论文发表于人工智能顶会ICLR(原文链接)。基于定位和修改的模型编辑方法(针对ROME和MEMIT等)会破坏LLM中最初保存的知识,特别是在顺序编辑场景。为此,本文提出AlphaEdit:
1、在将保留知识应用于参数之前,将扰动投影到保留知识的零空间上。
2、从理论上证明,这种预测确保了在查询保留的知识时,编辑后的LLM的输出保持不变,从而减轻中断问题。
3、对各种LLM(包括LLaMA3、GPT2XL和GPT-J)的广泛实验表明,AlphaEdit只需一行额外的投影代码,即可将大多数定位编辑方法的性能平均提高36.4%。
阅读本文请同时参考原始论文图表。
AlphaEdit
零空间
基于前面ROME/MEMIT的工作,对于LLM中的MLP矩阵W,可被表示为关于已有知识(K_0,V_0)的优化结果:
W= \\arg \\min\\limits_{\\tilde{W}} \\left\\\| \\tilde{W} K_0 - V_0 \\right\\\|\^2
其中矩阵K_0\\in \\mathbb{R}\^{d_0\\times n},V_0\\in \\mathbb{R}\^{d_0\\times n},n表示已有知识数量。对于新增知识(K_1,V_1),MEMIT的做法为优化扰动\\Delta来更新W:
\\Delta = \\arg \\min\\limits_{\\tilde{\\Delta}} \\left( \\left\\\| (W + \\tilde{\\Delta}) K_1 - V_1 \\right\\\|\^2 + \\left\\\| (W + \\tilde{\\Delta}) K_0 - V_0 \\right\\\|\^2 \\right)
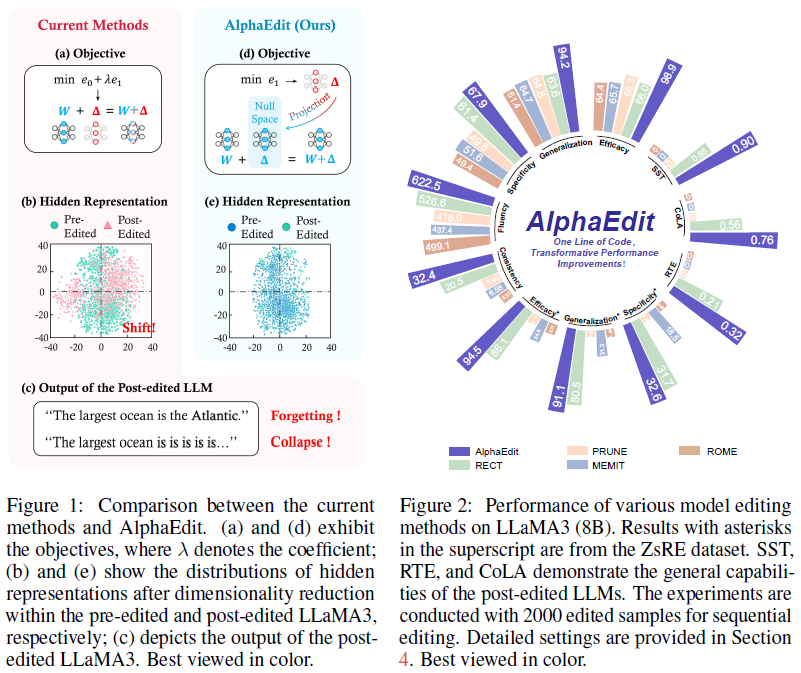
上式为二次优化,可通过求导直接获得闭式解。然而,耦合的优化不可避免会是扰动量对原始知识产生影响,从而在终身编辑场景中鲁棒性不强。文中通过将中间token表示映射到二维空间的分布偏移来表明这一观点:如图1be所示,MEMIT在编辑后token表示的分布产生了较大偏移,而AlphaEdit则没有。
因此,AlphaEdit期望找到K_0的零空间,把\\Delta映射到其上,从而权重更新将对这些知识不产生影响。矩阵A在矩阵B的零空间内,当且仅当BA=0。也就是说,期望找到\\Delta有:
(W + \\Delta) K_0 = W K_0 = V_0
那么如何将\\Delta映射到K_0的零空间呢?
SVD分解获取零空间映射
考虑对称方阵K_0K_0\^T\\in\\mathbb{R}\^{d_0\\times d_0},对其进行奇异值分解(SVD),得到:
\\{ U, \\Lambda, U\^T \\} = \\text{SVD} \\left( K_0 K_0\^T \\right)
其中U为正交矩阵(UU\^T =I),\\Lambda对角矩阵,主对角线为奇异值。将奇异值在主对角线降序排序:
\\Lambda = \\begin{bmatrix} \\Lambda_1 \& 0 \\\\ 0 \& \\Lambda_2 \\end{bmatrix}
取其中为零的部分\\Lambda_2(假设\\Lambda_2都很小几乎为0,文中取小于0.01的值)在U中对应的特征向量矩阵\\hat{U}\\in\\mathbb{R}\^{d_0\\times m}。则P = \\hat{U}\\hat{U}\^T为将任意矩阵映射到K_0K\^T_0零空间的矩阵。这是由于,对于任意矩阵\\Delta,有:
\\Delta PK_0K\^T_0 = \\Delta\\hat{U}\\hat{U}\^TK_0K\^T_0= \\Delta\\hat{U}\\hat{U}\^TU\\Lambda U\^T
由于其中\\hat{U}\^TU\\Lambda=0,上式为零。P为K_0K_0\^T的零空间映射矩阵,同时也K_0的零空间映射矩阵,这是由于:
\begin{align*} &P K_0 K_0^T = 0 \\ \Rightarrow &P K_0 K^T P^T = 0 \\ \Rightarrow &P K_0 (K P)^T = 0 \\ \Rightarrow & P K_0 = 0 \end{align*}
AlphaEdit优化
基于ROME/EMMIT工作,K_0K_0\^T可通过计算10万条数据获得,即可进一步获得映射矩阵P。有了P,优化就无需再考虑原有知识K_0,则AlphaEdit将优化式改为:
\\Delta = \\arg \\min\\limits_{\\tilde{\\Delta}} \\left( \\left\\\| (W + \\tilde{\\Delta} P) K_1 - V_1 \\right\\\|\^2 + \\left\\\| \\tilde{\\Delta} P \\right\\\|\^2 +\\left\\\| \\tilde{\\Delta} P K_p\\right\\\|\^2\\right)
其中第二项控制\\Delta的范数,避免数值过大,第三项额外考虑终身编辑场景中已编辑的知识(K_p,V_p)。原始MEMIT没有考虑第三项。求导得到方程:
(\\Delta PK_1 - R)K_1\^T P + \\Delta P + \\Delta PK_p K_p\^T P = 0
其中R=V_1 −WK_1表示新值V_1与原始矩阵在新键下的残差。可得AlphaEdit的矩阵变化量\\Delta_\\text{AlphaEdit}为:
\\Delta_\\text{AlphaEdit} =\\Delta P = R K_1\^T P \\left( K_p K_p\^T P + K_1 K_1\^T P + I \\right)\^{-1}
MEMIT的原始闭式解如下所示(额外考虑了已编辑知识),文中表明,仅仅这里改动一行代码,产生较好的编辑性能。
\\Delta_{\\text{MEMIT}} = R K_1\^T \\left( K_p K_p\^T P + K_1 K_1\^T + K_0 K_0\^T \\right)\^{-1}
实验
表1:2000条知识的编辑实验,AlphaEdit的编辑批量为100,编辑20次。
图5:token表示分布偏移对比。
其它图表:一些对比和增强效果。