文章目录
- 简介
- 一、address_space
-
- [1.1 address_space](#1.1 address_space)
- [1.2 struct page](#1.2 struct page)
- [1.3 基数树](#1.3 基数树)
-
- [1.3.1 radix_tree_root](#1.3.1 radix_tree_root)
- [1.3.2 radix_tree_node](#1.3.2 radix_tree_node)
- 二、find_get_page
-
- [2.1 find_get_page用到场景](#2.1 find_get_page用到场景)
-
- [2.1.1 generic_file_buffered_read](#2.1.1 generic_file_buffered_read)
- [2.1.2 filemap_fault](#2.1.2 filemap_fault)
-
- [2.1.2.1 file mmap](#2.1.2.1 file mmap)
- [2.1.2.2 file filemap_fault](#2.1.2.2 file filemap_fault)
- [2.1.3 do_read_cache_page](#2.1.3 do_read_cache_page)
- [2.2 pagecache_get_page](#2.2 pagecache_get_page)
-
- [2.2.1 __page_cache_alloc](#2.2.1 __page_cache_alloc)
- [2.2.2 add_to_page_cache_lru](#2.2.2 add_to_page_cache_lru)
- 三、相应数据结构关系图
简介
这篇文章介绍了page cache:Linux 内存管理之page cache,接下来介绍 page cache 的管理数据结构 address_space。
一、address_space
1.1 address_space
在Linux内核中,struct address_space是用于管理文件系统中的文件页缓存(page cache)和内存映射(Memory Mapping)文件的数据结构,主要用于文件系统和块设备的缓存管理。
一个address_space管理了一个文件在内存中缓存的所有pages,这部分缓存也是页高速缓存。address_space将属于同一文件的page联系起来,将这些page的操作方法与文件所属的文件系统联系起来。
大量子系统(文件系统、页交换、同步、缓存)都围绕地址空间的概念展开。因而,这个概念可以认为是内核最根本的抽象机制之一,以重要性而论,该抽象可跻身于传统抽象如进程、文件之列。
c
// v4.15/source/include/linux/fs.h
struct address_space {
struct inode *host; /* owner: inode, block_device */
struct radix_tree_root page_tree; /* radix tree of all pages */
spinlock_t tree_lock; /* and lock protecting it */
atomic_t i_mmap_writable;/* count VM_SHARED mappings */
struct rb_root_cached i_mmap; /* tree of private and shared mappings */
struct rw_semaphore i_mmap_rwsem; /* protect tree, count, list */
/* Protected by tree_lock together with the radix tree */
unsigned long nrpages; /* number of total pages */
/* number of shadow or DAX exceptional entries */
unsigned long nrexceptional;
pgoff_t writeback_index;/* writeback starts here */
const struct address_space_operations *a_ops; /* methods */
unsigned long flags; /* error bits */
spinlock_t private_lock; /* for use by the address_space */
gfp_t gfp_mask; /* implicit gfp mask for allocations */
struct list_head private_list; /* for use by the address_space */
void *private_data; /* ditto */
errseq_t wb_err;
} __attribute__((aligned(sizeof(long)))) __randomize_layout;address_space 作为文件(owner)与内存页的中间层,管理文件对应的所有缓存页。在page cache中,page cache中的每个page都有对应的文件,这个文件就是这个page的owner,address_space将属于同一owner的pages联系起来。
(1)struct inode *host:指向所属的 inode 或 block_device,标识缓存的所有者(如文件或块设备)。
(2)struct radix_tree_root page_tree:基数树,存储所有缓存的物理页(struct page),用于快速按偏移查找。通过 page_tree(基数树)根据文件偏移快速定位缓存页。
Linux 4.20 以后的内核版本使用 xarray 管理 page cache。
(3)atomic_t i_mmap_writable:统计共享内存映射(VM_SHARED)的数量。
(4)struct rb_root_cached i_mmap:红黑树,管理所有内存映射(包括私有和共享的 VMA)。通过 i_mmap 红黑树快速找到所有映射该文件的进程(用于内存回收等)。
(5)unsigned long nrpages:当前缓存的页数,受 tree_lock 保护。
(6)pgoff_t writeback_index:标记下次回写(Writeback)的起始文件偏移。
(7)const struct address_space_operations *a_ops:定义文件系统对页缓存的操作(如 readpage、writepage)。
1.2 struct page
c
struct page {
struct address_space *mapping;
pgoff_t index; /* Our offset within mapping. */
}mapping:指向所属文件的 address_space。
index:表示该页在文件中的逻辑偏移(如文件第3页对应 index=2)。
与地址空间所管理的区域之间的关联,是通过以下两个成员建立的:一个指向inode实例(类型为struct inode)的指针指定了后备存储器,一个基数树的根(page_tree)列出了地址空间中所有的物理内存页。
1.3 基数树
内核使用了基数树来管理与一个地址空间相关的所有页。
基数树最广泛的用途是在内存管理代码中。用于跟踪后备存储的address_space结构包含一个基数树,用于跟踪与该映射关联的核心页面。除此之外,该树还允许内存管理代码快速查找脏页或正在写回的页等功能。
从大量数据的集合(页缓存)中快速获取单个数据元素(页),Linux也采用了基数树这种结构来管理页缓存中包含的页。
1.3.1 radix_tree_root
根据address_space的定义,我们很清楚radix_tree_root结构是每个基数树的的根结点:
c
/* root tags are stored in gfp_mask, shifted by __GFP_BITS_SHIFT */
struct radix_tree_root {
unsigned int height;
gfp_t gfp_mask;
struct radix_tree_node __rcu *rnode;
};(1)height指定了树的高度,即根结点之下结点的层次数目。根据该信息和每个结点的项数,内
核可以快速计算给定树中数据项的最大数目。如果没有足够的空间容纳新数据,可以据此对
树进行扩展。
(2)gfp_mask指定了从哪个内存域分配内存。
(3)rnode是一个指针,指向树的第一个结点。该结点的数据类型是radix_tree_node。
1.3.2 radix_tree_node
基数树的结点基本上由以下数据结构表示:
c
#define RADIX_TREE_MAP_SHIFT (CONFIG_BASE_SMALL ? 4 : 6)
#define RADIX_TREE_MAP_SIZE (1UL << RADIX_TREE_MAP_SHIFT)
#define RADIX_TREE_MAP_MASK (RADIX_TREE_MAP_SIZE-1)
#define RADIX_TREE_TAG_LONGS \
((RADIX_TREE_MAP_SIZE + BITS_PER_LONG - 1) / BITS_PER_LONG)
struct radix_tree_node {
unsigned int height; /* Height from the bottom */
unsigned int count;
union {
struct radix_tree_node *parent; /* Used when ascending tree */
struct rcu_head rcu_head; /* Used when freeing node */
};
void __rcu *slots[RADIX_TREE_MAP_SIZE];
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
};(1)slots
是一个void指针的数组,根据结点所在的层次,指向数据或其他结点。
每个树结点都可以进一步指向64个结点(或叶子),根据radix_tree_node中的slots数组可以
推断。该定义的直接后果是,每个结点中的数组长度都只能为2的幂。另外,基数树结点的大小只能在编译时定义(当然,树中结点的最大数目可以在运行时修改)。
(2)count
保存了该结点中已经使用的数组项的数目。各数组项从头开始填充,未使用的项
为NULL指针。
(3)tags
linux中radix tree的每个slot除了存放指针,还存放着标志page和磁盘文件同步状态的tag。如果page cache中一个page在内存中被修改后没有同步到磁盘,就说这个page是dirty的,此时tag就是PAGE_CACHE_DIRTY。如果正在同步,tag就是PAGE_CACHE_WRITEBACK。
包括地址空间和页树,但这些并不能让内核直接区分映射的干净页和脏页。在某些时候这种区分是本质性的,例如在将页回写到后备存储器、永久修改底层块设备上的数据时。早期的内核版本在address_space中提供了额外的链表,来列出脏页和干净页。原则上,内核当然可以扫描整个树,并过滤出具备适当状态的页,但这显然非常耗时。为此,基数树的每个结点都包含了额外的标记信息,用于指定结点中的每个页是否具有标记中指定的属性。例如,内核对带有脏页的结点使用了一个标记。在扫描脏页期间,没有该标记的结点即可跳过。这种方案是在简单、统一的数据结构(不需要显式的链表来保存不同状态的页)与快速搜索具备特定性质的页的方案之间的一个折中。
内核可以据此快速判断某个区域中是否有dirty page或正在write back的page,而无须扫描该区域中的所有pages。
当前支持如下三种标记:
c
#define RADIX_TREE_MAX_TAGS 3
c
/*
* Radix-tree tags, for tagging dirty and writeback pages within the pagecache
* radix trees
*/
#define PAGECACHE_TAG_DIRTY 0
#define PAGECACHE_TAG_WRITEBACK 1
#define PAGECACHE_TAG_TOWRITE 2(1)PAGECACHE_TAG_DIRTY:用于标记脏页,即已经被修改但尚未同步到存储介质上的页面。
(2)PAGECACHE_TAG_WRITEBACK:用于标记正在进行写回操作的页,即已经触发了将脏页写回到存储介质的操作,但尚未完成。
(3)PAGECACHE_TAG_TOWRITE:用于标记待写入页,即需要将脏页写回到存储介质的页面。
Tags是一个二维数组,RADIX_TREE_MAX_TAGS为3代表的是3种tag类型,RADIX_TREE_TAG_LONGS定义slot数占用的long类型长度个数。加入这个值为64,也就是3*64的数组,这样每一行代表一种tag的集合,假如tag0代表PAGE_CACHE_DIRTY,假如我们查到当前节点的tags0值为1,那么它的子树节点就存在PAGE_CACHE_DIRTY节点,在我们查找PG_dirty的页面时,就不用遍历整个树了,可以提高查找效率。
标记信息保存在一个二维数组中(tags),它是radix_tree_node的一部分。数组的第一维区分不同的标记,而第二维包含了足够数量的unsigned long,使得对该结点中可能组织的每个页,都能分配到一个比特位。
这些标签可以在页缓存的基数树中的节点上进行设置和查询,以便标记和跟踪页面的状态。通过使用这些标签,可以更有效地管理页缓存中的脏页和写回页,以提高文件系统的性能和数据一致性。
radix_tree_tag_set用于对一个特定的页设置一个标志:
c
void *radix_tree_tag_set(struct radix_tree_root *root,
unsigned long index, unsigned int tag);内核在位串中操作对应的位置,并将该比特位设置为1。在完成后,将自上而下扫描树,更新所有结点中的信息。为查找所有具备特定标记的页,内核仍然必须扫描整个树,但该操作现在可以被加速,首先可以过滤出至少有一页设置了该标志的所有子树。另外,这个操作还可以进一步加速,内核实际上无须逐比特位检查,只需要检查存储该标记的unsigned long中,是否有某个不为0即可。
Tag 与 Page Flags 的关系:
| Radix Tree Tag | Page Flag | 用途 |
|---|---|---|
| PAGECACHE_TAG_DIRTY | PG_dirty | 标识页内容已修改 |
| PAGECACHE_TAG_WRITEBACK | PG_writeback | 标识页正在回写磁盘 |
为什么需要双重标记?
Radix Tree Tag:快速扫描大范围页状态(如 find_get_pages_tag())
Page Flag:原子操作单个页状态(如 TestClearPageDirty())
radix tree加上tag标记为了管理的方便,内核可以据此快速判断某个区域中是否有dirty page或正在write back的page,而无须扫描该区域中的所有pages。
二、find_get_page
c
// v4.15/source/include/linux/pagemap.h
/**
* find_get_page - find and get a page reference
* @mapping: the address_space to search
* @offset: the page index
*
* Looks up the page cache slot at @mapping & @offset. If there is a
* page cache page, it is returned with an increased refcount.
*
* Otherwise, %NULL is returned.
*/
static inline struct page *find_get_page(struct address_space *mapping,
pgoff_t offset)
{
return pagecache_get_page(mapping, offset, 0, 0);
}find_get_page() 这个函数是用于查找并获取页缓存(page cache)中某个页面的引用,用于在给定的地址空间(address_space)中,根据页面偏移量(offset)查找对应的缓存页。
mapping的获取:
c
struct address_space *mapping = file->f_mapping
c
struct inode *inode = file_inode(file);
struct address_space *mapping = inode->i_mapping;2.1 find_get_page用到场景
2.1.1 generic_file_buffered_read
c
/**
* generic_file_read_iter - generic filesystem read routine
* @iocb: kernel I/O control block
* @iter: destination for the data read
*
* This is the "read_iter()" routine for all filesystems
* that can use the page cache directly.
*/
ssize_t
generic_file_read_iter(struct kiocb *iocb, struct iov_iter *iter)
{
generic_file_buffered_read(iocb, iter, retval);
}
c
/**
* generic_file_buffered_read - generic file read routine
* @iocb: the iocb to read
* @iter: data destination
* @written: already copied
*
* This is a generic file read routine, and uses the
* mapping->a_ops->readpage() function for the actual low-level stuff.
*
* This is really ugly. But the goto's actually try to clarify some
* of the logic when it comes to error handling etc.
*/
static ssize_t generic_file_buffered_read(struct kiocb *iocb,
struct iov_iter *iter, ssize_t written)
{
struct file *filp = iocb->ki_filp;
struct address_space *mapping = filp->f_mapping;
struct inode *inode = mapping->host;
for (;;) {
struct page *page;
pgoff_t end_index;
loff_t isize;
page = find_get_page(mapping, index);
if (!page) {
if (iocb->ki_flags & IOCB_NOWAIT)
goto would_block;
page_cache_sync_readahead(mapping,
ra, filp,
index, last_index - index);
page = find_get_page(mapping, index);
if (unlikely(page == NULL))
goto no_cached_page;
}
if (PageReadahead(page)) {
page_cache_async_readahead(mapping,
ra, filp, page,
index, last_index - index);
}
/*
* Ok, we have the page, and it's up-to-date, so
* now we can copy it to user space...
*/
ret = copy_page_to_iter(page, offset, nr, iter);
}
......
no_cached_page:
/*
* Ok, it wasn't cached, so we need to create a new
* page..
*/
page = page_cache_alloc(mapping);
if (!page) {
error = -ENOMEM;
goto out;
}
error = add_to_page_cache_lru(page, mapping, index,
mapping_gfp_constraint(mapping, GFP_KERNEL));
if (error) {
put_page(page);
if (error == -EEXIST) {
error = 0;
goto find_page;
}
goto out;
}
goto readpage;
}
}这段代码是 Linux 内核中 generic_file_buffered_read() 函数的简化版,主要用于实现缓冲文件读取(buffered I/O)。
(1)内核首先尝试从页缓存中直接读取数据(find_get_page),避免磁盘 I/O。
如果页不存在(!page),触发同步预读(page_cache_sync_readahead),预加载后续数据到缓存。
同步预读:当缓存未命中时,立即加载当前页和后续若干页。
如果同步预读(page_cache_sync_readahead)还是没有找到,则 跳往 no_cached_page,调用 page_cache_alloc分配一个新的page。
(2)如果第一次找缓存页就找到了,我们还是要判断,是不是应该继续预读;如果需要,就调用 page_cache_async_readahead 发起一个异步预读。
如果发现页标记了 PageReadahead,说明访问模式是顺序读取,后台异步预读更多数据(page_cache_async_readahead)。
page_cache_sync/async_readahead
(1)page_cache_sync_readahead:同步预读,在缓存未命中(需要读取新数据)时触发,直接提交读请求。同步执行,可能阻塞当前操作(等待 I/O)。
关键逻辑:
直接处理缓存未命中的请求。
根据访问模式(随机 / 顺序)选择不同的预读策略。
触发时机:缓存未命中(cache miss)时触发,即需要读取的数据不在页缓存中。
执行方式:同步执行,直接提交读请求,可能阻塞当前操作等待 I/O 完成。
预读目标:足当前读取请求,并预读少量后续数据。
应用场景:顺序读取或随机读取的初始阶段。
(2)page_cache_async_readahead:异步预读,当已预读的页面被使用(且标记了PG_readahead)时触发,提前加载更多数据,不阻塞当前操作。异步执行,不阻塞当前操作。
关键逻辑:
当页面的 PG_readahead 标记被触发时,表明应用正在快速消耗预读数据,需启动新一轮预读。
检查页面状态和系统负载,避免在不合适的时机预读。
触发时机:当已预读的页面被使用(且设置了 PG_readahead 标记)时触发。
执行方式:异步执行,不阻塞当前操作,在后台预读后续数据。
预读目标:预测未来可能需要的数据,提前加载到页缓存中。
应用场景:顺序读取的持续阶段(如大文件连续读取)。
这两个函数通过 ondemand_readahead 函数实现预读窗口的动态调整:
(1)顺序访问模式:
初始读取时,sync_readahead 触发,预读少量数据(如 1-2 页)。
当应用快速消耗这些预读页时,async_readahead 被触发,预读窗口按指数级增长(如 2 → 4 → 8 页)。
(2)随机访问模式:
sync_readahead 检测到随机访问标志(FMODE_RANDOM),仅预读当前请求所需的数据,不扩展预读窗口。
async_readahead 几乎不会被触发,避免无效预读。
2.1.2 filemap_fault
2.1.2.1 file mmap
(1)建立起虚拟地址内存到文件的映射关系。
c
SYSCALL_DEFINE6(mmap_pgoff
-->vm_mmap_pgoff()
-->do_mmap_pgoff()
-->do_mmap()
-->get_unmapped_area()
{
get_area = current->mm->get_unmapped_area;
if (file) {
if (file->f_op->get_unmapped_area)
get_area = file->f_op->get_unmapped_area;
}
-->mmap_region()调用 get_unmapped_area 找到一个没有映射的虚拟地址区域;
调用 mmap_region 映射这个虚拟地址区域。
(2)用户态缺页异常
一旦开始访问虚拟内存的某个地址,如果我们发现,并没有对应的物理页,那就触发缺页中断,调用 do_page_fault。
c
do_page_fault()
-->__do_page_fault()
-->handle_mm_fault()
-->__handle_mm_fault()
-->handle_pte_fault()handle_pte_fault有三种情况:
do_anonymous_page:匿名页的映射
do_fault:文件映射
do_swap_page:swap映射
这里我们只看 do_fault:文件映射。
c
do_fault()
-->__do_fault()
{
vma->vm_ops->fault(vmf);
}mmap 映射文件的时候,对于 ext4 文件系统,vm_ops 指向了 ext4_file_vm_ops,也就是调用了 ext4_filemap_fault。
c
static const struct vm_operations_struct ext4_file_vm_ops = {
.fault = ext4_filemap_fault,
.map_pages = filemap_map_pages,
.page_mkwrite = ext4_page_mkwrite,
};
int ext4_filemap_fault(struct vm_fault *vmf)
{
struct inode *inode = file_inode(vmf->vma->vm_file);
......
err = filemap_fault(vmf);
......
return err;
}2.1.2.2 file filemap_fault
c
/**
* filemap_fault - read in file data for page fault handling
* @vmf: struct vm_fault containing details of the fault
*
* filemap_fault() is invoked via the vma operations vector for a
* mapped memory region to read in file data during a page fault.
*
* The goto's are kind of ugly, but this streamlines the normal case of having
* it in the page cache, and handles the special cases reasonably without
* having a lot of duplicated code.
*
* vma->vm_mm->mmap_sem must be held on entry.
*
* If our return value has VM_FAULT_RETRY set, it's because
* lock_page_or_retry() returned 0.
* The mmap_sem has usually been released in this case.
* See __lock_page_or_retry() for the exception.
*
* If our return value does not have VM_FAULT_RETRY set, the mmap_sem
* has not been released.
*
* We never return with VM_FAULT_RETRY and a bit from VM_FAULT_ERROR set.
*/
int filemap_fault(struct vm_fault *vmf)
{
int error;
struct file *file = vmf->vma->vm_file;
struct address_space *mapping = file->f_mapping;
struct inode *inode = mapping->host;
pgoff_t offset = vmf->pgoff;
struct page *page;
int ret = 0;
......
page = find_get_page(mapping, offset);
if (likely(page) && !(vmf->flags & FAULT_FLAG_TRIED)) {
do_async_mmap_readahead(vmf->vma, ra, file, page, offset);
} else if (!page) {
goto no_cached_page;
}
......
vmf->page = page;
return ret | VM_FAULT_LOCKED;
no_cached_page:
error = page_cache_read(file, offset, vmf->gfp_mask);
......
}这段代码是 Linux 内核中处理文件内存映射(mmap)缺页异常的核心函数 filemap_fault(),属于虚拟内存子系统(VFS)的关键路径。它的作用是在进程访问文件映射区域触发 缺页异常(page fault) 时,将文件数据加载到物理内存。
(1)find_get_page
find_get_page 优先从页缓存查找目标页,避免磁盘 I/O。当首次命中页缓存时,调用do_async_mmap_readahead,后台异步预读后续文件内容(基于局部性原理),减少后续缺页异常的开销。
如果没有找到跳到 no_cached_page ,调用 page_cache_read。
do_async_mmap_readahead最常见的场景是处理文件支持的页面的缺页异常 (handle_mm_fault -> filemap_fault)。
(2)page_cache_read
c
/**
* page_cache_read - adds requested page to the page cache if not already there
* @file: file to read
* @offset: page index
* @gfp_mask: memory allocation flags
*
* This adds the requested page to the page cache if it isn't already there,
* and schedules an I/O to read in its contents from disk.
*/
static int page_cache_read(struct file *file, pgoff_t offset, gfp_t gfp_mask)
{
struct address_space *mapping = file->f_mapping;
struct page *page;
int ret;
do {
page = __page_cache_alloc(gfp_mask);
if (!page)
return -ENOMEM;
ret = add_to_page_cache_lru(page, mapping, offset, gfp_mask & GFP_KERNEL);
if (ret == 0)
ret = mapping->a_ops->readpage(file, page);
else if (ret == -EEXIST)
ret = 0; /* losing race to add is OK */
put_page(page);
} while (ret == AOP_TRUNCATED_PAGE);
return ret;
}__page_cache_alloc:从内核内存分配器获取一个干净的页框。
add_to_page_cache_lru:将页插入页缓存和 LRU 链表。
然后在 address_space 中调用 address_space_operations 的 readpage 函数,将文件内容读到内存中。
struct address_space_operations 对于 ext4 文件系统的定义如下所示。这么说来,上面的 readpage 调用的其实是 ext4_readpage。
c
static const struct address_space_operations ext4_aops = {
.readpage = ext4_readpage,
.readpages = ext4_readpages,
......
};
2.1.3 do_read_cache_page
暂无。
2.2 pagecache_get_page
c
// v4.15/source/mm/filemap.c
/**
* pagecache_get_page - find and get a page reference
* @mapping: the address_space to search
* @offset: the page index
* @fgp_flags: PCG flags
* @gfp_mask: gfp mask to use for the page cache data page allocation
*
* Looks up the page cache slot at @mapping & @offset.
*
* PCG flags modify how the page is returned.
*
* @fgp_flags can be:
*
* - FGP_ACCESSED: the page will be marked accessed
* - FGP_LOCK: Page is return locked
* - FGP_CREAT: If page is not present then a new page is allocated using
* @gfp_mask and added to the page cache and the VM's LRU
* list. The page is returned locked and with an increased
* refcount. Otherwise, NULL is returned.
*
* If FGP_LOCK or FGP_CREAT are specified then the function may sleep even
* if the GFP flags specified for FGP_CREAT are atomic.
*
* If there is a page cache page, it is returned with an increased refcount.
*/
struct page *pagecache_get_page(struct address_space *mapping, pgoff_t offset,
int fgp_flags, gfp_t gfp_mask)
{
struct page *page;
repeat:
page = find_get_entry(mapping, offset);
if (radix_tree_exceptional_entry(page))
page = NULL;
if (!page)
goto no_page;
if (fgp_flags & FGP_LOCK) {
if (fgp_flags & FGP_NOWAIT) {
if (!trylock_page(page)) {
put_page(page);
return NULL;
}
} else {
lock_page(page);
}
/* Has the page been truncated? */
if (unlikely(page->mapping != mapping)) {
unlock_page(page);
put_page(page);
goto repeat;
}
VM_BUG_ON_PAGE(page->index != offset, page);
}
if (page && (fgp_flags & FGP_ACCESSED))
mark_page_accessed(page);
no_page:
if (!page && (fgp_flags & FGP_CREAT)) {
int err;
if ((fgp_flags & FGP_WRITE) && mapping_cap_account_dirty(mapping))
gfp_mask |= __GFP_WRITE;
if (fgp_flags & FGP_NOFS)
gfp_mask &= ~__GFP_FS;
page = __page_cache_alloc(gfp_mask);
if (!page)
return NULL;
if (WARN_ON_ONCE(!(fgp_flags & FGP_LOCK)))
fgp_flags |= FGP_LOCK;
/* Init accessed so avoid atomic mark_page_accessed later */
if (fgp_flags & FGP_ACCESSED)
__SetPageReferenced(page);
err = add_to_page_cache_lru(page, mapping, offset,
gfp_mask & GFP_RECLAIM_MASK);
if (unlikely(err)) {
put_page(page);
page = NULL;
if (err == -EEXIST)
goto repeat;
}
}
return page;
}
EXPORT_SYMBOL(pagecache_get_page);
c
// v4.15/source/include/linux/pagemap.h
#define FGP_ACCESSED 0x00000001
#define FGP_LOCK 0x00000002
#define FGP_CREAT 0x00000004
#define FGP_WRITE 0x00000008
#define FGP_NOFS 0x00000010
#define FGP_NOWAIT 0x00000020(1)页面查找阶段
c
repeat:
page = find_get_entry(mapping, offset); // 查找页缓存条目
if (radix_tree_exceptional_entry(page)) // 特殊条目处理
page = NULL;
if (!page)
goto no_page; // 未找到跳转(2)页面存在时的处理
c
// 锁定处理
if (fgp_flags & FGP_LOCK) {
if (fgp_flags & FGP_NOWAIT) {
if (!trylock_page(page)) { // 非阻塞尝试锁
put_page(page);
return NULL;
}
} else {
lock_page(page); // 阻塞锁定
}
// 检查页面截断
if (unlikely(page->mapping != mapping)) {
unlock_page(page);
put_page(page);
goto repeat; // 重新查找
}
VM_BUG_ON_PAGE(page->index != offset, page); // 调试检查
}
// 标记访问状态
if (page && (fgp_flags & FGP_ACCESSED))
mark_page_accessed(page); // 更新访问状态当页面被访问时,内核调用 mark_page_accessed(),mark_page_accessed() 函数负责管理页面的活跃状态标记(PG_referenced 和 PG_active)。
标记页面为"被访问过",参与 LRU 链表的活跃度管理。
关键行为:
若页面首次被访问,设置 PG_referenced 标志。
对应状态转换:inactive,unreferenced → inactive,referenced。
若页面已被访问过(PG_referenced 已设置)且可回收,则将其激活(移到 Active List)。
对应状态转换:inactive,referenced → active,unreferenced。
(3)页面不存在时的创建处理
c
no_page:
if (!page && (fgp_flags & FGP_CREAT)) {
// 调整分配标志
if ((fgp_flags & FGP_WRITE) && mapping_cap_account_dirty(mapping))
gfp_mask |= __GFP_WRITE; // 可写页面优化
if (fgp_flags & FGP_NOFS)
gfp_mask &= ~__GFP_FS; // 禁止文件系统操作
page = __page_cache_alloc(gfp_mask); // 分配新页
if (!page)
return NULL;
// 安全保护:确保新页被锁定
if (WARN_ON_ONCE(!(fgp_flags & FGP_LOCK)))
fgp_flags |= FGP_LOCK;
// 预标记访问状态
if (fgp_flags & FGP_ACCESSED)
__SetPageReferenced(page);
// 添加到页缓存
err = add_to_page_cache_lru(page, mapping, offset,
gfp_mask & GFP_RECLAIM_MASK);
if (unlikely(err)) {
put_page(page);
page = NULL;
if (err == -EEXIST) // 处理竞争条件
goto repeat; // 页面已被其他线程创建
}
}如果在page cache中未找到,就会触发page fault,然后调用__page_cache_alloc在内存中分配若干物理页面,最后将数据从磁盘对应位置复制到内存;
调用__page_cache_alloc分配一个新的page,然后调用add_to_page_cache_lru将其加入到缓存page cache 和 LRU链表里面。
2.2.1 __page_cache_alloc
c
#ifdef CONFIG_NUMA
struct page *__page_cache_alloc(gfp_t gfp)
{
int n;
struct page *page;
if (cpuset_do_page_mem_spread()) {
unsigned int cpuset_mems_cookie;
do {
cpuset_mems_cookie = read_mems_allowed_begin();
n = cpuset_mem_spread_node();
page = __alloc_pages_node(n, gfp, 0);
} while (!page && read_mems_allowed_retry(cpuset_mems_cookie));
return page;
}
return alloc_pages(gfp, 0);
}
EXPORT_SYMBOL(__page_cache_alloc);
#endif调用__alloc_pages_node/alloc_pages 分配新的页。
2.2.2 add_to_page_cache_lru
c
int add_to_page_cache_lru(struct page *page, struct address_space *mapping,
pgoff_t offset, gfp_t gfp_mask)
{
void *shadow = NULL;
int ret;
__SetPageLocked(page);
ret = __add_to_page_cache_locked(page, mapping, offset,
gfp_mask, &shadow);
if (unlikely(ret))
__ClearPageLocked(page);
else {
/*
* The page might have been evicted from cache only
* recently, in which case it should be activated like
* any other repeatedly accessed page.
* The exception is pages getting rewritten; evicting other
* data from the working set, only to cache data that will
* get overwritten with something else, is a waste of memory.
*/
if (!(gfp_mask & __GFP_WRITE) &&
shadow && workingset_refault(shadow)) {
SetPageActive(page);
workingset_activation(page);
} else
ClearPageActive(page);
lru_cache_add(page);
}
return ret;
}
EXPORT_SYMBOL_GPL(add_to_page_cache_lru);add_to_page_cache_lru 是 Linux 内存管理核心函数,负责将新分配的页面添加到页缓存(page cache)并纳入 LRU链表管理。
这个函数就说明 page cache 在两个数据结构里面管理:
(1)address_space里的基数树(高版本变为xarray)
c
static int __add_to_page_cache_locked(struct page *page,
struct address_space *mapping,
pgoff_t offset, gfp_t gfp_mask,
void **shadowp)
{
......
get_page(page);
page->mapping = mapping;
page->index = offset;
......
page_cache_tree_insert(mapping, page, shadowp);
.......
}__add_to_page_cache_locked 执行实际的基数树插入操作。
(2)LRU链表
c
/**
* lru_cache_add - add a page to a page list
* @page: the page to be added to the LRU.
*
* Queue the page for addition to the LRU via pagevec. The decision on whether
* to add the page to the [in]active [file|anon] list is deferred until the
* pagevec is drained. This gives a chance for the caller of lru_cache_add()
* have the page added to the active list using mark_page_accessed().
*/
void lru_cache_add(struct page *page)
{
VM_BUG_ON_PAGE(PageActive(page) && PageUnevictable(page), page);
VM_BUG_ON_PAGE(PageLRU(page), page);
__lru_cache_add(page);
}
c
static void __lru_cache_add(struct page *page)
{
struct pagevec *pvec = &get_cpu_var(lru_add_pvec);
get_page(page);
if (!pagevec_add(pvec, page) || PageCompound(page))
__pagevec_lru_add(pvec);
put_cpu_var(lru_add_pvec);
}将page cache添加到LRU链表。
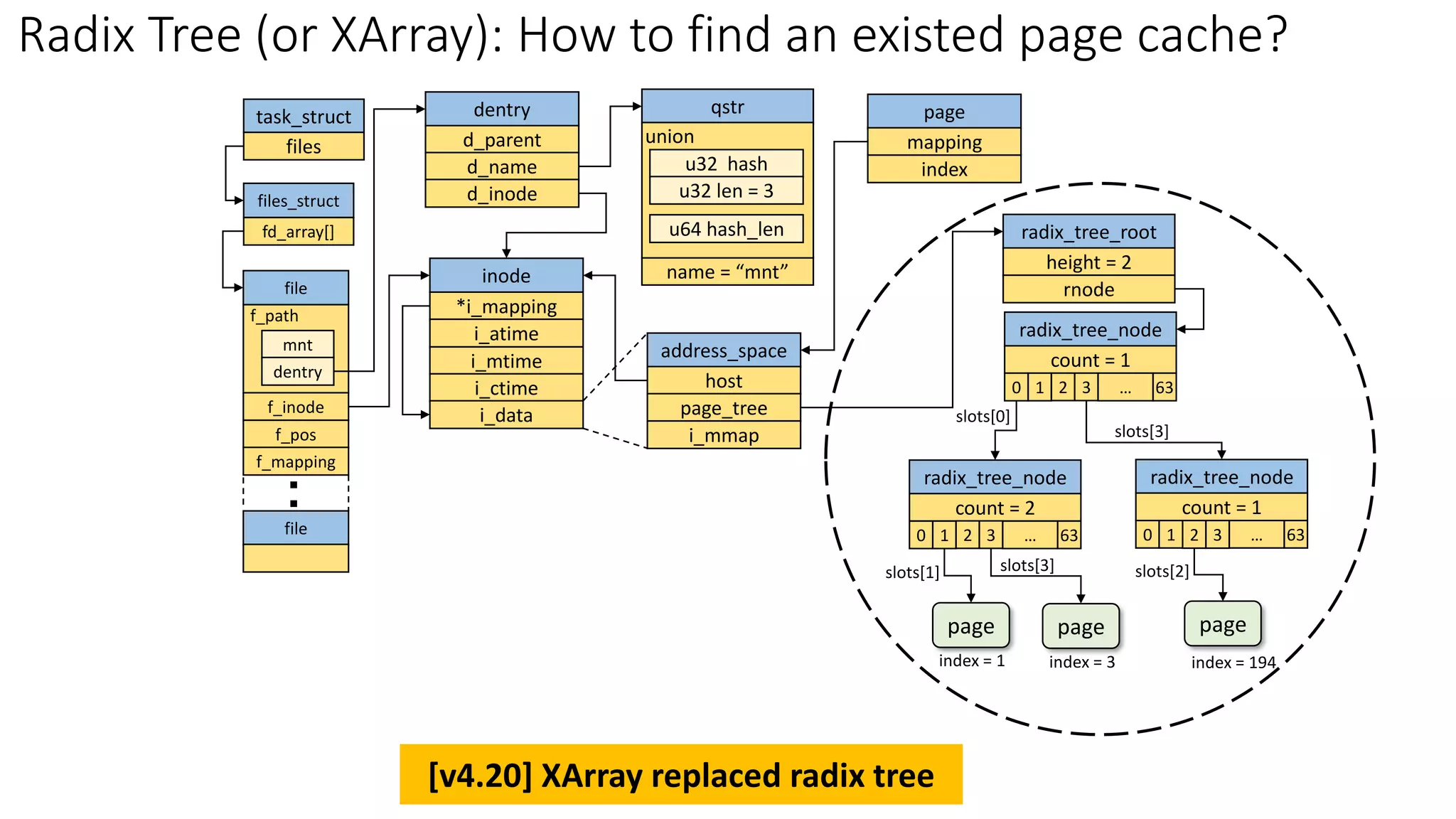
三、相应数据结构关系图
1、每个adrres_space对象对应一颗搜索树。他们之间的联系是通过address_space对象中的page_tree字段指向该address_space对象对应的基树。
c
struct address_space {
......
struct radix_tree_root page_tree; /* radix tree of all pages */
......
}2、一个inode节点对应一个address_space对象,其中inode节点对象的i_mapping和i_data字段指向相应的 address_space对象,而address_space对象的host字段指向对应的inode节点对象。
c
struct inode {
......
struct address_space *i_mapping;
......
struct address_space i_data;
......
}
c
struct address_space {
struct inode *host; /* owner: inode, block_device */
......
}索引节点的i_mapping字段总是指向索引节点的数据页所有者的address_space对象,address_space对象的host字段指向其所有者的索引节点对象。
因此,如果页属于一个文件(保存在ext4文件系统中),那么页的所有者就是文件的索引节点,而且相应的address_space对象存放在VFS索引节点对象的i_data字段中。索引节点的i_mapping字段指向同一个索引节点的i_data字段,而address_space对象的host字段也只想索引节点。
3、一般情况下一个inode节点对象对应的文件或者是块设备都会包含多个页面的内容,所以一个inode对象对应多个page描述符。同一个文件拥有的所有page描述符都可以在该文件对应的基树中找到。
c
struct page {
/* First double word block */
......
struct address_space *mapping; /* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
......mapping指定了页帧所在的地址空间address_space。地址空间用于将文件的内容(数据)与装载数据的内存区关联起来。通过一个小技巧,mapping不仅能够保存一个指针,而且还能包含一些额外的信息,用于判断页是否属于未关联到地址空间的某个匿名内存区。如果将mapping置为1,则该指针并不指向address_space的实例,而是指向另一个数据结构(anon_vma),该结构对实现匿名页的逆向映射很重要。对该指针的双重使用是可能的,因为address_space实例总是对齐到sizeof(long)。因此在Linux支持的所有计算机上,指向该实例的指针最低位总是0。该指针如果指向address_space实例,则可以直接使用。如果使用了技巧将最低位设置为1,内核可使用下列操作恢复来恢复指针:
anon_vma = (struct anon_vma *) (mapping -PAGE_MAPPING_ANON)
它们之间的关系如下图: