大家好,我继续来进行一个落后于热点资讯的老生常谈。
用一句话来概括本文内容:本文介绍了关于 MCP 的前世今生,通过以某个 AI IDE 举例来叙述了 MCP 的背景、配置方案、如何实现一个简单的 MCP,同时,在结尾处简单叙述了 Agent 的背景故事与基础原理。
1、什么是 MCP?
MCP 是一种开放协议,它标准化了应用向 AI 应用提供上下文的方式。您可以将 MCP 视为 AI 应用的 USB-C 端口。正如 USB-C 提供了一种将设备连接到各种外围设备和配件的标准化方式一样,MCP 提供了一种将 AI 模型连接到不同数据源和工具的标准化方式。
简单的说,MCP 就像是一个万能接口,可以让 AI Client 调用外部本地的命令文件,或是服务器上的 API 服务,来拓展并增强 Client 的能力。
2、我该如何使用 MCP?
- 找到开源的 MCP 服务 / 自己编写一个
shell
https://github.com/ferrislucas/iterm-mcp
https://github.com/GLips/Figma-Context-MCP- 配置网络 API 服务 / 本地脚本服务
shell
pnpx figma-developer-mcp --figma-api-key=\<\your-figma-api-key\>\- 在 Cursor 的设置中,找到 MCP 的配置并进行配置
json
"iterm-mcp": {
"command": "npx",
"args": ["-y", "iterm-mcp"]
},
"figma-context-mcp": {
"url": "http://localhost:3333/sse"
}万事俱备!
我们现在可以使用 MCP 来调用本地应用程序 / 网络服务中间件了
我们只需要在对话框中显式 / 隐式的调用 MCP 服务即可
例如:
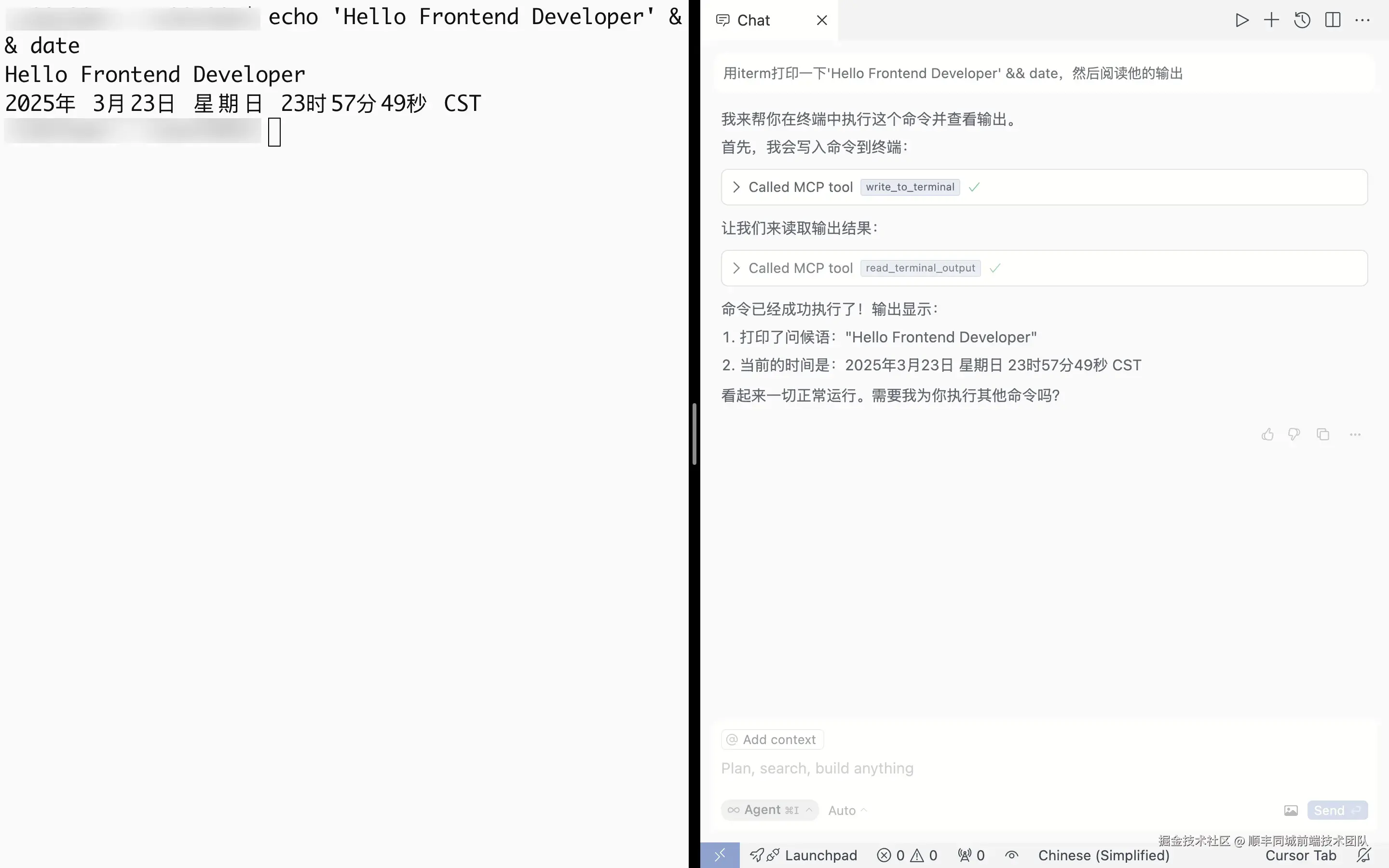
或
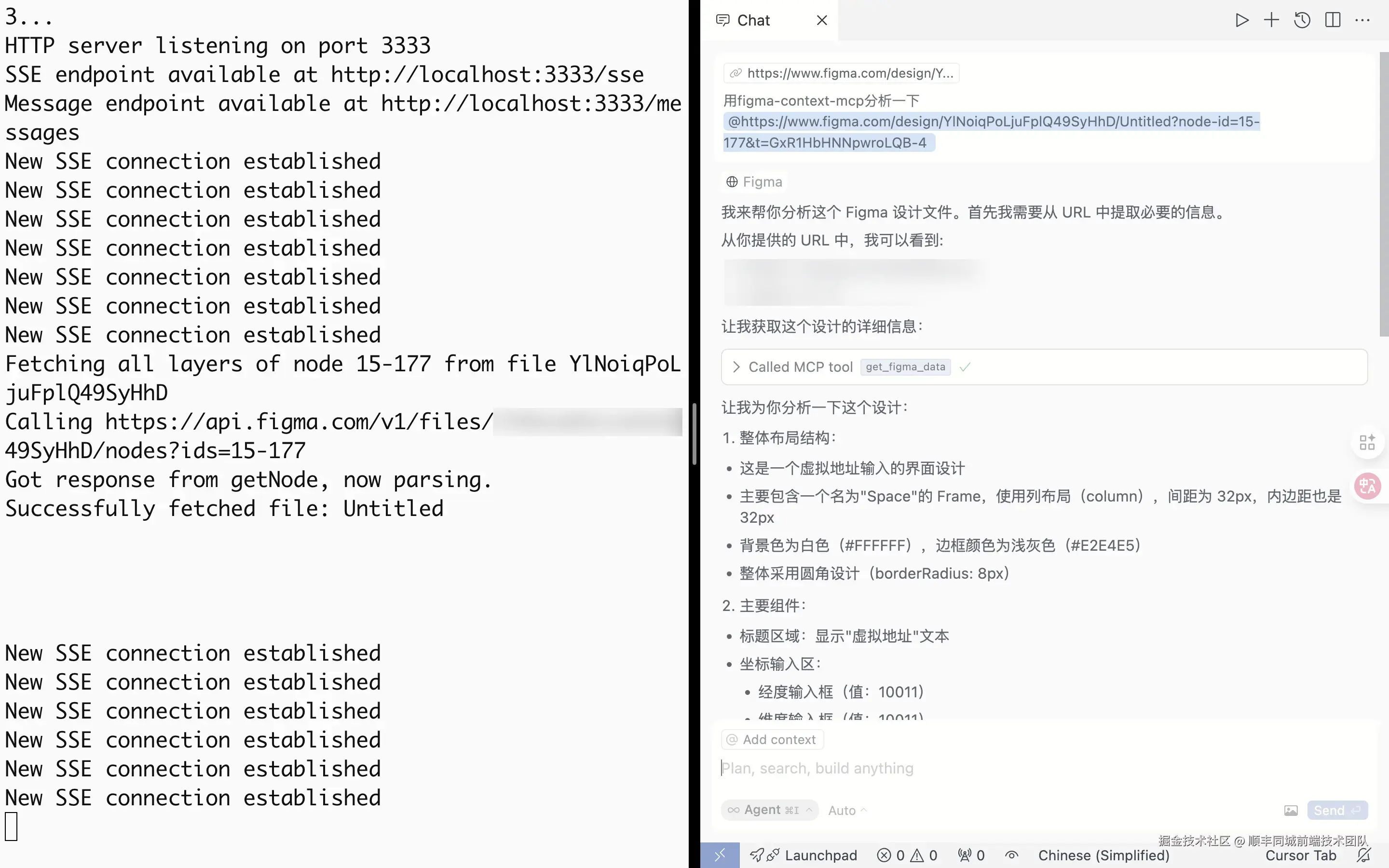
我们也可以通过 github.com/modelcontex... 查看更多的 MCP 服务
3、我该如何写一个属于自己的 MCP?
无论营销号们将 MCP 吹的多么的上天,MCP 终究只是类似于 Schema、HTTPS、Type-C 等的一种协议。
也就是说,无论我们用任何语言,用任何方式,只要遵循 MCP 的规范,我们的应用就可以被叫做:(符合)MCP(规范的应用)
此章节会以一个简单的获取实时天气的 MCP 服务为例来实现一个 MCP 服务。
前置准备:彩云天气API、高德地图API
前置知识储备
· MCP 使用 JSON-RPC 2.0 作为其传输格式。传输层负责将 MCP 协议消息转换为 JSON-RPC 格式进行传输,并将收到的 JSON-RPC 消息转换回 MCP 协议消息
· MCP 使用 Zod 进行严格的类型校验
· MCP 有两种调用方式:stdio | sse,stdio 使用标准输入 / 输出进行通信;sse 使用 Server-Sent Events 进行通信
plaintext
stdio(standard input/output)
stdio(standard input/output)模式指的是: 你的程序作为子进程运行,通过标准输入(stdin)读取请求,通过标准输出(stdout)返回响应
Cursor(主进程)
│
├── 启动你的 CLI 工具 → [node index.js]
│
├── 写入 stdin(请求)
│
└── 读取 stdout(响应)
1· 完全本地运行(无需开启端口、没有防火墙/SSL问题)
2· 安全、简单(不暴露服务,不占端口)
3· 支持自动退出(工具执行完毕可自动关闭进程)
bash
SSE(Server-Sent Events)
SSE(Server-Sent Events)模式指的是: 你的程序作为本地 HTTP 服务运行,提供一个支持事件流(event-stream)的 `/sse` 路径,供 Cursor 建立长连接并通过 `/messages` 接收请求。
Cursor(主进程)
│
├── 发起 GET 请求连接你的服务:`http://localhost:9614/sse`
│
├── 发起 POST 请求传递消息:`/messages`
│
└── 等待服务端通过 SSE 推送响应
1· 适合流式推送(如对话工具、代码生成、实时结果)
2· 支持并发连接,可服务多个客户端
3· 更像真实服务,可由 Nginx 代理、部署在常驻进程中如果我们想实现一个例如 PDF 解析、天气查询、RSS 抓取等服务的即用即走的插件,我们可以使用 stdio。
如果我们有可以常驻,或是启动过于缓慢,并且需要缓存的服务,例如图像处理、向量检索等需求,我们可以使用 sse。
我们本次以 stdio 的方式来实现一个简单的 MCP 服务。
我们通过大量的 mcp 官方库的方法来搭建我们的 MCP 应用。
- 设置应用参数
typescript
// index.ts
const argv = yargs(hideBin(process.argv))
.option('amapToken', {
type: 'string',
describe: 'Amap token',
})
.option('caiyunToken', {
type: 'string',
describe: 'Caiyun token',
})
.help()
.parseSync();- 设置 MCP 应用的入口方法
typescript
// server.ts
this.server.setRequestHandler(ListToolsRequestSchema, async () => {
return {
tools: [
{
name: 'get_real_time_weather',
description: '获取实时天气信息',
inputSchema: {
type: 'object',
properties: {
location: {
type: 'string',
description: '地理位置, 格式为 "天安门广场"',
},
region: {
type: 'string',
description: '地区, 格式为 "北京市"',
},
},
required: ['location', 'region'],
},
},
],
};
});- MCP 相应方法的具体实现函数
typescript
// server.ts
const getLocation = () => {
// 根据地区、关键词通过高德地图 API 获取经纬度
}
const getWeather = () => {
// 根据经纬度通过彩云天气 API 获取实时天气
}
this.server.setRequestHandler(CallToolRequestSchema, async (request) => {
try {
if (request.params.name !== 'get_real_time_weather') {
throw new Error(`Unsupported tool: ${request.params.name}`);
}
const args = request.params.arguments as {
location: string;
region: string;
};
if (!args.location) {
throw new Error('Location is required');
}
if (!args.region) {
throw new Error('Region is required');
}
const location = await this.getLocation(args.location, args.region);
if (!location) {
throw new Error('Location not found');
}
const weather = await this.getWeather(location);
if (!weather || weather.error || weather.status !== 'ok') {
throw new Error('Caiyun API error: ' + weather.error);
}
const { realtime } = weather.result;
// 一些天气的常量枚举
const weatherSkyConDesc = ...
// 生成天气报告的模版字符串
const weatherTemplate = ``;
return {
content: [
{
type: 'text',
text: weatherTemplate,
},
],
};
} catch (error) {
throw new McpError(
ErrorCode.InternalError,
'[Error] failed to call tool: ' +
(error instanceof Error ? error.message : String(error))
);
}
});- 别的没了
你可能不敢相信,营销号口中的颠覆 AI Client 使用体验的全新 AI 能力竟然只需要这么点代码就可以了???
不 要 相 信 营 销 号
如你所见,如我上文所述。
MCP 只是一个协议,不管我的服务是什么样的(我可以去获取天气、我可以查询互联网内容、我可以通过 AI 优化我的内容的文采、我甚至可以通过 API 去操控我米家中的智能家居...),只要我遵循其结构,我就可以让 AI Client 来通过 MCP 协议来调用我的服务。
4、一些关于调试和发布的后话
调试
有很多种调试 MCP 服务的方式,大家可以自行搜索,此处以 @wong2/mcp-cli 为例
我们可以通过运行 npx trc 打包之后,通过以下代码来进行调试。
npx @wong2/mcp-cli node ./build/index.js --amapToken=xxx --caiyunToken=xxx
发布
我们可以在 AI Client 的设置中看到类似于
json
"iterm-mcp": {
"command": "npx",
"args": ["-y", "iterm-mcp"]
}的写法。
MCP 并没有一个类似于 Chrome Extension 或 Vscode Plugin 这样的公共的平台,以以上内容为例,我可以直接将我的 MCP 应用发布到 NPM、或是 Python 类似的其他的任何平台。我们只需要保证可以通过命令行调用即可。
5、总结
没啥可总结的。
正文内容到此为止,以下是关于 Agent 的介绍,有兴趣的可以看一看。
6、Agent 基本原理
起源
Agent 一词源自拉丁语 "Agere",意为"行动"或"执行(to do)"。在大语言模型(LLM)的语境中,Agent 可以被看作是一种智能体,它具备自主理解指令、规划决策并执行复杂任务的能力。
对于我们日常的使用场景而言,Agent 类似于私人秘书或助理。当我们设定了一个最终目标,例如:"请帮我查询一下我在 Github 上 Star 的仓库,并将其整理为一个表格,同时编写一个脚本,在这些仓库更新时通知我",或"帮我创建一个使用 Next.js 和 Shadcn/UI 框架开发的个人网站,并部署在 Vercel 上",Agent 能够自主地将这些复杂任务自动拆解成具体的子步骤,并逐步执行,直至实现我们的最终目标。
如何明确地定义 Agent?
人们对 Agent 的理解存在着一定差异:
有些观点认为 Agent 是完全自主运行的系统,比如《生化危机》中的"红皇后",或者《钢铁侠》中的"贾维斯",它们能够独立执行决策,主动解决问题。
另一些观点则认为 Agent 是一种严格遵循预定义流程的系统,更类似于以预先编写好的代码和流程来执行规范性任务的 Workflow。
然而,在 Anthropic 的定义中,Workflow 与 Agent 是有严格区分的两个概念:
-
Workflow:是通过 LLM 以及其他(第三方)工具,根据明确定义的代码或流程,执行特定任务的系统。Workflow 的执行路径通常是预先设计并严格限定的。
-
Agent:则具备自主规划、信息检索、工具调用及记忆能力的智能体,能够在无需人为干预的情况下独立完成任务。
因此,我们可以更清晰地界定:
Agent 是一种经过增强的大语言模型,它不仅能处理语言,还能自主地进行规划、信息检索、工具使用和任务记忆,从而自动、高效地完成复杂的任务目标。
Agent 概述
Agent 通常由以下几个关键部分组成:
LLM
Agent 都是由 LLM 来驱动的,LLM 作为 Agent 的大脑,加上一些辅助的关键组件组成了 Agent。
Planning System
Memory System
Tool Use
Planning
- Planning System 会将大的任务分解成一些较小的、易于管理的小任务,从而更加高效的处理复杂任务。
- Planning System 会进行自我反省,在错误中吸取教训来改正未来的工作。
Planning 是 Agent 系统的核心能力之一,它允许 Agent 将复杂任务分解为可管理的子任务,并制定执行策略。有效的规划系统使 Agent 能够处理超出简单指令响应范围的复杂、多步骤任务。
Planning 的核心原理是目标驱动与任务分解。
- 一切的出发点是一个明确的目标,例如用户输入:"帮我制定一个去上海玩的规划"。
「制定一个去上海玩的规划」就是一个明确的目标
- 有了目标之后 Planning 会将一个大目标拆分成多个子任务。
查询车票 -> 预定酒店 -> 安排每日节点 -> 准备物品清单
这个过程通常用到
ReAct 模式(Reasoning + Acting)
ReAct 的核心理念是在每一步中先 Reasoning,再 Acting,然后再继续 Reason。
思维链推理(Chain of Thought | CoT)
CoT 允许 Agent 将复杂推理过程一步步的进行推理,而不是直接给出答案。
树状规划(Tree of Thoughts)
树状规划扩展了 CoT,允许 Agent 同时展开多个思路,然后再沿着最优的路径继续探索。
举例说明
我们通过「写一份周报」这个任务来对比一下这三种方法的流程对比
用户说帮我写一份本周的周报,内容包括
- 本周完成的工作
- 下周的计划
- 可能存在的问题和风险
方法一:ReAct | 边想边做,边做边想
Thought: 我要写一份周报,先问用户要"本周完成的内容" Action: 向用户提问「请列出你本周完成的工作」 Observation: 用户回复了三项工作内容
Thought: 然后收集"下周计划" Action: 向用户提问「请列出你下周的工作计划」 Observation: 用户回复了四项计划
Thought: 然后收集"风险与问题" Action: 向用户提问「请列出目前存在的问题和风险」 Observation: 用户回复了两项风险
Thought: 收集完毕,生成周报正文 Action: 编写并格式化完整周报
方法二:CoT | 一步步逻辑推理 -> 输出结果
- 思考:用户需要一份周报。周报通常包括:完成内容、计划内容、问题与风险。
- 思考:我需要先收集用户这周做了什么。
- 思考:再问用户下周准备做什么。
- 思考:最后获取用户遇到的困难或风险。
- 整理所有信息后,拼接成标准格式周报。
方法三:ToT | 展开多个写法/结构方案 -> 选最优路径生成周报
第一阶段:思考写法风格 Thought A1: 我可以用正式企业风格 Thought A2: 我可以用轻松口语风格 Thought A3: 我可以用结构化 Markdown 风格
第二阶段:对每种风格写出"完成内容"段落 Thought A1 → 本周完成了以下三项核心任务... Thought A2 → 这周我干了三件事,还挺忙的哈哈... Thought A3 → ## 本周完成事项\n - 任务 1\n - 任务 2...
评分阶段:根据"格式整洁度 + 语气适配度"选择 A3 为最优
第三阶段:基于 A3 模板,继续展开"下周计划"、"问题风险"
最终输出:完整的 Markdown 风格周报
什么时候使用这三种方式?
先说结论:LLM 会根据用户的提问来动态的选择推理的方式
例如:以 Claude 为例
当我们输入「帮我写一篇关于 LLM 安全的论文摘要」
Claude 可能会
好的,我们可以先梳理思路:
- 明确什么是 LLM 安全
- 分析其风险来源(幻觉、有害内容、Prompt Injection 等)
- 概述现有的防护机制
- 给出未来研究方向 ... (最后生成摘要)
这是典型的 Chain of Thought。
当我们输入「帮我生成一个合适的商业计划书」
Claude 会:
- 首先提问:你打算做什么类型的业务?
- 根据你的回答,继续提问你要融资多少、主要竞争者是谁......
- 最后再输出完整商业计划书
这是一种「模拟 ReAct」的行为(虽然不显式"Action + Observation",但过程上是 Reason → 用户反馈 → 再 Reason)。
Claude 会根据上下文自动生成最合适的推理路径,Claude 先进行任务识别,然后再根据以往的经验案例,最后在执行中随时修正推理路径。
例如: 假如我想用 Claude 完成一份周报,我输入的信息十分完整:
本周完成了 A/B/C,下周计划做 D/E/F,遇到的问题是 G/H。
这时 Claude 认为你已经给了所有的先决条件,所以通过纯粹的 CoT 来执行你的操作
假如我想用 Claude 完成一份项目总结,我直接说「给我写一份项目总结」
这时 Claude 判断你什么信息都没有给出,所以开始切换为 ReAct 风格的反问:「你的项目是什么样的?做了那些内容?」然后等你补充完成之后,再进行下一步的推理。
• ReAct 模式尤其适用于需要动态信息检索或实时反馈交互的任务; • CoT 更适合已明确信息且逻辑顺序较为简单的推理任务; • ToT 更适合多方案探索和优化、创造性的场景。
Memory
记忆系统分为两个部分:
短期记忆
短期记忆指的是 Agent 在执行单个任务或对话过程中临时存储的信息,类似人类大脑在短暂思考或进行简单推理时所用的记忆。
短期记忆通常通过 Sliding Window / 有限窗口 机制来实现,这个机制可以保证只保留最近的几个对话轮次中的内容,有时也用其他更灵活的方式来实现,例如 Stateful Cache / 状态缓存 等等
短期记忆用来确保 Agent 能够在单一对话中保持连贯性,也就是说,可以理解为短期记忆只用来储存较少的轮次的对话中的信息。例如智能客服中可以在短暂的时间内来保证对话连贯,或是在用户进行对话交互时记住用户刚刚提到的要求或者关键词。
长期记忆
长期记忆类似于知识库、经验库,可以让 Agent 根据以往的经验来做出更加合理的决策。
长期记忆通常通过 RAG(Retrieval-Augmented Generation)、向量数据库或知识图谱等技术实现,将非结构化数据(如文档、网页)或结构化数据(如用户偏好、历史交互记录)转化为可检索的知识形式,帮助 Agent 在未来的决策中参考以往的经验。
长期记忆可以让 Agent 根据以往的经验来做出更加合理的决策。
长期记忆和短期记忆在运行中的协作关系
以一个简单的对话为例:
用户对 Agent 提问"今天上海天气如何?"
(短期记忆记录):用户关注上海今天的天气 (读取长期记忆):用户的语言偏好、天气预报来源偏好等等
用户追问"适合穿什么衣服?"
(读取短期记忆):用户关心的是今天在上海适合穿什么衣服 (读取长期记忆):用户以往的穿衣风格
当用户持续使用一段时间后,Agent 的长期记忆的内容会越来越丰富,使得每一次交互都更加高效、智能。
Tool Use
Agent 的 Tool Use 是它实现"动手能力"的关键模块。它让语言模型不只是"在脑中想",还能"用手去做"。比如调用搜索引擎、数据库、函数、插件、浏览器、API 等等,把语言思维落地为真实操作。
它的工作流程通常是
- 用户发出一个复杂请求
- Agent 判断是否需要调用工具
- Agent 构造一个调用指令(工具名称 + 参数)
- 中间系统(如插件机制、Tool Router)接收指令并执行
- 把执行结果返回给 LLM
- LLM 根据结果继续思考 / 执行下一步
人们通常通过 专门训练 / 微调 让 LLM 看例子,然后来让 LLM 知道对于什么样的场景要调用什么样的工具
类似于
用户:请告诉我今天北京的天气
助手: Thought: 我不知道当前天气,需要使用 weather API 查询 Action: get_weather("Beijing") Observation: 北京今天多云,温度 21°C Thought: 得到了结果,可以回答用户了 Answer: 北京今天是多云,气温在 21°C 左右。
Agent 要怎样调用各种工具?
Agent 会通过外部的 Tool Router、Function Handler、Plugin Runtime 等模块调用工具。
Tool Router
Tool Router 是一个判断语言调用意图,并分发任务的中间组件。
它负责
- 看懂 LLM 的输出
- 判断 LLM 要使用哪个工具
- 把指令交给服务去执行
比如说,我们举一个「请帮我在项目中初始化 tailwind」的例子,LLM 可能发出了这样的一些调用命令:
json
{
"tool_call": {
"name": "search",
"arguments": {
"query": "tailwind 初始化命令"
}
}
}
{
"tool_call": {
"name": "execute_terminal_command",
"arguments": {
"query": "npx tailwind init"
}
}
}
{
"tool_call": {
"name": "read_terminal",
}
}Tool Router 会判断 LLM 想要调用的是哪个工具,里面带有哪些参数,然后分发给相应的被绑定的 Search Handler
Function Handler
如果把 LLM 类比为司令,把 Tool Router 类比成参谋,Function Handler 就是下面的大头兵。
上文我们提到,Tool Router 会将相对应的任务分发给 Function Handler,Function Handler 就类似于一个函数
javascript
function search({ query }) {
return realGoogleSearchAPI(query);
}这样的一个函数,Function Handler 执行完之后再把结果返回给 Router,然后 Router 再把结果交给 LLM。
Plugin Runtime
类似于我们会将服务运行在 Docker 中,Agent 的 Function Handler 也是被放在类似于 Docker 的 Plugin Runtime 中,Plugin Runtime 为 Agent 提供安全、受控的隔离执行环境(如容器或沙箱),管理插件生命周期,执行 Function Handler,并处理安全权限控制、资源限制、上下文传递等功能。
MCP
MCP(Model Context Protocol)是一种可以让 LLM 与外界系统进行通信的协议。
在实际使用中,人们经常用『MCP 插件』来泛指「遵循 MCP 协议的服务模块」,例如「支付宝 MCP」「高德地图 MCP」,本质上是指这些服务作为 Agent 插件,按照 MCP 协议暴露了可调用的方法。
以 Cursor 为例,我们可以在其 mcp.json 配置文件中添加自定义的 MCP 服务。Cursor 会将这些服务所暴露的方法统一注册到其内部的函数调用表中,作为可供 Agent 调用的工具。这些方法本质上就是 MCP 协议定义的接口,实现了对应的 Function Handler,并由 Tool Router 动态路由和触发调用。
注意!LLM 的调用并不完全遵循 MCP 协议,MCP 协议主要是为了解决不同厂商的 LLM 之间的协议不互通的问题,也就是为了让第三方服务可以通过一套方案来适配不同的 LLM。类似 ChatGPT 和 Claude,在其 LLM 内部都有属于自家厂商的私有协议。拿 search 这个动作来举例,LLM 可能通过私有协议调用 LLM 本身的网络搜索能力,也可能通过 MCP 来调用第三方插件来获取更加强大更具有拓展性的搜索。
使用哪一种方案取决于 Router 调度系统的决策。比如模型能力优先、插件优先、条件分发、混合对比模式。
MCP 的大致结构
- 请求(Requests) 请求消息用于从客户端向服务器发起操作,或者从服务器向客户端发起操作。
请求消息的结构如下:
json
{
"jsonrpc": "2.0",
"id": "string | number",
"method": "string",
"params": {
"[key: string]": "unknown"
}
}jsonrpc:协议版本,固定为"2.0"。 id:请求的唯一标识符,可以是字符串或数字。 method:要调用的方法名称,是一个字符串。 params:方法的参数,是一个可选的键值对对象,其中键是字符串,值可以是任意类型。
- 响应(Responses) 响应消息是对请求的答复,从服务器发送到客户端,或者从客户端发送到服务器。
响应消息的结构如下:
json
{
"jsonrpc": "2.0",
"id": "string | number",
"result": {
"[key: string]": "unknown"
},
"error": {
"code": "number",
"message": "string",
"data": "unknown"
}
}jsonrpc:协议版本,固定为"2.0"。 id:与请求中的 id 相对应,用于标识响应所对应的请求。 result:如果请求成功,result 字段包含操作的结果,是一个键值对对象。 error:如果请求失败,error 字段包含错误信息,其中: code:错误代码,是一个数字。 message:错误描述,是一个字符串。 data:可选的附加错误信息,可以是任意类型。
- 通知(Notifications) 通知消息是一种单向消息,不需要接收方回复。
通知消息的结构如下:
json
{
"jsonrpc": "2.0",
"method": "string",
"params": {
"[key: string]": "unknown"
}
}jsonrpc:协议版本,固定为"2.0"。 method:要调用的方法名称,是一个字符串。 params:方法的参数,是一个可选的键值对对象,其中键是字符串,值可以是任意类型。