文章目录
- [1 Softmax回归](#1 Softmax回归)
-
- [1.1 分类 vs 回归](#1.1 分类 vs 回归)
- [1.2 从回归到分类](#1.2 从回归到分类)
- [1.3 Softmax函数](#1.3 Softmax函数)
- [1.4 交叉熵损失(Cross-Entropy)](#1.4 交叉熵损失(Cross-Entropy))
- [2 经典损失函数](#2 经典损失函数)
-
- [2.1 均方误差(MSE / L2 Loss)](#2.1 均方误差(MSE / L2 Loss))
- [2.2 绝对值误差(MAE / L1 Loss)](#2.2 绝对值误差(MAE / L1 Loss))
- [2.3 Huber Loss(鲁棒损失)](#2.3 Huber Loss(鲁棒损失))
- [3 图像分类数据集](#3 图像分类数据集)
-
- [3.1 读取数据集](#3.1 读取数据集)
- [3.2 读取小批量](#3.2 读取小批量)
- [4 softmax回归的简洁实现](#4 softmax回归的简洁实现)
硬件配置:
- Windows 11 + WLS2 + Ubuntu-24.04
- Intel®Core™i7-12700H
- NVIDIA GeForce RTX 3070 Ti Laptop GPU
软件环境:
- Pycharm 2025.1.3.1
- Python 3.13.5
- Pytorch 2.7.1+cu128

1 Softmax回归
1.1 分类 vs 回归
- 回归:预测连续值(如房价),输出为单值,损失函数通常用均方误差(MSE)。
- 分类:预测离散类别(如猫/狗),输出为多值(每个类别对应一个置信度),损失函数常用交叉熵。

多分类问题示例
- MNIST:10类手写数字识别(0-9)。
- ImageNet:1000类自然物体分类(含100种狗)。

-
其他应用:
-
蛋白质分类(28 类显微镜图像)。
-
恶意软件检测(多类别分类)。

-
文本情感分类(如 Wikipedia 评论的 7 类恶意性判断)。
-
1.2 从回归到分类
类别编码:One-Hot编码
- 对于 N 个类别,标签 Y 为长度为 N 的向量,真实类别对应位置为 1,其余为 0。
- 示例:3 分类问题,类别 2 的编码为
[0, 1, 0]。

扩展回归的局限性
- 问题:直接对多输出使用 MSE 损失,无法保证模型关注"相对置信度"。
- 改进目标:使正确类别的置信度 o y o_y oy 显著高于其他类别(如 o y − o i > Δ o_y - o_i > \Delta oy−oi>Δ)。

1.3 Softmax函数
将原始输出 o o o 转换为概率分布 y ^ \hat{y} y^,满足:
- 非负性: y ^ i ≥ 0 \hat{y}_i ≥ 0 y^i≥0。
- 归一化: ∑ y ^ i = 1 ∑\hat{y}_i = 1 ∑y^i=1。
y ^ i = e o i ∑ j = 1 N e o j \hat{y}i=\frac{e^{o_i}}{\sum{j=1}^Ne^{o_j}} y^i=∑j=1Neojeoi
作用:
- 指数变换:确保输出非负,并放大差异。
- 分母:归一化所有类别的概率。

1.4 交叉熵损失(Cross-Entropy)
衡量预测概率 y ^ \hat{y} y^ 与真实分布 y y y 的差异。
L ( y , y ^ ) = − ∑ i = 1 N y i log y ^ i L(y,\hat{y})=-\sum_{i=1}^Ny_i\log\hat{y}_i L(y,y^)=−i=1∑Nyilogy^i
简化:因 y y y 为 One-Hot 编码,实际计算仅需正确类别的概率:
L ( y , y ^ ) = − log y ^ y L(y,\hat{y})=-\log\hat{y}_y L(y,y^)=−logy^y

梯度计算
损失对 o i o_i oi 的梯度为 y ^ i − y i \hat{y}_i - y_i y^i−yi,即预测概率与真实概率的差值。
2 经典损失函数
损失函数用于量化模型预测值( y ^ \hat{y} y^)与真实值( y ^ \hat{y} y^)的差异,指导参数优化。
关键分析维度:
- 函数形状(损失 vs 预测值)。
- 梯度特性(更新幅度与方向)。
- 数值稳定性(如可导性)。
2.1 均方误差(MSE / L2 Loss)
L ( y , y ^ ) = 1 2 ( y − y ^ ) 2 L(y,\hat{y})=\frac12(y-\hat{y})^2 L(y,y^)=21(y−y^)2
特性:
- 函数曲线:二次函数(抛物线),对称于真实值点(下图蓝线)。
- 梯度:线性增长(下图橙线),远离真实值时梯度大,靠近时梯度小。
- 优点:处处可导,优化末期稳定。
- 缺点:对离群值敏感(梯度过大可能导致震荡)。

2.2 绝对值误差(MAE / L1 Loss)
L ( y , y ^ ) = ∣ y − y ^ ∣ L(y,\hat{y})=|y-\hat{y}| L(y,y^)=∣y−y^∣
特性:
- 函数曲线:V 形折线(下图蓝线),在真实值处不可导。
- 梯度:常数 ±1(下图橙线),远离真实值时更新力度恒定。
- 优点:对离群值鲁棒(梯度不受距离影响)。
- 缺点:零点不可导,优化末期可能震荡。

2.3 Huber Loss(鲁棒损失)
L ( y , y ^ ) = { 1 2 ( y − y ^ ) 2 i f ∣ y − y ^ ∣ ≤ δ δ ∣ y − y ^ ∣ − 1 2 δ 2 o t h e r w i s e L(y,\hat{y})=\begin{cases}\frac12(y-\hat{y})^2&\mathrm{if}|y-\hat{y}|\leq\delta\\\delta|y-\hat{y}|-\frac12\delta^2&\mathrm{otherwise}\end{cases} L(y,y^)={21(y−y^)2δ∣y−y^∣−21δ2if∣y−y^∣≤δotherwise
特性:
- 函数曲线:在阈值内为二次函数,阈值外为线性(下图蓝线)。
- 梯度:阈值内线性变化,阈值外恒定(下图橙线)。
- 优点:平衡 MSE 和 MAE,对离群值鲁棒且优化平滑。
- 应用场景:回归任务中需兼顾稳定性和鲁棒性。

3 图像分类数据集
Fashion MNIST数据集是传统MNIST手写数字数据集的替代品,由Zalando(一家欧洲的时尚科技公司)的研究部门创建并发布。与MNIST相比,Fashion MNIST具有以下特点37:
- 更复杂的分类任务:包含10个类别的服装物品,比简单数字识别更具挑战性
- 相同的图像规格:28×28像素的灰度图像,训练集60000张,测试集10000张
- 现代相关性:相比1980年代的MNIST,Fashion MNIST更能反映现代计算机视觉任务
数据集包含的10个类别分别是:T-shirt/top(T恤)、Trouser(裤子)、Pullover(套衫)、Dress(连衣裙)、Coat(外套)、Sandal(凉鞋)、Shirt(衬衫)、Sneaker(运动鞋)、Bag(包)和Ankle boot(短靴)。
3.1 读取数据集
-
我们可以通过框架中的内置函数将Fashion-MNIST数据集下载并读取到内存中。
训练集和测试集分别包含60000和10000张图像。 测试数据集不会用于训练,只用于评估模型性能。
pythonimport torch import torchvision from torch.utils import data from torchvision import transforms from d2l import torch as d2l d2l.use_svg_display() # 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式, # 并除以255使得所有像素的数值均在0~1之间 trans = transforms.ToTensor() mnist_train = torchvision.datasets.FashionMNIST( root="./data", train=True, transform=trans, download=True) mnist_test = torchvision.datasets.FashionMNIST( root="./data", train=False, transform=trans, download=True) # 训练集和测试集大小 len(mnist_train), len(mnist_test)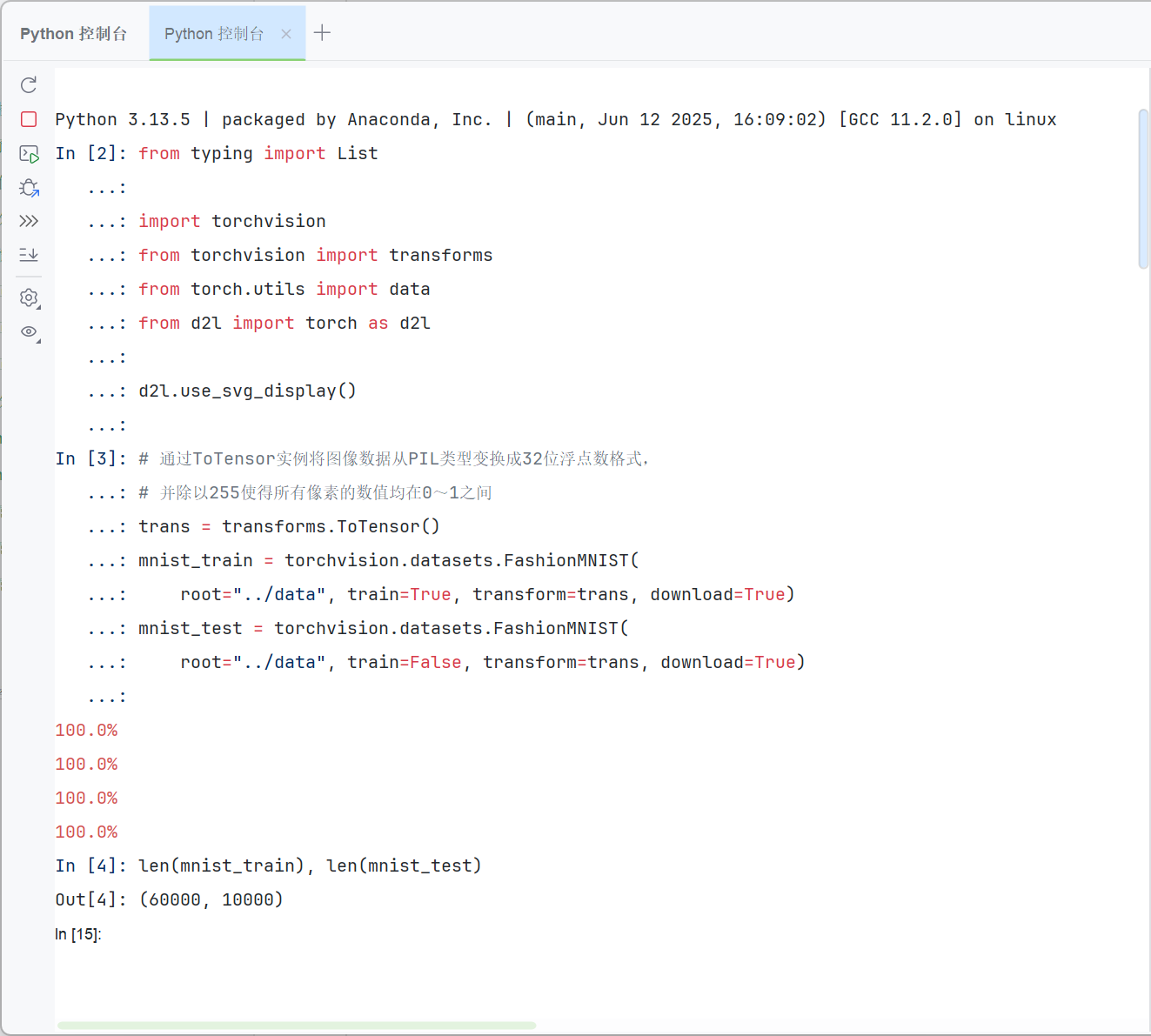
-
每个输入图像的高度和宽度均为28像素。 数据集由灰度图像组成,其通道数为1。
pythonmnist_train[0][0].shape
-
以下函数用于
- 在数字标签索引及其文本名称之间进行转换。
- 可视化这些样本。
pythondef get_fashion_mnist_labels(labels): #@save """返回Fashion-MNIST数据集的文本标签""" text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat', 'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot'] return [text_labels[int(i)] for i in labels] def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5): #@save """绘制图像列表""" figsize = (num_cols * scale, num_rows * scale) _, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize) axes = axes.flatten() for i, (ax, img) in enumerate(zip(axes, imgs)): if torch.is_tensor(img): # 图片张量 ax.imshow(img.numpy()) else: # PIL图片 ax.imshow(img) ax.axes.get_xaxis().set_visible(False) ax.axes.get_yaxis().set_visible(False) if titles: ax.set_title(titles[i]) return axes -
以下是训练数据集中前几个样本的图像及其相应的标签。
pythonX, y = next(iter(data.DataLoader(mnist_train, batch_size=18))) show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y));
3.2 读取小批量
- 在每次迭代中,数据加载器每次都会读取一小批量数据,大小为
batch_size。 通过内置数据迭代器,我们可以随机打乱了所有样本,从而无偏见地读取小批量。
python
batch_size = 256
def get_dataloader_workers(): #@save
"""使用4个进程来读取数据"""
return 4
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers())
timer = d2l.Timer()
for X, y in train_iter:
continue
f'{timer.stop():.2f} sec' # 读取所需要的时间
-
定义
load_data_fashion_mnist函数,用于获取和读取Fashion-MNIST数据集。 这个函数返回训练集和验证集的数据迭代器。 此外,这个函数还接受一个可选参数resize,用来将图像大小调整为另一种形状。通过指定
resize参数来测试load_data_fashion_mnist函数的图像大小调整功能。pythondef load_data_fashion_mnist(batch_size, resize=None): #@save """下载Fashion-MNIST数据集,然后将其加载到内存中""" trans = [transforms.ToTensor()] if resize: trans.insert(0, transforms.Resize(resize)) trans = transforms.Compose(trans) mnist_train = torchvision.datasets.FashionMNIST( root="../data", train=True, transform=trans, download=True) mnist_test = torchvision.datasets.FashionMNIST( root="../data", train=False, transform=trans, download=True) return (data.DataLoader(mnist_train, batch_size, shuffle=True, num_workers=get_dataloader_workers()), data.DataLoader(mnist_test, batch_size, shuffle=False, num_workers=get_dataloader_workers())) train_iter, test_iter = load_data_fashion_mnist(32, resize=64) for X, y in train_iter: print(X.shape, X.dtype, y.shape, y.dtype) break
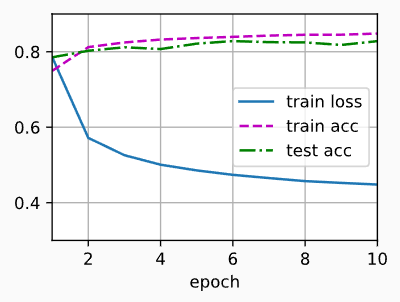
4 softmax回归的简洁实现
-
初始化模型参数
softmax回归的输出层是一个全连接层。 因此,只需在
Sequential中添加一个带有10个输出的全连接层。 同样,在这里Sequential并不是必要的, 但它是实现深度模型的基础。 我们仍然以均值0和标准差0.01随机初始化权重。pythonimport torch from torch import nn from d2l import torch as d2l batch_size = 256 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) # PyTorch不会隐式地调整输入的形状。因此, # 我们在线性层前定义了展平层(flatten),来调整网络输入的形状 net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10)) def init_weights(m): if type(m) == nn.Linear: nn.init.normal_(m.weight, std=0.01) net.apply(init_weights); -
使用内置交叉熵损失函数
pythonloss = nn.CrossEntropyLoss(reduction='none') -
使用优化算法 SGD
使用学习率为0.1的小批量随机梯度下降作为优化算法。
pythontrainer = torch.optim.SGD(net.parameters(), lr=0.1) -
训练
pythonnum_epochs = 10 d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)