文章目录
前言
在上一篇文章中,我们将ChatOpenAI强行塞入前端,实现了一个乱七八糟的前端页面。这当然不是很好的。所以,今天我们就来优雅的再塞进去一次,争取完善之前的问题。
当然,这次主要讨论的是主动方式,也就是自行实现一个Wrapper类。
所有的东西都放在了Github仓库中。
欢迎来玩。
大前提
为了更好的说明这件事儿,有一个大前提:
我现在有两个大模型:
| 模型来源 | 模型名称 | 模型描述 |
|---|---|---|
| 阿里灵积 | qwen-max | 支持文本类的全部功能和自定义tool |
| 华为昇腾本地部署 | DeepSeek-Dstill-Llama-70B | 仅支持文本对话功能和记忆 |
然后呢,我希望这俩的stream和invoke能够全部兼容。
于是这就对Wrapper有 2 2 2个要求:
- 可以接受 3 3 3个类型,分别是
str、BaseMessage和Iterator; - 本地部署的
DeepSeek-Dstill-Llama-70B模型输出格式为:<think></think>标签内存放模型的思考过程;- 标签外的内容为真正的回答;
这又是一个考验。因为,单纯的将所有的str全部放在回答栏中,总有种怪怪的感觉。有时候大模型思考过程很长的时候,还很影响观感。
为了实现这样的过程,这个需要自定义的Wrapper类也就可以按照这样的顺序来:
- 获取模型输出,并解析为
str; - 动态构建
st.expander和st.container; - 监测大模型返回结果,当识别到
<think></think>标签的时候,需要将内容整合到st.expander中; - 当接收到
BaseMessage参数的时候,输出结果需要用response.content访问; - 当接收到
str参数的时候,一般为内置信息,直接访问; - 当接收到
Iterator[BaseMessageChunk]参数的时候,输出结果需要用循环访问,循环的每一个对象都需要取出其中的content属性; - 无论使用的是
invoke还是stream,Wrapper类都可以兼容;
看上去任务量可不小啊。一步步来吧。
类创建
我们首先要明确,如果是真需要这样子自定义的话,需要的参数其实必要的有:
- 当前角色
role; - 是否保存到对话记录
save; - 流式延迟
typing_delay; - 传入信息
msg
不过呢,作为Wrapper,我们可以模仿工厂构建模式,先固定住通用的,比如Wrapper接收save和typing_delay作为配置项,然后由Wrapper的成员方法接收role和msg进行文本渲染。
看上去没啥问题。
P.S.:你当然也可以将
role拆出来,用类似HumanMessage和AssistantMessage这样内置role的概念来区分不同的角色。我们接下来就是选用这样的设计。
那么既然确定了这样的结构,我们就来创建一个Wrapper类:
python
class ChatRender:
def __init__(
self,
role: str,
save: bool = True,
typing_delay: float = 2e-2
):
self.role = role
self.save = save
self.typing_delay = typing_delay
# 预留一个回答框
with st.chat_message(role):
self.answer_holder = st.empty()
# 思考框不一定存在,不保留
self.expander = None
self.think_holder = None
# 流式缓冲区
self._buffer = ""这样的话,就可以通过role创建一个渲染消息框的对象了。至于为什么需要typing_delay呢,是因为,在主动模式下,我们无法监听到on_llm_new_token或者on_llm_end等钩子函数的回调,所以,尤其是在invoke函数中,返回值是一次性给出来的。为了依然还原出相对比较完整的打字机效果,必须得手动控制显示速度。至于为什么是 0.02 0.02 0.02秒,只能说,这是一个经验数据,大致上是在人眼感知极限范围内。
最后,至于为什么要用save,其实本质上也是因为输出信息和渲染信息的区别。每次用户执行完成后,都将重新开始渲染整个页面。期间,将执行for循环中整个消息记录全部展现在页面上的命令。这个过程如果再次执行save的话,也就会导致消息记录中会出现重复。
内容更新
至于内容更新,为了能够兼容本地部署DeepSeek的<think></think标签输出,比较方便的方法就是直接采用正则表达式匹配。这种可能看起来略有些简陋。比如说,因为匹配的是一整段,也就是需要头尾都能检测到tag,所以先出来的<think>标签,可能就无法匹配到,还是会把思考过程大段大段地输出出来。等匹配到</think>标签后,才能够将整段思考过程放入st.expander中。
于是就有:
python
def _update(self, new_text: str):
if not new_text: return
self._buffer += new_text
# 把 <think> 剥离出来
think_parts = "\n".join(_THINK_RE.findall(self._buffer))
answer_text = _THINK_RE.sub("", self._buffer).strip() or " "
# 首次检测到 <think> ⇒ 动态创建 expander
if think_parts and self.expander is None:
self.expander = st.expander("🤔 思考过程", expanded=False)
self.think_holder = self.expander.empty()
# 刷新 UI
if self.think_holder is not None:
self.think_holder.markdown(think_parts)
self.answer_holder.markdown(answer_text)进一步的,再给出渲染方法,也就是传入message交给容器渲染页面的逻辑:
python
def render(self, msg: "str | BaseMessage | Iterator[BaseMessageChunk]"):
if isinstance(msg, str):
self._update(msg)
elif isinstance(msg, BaseMessage):
self._update(msg.content)
elif isinstance(msg, Iterator):
for chunk in msg:
self._update(chunk.content)
time.sleep(self.typing_delay)
else:
raise TypeError("不支持的消息类型")
if self.save:
st.session_state.dashscope["messages"].append(
{"role": self.role, "content": self._buffer}
)内容总结
以上就是一个完整的部分了。下面将整段代码贴出来,可以放在单独的文件中,作为一个模块,这样就解耦出来了。
python
import re, time
import streamlit as st
from collections.abc import Iterator
from langchain_core.messages.base import BaseMessageChunk, BaseMessage
_THINK_RE = re.compile(r"<think>(.*?)</think>", re.S)
class ChatRenderer:
"""同时管理 expander + chat_message 的流式渲染器"""
def __init__(
self,
role: str,
save: bool = True,
typing_delay: float = 0.02
):
self.role = role
self.save = save
self.typing_delay = typing_delay
# UI:先只放 chat_message,占位可反复写
with st.chat_message(role):
self.answer_holder = st.empty()
# expander 延迟创建(只有检测到 <think> 才建)
self.expander = None
self.think_holder = None
# 缓冲区
self._buffer = ""
def render(self, msg: "str | BaseMessage | Iterator[BaseMessageChunk]"):
if isinstance(msg, str):
self._update(msg)
elif isinstance(msg, BaseMessage):
self._update(msg.content)
elif isinstance(msg, Iterator):
for chunk in msg:
self._update(chunk.content)
time.sleep(self.typing_delay)
else:
raise TypeError("不支持的消息类型")
if self.save:
st.session_state.dashscope["messages"].append(
{"role": self.role, "content": self._buffer}
)
def _update(self, new_text: str):
if not new_text: return
self._buffer += new_text
# 把 <think> 剥离出来
think_parts = "\n".join(_THINK_RE.findall(self._buffer))
answer_text = _THINK_RE.sub("", self._buffer).strip() or " "
# === 首次检测到 <think> ⇒ 动态创建 expander ===
if think_parts and self.expander is None:
self.expander = st.expander("🤔 思考过程", expanded=False)
self.think_holder = self.expander.empty()
# 刷新 UI
if self.think_holder is not None:
self.think_holder.markdown(think_parts)
self.answer_holder.markdown(answer_text)使用方法
其实在页面中使用也是相当方便的:
python
from utils.chat_render import ChatRender
if prompt := st.chat_input("你得注意你的言行......求你了......(´;ω;`)"):
ChatRender("user").render("prompt")
response = llm.stream(prompt)
ChatRender("assistant").render(response)就OK啦。
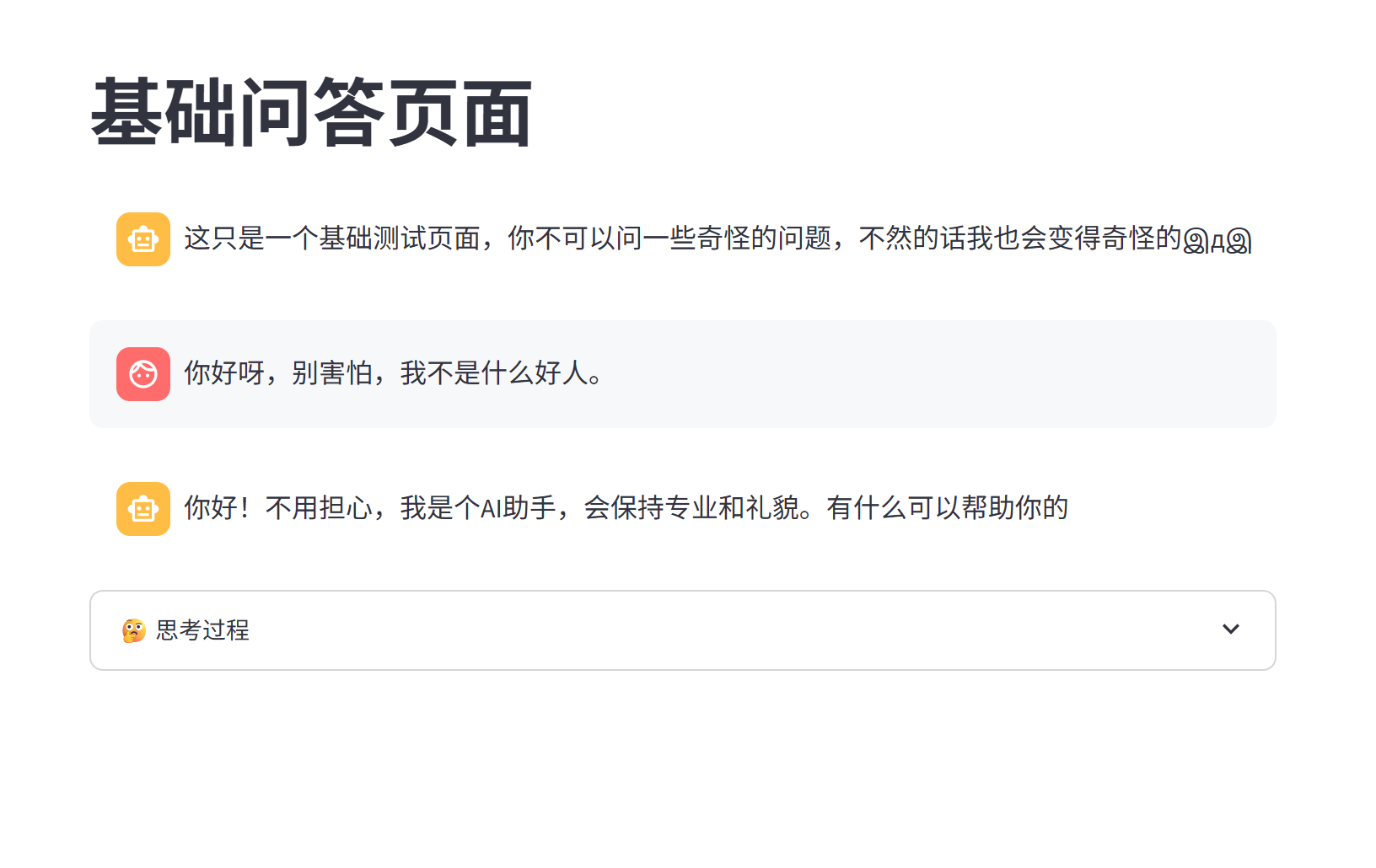
于是整体效果就是这样子:
先不管三七二十一弄得满地都是:
然后才把满地的东西收到一个地方:
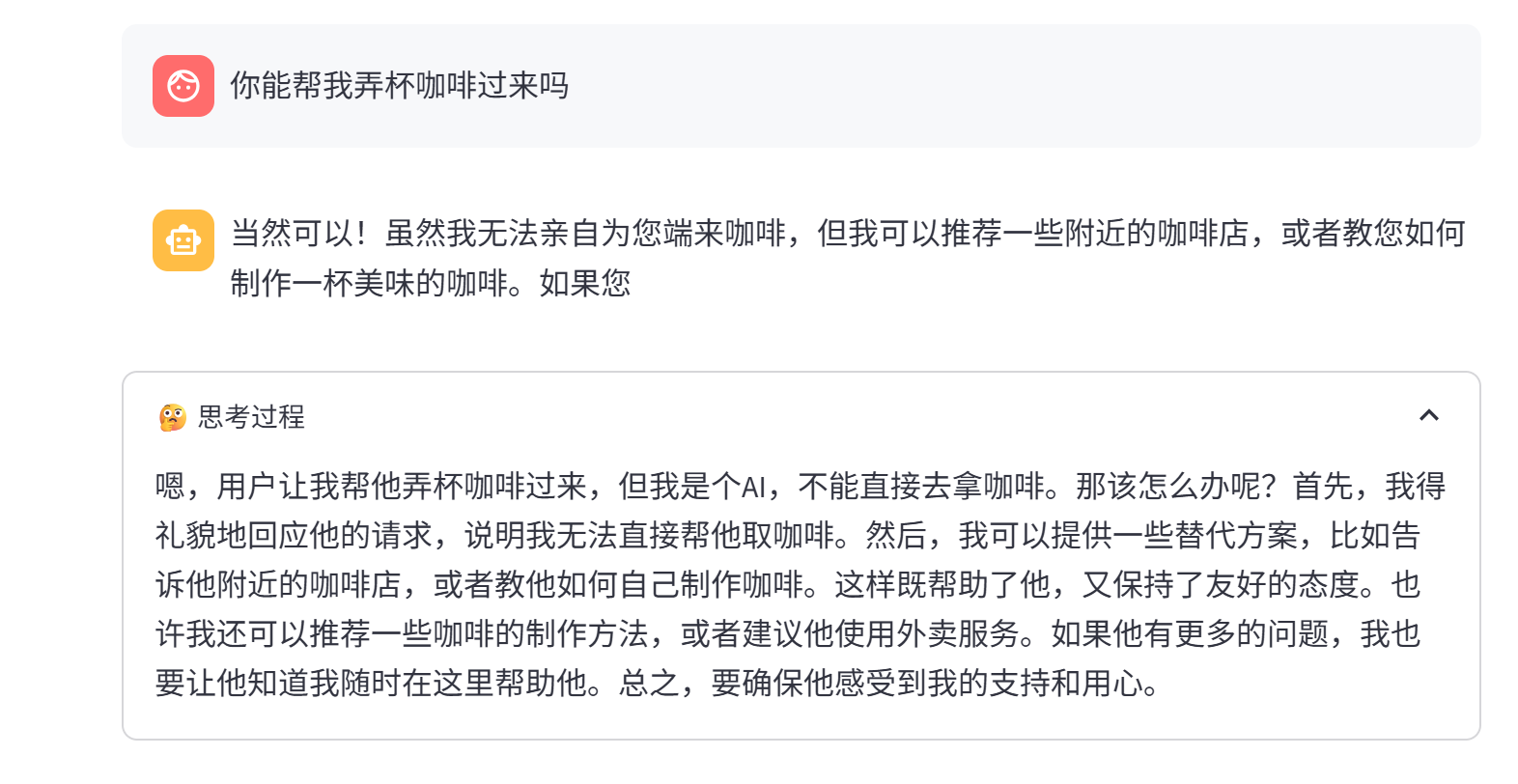
总之算是完成了,既实现了流式输出,又给实现了记忆。