随着流量红利的逐渐消失,用户获取、留存和商业收入面临巨大挑战。在这种情况下,用户增长承担重要的使命,也成为互联网甚至传统企业至关重要的发展利器。用户增长离不开企业发展和技术双轮驱动,通过数字化实现A(Acquisition,获取)A(Activation,激活)R(Retention,留存)R(Revenue)R(Referral)模型驱动,从而指导和推进企业发展,这就是数字化营销。
技术打造营销平台,埋点采集用户行为数据,分析挖掘用户行为与基础标签数据写入到大宽表,画像画像借助用户标签分析用户、了解用户,沉淀高潜用户客群和规则,接下来投入到任务策略进行触达、转化,然后深入分析和复盘任务策略转化漏斗,从而达到利用数据和程序驱动运营。
这里站在技术角度,重点分析营销客群系统如何构建,主要包括用户标签、用户客群和开放API三大模块,为运营人员提供操作和维护。
一、客群架构
业务架构图呈现用户标签、用户客群和开放API三大模块的核心功能,用户标签提供圈人标签基础能力,用户客群提供数据落地和服务逻辑实现,开放API提供对外客群能力。
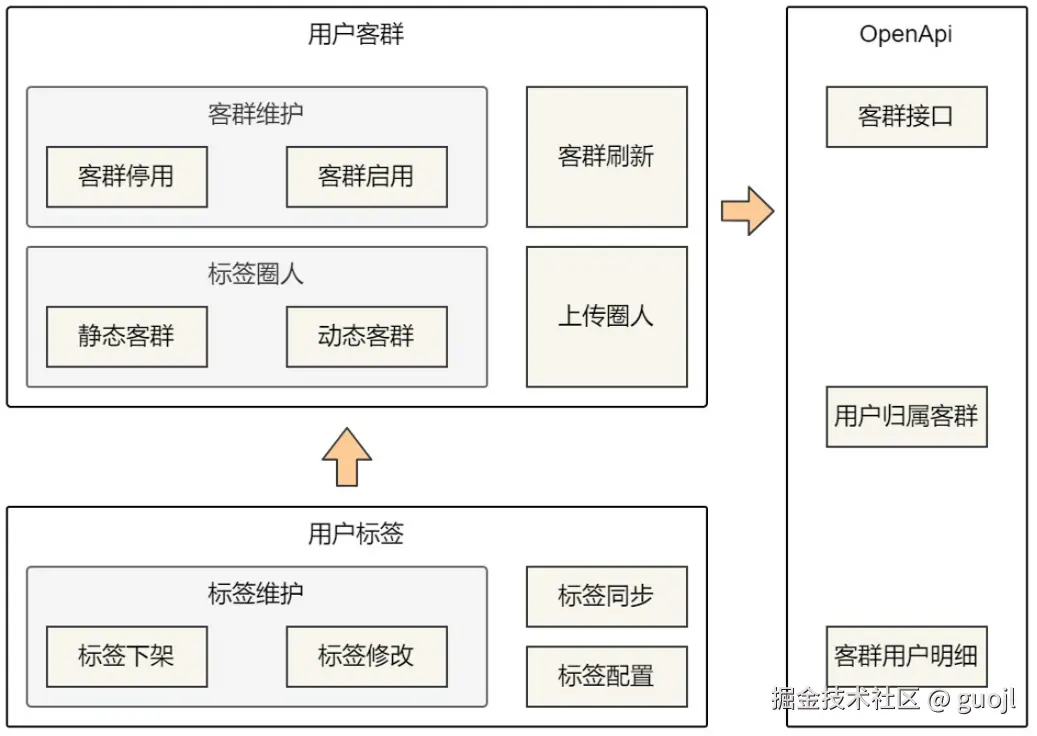
二、用户标签
企业对客业务平台收集用户基础信息,通过埋点采集用户行为数据,实现数据全方位采集。大数据清洗埋点和业务数据,输出一些列数据标签,比如用户性别、用户年龄和用户分层,然后保存到Doris数据库。营销客群系统同步数据库标签表,然后增量同步到标签配置表。
2.1 为何选择Doris
营销系统会涉及很多用户基础信息和用户行为标签,业务大宽表标签字段会高达几百个,那么大数据聚合标签数据存在技术挑战。
大数据选用基于Hive作为存储引擎,那么标签数据存储存在每个用户标签存储一条数据、多条数据两种方式。如果每个用户标签仅存储一条数据,大数据使用关联大量中间表,清洗出用户标签数据,存在内存占用YARN内存队列,严重会影响其他调度任务。如果每个用户标签存储多条数据,用户数据存在标签数量级别爆炸,严重浪费存储资源,用户客群进行圈人也会大量浪费计算资源。总而言之,基于**Hive**关联用户标签数据技术方案不可行。
最佳实践方案就是使用聚合存储引擎,如Doris或者Druid存储引擎。其中,Doris支持写时合并Unique数据模型,ClickHouse提供AggregatingMergeTree聚合引擎。使用仅指定标签表用户维度,用户标签就会通过维度进行数据聚合。
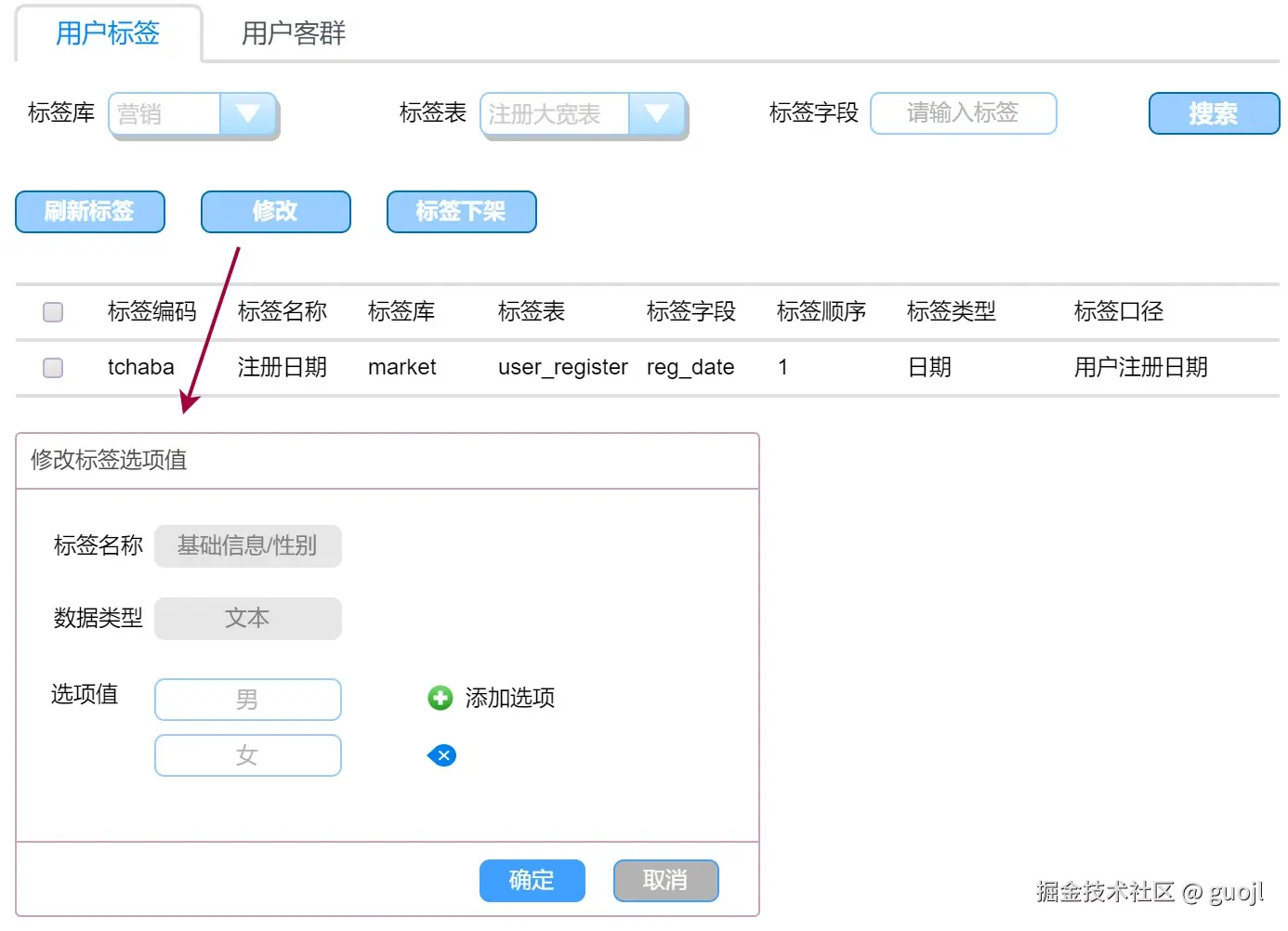
2.2 标签配置
标签配置核心功能主要包括标签映射类型,以及待同步标签数据源表、允许同步的标签和不允许同步的标签。用户标签类型用于交互界面进行数据条件填充逻辑,支持数字类型、文本类型、时间类型、日期类型和地理位置类型,这些信息可以放在配置中心或者数据库存储。
注意:如果需要支持地理位置类型需要通过数据库脚本进行修改,不支持营销管理平台进行操作。比如,用户常住地标签数据库存储为字符串类型,标签同步后为文本类型,如果需要展示位地理位置类型,需要通过数据库修改为地理位置类型。
json
{
"varchar": "text",
"text": "text",
"int": "number",
"bigint": "number",
"numeric": "number",
"decimal": "number",
"double": "number",
"money": "number",
"timestamp": "datetime",
"date": "datetime",
"float": "number"
}2.3 标签刷新
营销管理平台提供刷新操作,服务端获取待同步标签数据库表,然后链接数据库获取标签表元数据,对比过滤已同步标签字段,增量插入未同步标签字段到标签配置表。其中,获取Doris表元数据数据库脚本已整理,如下脚本代码所示。
sql
select
table_name as tablename,
column_name as columnname,
column_type as columntype,
column_comment as columncomment,
ordinal_position as position
from information_schema.columns
where
col.table_schema = #{schemaname}
and col.table_name = #{tablename}标签表用于管理数据库表标签相关信息,包括标签的数据库来源,数据口径等,数据库脚本如下所示。
sql
create table tag_table
(
id bigint unsigned not null auto_increment comment '主键',
tag_code varchar(50) not null default '' comment '标签代码',
tag_name varchar(100) not null default '' comment '标签名称',
db_name varchar(50) not null default '' comment '模式名称',
tbl_name varchar(50) not null default '' comment '表名称',
tbl_field varchar(50) not null default '' comment '标签字段',
data_type varchar(50) not null default '' comment '数据类型, text-文本, number-数字, datetime-时间, date-日期, region-地理位置',
tag_group_name varchar(64) not null default '' comment '标签分组',
tag_layer varchar(64) not null default '' comment '标签分层',
tag_layer_num int(11) not null default '' comment '标签层级',
tag_state varchar(50) not null default 'on' comment '标签状态, off-下架, on-启用',
## ...
deleted tinyint(1) not null default '0' comment '删除标记, 0-正常, 1-删除',
primary key (id) using btree,
unique key uniq_tag_code (tag_code) using btree
) engine = innodb
auto_increment = 1
default charset = utf8mb4
collate = utf8mb4_0900_ai_ci
row_format = dynamic comment ='标签表';2.4 标签维护
标签维护主要包括标签修改和上下架操作,标签修改主要提供标签下拉列表维护,也就是后台管理可以维护常见下拉框选项值,存储到标签选项表。上下架主要是用于维护标签不提供服务时,暂停标签数据清洗,减少资源浪费。
sql
create table tag_table_option
(
id bigint unsigned not null auto_increment comment '主键',
tag_code varchar(50) not null default '' comment '标签代码',
option_key varchar(100) not null default '' comment '选项键',
option_val varchar(100) not null default '' comment '选项值',
show_no varchar(50) not null default '' comment '显示顺序',
## ...
deleted tinyint(1) not null default '0' comment '删除标记, 0-正常, 1-删除'
) engine = innodb
auto_increment = 1
default charset = utf8mb4
collate = utf8mb4_0900_ai_ci comment ='标签选项';三、用户客群
用户客群提供标签圈人、上传圈人、客群拆分核心能力,附带用户客群维护。标签圈人需要借助"营销画像规则引擎能力",根据客群标签灵活交并差圈人逻辑生成筛选条件数据库脚本。 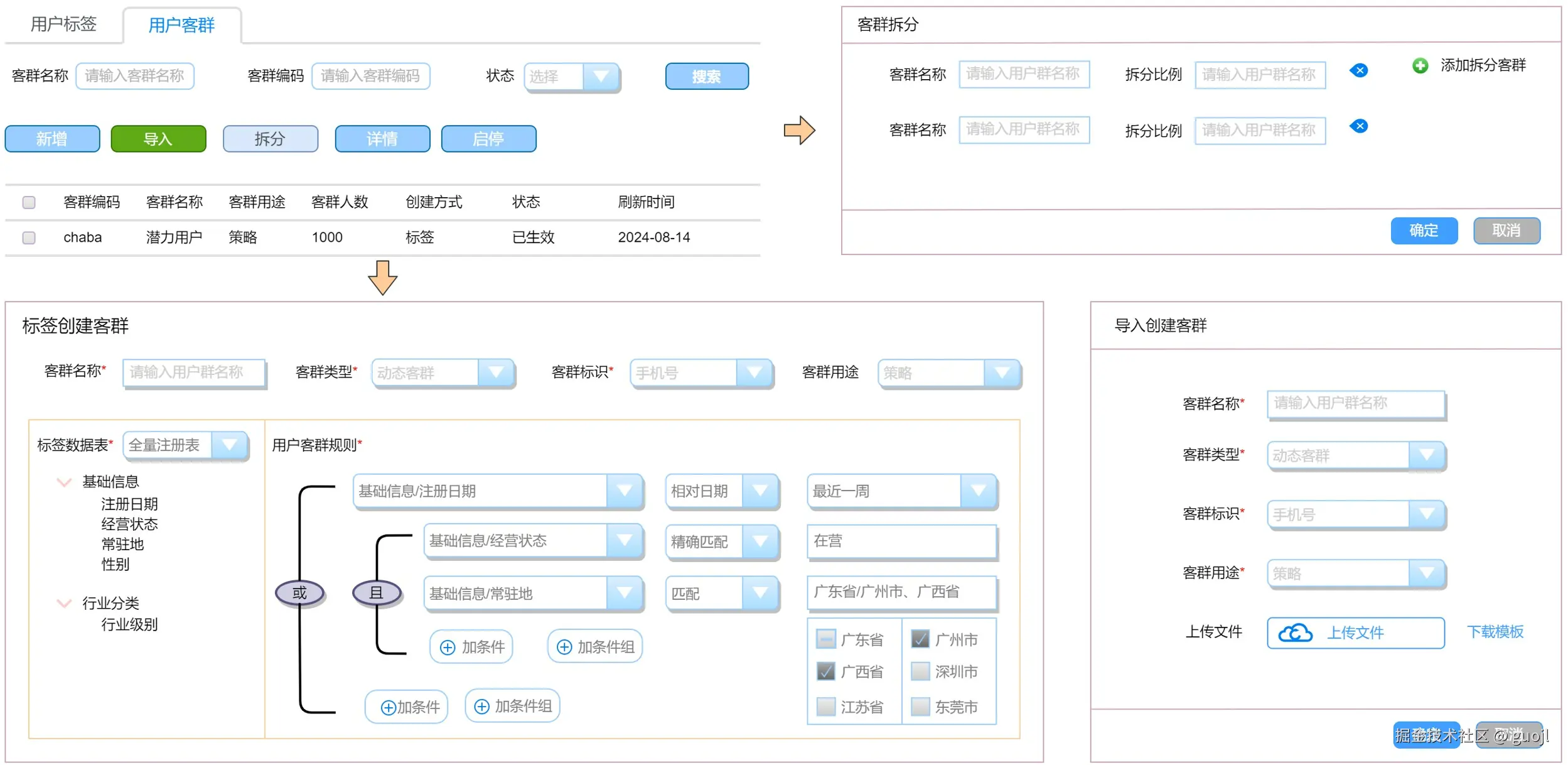
3.1 创建客群
客群创建提供标签客群和导入客群创建,标签客群通过用户标签灵活交并差组装标签条件逻辑,服务端接收参数条件生成存储引擎查询脚本推送到消息队列,消息队列根据存储引擎和脚本固化数据,然后通知营销平台客群进行数据处理入库。 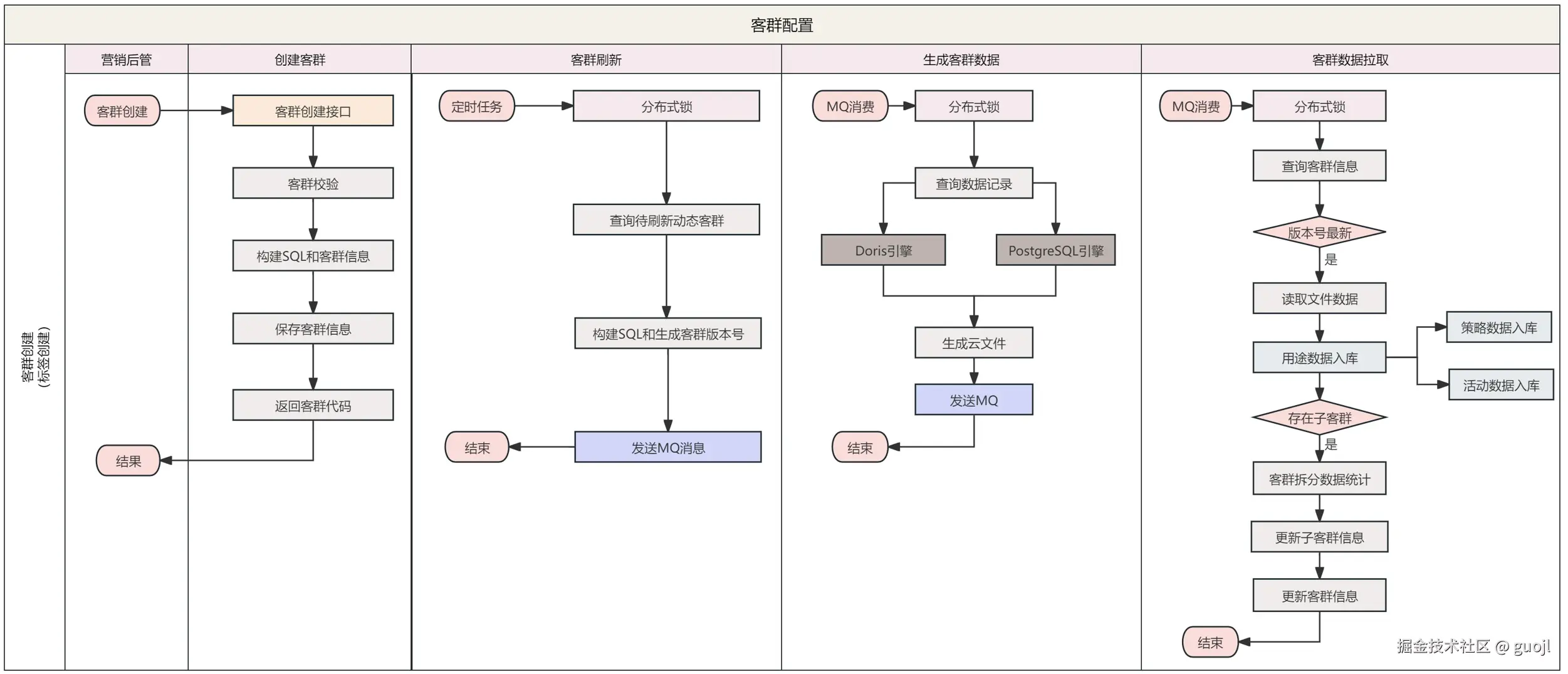
sql
create table tag_crowd (
id bigint unsigned not null auto_increment comment '主键',
crowd_code varchar(64) not null default '' comment '客群代码',
crowd_name varchar(200) not null default '' comment '客群名称',
start_time datetime not null default '1970-01-01' comment '开始时间',
end_time datetime not null default '1970-01-01' comment '结束时间',
create_mode varchar(64) not null default 'TAG' comment '创建方式, TAG-标签创建, IMPORT-导入, EVENT-事件',
update_mode varchar(64) NOT NULL DEFAULT 'ONCE' COMMENT '更新类型, ONCE-单次, REPEAT-重复',
crowd_count int(11) NOT NULL DEFAULT '0' COMMENT '客群人数',
tag_condition varchar(1024) not null default '' comment '标签条件',
use_flag varchar(50) not null default 'ON' comment '使用标志, OFF-暂停, ON-启用',
crowd_state varchar(64) not null default 'ON_AUDIT' comment '客群状态, ON_AUDIT-待处理, NO_EFFECT-未生效, EFFECT-已生效, EXPIRE-已过期',
crowd_version varchar(50) not null default '0' comment '客群数据版本',
level_path varchar(128) not null default '' comment '客群路径',
level_num int(11) not null default '1' comment '客群层数',
level_node varchar(64) not null default '0' comment '客群节点, LEAF-叶子客群, BRANCH-分支客群',
dim_start int(11) not null default '0' comment '用户范围开始位置',
dim_end int(11) not null default '9999' comment '用户范围结束位置',
remark varchar(2048) not null default '' comment '备注',
## ...
deleted tinyint(1) not null default '0' comment '删除标记, 0-正常, 1-删除'
) engine = innodb
auto_increment = 1
default charset = utf8mb4
collate = utf8mb4_0900_ai_ci comment ='客群信息表';3.2 客群拆分
用户客群提供拆分功能,也就是根据指定比例拆分多子客群,可以用于特征客群灰度或者分流等相关处理。首先,客群信息表包括客群路径、客群层数和客群节点指定客群之间层级关系。其次,客群用户数据明细整体归属根客群,数据范围使用哈希或者递增序列数学取模1W数值表示数据位置,客群信息表通过用户范围开始位置(dim_start)和用户范围结束位置(dim_end)可获取范围用户数据。
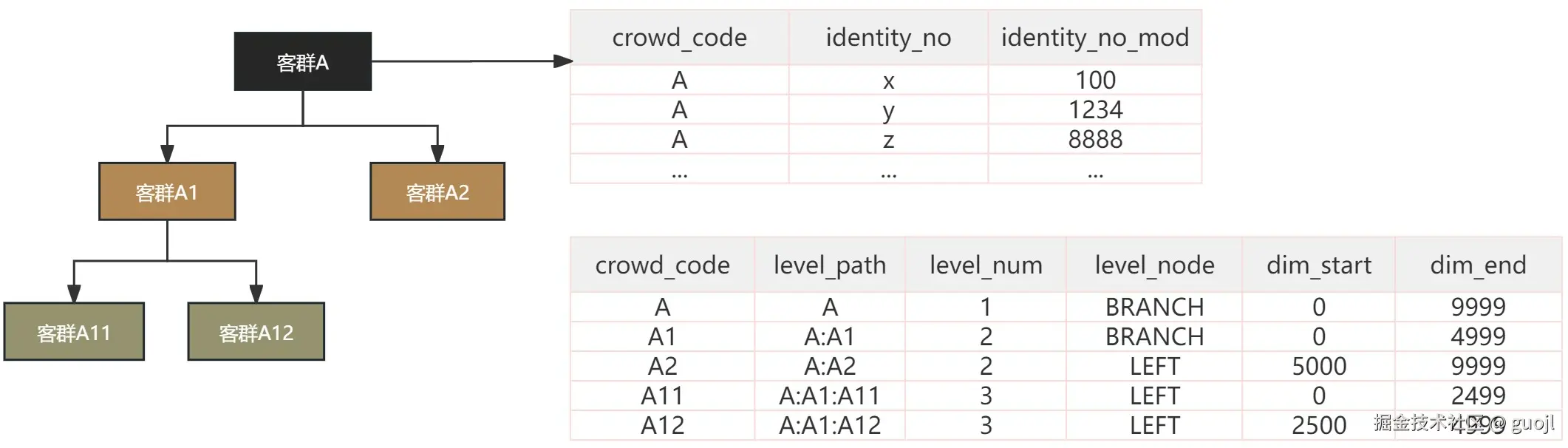
sql
create table tag_crowd_detail
(
id bigint unsigned not null auto_increment comment '主键',
crowd_code varchar(64) not null default '' comment '客群代码',
crowd_version varchar(64) not null default '0' comment '客群版本号',
identity_no varchar(64) not null default '' comment '用户编号',
identity_type varchar(20) not null default '' comment '用户标识, OPEN_ID-微信OpenID, USER_NO-用户号, CUST_NO-客户号, COMPANY_NO-企业号, PHONE-手机号, FLOWNO-节点流水',
identity_no_mod int(11) not null default '0' comment '客群模值',
##...
deleted tinyint(1) not null default '0' comment '删除标记, 0-正常, 1-删除'
) engine = innodb auto_increment = 1 default charset = utf8mb4 collate = utf8mb4_0900_ai_ci comment ='客群用户明细表'3.3 客群多版本
客群通过添加版本号(crowd_version)支持多个版本明细数据,定时任务定期扫描进行数据刷新,仅会在数据刷新成功之后才会更新客群信息表,保证当前客群数据读取不受影响。其次,定时任务会定期扫描版本旧版本客群,然后执行删除,保证当前客群仅保存固定版本数用户明细。
3.4 客群刷新
定时任务扫描用户客群当天是否有刷新记录,然后检查大数据是否已准备好数据,如果满足条件就通过生成相关查询脚本提交客群数据刷新。所以,这里数据刷新依赖大数据宽表数据准备。
sql
create table big_tag_table_fresh_info
(
id bigint unsigned not null auto_increment comment '主键',
schema_name varchar(100) not null default '' comment '库名',
table_name varchar(100) not null default '' comment '表名',
finish_time date not null default '1970-01-01' comment '数据日期',
## ...
deleted tinyint(1) not null default '0' comment '删除标记:0:正常, 1:删除'
) engine = innodb
auto_increment = 1
default charset = utf8mb4
collate = utf8mb4_0900_ai_ci comment ='大数据客群宽表刷新信息';
create table tag_crowd_fresh_record
(
id bigint unsigned not null auto_increment comment '主键',
flow_no varchar(32) not null default '' comment '流水号',
crowd_code varchar(50) not null default '' comment '客群编码',
crowd_sql varchar(1024) not null comment '客群sql',
push_time datetime not null default '1970-01-01' comment '推送时间',
crowd_version varchar(50) not null default '' comment '客群版本号',
file_path varchar(1024) not null default '' comment '文件路径',
data_count int(11) default '0' comment '数据量',
finish_time datetime not null default '1970-01-01' comment '完成时间',
process_state int(11) not null default '0' comment '处理进度, 0-处理中, 1-处理成功, 2-处理失败, 3-版本数据已删除',
remark varchar(200) default '' comment '处理备注',
# ...
) engine = innodb
auto_increment = 1
default charset = utf8mb4
collate = utf8mb4_0900_ai_ci comment ='客群刷新记录表';四、开放API
客群开放API主要包括授权查询客群信息、客群明细拉取和用户是否归属客群进行查询。比如,活动需要限定一定范围用户参与,那么可以通过查询用户是否归属当前客群即可进行限定。
五、总结
用户客群作为营销基础能力,需要根据企业用户量进行设计底层存储引擎,还有需要清晰的数据库关系设计才能减少复杂逻辑,另外多使用设计模式减少实现复杂度,提高代码可扩展性和维护性。