB 伪指令也可以定义有符号或无符号的8位变量:
va11 DB 255 :无符号字节
va12 DB-128 ;有符号字节
1.多初始值
如果同一个数据定义中使用了多个初始值,那么它的标号只指出第一个初始值的偏移量。在下面的例子中,假设list的偏移量为0000。那么,数值10的偏移量就为0000,20的偏移量为0001,30的偏移量为0002,40的偏移量为0003:
list BYTE 10,20,30,40
图3-11给出了字节序列1ist,显示了每个字节及其偏移量。并不是所有的数据定义都要用标号。比如,在1ist后面继续添加字节数组,就可以在下一行定义它们:
list BYTE 10,20,30,40
BYTE 50,60,70,80
BYTE 81.82,83,84

在单个数据定义中,其初始值可以使用不同的基数。字符和字符串常量也可以自由组合。在下面的例子中,list1 和 list2 有相同的内容:
list1 BYTE 10, 32,41h, 00100010b
list2 BYTE 0Ah, 20h,'A', 22h
2.定义字符串
定义一个字符串,要用单引号或双引号将其括起来。最常见的字符串类型是用一个空字节(值为0)作为结束标记,称为以空字节结束的字符串,很多编程语言中都使用这种类型的字符串:
greetingl BYTE "Good afternoon",0
greeting2 BYTE 'Good night'.0
每个字符占一个字节的存储空间。对于字节数值必须用逗号分隔的规则而言,字符串是一个例外。如果没有这种例外,greeting1就会被定义为:
greetingl BYTE 'G','o',"o','d'....etc.
这就显得很冗长。一个字符串可以分为多行,并且不用为每一行都添加标号:
greetingl BYTE "Welcome to the Encryption Demo program"
BYTE "created by Kip Irvine.",0dh,0ah
BYTE "If you wish to modify this program, please "
BYTE "send me a copy." 0dh,0ah,0
十六进制代码 0Dh 和 0Ah 也被称为CR/LF(回车换行符)或行结束字符。在编写标准输出时,它们将光标移动到当前行的下一行的左侧。
行连续字符(1)把两个源代码行连接成一条语句,它必须是一行的最后一个字符。下面的语句是等价的:
greetingl BYTE "welcome to the Encryption Demo program"
和
greetingl \
BYTE "Welcome to the Encryption Demo program "
3.DUP 操作符
DUP 操作符使用一个整数表达式作为计数器,为多个数据项分配存储空间。在为字符串或数组分配存储空间时,这个操作符非常有用,它可以使用初始化或非初始化数据:
BYTE 20 DUP(0) ;20 个字节,值都为0
BYTE 20 DUP(?) 120 个字节,非初始化
BYTE 4 DUP(STACK") 120 个字节:
3.4.5 定义WORD和SWORD数据
WORD(定义字)和SWORD(定义有符号字)伪指令为一个或多个 16位整数分配存储空间:
word1 WORD 65535 ;最大无符号数
word2 SWORD -32768 ;最小有符号数
word3 WORD ? ;未初始化,无符号
也可以使用传统的DW伪指令:
val1 DW 65535 ;无符号
va12 DW-32768 ;有符号
16 位字数组 通过列举元素或使用DUP操作符来创建字数组。下面的数组包含了一组数值:
myList WORD 1,2,3,4,5
图3-12是一个数组在内存中的示意图,假设myList起始位置偏移量为0000。由于每个数值占两个字节,因此其地址递增量为2。DUP 操作符提供了一种方便的方法来声明数组:
array WORD 5 DUP(?) ;5个数值,未初始化

3.4.6 定义 DWORD 和 SDWORD 数据
DWORD(定义双字)和SDWORD(定义有符号双字)伪指令为一个或多个32位整数分配存储空间:
va11 DWORD 12345678h ;无符号
va12 SDWORD -2147483648 ;有符号
va13 DWORD 20 DUP(?) ;无符号数组
传统的DD 伪指令也可以用来定义双字数据:
va11 DD 12345678h ;无符号
va12 DD -2147483648 ;有符号
DWORD 还可以用于声明一种变量,这种变量包含的是另一个变量的 32 位偏移量。如下所示,pVal 包含的就是val3 的偏移量:
pVal DWORD val3
32 位双字数组 现在定义一个双字数组,并显式初始化它的每一个值:
myList DWORD 1, 2, 3, 4, 5
图3-13 给出了这个数组在内存中的示意图,假设myList起始位置偏移量为0000,偏移量增量为4。

3.4.7 定义 QWORD 数据
QWORD(定义四字)伪指令为64 位(8 字节)数值分配存储空间:
quad1QWORD 1234567812345678h
传统的DQ 伪指令也可以用来定义四字数据:
quad1 DQ 1234567812345678h
3.4.8定义压缩BCD(TBYTE)数据
Intel把一个压缩的二进制编码的十进制(BCD,Binary Coded Decimal)整数存放在一个10字节的包中。每个字节(除了最高字节之外)包含两个十进制数字。在低9个存储字节中,每半个字节都存放了一个十进制数字。最高字节中,最高位表示该数的符号位。如果最高字节为80h,该数就是负数;如果最高字节为 00h,该数就是正数。整数的范围是-999 999 999 999 999 999到+999 999 999 999 999999。
示例 下表列出了正、负十进制数 1234 的十六进制存储字节,排列顺序从最低有效字节到最高有效字节:
|-------|-------------------------------|
| 十进制数值 | 存储字节 |
| +1234 | 34 12 00 00 00 00 00 00 00 00 |
| -1234 | 34 12 00 00 00 00 00 00 00 80 |
MASM使用TBYTE伪指令来定义压缩BCD变量。因为,汇编器不会自动将十进制初始值转换为BCD码。下面的两个例子展示了十进制数-1234有效和无效的表达方式:
intVal TBYTE 800000000000001234h ;有效
intVal TBYTE-1234 :无效
第二个例子无效的原因是 MASM 将常数编码为二进制整数,而不是压缩 BCD 整数。
如果想要把一个实数编码为压缩BCD码,可以先用FLD指令将该实数加载到浮点寄存器堆栈,再用FBSTP指令将其转换为压缩BCD码,该指令会把数值舍人到最接近的整数:
.data
posVal REAL8 1.5
bcdVal TBYTE ?
.code
fld posVal ;加载到浮点堆栈
fbstp bcdVal ;向上舍入到2,压缩BCD码值如果 posVal 等于1.5,结果BCD 值就是2。第 7 章将学习怎样用压缩 BCD 值进行算术运算。
3.4.9 定义浮点类型
REAL4定义4字节单精度浮点变量。REAL8定义8字节双精度数值,REAL10定义10字节扩展精度数值。每个伪指令都需要一个或多个实常数初始值:
rVal1 REAL4 -1.2
rVal2 REAL8 3.2E-260
rVal3 REAL10 4.6E+4096
ShortArraY REAL4 20 DUP(0.0)
表 3-4描述了标准实类型的最少有效数字个数和近似范围:

DD、DO和 DT伪指令也可以定义实数:
rVal1 DD -1.2 ;短实数
rVal2 DQ 3.2E-260 ;长实数
rVa13 DT 4.6E+4096 ;扩展精度实数
说明: MASM汇编器包含了诸如real4和real8的数据类型,这些类型表明数值是实数。更准确地说,这些数值是浮点数,其精度和范围都是有限的。从数学的角度来看实数的精度和大小是无限的。
3.4.10 变量加法程序
到目前为止,本章的示例程序实现了存储在寄存器中的整数加法。现在已经对如何定义数据有了一些了解,那么可以对同样的程序进行修改,使之实现三个整数变量相加,并将和数存放到第四个变量中。
;AddVariables.asm - 第3章 第61页
.386
.model flat, stdcall
.stack 4096
ExitProcess PROTO, dwExitCode:DWORD
.data
firstval DWORD 20002000h
secondval DWORD 11111111h
thirdval DWORD 22222222h
sum DWORD 0
.code
main PROC
mov eax, firstval
add eax, secondval
add eax, thirdval
mov sum, eax
INVOKE ExitProcess, 0
main ENDP
END main注意,已经用非零数值对三个变量进行了初始化(9~11行)。16~18行进行变量相加。x86 指令集不允许将一个变量直接与另一个变量相加,但是允许一个变量与一个寄存器相加。这就是为什么16~17行用EAX 作累加器的原因:
16: mov eax,firstval
17: add eax,secondval
第 17 行之后,EAX 中包含了firstval 和 secondval 之和。接着,第18 行把 thirdval 加到EAX 中的和数上:
18: add eax.thirdval
最后,在第 19 行,和数被复制到名称为sum 的变量中:
19: mov sum.eax
作为练习,鼓励读者在调试会话中运行本程序,并在每条指令执行后检查每个寄存器。最终和数应为十六进制的53335333。

提示 在调试会话过程中,如果想要变量显示为十六进制,则按下述步骤操作:鼠标在变量或寄存器上悬停1秒,直到一个灰色矩形框出现在鼠标下。右键点击该矩形框,在弹出菜单中选择Hexadecimal Display。
3.4.11 小端顺序
x86处理器在内存中按小端(little-endian)顺序(低到高)存放和检索数据。最低有效字节存放在分配给该数据的第一个内存地址中,剩余字节存放在随后的连续内存位置中。考虑一个双字12345678h。如果将其存放在偏移量为0000的位置,则78h存放在第一个字节,56h存放在第二个字节,余下的宁节存放地址偏移量为0002和0003,如图3-14所示。


其他有些计算机系统采用的是大端顺序(高到低)图3-15展示了12345678h从偏移量0000开始的大端顺序存放。
3.4.12 声明未初始化数据
.DATA?伪指令声明未初始化数据。当定义大量未初始化数据时,.DATA?伪指令减少了编译程序的大小。例如,下述代码是有效声明:
.data
smallArraY DWORD 10DUP(0) ;40个字节
.data?
bigArraY DWORD 5000 DUP(?) ;20000个字节,未初始化
而另一方面,下述代码生成的编译程序将会多出20000个字节:
代码与数据混合汇编器允许在程序中进行代码和数据的来回切换。比如,想要声明一个变量,使其只能在程序的局部区域中使用。下述示例在两个代码语句之间插人了一个名为temp 的变量:
.data
smallArraY DWORD 10DUP(0) ;40个字节
bigArraY DWORD 5000 DUP(?) ;20000个字节
代码与数据混合汇编器允许在程序中进行代码和数据的来回切换。比如,想要声明一个变量,使其只能在程序的局部区域中使用。下述示例在两个代码语句之间插人了一个名为temp 的变量:
.code
mov eax.ebx
.data
temp DWORD ?
.code
mov temp,eax
. . .尽管 temp 声明的出现打断了可执行指令流,MASM 还是会把temp 放在数据段中,并与保持编译的代码段分隔开。然而同时,混用.code 和.data 伪指令会使得程序变得难以阅读。
3.4.13 本节回顾
(变量定义都要在.data段下声明)
1.为一个16 位有符号整数创建未初始化数据声明。
答:val SWORD ?
2.为一个8位无符号整数创建未初始化数据声明。
答:var BYTE ?
3.为一个8位有符号整数创建未初始化数据声明。
答:val SBYTE ?
4.为一个64 位整数创建未初始化数据声明。
答:val QWORD ?
5.哪种数据类型能容纳32位有符号整数?
答:SDWORD
3.5 符号常量
通过为整数表达式或文本指定标识符来创建符号常量(symbolic constant)(也称符号定义(symbolic definition))。符号不预留存储空间。它们只在汇编器扫描程序时使用,并且在运行时不会改变。下表总结了符号与变量之间的不同:
|------------|----|----|
| | 符号 | 变量 |
| 使用内存吗? | 否 | 是 |
| 运行时数值会改变吗? | 否 | 是 |
本节将展示如何用等号伪指令(=)创建符号来表示整数表达式,还将使用EQU和TESTEOU伪指令创建符号来表示任意文本。
3.5.1 等号伪指令
等号伪指令(equal-sign directive)把一个符号名称与一个整数表达式连接起来(参见3.1.3节),其语法如下:
name =expression
通常,表达式是一个32位的整数值。当程序进行汇编时,在汇编器预处理阶段,所有出现的name都会被替换为expression。假设下面的语句出现在一个源代码文件开始的位置:
COUNT=500
然后,假设在其后10行的位置有如下语句:
mov eax, COUNT
那么,当汇编文件时,MASM 将扫描这个源文件,并生成相应的代码行:
mov eax, 500
为什么使用符号? 程序员可以完全跳过COUNT 符号,简化为直接用常量500来编写MOV指令,但是经验表明,如果使用符号将会让程序更加容易阅读和维护。设想,如果COUNT 在整个程序中出现多次,那么,在之后的时间里,程序员就能方便地重新定义它的值:
COUNT=600
假如再次对该源文件进行汇编,则所有的 COUNT 都将会被自动替换为600。
当前地址计数器 最重要的符号之一被称为当前地址计数器(current location counter),表示为$。例如,下面的语句声明了一个变量selfPtr,并将其初始化为该变量的偏移量;
selfPtr DWORD $
键盘定义程序通常定义符号来识别常用的数字键盘代码。比如,27是 Esc 键的 ASCII 码:
Esc_key= 27
在该程序的后面,如果语句使用这个符号而不是整数常量,那么它会具有更强的自描述性。使用
mov al,Esc_key ;好的编程风格
而非
mov al, 27 ;不好的编程风格
使用DUP操作符 3.4.4节说明了怎样使用DUP操作符来存储数组和字符串。为了简化程序的维护,DUP 使用的计数器应该是符号计数器。在下例中,如果已经定义了COUNT,那么它就可以用于下面的数据定义中:
array dword COUNT DUP(0)
重定义 用=定义的符号,在同一程序内可以被重新定义。下例展示了当 COUNT 改变数值后,汇编器如何计算它的值:
COUNT = 5
mov al, COUNT ;AL=5
COUNT = 10
mov al, COUNT ;AL=10
COUNT = 100
mov al, COUNT ;AL=100
符号值的改变,例如 COUNT,不会影响语句在运行时的执行顺序。相反,在汇编器预处理阶段,符号会根据汇编器对源代码处理的顺序来改变数值。
list BYTE 10,20,30,40
ListSize =4
显式声明数组的大小会导致编程错误,尤其是如果后续还会插入或删除数组元素。声明数组大小更好的方法是,让汇编器来计算这个值。$运算符(当前地址计数器)返回当前程序语句的偏移量。在下例中,从当前地址计数器(S)中减去 list 的偏移量,计算得到ListSize:
list BYTE 10,20,30.40
Listsize-(S-list)
ListSize 必须紧跟在list 的后面。下面的例子中,计算得到的ListSize值(24)就过大,原因是var2 使用的存储空间,影响了当前地址计数器与 list 偏移量之间的距离:
list BYTE 10,20,30.40
var2 BYTE 20 DUP(?)
ListSize=($-list)
不要手动计算字符串的长度,让汇编器完成这个工作:
myString BYTE "This is a long string,containing"
BYTE "any number of characters"
myString_len=($-myString)
字数组和双字数组 当要计算元素数量的数组中包含的不是字节时,就应该用数组总的大小(按字节计)除以单个元素的大小。比如,在下例中,由于数组中的每个字要占2个字节(16位),因此,地址范围应该除以2:
list WORD 1000h, 2000h, 3000h,4000h
ListSize=($-list)/2
同样,双字数组中每个元素长4个字节,因此,其总长度除以4才能产生数组元素的个数:
list DWORD 10000000h,20000000h,30000000h,40000000h
Listsize=(s-1ist)/4
3.5.3 EQU 伪指令
EQU伪指令把一个符号名称与一个整数表达式或一个任意文本连接起来,它有 3 种格式:
name EQU expression
name EQU symbol
name EQU <text>
第一种格式中,expression 必须是一个有效整数表达式(参见3.1.3)。第二种格式中,symbol是一个已存在的符号名称,已经用=或EQU定义过了。第三种格式中,任何文本都可以出现在<...> 内。当汇编器在程序后面遇到name 时,它就用整数值或文本来代替符号。
在定义非整数值时,EQU 非常有用。比如,可以使用 EQU 定义实数常量:
PI EQU <3.1416>
示例 下面的例子将一个符号与一个字符串连接起来,然后用该符号定义一个变量:pressKey EQU <"Press any key to continue..."0>
.data
prompt BYTE pressKey
示例假设想定义一个符号来计算一个10x10整数矩阵的元素个数。现在用两种不同的方法来进行符号定义,一种用整数表达式,一种用文本。然后把两个符号都用于数据定义:
matrix1 EQU 10*10
matrix2 EQU <10*10>
.data
M1 WORD matrix1
M2 WORD matrix2
汇编器将为 M1 和 M2 生成不同的数据定义。计算 matrix1 中的整数表达式,并将其赋给M1。而matrix2中的文本则直接复制到M2的数据定义中:
M1 WORD 100
M2 WORD 10*10
不能重定义 与=伪指令不同,在同一源代码文件中,用EQU定义的符号不能被重新定义。这个限制可以防止现有符号在无意中被赋予新值。
3.5.4TEXTEQU伪指令
TEXTEQU 伪指令,类似于EQU,创建了文本宏(text macro)。它有3 种格式:第一种为名称分配的是文本;第二种分配的是已有文本宏的内容;第三种分配的是整数常量表达式:
name TEXTEQU <text>
name TEXTEQU textmacro
name TEXTEQU %constExpr
例如,变量promptl使用了文本宏continueMsg:
continueMsg TEXTE0U<"Do you wish to continue (Y/N)?">
.data
prompt1 BYTE continueMsg
文本宏可以相互构建。如下例所示,count被赋值了一个整数表达式,其中包含rowSize。然后,符号move被定义为mov。最后,用move和count创建setupAL:
rowSize = 5
count TEXTEQU %(rowSize *2)
move TEXTEQU <mov>
setupAL TEXTEQU <move al,count>
因此,语句
setupAL
就会被汇编为
mov al,10
用TEXTEQU定义的符号随时可以被重新定义。
3.5.5 本节回顾
1.用等号伪指令定义一个符号常量,使其包含Backspace键的ASCII码(08h)。
答:Backspace = 08h
2.用等号伪指令定义符号常量SecondsInDay,并为其分配一个算术表达式计算24小时包含的秒数。
答:SecondsInDay = 24 * 60 * 60
3.编写一条语句使汇编器计算下列数组的字节数,并将结果赋给符号常量ArraySize:
myArray WORD 20 DUP(?)
答:ArraySize = ($ - myArray)
4.说明如何计算下列数组的元素个数,并将结果赋给符号常量ArraySize
myArray DWORD 30 DUP(?)
答:ArraySize = ($ - myArray) / 4
5.使用TEXTEQU表达式将"proc"重定义为"procedure"。
答:procedure TEXTEQU <proc>
6.使用TEXTEQU将一个字符串常量定义为符号Sample,再使用该符号定义字符串变量MyString。
答:Sample TEXTEQU <"const string"> ;定义常量
MyString BYTE Sample
7.使用 TEXTEQU 将下面的代码行赋给符号SetupESI:
mov esi, OFFSET myArray
答:SetupESI TEXTEQU <mov esi, OFFSET myArray>
3.6 64位编程
AMD 和 Intel 64位处理器的出现增加了对64位编程的兴趣。MASM 支持 64 位代码,所有的Visual Studio 2012 版本(最终版、高级版和专业版)以及桌面系统的Visual Studio2012 Express 都会同步安装 64位版本的汇编器。从本章开始,之后的每一章都将给出一些示例程序的 64 位版本。同时,还会讨论本书提供的 Irvine64 子程序库。
现在借助本章之前给出的AddTwoSum 程序,将其改为 64 位编程;
; AddTwoSum_64.asm 第3章 示例 第67页
ExitProcess PROTO
.data
sum DWORD 0
.code
main PROC
mov eax, 5
add eax, 6
mov sum, eax
mov ecx, 0
call ExitProcess
main ENDP
END上述程序与本章之前给出的32 位版本不同之处如下所示:
●32位AddTwoSum程序中使用了下列三行代码,而64位版本中则没有:
.386
.model flat,stdcall
.stack 4096
●64 位程序中,使用 PROTO 关键字的语句不带参数,如第3行代码所示:
ExitProcess PROTO
32位版本代码如下:
ExitProcess PROTO,dwExitCode:DWORD
●14~15行使用了两条指令(mov和call)来结束程序。32 位版本则只使用了一条INVOKE 语句实现同样的功能。64 位MASM 不支持INVOKE伪指令。
●在第 17 行,END 伪指令没有指定程序入口点,而 32 位程序则指定了。
使用64位寄存器
在某些应用中,可能需要实现超过 32 位的整数的算术运算。在这种情况下,可以使用64 位寄存器和变量。例如,下述步骤让示例程序能使用 64 位数值:
●在第6行,定义sum变量时,把 DWORD 修改为QWORD。
●在10~12行,把EAX替换为其64 位版本RAX。
下面是修改后的6~12行:
sum QWORD 0
.code
main PROC
mov rax, 5
add rax, 6
mov sum, rax 运行调试:

编写 32 位还是64 位汇编程序,很大程度上是个人喜好的问题。但是,需要记住:64位MASM 11.0(Visual Studio 2012 附带的)不支持INVOKE 伪指令。同时,为了运行 64 位程序,必须使用 64 位Windows。
本书作者网站(asmirvine.com)上提供了说明,帮助在64位编程时配置Visual Studio
整型常量表达式是算术表达式,包括了整数常量、符号常量和算术运算符。优先级是指当表达式有两个或更多运算符时,运算符的隐含顺序。
字符常量是用引号括起来的单个字符。汇编器把字符转换为一个字节,其中包含的是该字符的二进制ASCII码。字符串常量是用引号括起来的字符序列,可以选择用空字节标记结束。
汇编语言有一组保留字,它们含义特殊且只能用于正确的上下文中。标识符是程序员选择的名称,用于标识变量、符号常量、子程序和代码标号。不能用保留字作标识符。
伪指令是嵌在源代码中的命令,由汇编器进行转换。指令是源代码语句,由处理器在运行时执行。指令助记符是短关键字,用于标识指令执行的操作。标号是一种标识符,用作指令或数据的位置标记。
操作数是传递给指令的数据。一条汇编指令有0~3个操作数,每一个都可以是寄存器、内存操作数、整数表达式或输入/输出端口号。
程序包括了逻辑段,名称分别为代码段、数据段和堆栈段。代码段包含了可执行指令;堆栈段包含了子程序参数、局部变量和返回地址;数据段包含了变量。
源文件包含了汇编语言语句。列表文件包含了程序源代码的副本,再加上行号、偏移地址、翻译的机器代码和符号表,适合打印。源文件用文本编辑器创建。汇编器是一种程序,它读取源文件,并生成目标文件和列表文件。链接器也是一种程序,它读取一个或多个目标文件,并生成可执行文件。后者由操作系统加载器来执行。
MASM 识别内部数据类型,每一种类型都描述了一组数值,这些数值能分配给指定类型的变量和表达式:
●BYTE和SBYTE定义8位变量。
●WORD和SWORD定义16位变量。
●DWORD和SDWORD定义32位变量。
●QWORD和TBYTE 分别定义8字节和 10字节变量。
●REAL4、REAL8 和REAL10 分别定义 4 字节、8 字节和 10 字节实数变量。
数据定义语句为变量预留内存空间,并可以选择性地给变量分配一个名称。如果一个数据定义有多个初始值,那么它的标号仅指向第一个初始值的偏移量。创建字符串数据定义时,要用引号把字符序列括起来。DUP 运算符用常量表达式作为计数器,生成重复的存储分配。当前地址计数器运算符(S)用于地址计算表达式。
x86 处理器用小端顺序在内存中存取数据:变量的最低有效字节存储在其起始(最低)地址中。
符号常量(或符号定义)把标识符与一个整数或文本表达式连接起来。有 3个伪指令能够定义符号常量:
●等号伪指令(-)连接符号名称与整数常量表达式。
●EQU和TESTEQU伪指令连接符号名称与整数常量表达式或一些任意的文本。
3.8 关键术语
3.8.1 术语


3.8.2 指令、运算符和伪指令
