MySQL
OTC 业务积压
-
业务停sync同步
-
【与1同时】停dble服务(走批量脚本,贴JSON)
-
等待数据库恢复后,批量启动dble
-
业务开启sync
OTC 物理机CPU型号
- OTC库主机使用Intel 5218 CPU,不能使用5117,自旋锁性能差

uproxy前/后端连接数满
- 后端连接数满(Consider insufficient bconns)
-
业务存在间断性报错:可临时扩容后端数据库连接数(20%左右)
-
业务完全停滞:切库
-
快速分析慢查,给到开发
- 前端连接数满
-
查询当前uproxy中客户端连接ip及数量反馈给开发 http://172.21.141.48:8080/job/OS/job/dba.os.get_tcp_clients/
-
临时调大uproxy前端最大连接数
DMP上从库正在提升为主库处于停滞状态
- 中断提升为主操作,使主库还原回去:在提升为主的机器上将uguard agent进程kill
pkill -f "uguard-agent"
-
去DMP重新启动uguard agent
-
再次切换
D3慢查增多
d3重大活动时若慢查较多,且都为正常业务sql,则大概率由于表数据量变大有关,紧急预案为删除表数据:(具体删除数据量由开发确认)
- delete from order_list_XXXX where order_flag&8388608=8388608 order by id limit 5000;
D3预备队从库cpu飙升/延迟
- 延迟:
-
检查是否有备份进程卡住
-
若不是备份原因,重启数据库
- CPU飙升:
- 检查异常sql
- 若都为如下监控 sql,可直接kill,并反馈给开发进行优化
sql
SELECT count(distinct(a.order_id)) FROM loc_order.order_log_20230529 a inner join loc_order.order_list_20230529 b on a.order_id=b.order_id where a.action_time > 1685652301 and a.action_type=1 and b.dispatch_type=3 and b.shop_id not in (select distinct s.shop_id from loc.aoi a1 inner join loc.shop_info s on s.aoi_id=a1.id where a1.shop_ids is not null) and b.city_id not in ( select c.divide_val from loc.idc_map c where c.divide_key = 'city_id')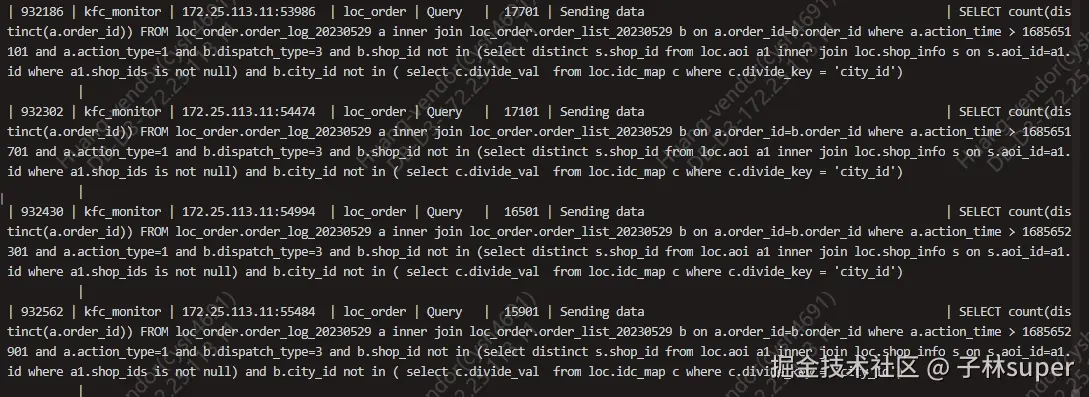
D3归档失败
MySQL辅助监控 核心版 - Dashboards - Grafana (hwwt2.com)
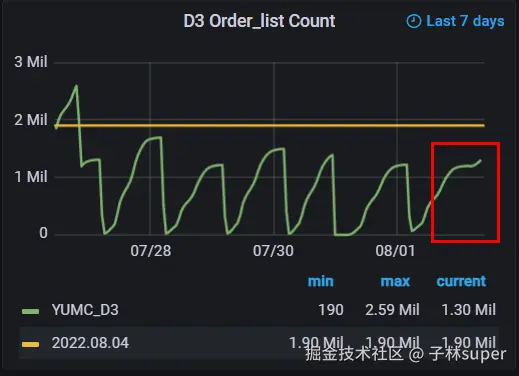
- 检查归档失败原因
172.25.113.51上查看错误日志:(字符集bug)--已解决
bash
cd /data/mysql/backup/D3Archive/log
cat PRG_D3-KFC-OLN_202308020505.err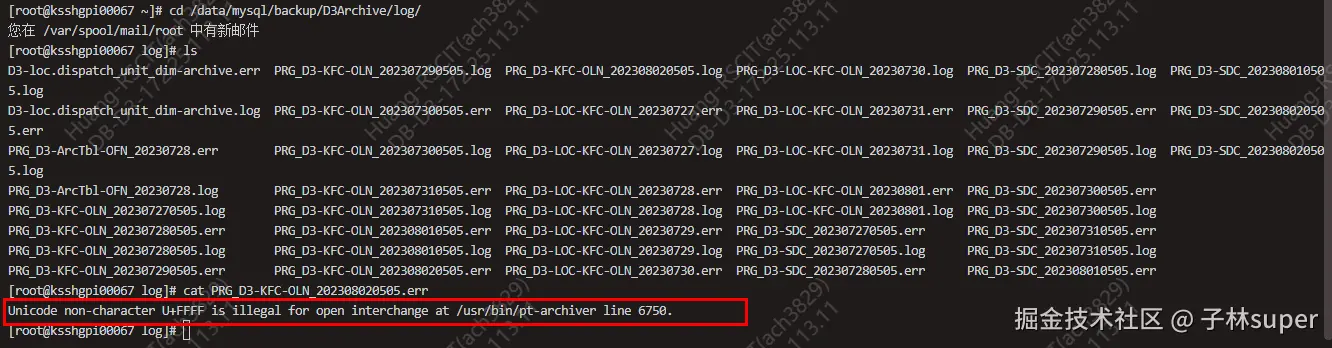
- 解决方法:
1)主库上手动删除行数据,再执行归档脚本
sql
-- ☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️
-- ☣️☣️☣️注意!以下脚本中的表名后缀及日期范围应以实际情况进行修改! ☣️☣️☣️
-- ☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️☣️
select count(1),date from order_list_20240805 where date < '20240810' and order_flag&8388608=8388608 group by date;
delete from order_list_20240805 where date <'20240810' and order_flag&8388608=8388608 order by id limit 10000;- 172.25.113.51预备队从库上执行脚本
bash
# 进入screen
screen -r delete
# 跑清理脚本
sh /data/mysql/backup/D3Archive/script/D3Purge_KFC.sh >> /data/mysql/backup/D3Archive/log/PRG_D3-KFC-OLN_$(date +%s)_manual.log 2>> /data/mysql/backup/D3Archive/log/PRG_D3-KFC-OLN_$(date +%s)_manual.err结合监控及err日志观察数据是否有在正常清理,若再次出现字符集错误,则重复1) 2)操作
主备切换
① 自动切换
禁用主库网卡,使主自动切换
-
安装screen
yum install -y screen
-
开启screen
arduino
screen -S switch-
查看网卡
ifconfig
-
禁用网卡,3分钟后起来
bash
ip link set dev bond0 down; sleep 180; ip link set dev bond0 up② 手动切换
手动提升为主
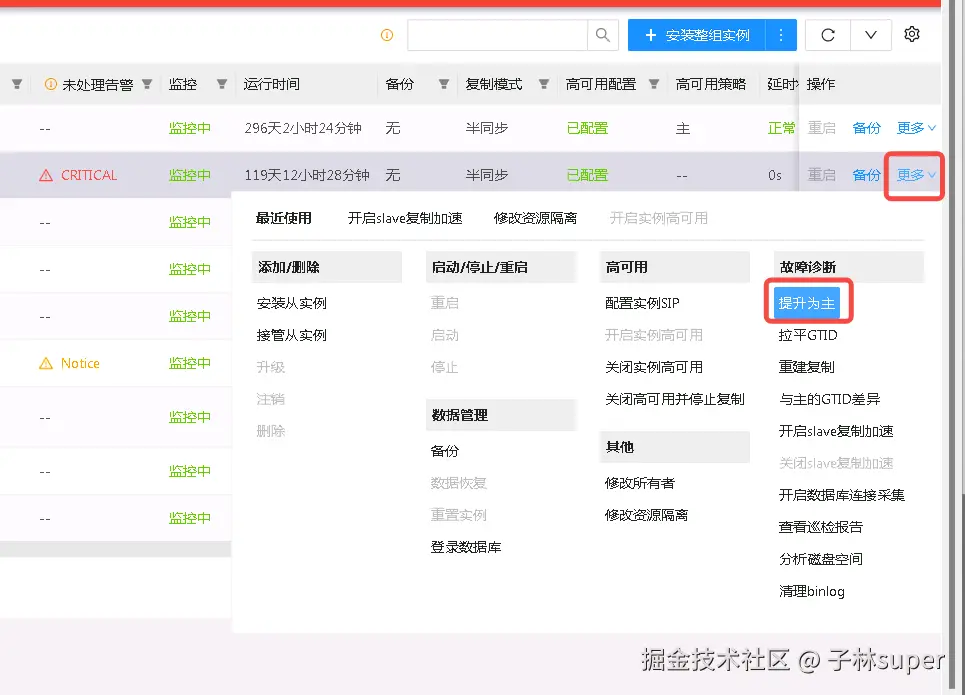
连接数打满
现象:数据库连接数打满,且root用户已无法登录处理
解决方法:1.停程序 2.重启数据库
DR Flink的case
从机器上查看连4353端口的ip来源及其数量
bash
ss -anp | grep 4345 | awk '{print $6}' | awk -F':' '{print $4}' | sort -nr | uniq -ccpu飙高
解决方法:首先查询出占用cpu高的sql语句
1.与开发确认是否可以kill
2.程序是否可以将此sql的任务停止
3.程序是否可以重启
4.是否可以重启数据库
磁盘资源不足
- 非RDS
2、磁盘空间不足
- RDS
① 临时调整quota,把资源放大
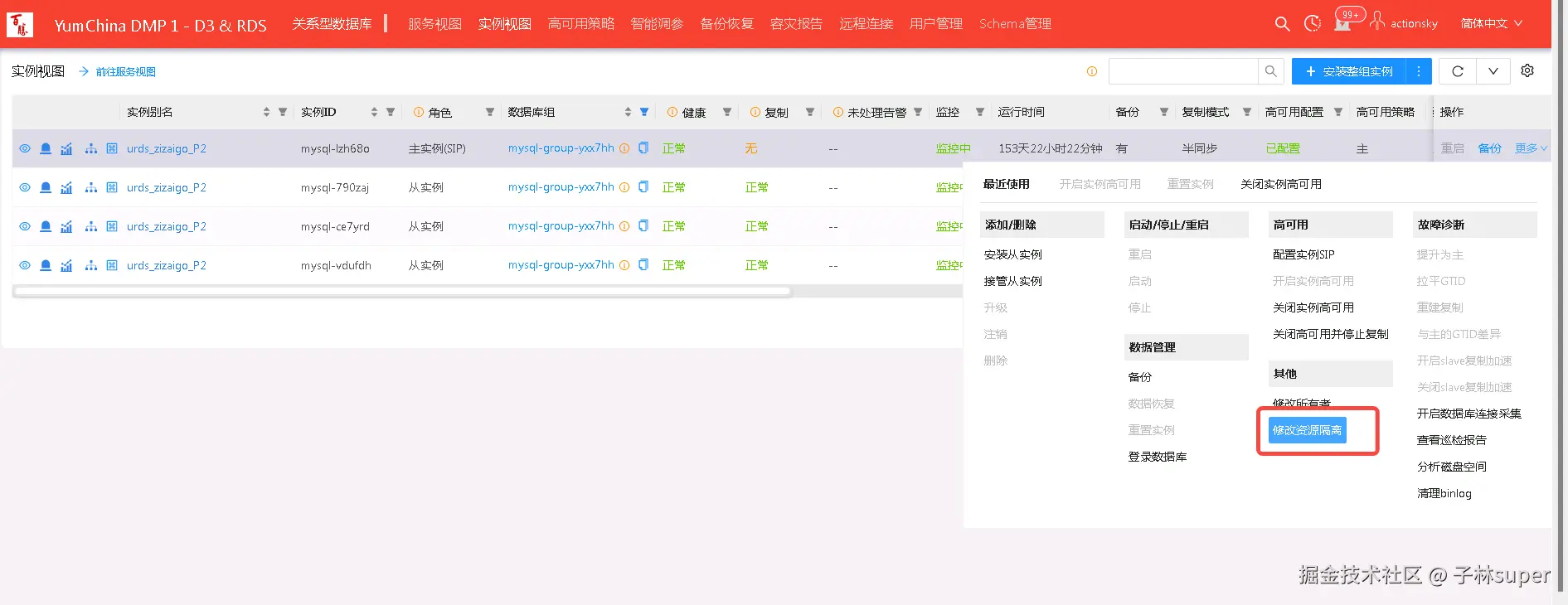 |
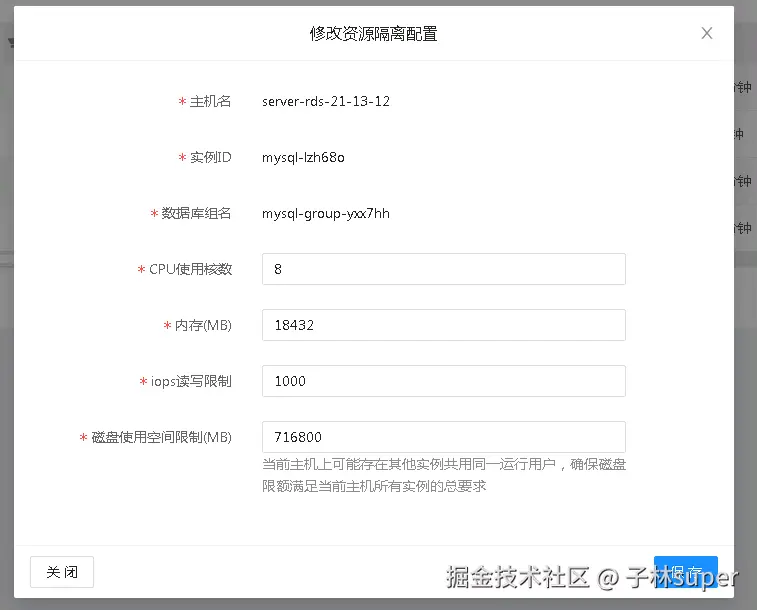 |
|---|
② 再做数据的清理
2、磁盘空间不足
主从延迟处理
1、复制延迟
特殊场景,可以不用关注@欧阳涵 @张效闻 补充
- mysql-group-sqw7vj,餐期/晚上有一定延迟,开启复制加速即可
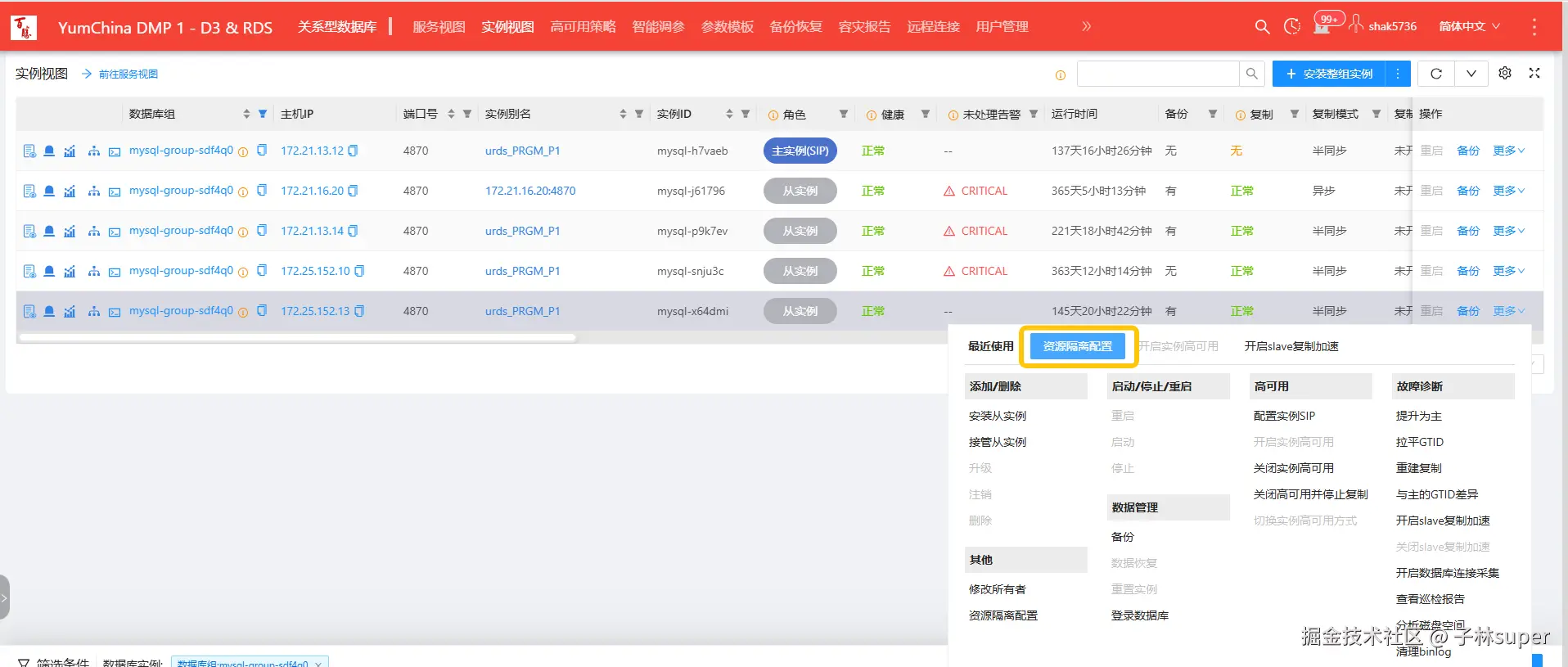
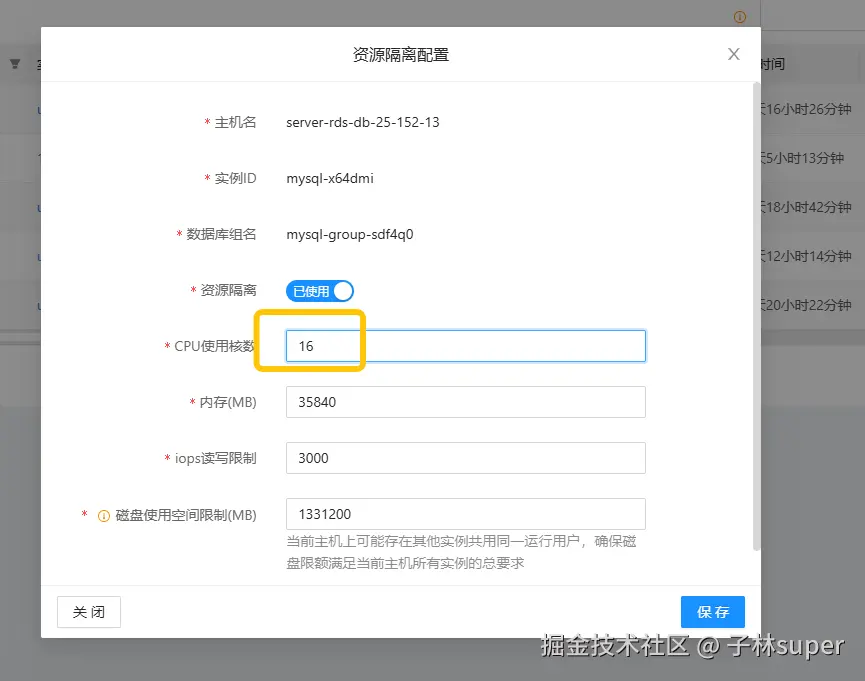
- mysql-group-sdf4q0的cpu打满,将资源隔离里的cpu扩10c
- mysql-cpos-cposcounter 数据库备份,维护窗口0:00-6:00,延迟从6点追到10:30
mysql-shouquan
mysql-pro
mysql-group-eme85s
慢查阻塞
- 登录DMP,通过慢日志功能,快速查看、导出、定位当前慢查
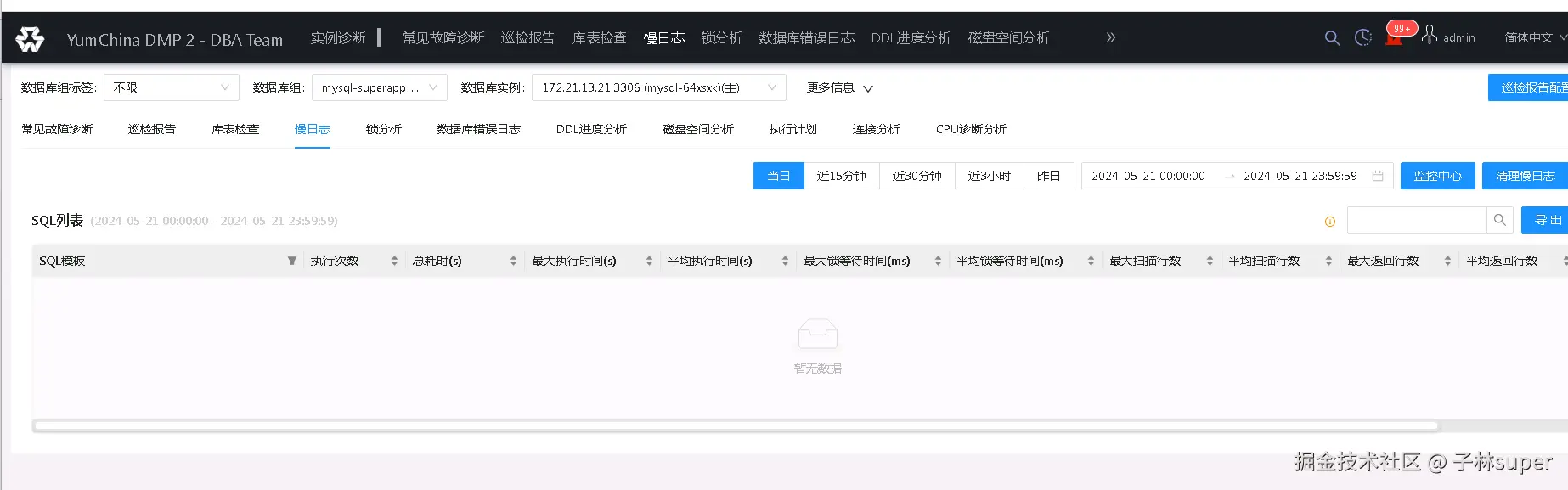
-
将导出的慢日志中,top SQL发到开发运维所在的群,并引导开发快速制定对策
-
慢日志中的关键SQL如何定位??(进阶)
从库发生故障不可用
- 旧主比新主多GTID
查看具体GTID,如果业务表示无需补数据,则拉平GTID,开启高可用
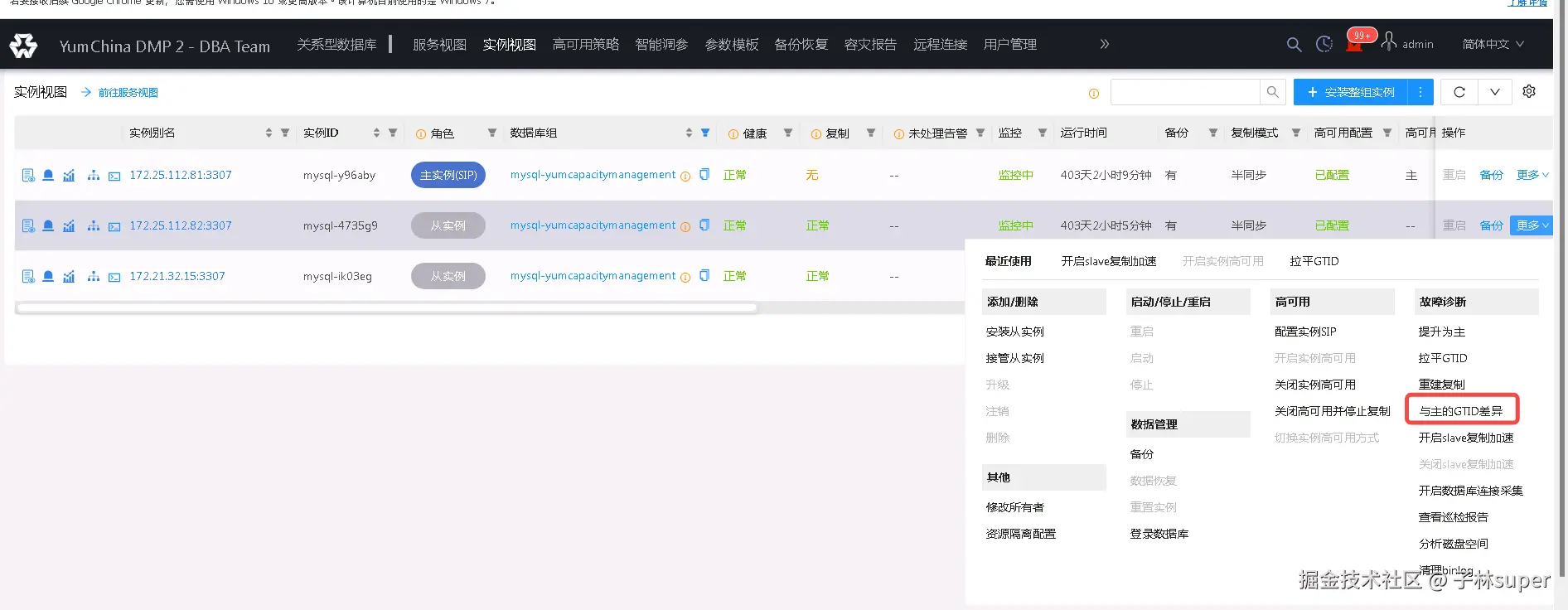
- 从库延迟超过binlog保留时间
重置从库
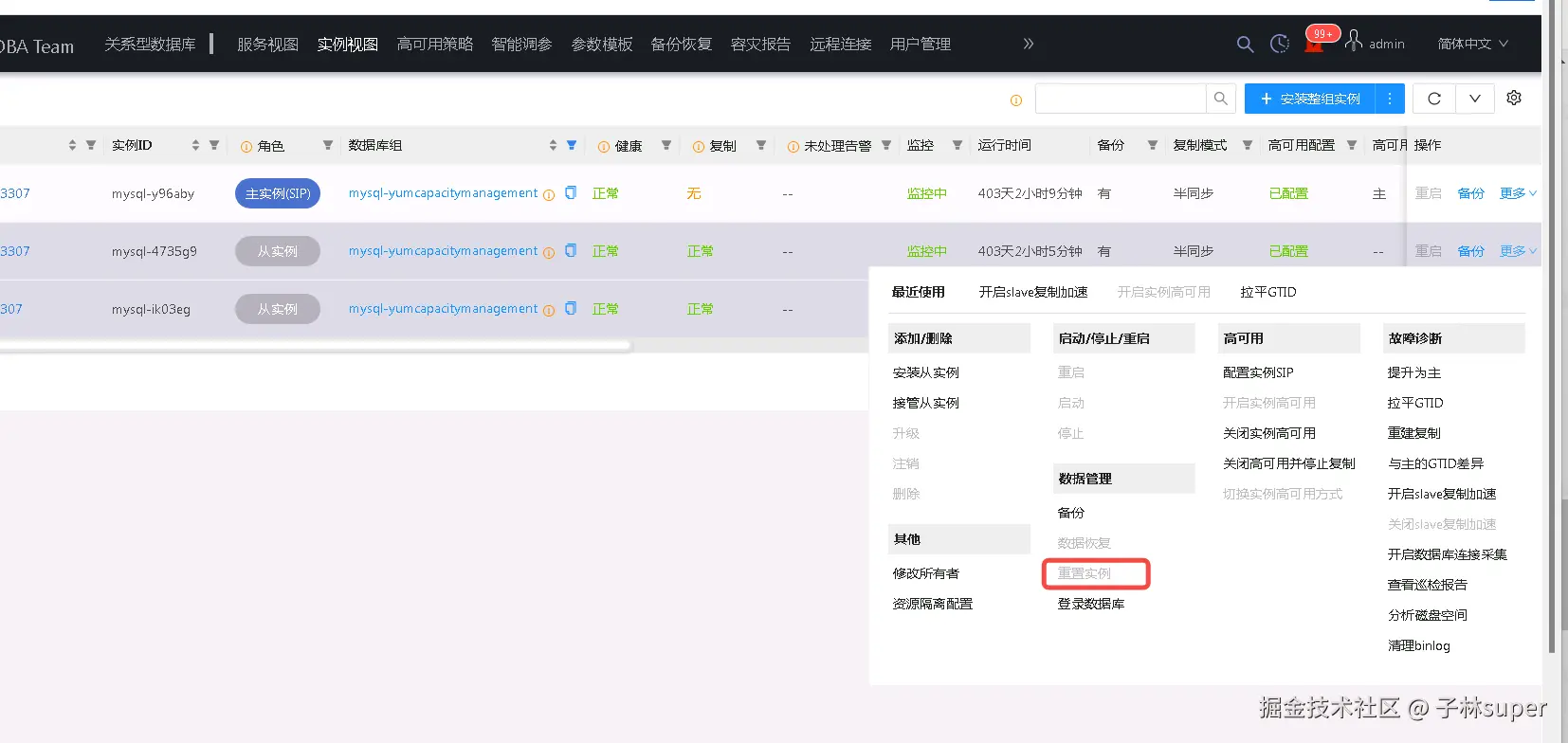
- 屏蔽中心(特例)--业务已解决
主库下发truncate,触发bug导致从库主键冲突
处理:
① 关闭从库高可用
② 登录从库,关闭只读
SET GLOBAL SUPER_READ_ONLY=OFF;
③ 临时关闭从库binlog
set session sql_log_bin=0;
④ 停主从复制
stop slave;
⑤ 在从上执行truncate命令(根据实际情况)
truncate table mcsell.t_d_raw_sell_out_task_2;
⑥ 启动复制
start slave;
⑦ 开启从库高可用(如果开启失败则重启从库,再开启高可用)
- 主机故障
升级给裸金属
DMP单站网络故障
- yumc3出口异常
-
确保所有S级数据库主站保持在YUMC4
-
屏蔽所有从库延迟告警
- yumc4出口异常
-
拉起Yumc3的DMP
-
S级数据库主站全部切换至YUMC3
【主要】S级MySQL一键切换Json
【次要】S级MySQL一键切换Json
PG
磁盘使用率高
查看文件系统使用情况,确认是数据库实际使用空间过大还是归档未清理导致
如果是实际使用过大,联系项目组扩容或者清数据,如果是归档保留过多则清理归档日志,可以根据归档产生情况调整保留天数
CPU使用率高
CPU告警大概率是SQL性能或者并发太多导致,可以将下面SQL查询结果反馈给开发
csharp
-- 查看长事务
-- where条件里的时间取值自行决定
select now(),pid,client_addr,now()-xact_start exec_time,regexp_replace(query,E'[\n\r\t]*\n[\n\r\t ]*',' ','g') act_sql from pg_stat_activity where state = 'active' and pid <> pg_backend_pid() and xact_start < now() - '600 s'::interval order by xact_start;
-- 查看慢sql
-- where条件里的时间取值自行决定
select now(),pid,client_addr,now()-query_start exec_time,regexp_replace(query,E'[\n\r \t]*\n[\n\r\t ]*',' ','g') act_sql from pg_stat_activity where state = 'active' and pid <> pg_backend_pid() and query_start < now() - '600 s'::interval order by query_start;
-- 杀掉慢SQL
select pg_terminate_backend(pid);PG数据库CPU使用率高
主从延迟
- 因为主库没有事务,导致从库的时间戳不更新------不是故障
-
确定主库上最近3小时内是否有insert、update、delete等操作
-
检查从库上CPU是否高
-
检查主从库上活跃连接数是否升高
-
检查fetched与returned之间的比值
-
拉慢查报告
-
从库追不上
-
Vacuum
-
从库性能不如主库(CPU/IO)
-
从库有大的查询
-
重做从库
-
连接数过高
提供client IP给开发,使用job:
http://172.21.141.48:8080/job/OS/job/dba.os.get_tcp_clients/
PG故障切换预案
-
首先使用CLUP平台切换(clup.hwwt2.com:8080/)[CLUP操作切换主...
- 第一次切换失败后,手工直接拉起新主
- 第二次切换成功后,检查主从状态
-
登录主机手工切换
-
HAProxy无需干预,可实现自动故障转移【待六一后生产切换演练】
详情参见:营销中间件切换预案
历史切换文档参考:
Coupon PG切换演练 (主备站切换)-2024.1.12
Coupon PG切换演练 (同站切主从)-2024.1.20
Coupon PG切换演练 (主备站切换)-2024.5.28/29
2025.1.21/22-Coupon PG切换演练 (主备站切换)
Redis
Redis故障切换预案(全局唯一)
| Redis | 故障切换预案 |
内存使用率超过80%
- 设置maxmemory:要设置Redis的最大内存使用量不超过主机内存的75%,假设主机内存为16GB,那么Redis的最大内存设置为12GB(12GB = 12 * 1024 * 1024 * 1024 bytes)
sql
CONFIG SET maxmemory 12gb- 通知应用运维
观察内存变化趋势,瞬时还是持续上升做决策
- 修改maxmemory-policy :如果扩容后问题仍未解决,需要将内存淘汰策略修改为
allkeys-lru
sql
CONFIG SET maxmemory-policy allkeys-lru请注意,确保在执行这些命令之前已经备份了Redis的数据,以防止数据丢失
CPU使用率超过80%
- 提供client IP连接数给开发
连接数超过75%
- 清空对应单元的业务流量
- 如无法切站,临时调整最大连接至15000
sql
CONFIG SET maxclients 15000Elasticsearch
DBA接管
bash
# 启动
systemctl start elasticsearch
# 停止
systemctl stop elasticsearch
# 重启
systemctl restart elasticsearch
# 状态
systemctl status elasticsearchDBA未接管
perl
# 启动
# /bin 下有个elasticsearch启动脚本
sh elasticsearch -d
# 停止
kill [pid]
# 查看es的进程
ps -ef | grep elasticsearchhisorder ES节点CPU使用率异常高
-
提供ES上的client IP数给开发
-
查询es的慢查日志阈值,有开启的话,推进下面一步
-
登录主机查看es 的slow相关日志
hisorder ES协调节点OOM
重启ES服务,参考
Selection ES集群信息
selection ES集群信息
监控 infra-grafana.hwwt2.com/d/na_nxrE-s...
补充预案
ES六一故障预案
通用监控屏
infra-grafana.hwwt2.com/d/na_nxrE_m...
Mongodb
DBA接管
bash
# 启动
systemctl start mongod_27017
# 停止
systemctl stop mongod_27017
# 重启
systemctl restart mongod_27017
# 状态
systemctl status mongod_27017DBA未接管
perl
# 停止, 前提是找到mongod所在位置
./mongod --shutdown --dbpath=/data/db --fork --logpath=/var/log/mongodb/mongod.log
# 启动
# 指定启动配置和数据路径 ,--bind_ip_all 可以本机以外机器访问
./mongod --dbpath=/data/db --fork --logpath=/var/log/mongodb/mongod.log --bind_ip_all
# 状态
ps -ef | grep mongodmongo六一活动期间预案
mongo六一活动期间预案
通用监控屏
infra-grafana.hwwt2.com/d/uQ2OzPLGk...
ELK
YUMC3 ELK
-
使用火山的ES和flink PaaS产品
-
KS kafka节点信息
| 序号 | ip | 配置 | 角色 |
|---|---|---|---|
| 1 | 172.25.106.22 | 16C/32G/5T | KS ELK kafka + ZK |
| 2 | 172.25.106.23 | 16C/32G/5T | KS ELK kafka + ZK |
| 3 | 172.25.106.29 | 16C/32G/5T | KS ELK kafka + ZK |
| 4 | 172.25.106.30 | 16C/32G/5T | KS ELK kafka |
| 5 | 172.25.106.31 | 16C/32G/5T | KS ELK kafka |
- ZK的启停
bash
# 启动
/usr/bin/nohup /opt/zookeeper/bin/zkServer.sh start >/dev/null 2>&1 &
# 暂停
kill -9 `ps -ef |grep zoo.cfg |grep -v grep |awk '{print $2}'`- kafka服务
bash
# 第二种方式启动
sh /opt/bin/kafkastart.sh
# kafka停止
sh /opt/kafka/bin/kafka-server-stop.sh- filebeat服务
bash
# 启动
systemctl start filebeat
# 停止
systemctl stop filebeat
# 重启
systemctl restart filebeat
# 状态
systemctl status filebeatYUMC4 ELK
-
使用火山的ES和flink PaaS产品
-
WG kafka节点信息
| 序号 | IP | 配置 |
|---|---|---|
| 1 | 172.21.241.185 | 32C/64G/7T |
| 2 | 172.21.241.186 | 32C/64G/7T |
| 3 | 172.21.241.187 | 32C/64G/7T |
| 4 | 172.21.241.188 | 32C/64G/7T |
| 5 | 172.21.241.189 | 32C/64G/7T |
- ZK的启停
bash
# 启动
/usr/bin/nohup /opt/zookeeper/bin/zkServer.sh start >/dev/null 2>&1 &
# 暂停
kill -9 `ps -ef |grep zoo.cfg |grep -v grep |awk '{print $2}'`- kafka服务
bash
# 启动
# /kafka-server-start.sh /opt/kafka/config/server.properties
nohup /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties >> /opt/kafka/logs/kafka_nohup.log 2>&1 &
# 启动02
sh /opt/kafka/kafka_start.sh
# 停止
sh /opt/kafka/bin/kafka-server-stop.sh- filebeat服务
bash
# 启动
systemctl start filebeat
# 停止
systemctl stop filebeat
# 重启
systemctl restart filebeat
# 状态
systemctl status filebeatWG ELK ES容量告警应急预案
WG ELK ES容量告警应急预案
kafka消费延迟
- WG(火山ELK)
调整Flink的CU情况
- KS(阿里SLS)
调整logstore的分片数
kibana地址打不开问题
- 请使用VPN、尝试在PIM机中访问kibana
kafka磁盘不足
清理kafka的落盘数据,清理路径/data/kafka/topic/*,参考
topic消费降级预案
降低ELK的带宽使用,保障业务服务的带宽优先使用,参考ELK消费降级预案
TiDB
TiKV节点扩容
支付中心/消息中心/用户中心 Tikv 节点扩容
YUMC3单站失联
PRD_TiDB_haproxy_切换【谨慎操作!!!】
影响支付中心/消息中心,目前通过Jenkins脚本完成切站
无数据不一致风险,但是切站过程会出现预期业务报错

YUMC4单站失联
影响用户中心,目前通过Jenkins脚本完成切站(同上)
无数据不一致风险,但是切站过程会出现预期业务报错
用户中心活动缓存开关
- 优先应用运维限流,再扩容TiDB节点
- 2024-12-21 由于用户中心活动缓存开关关闭,导致连接数超过TiDB上限,业务响应超时报错

参考文档:2024-12-21 时代少年团活动复盘20241231 UH-TIDB性能测试报告 20250114 UH-TIBD性能测试报告
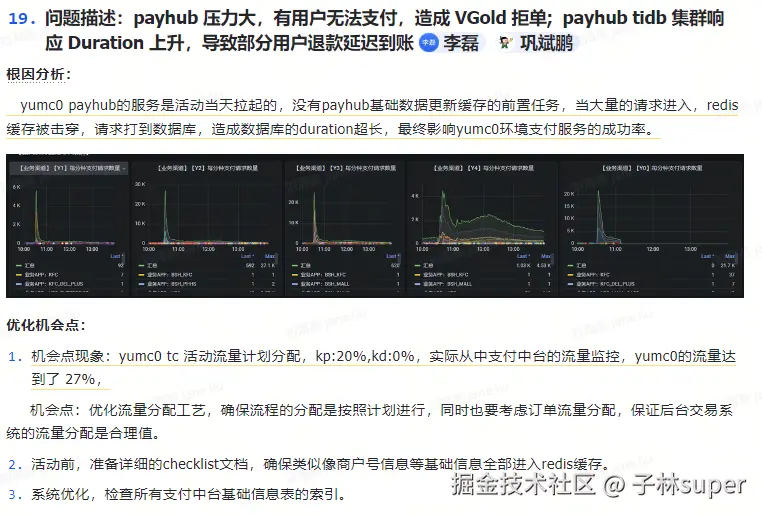
支付中心Y0环境预热
- 2025-01-03 由于支付中心Y0服务活动当天才拉起,导致redis缓存被击穿,造成数据库Duration超长,Y0支付服务成功率下降
Starrocks
集群清单
OLAP数据库信息收集
StarRocks集群清单
启停命令
bash
# ###
# 注意
starrocks的安装路径不同,启动和停止脚本所在路径会有所不同。
以下是按照dba标准的路径做用例
# 启动fe节点
sh /data/fe/bin/start_fe.sh --daemon
# 启动be节点
sh /data/be/bin/start_fe.sh --daemon
# 启动CN节点
sh /data/be/bin/start_fe.sh --daemon
# 停止fe节点
sh /data/fe/bin/stop_fe.sh --daemon
# 停止be节点
sh /data/be/bin/stop_be.sh --daemon
# 停止CN节点
sh /data/be/bin/stop_cn.sh --daemon日常q&a
starrocks日常Q\&A
通用监控屏
FE
infra-grafana.hwwt2.com/d/1fFiWJ4m1...
BE
infra-grafana.hwwt2.com/d/1fFiWJ4m1...
Doris
集群清单
OLAP数据库信息收集\] \[doris集群信息
启停命令
bash
# ###
# 注意
starrocks的安装路径不同,启动和停止脚本所在路径会有所不同。
以下是按照dba标准的路径做用例
FE节点操作
# 启动命令
sh /data/doris/fe/bin/start_fe.sh --daemon
# 停止命令
sh /data/doris/fe/bin/stop_fe.sh --daemon
BE节点操作
# 启动脚本
sh /data/doris/be/bin/start_be.sh --daemon
# 停止命令
sh /data/doris/be/bin/stop_be.sh --daemon日常q&a
通用监控屏
FE
infra-grafana.hwwt2.com/d/1fFiWJ4m2...
BE
infra-grafana.hwwt2.com/d/1fFiWJ4m2...